
Heim >Technologie-Peripheriegeräte >KI >Der Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!
Der Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!

- PHPznach vorne
- 2023-04-16 17:49:031436Durchsuche
Der Appetit der KI ist zu groß und die Daten des menschlichen Korpus reichen nicht mehr aus.
Eine neue Arbeit des Epoch-Teams zeigt, dass KI in weniger als 5 Jahren den gesamten hochwertigen Korpus verbrauchen wird.

Sie müssen wissen, dass dies ein vorhergesagtes Ergebnis ist, das die Wachstumsrate menschlicher Sprachdaten berücksichtigt. Mit anderen Worten, selbst wenn alle neuen Papiere und Codes, die in den letzten Jahren von Menschen geschrieben wurden, der KI zugeführt werden, es wird nicht reichen.
Wenn diese Entwicklung anhält, werden große Sprachmodelle, die auf qualitativ hochwertige Daten angewiesen sind, um ihr Niveau zu verbessern, bald mit einem Engpass konfrontiert sein.
Einige Internetnutzer können bereits nicht still sitzen:
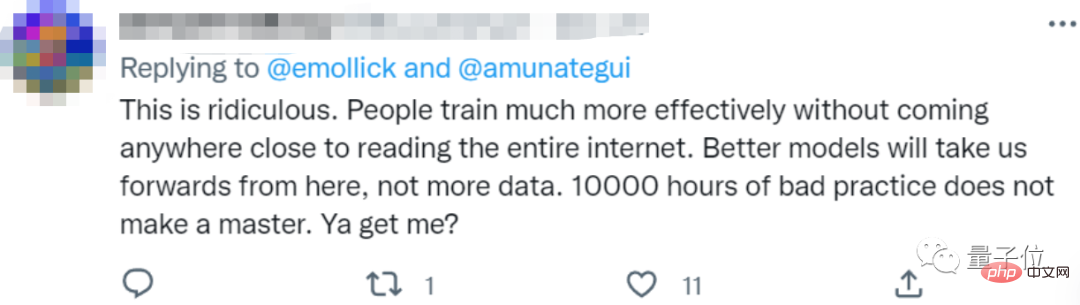
Das ist so lächerlich. Menschen können sich effektiv trainieren, ohne alles im Internet zu lesen.
Wir brauchen bessere Modelle, nicht mehr Daten.
Einige Internetnutzer machten sich darüber lustig, dass es besser sei, die KI fressen zu lassen, was sie ausspuckt:
Sie können den von der KI selbst generierten Text als minderwertige Daten an die KI weiterleiten.

Werfen wir einen Blick darauf, wie viele Daten von Menschen hinterlassen werden?
Wie wäre es mit der „Bestandsaufnahme“ von Text- und Bilddaten?
Das Papier sagt hauptsächlich Text- und Bilddaten voraus.
Zuerst sind die Textdaten.
Die Qualität der Daten reicht normalerweise von gut bis schlecht. Die Autoren haben die verfügbaren Textdaten basierend auf den Datentypen, die von vorhandenen großen Modellen und anderen Daten verwendet werden, in Teile mit geringer Qualität und in Teile mit hoher Qualität unterteilt.
Hochwertiger Korpus bezieht sich auf die Trainingsdatensätze, die von großen Sprachmodellen wie Pile, PaLM und MassiveText verwendet werden, einschließlich Wikipedia, Nachrichten, Codes auf GitHub, veröffentlichten Büchern usw.
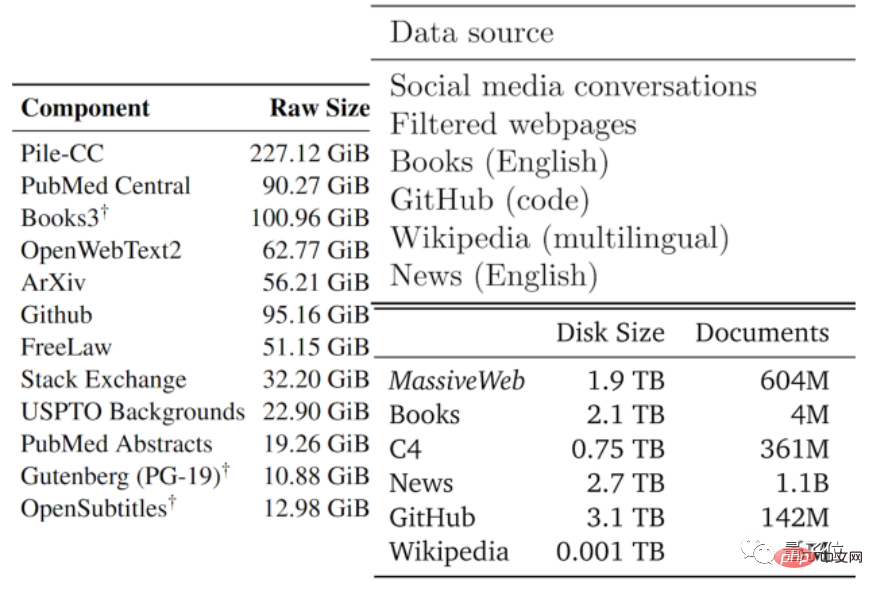
Korpus von geringer Qualität stammt aus Tweets in sozialen Medien wie Reddit und inoffizieller Fanfiction (Fanfic).
