
Heim >Technologie-Peripheriegeräte >KI >Der Aufstieg des GAN-Netzwerks der zweiten Generation? Die Grafiken von DALL·E Mini sind so gruselig, dass Ausländer verrückt werden!
Der Aufstieg des GAN-Netzwerks der zweiten Generation? Die Grafiken von DALL·E Mini sind so gruselig, dass Ausländer verrückt werden!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-15 23:52:01793Durchsuche
Heutzutage sind die textbasierten Diagrammmodelle von Google, OpenAI und anderen großen Unternehmen das Lebenselixier interessanter Nachrichtenreporter und der Nektar einer langen Durststrecke für Meme-Liebhaber. Durch die Eingabe von Wörtern können Sie verschiedene schöne oder lustige Bilder erstellen, die die Aufmerksamkeit der Menschen auf sich ziehen, ohne ermüdend oder lästig zu sein. Daher haben die DALL·E-Reihe und Imagens die wesentlichen Eigenschaften von Nahrungsmitteln und Kleidung sowie langanhaltender Dürre: Sie sind nur begrenzt verfügbar und keine jederzeit unbegrenzt verteilbaren Güter. Mitte Juni 2022 stellte Hugging Face Company die benutzerfreundliche und einfache Version der DALL·E-Schnittstelle: DALL·E Mini