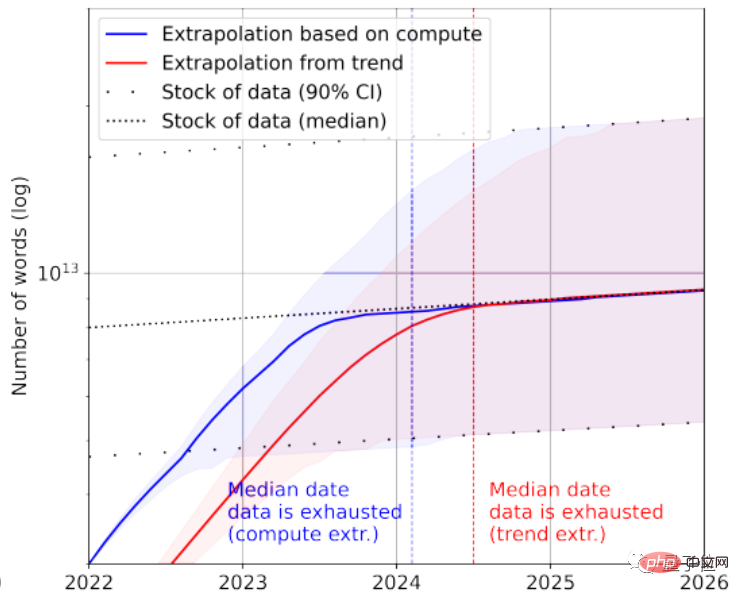
Statistik zufolge gibt es im hochwertigen Sprachdatenbestand nur noch etwa 4,6×10^12~1,7×10^13 Wörter, was weniger als eine Größenordnung größer ist als der derzeit größte Textdatensatz.
In Kombination mit der Wachstumsrate prognostiziert das Papier, dass hochwertige Textdaten zwischen 2023 und 2027 durch KI erschöpft sein werden und der geschätzte Knoten bei etwa 2026 liegt.
Es scheint ein bisschen schnell zu sein...
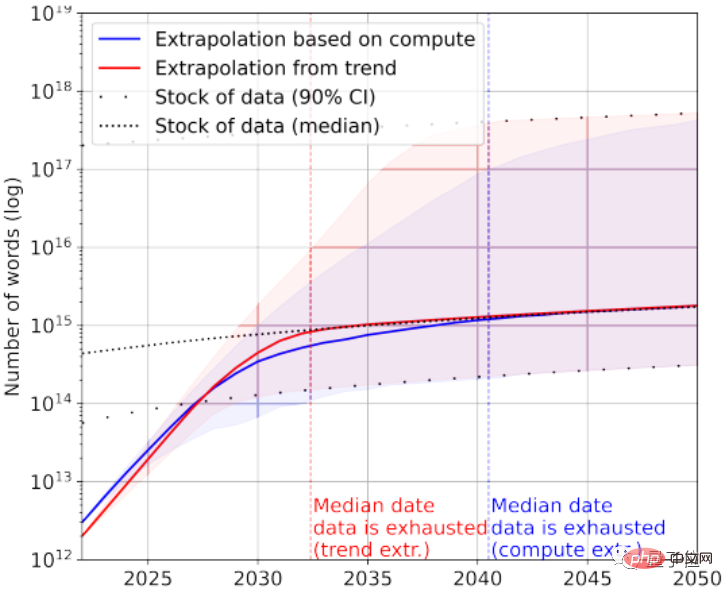
Natürlich können zur Rettung auch Textdaten von geringer Qualität hinzugefügt werden. Laut Statistik sind derzeit noch 7×10^13~7×10^16 Wörter im Gesamtbestand an Textdaten übrig, was 1,5–4,5 Größenordnungen größer ist als der größte Datensatz.
Wenn die Anforderungen an die Datenqualität nicht hoch sind, wird die KI zwischen 2030 und 2050 alle Textdaten verbrauchen.
Wenn man sich die Bilddaten noch einmal ansieht, unterscheidet das Papier hier nicht zwischen Bildqualität.
Der größte Bilddatensatz umfasst derzeit 3×10^9 Bilder.
Laut Statistik beträgt die aktuelle Gesamtzahl der Bilder etwa 8,11×10^12~2,3×10^13, was 3~4 Größenordnungen größer ist als der größte Bilddatensatz.
Das Papier prognostiziert, dass der KI zwischen 2030 und 2070 diese Bilder ausgehen werden.
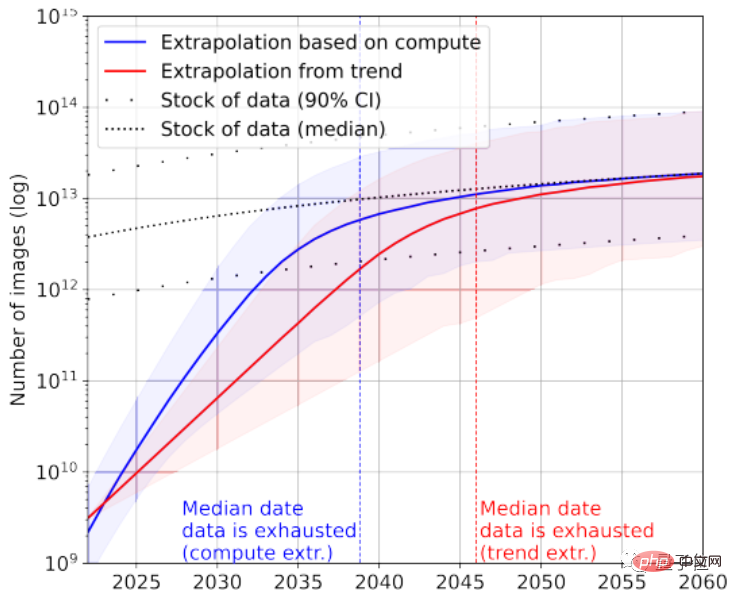
Offensichtlich sind große Sprachmodelle mit einer schwerwiegenderen Situation des „Datenmangels“ konfrontiert als Bildmodelle.
Wie kam man also zu dieser Schlussfolgerung?
Berechnen Sie die durchschnittliche tägliche Anzahl der von Internetnutzern geposteten Beiträge.
Der Artikel analysiert die Effizienz der Textbilddatengenerierung und das Wachstum des Trainingsdatensatzes aus zwei Perspektiven.
Es ist erwähnenswert, dass es sich bei den Statistiken im Papier nicht ausschließlich um gekennzeichnete Daten handelt. Da unbeaufsichtigtes Lernen relativ beliebt ist, sind auch unbeschriftete Daten enthalten.
Nehmen Sie als Beispiel Textdaten. Die meisten Daten werden von sozialen Plattformen, Blogs und Foren generiert.
Um die Geschwindigkeit der Textdatengenerierung abzuschätzen, müssen drei Faktoren berücksichtigt werden, nämlich die Gesamtbevölkerung, die Internetdurchdringungsrate und die durchschnittliche Datenmenge, die von Internetnutzern generiert wird.
Dies ist beispielsweise der geschätzte zukünftige Bevölkerungs- und Internetnutzerwachstumstrend basierend auf historischen Bevölkerungsdaten und der Anzahl der Internetnutzer:
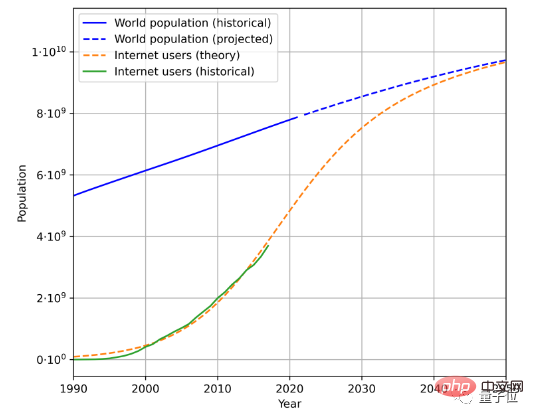
In Kombination mit der durchschnittlichen Datenmenge, die von Benutzern generiert wird, kann die Datengenerierungsrate ermittelt werden berechnet werden. (Aufgrund komplexer geografischer und zeitlicher Änderungen vereinfacht das Papier die Berechnungsmethode für die durchschnittliche Datenmenge, die von Benutzern generiert wird.)