allen Benutzern im gesamten Netzwerk kostenlos zur Verfügung. Es überrascht nicht, dass dies eine weitere große Welle auf diversen Plattformen auslöste Social-Media-Websites.

DALL·E Mini-Kreationstrend: sowohl lustig als auch gruselig
#🎜 🎜 # Heutzutage sagen Leute in verschiedenen sozialen Medien: Das Spielen von DALL·E Mini macht eine Weile Spaß und es macht auch weiterhin Spaß. Was soll ich tun, wenn ich überhaupt nicht aufhören kann? Wie „Kacken auf einem Skateboard“, Reibung und Reibung, wie das Tempo des Teufels. 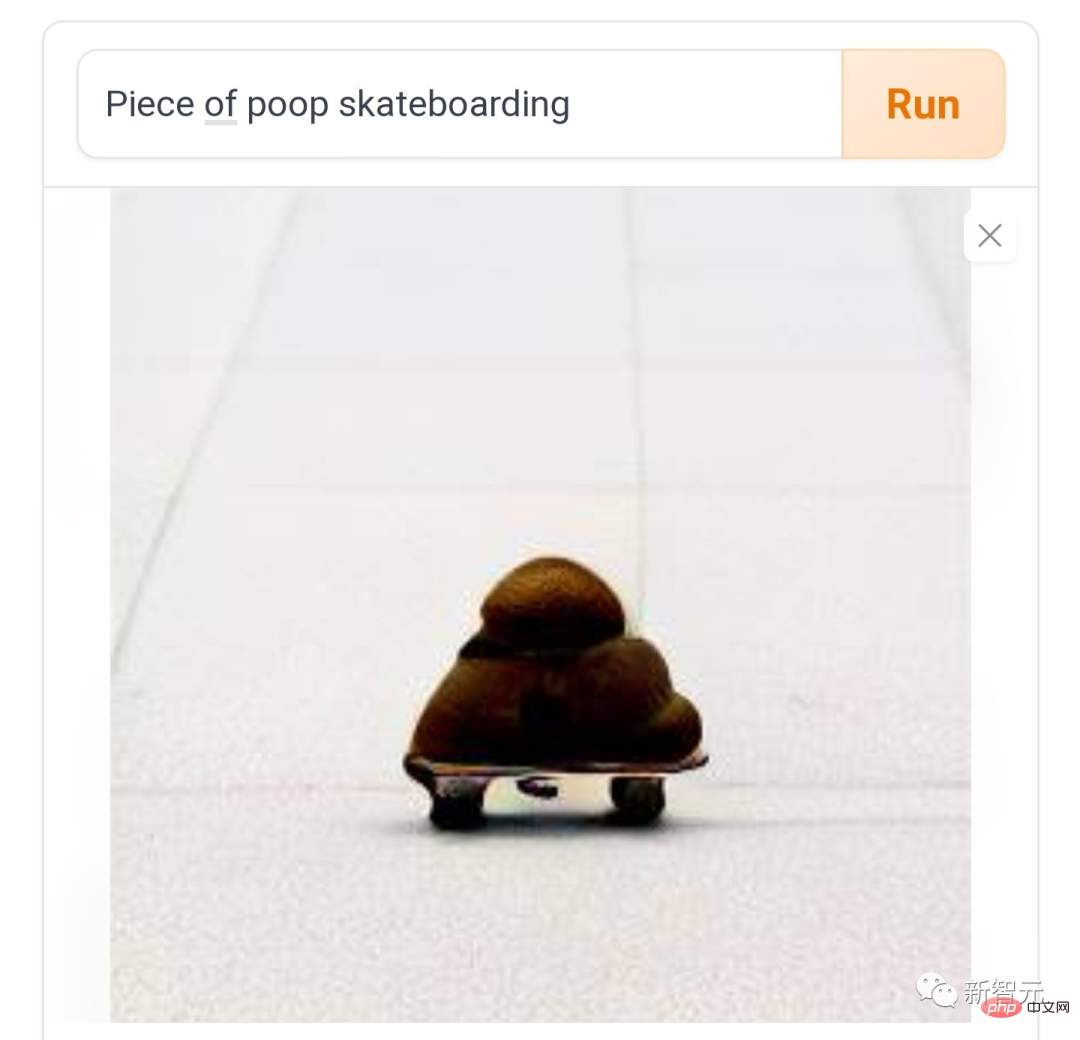
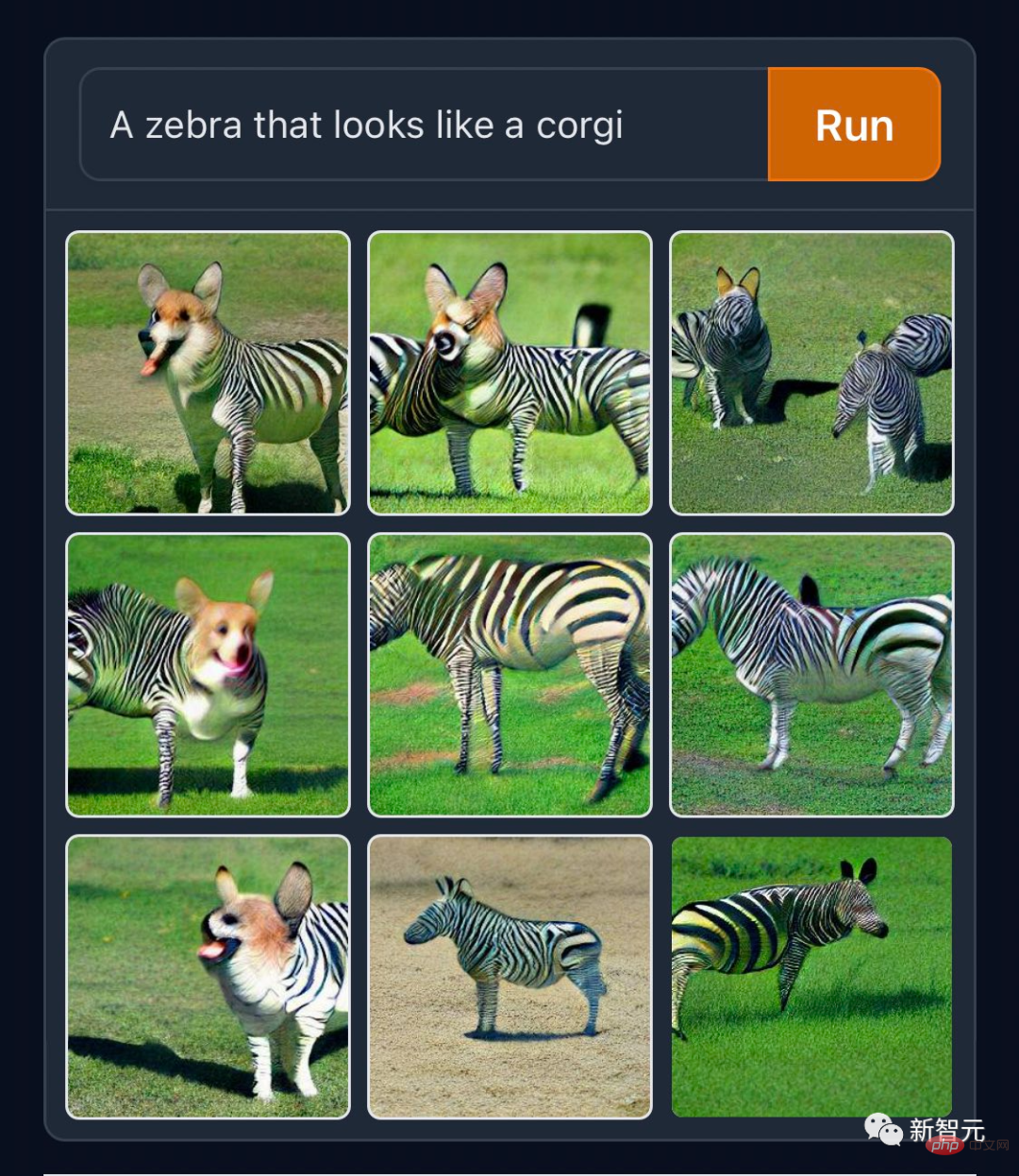
Wenn die alten Beamten diese Materialien hätten, müssten sie nicht so hart arbeiten, um die afrikanische Giraffe in das mythische Tier zu erfinden Kirin. Die Programmierer bei GitHub sind ihrem Beruf treu und haben ein generiertes Werk zum Thema „Squirrel Programming with Computers“ auf dem offiziellen Twitter gepostet.

„Godzillas Gerichtsskizze“, ich muss sagen, es ähnelt wirklich der Skizzenstil von Prozessberichten, die in englischsprachigen Zeitungen und Zeitschriften nicht der Öffentlichkeit zugänglich sind.