Nach dieser Methode wird berechnet, dass die Wachstumsrate der Sprachdaten etwa 7 % beträgt, aber dieses Wachstum Die Rate wird mit der Zeit allmählich sinken.
Es wird erwartet, dass die Wachstumsrate unserer Sprachdaten bis zum Jahr 2100 auf 1 % sinken wird.
Eine ähnliche Methode wird zur Analyse von Bilddaten verwendet. Die Wachstumsrate der Bilddaten wird sich jedoch bis 2100 ebenfalls auf etwa 1 % verlangsamen.
Das Papier geht davon aus, dass, wenn die Datenwachstumsrate nicht signifikant ansteigt oder neue Datenquellen entstehen, sei es ein großes Bild- oder Textmodell, das mit hochwertigen Daten trainiert wird, dies zu einem bestimmten Zeitpunkt zu einem Engpass führen kann.
Einige Internetnutzer scherzten darüber, und in Zukunft könnte so etwas wie eine Science-Fiction-Geschichte passieren:
Um KI zu trainieren, haben Menschen groß angelegte Projekte zur Textgenerierung gestartet, und alle arbeiten hart daran, Dinge für KI zu schreiben.
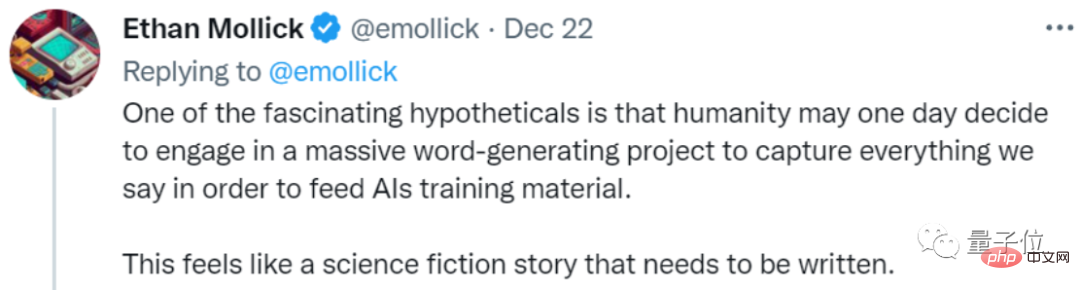
Er nennt es eine Art „Erziehung für KI“:
Wir senden jedes Jahr 140.000 bis 2,6 Millionen Wörter an Textdaten an die KI. Klingt das cooler, als Menschen als Batterien zu verwenden?
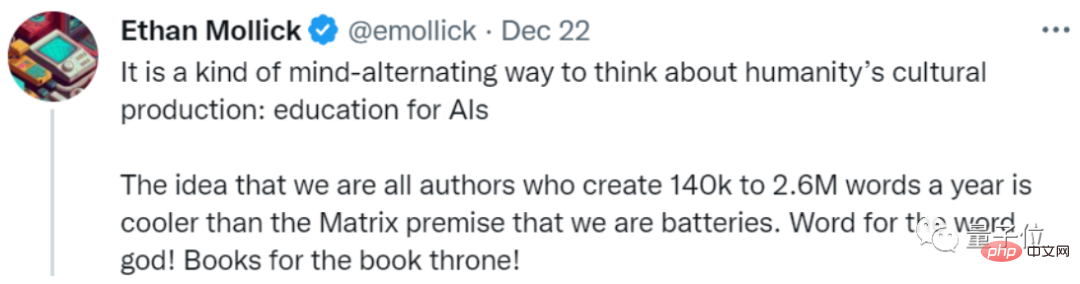
Was meint ihr?
Papieradresse: https://arxiv.org/abs/2211.04325
Referenzlink: https://twitter.com/emollick/status/1605756428941246466
Das obige ist der detaillierte Inhalt vonDer Mensch verfügt nicht über genügend hochwertiges Korpus, damit die KI lernen kann, und er wird im Jahr 2026 erschöpft sein. Netizens: Ein groß angelegtes Projekt zur Generierung menschlicher Texte wurde gestartet!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr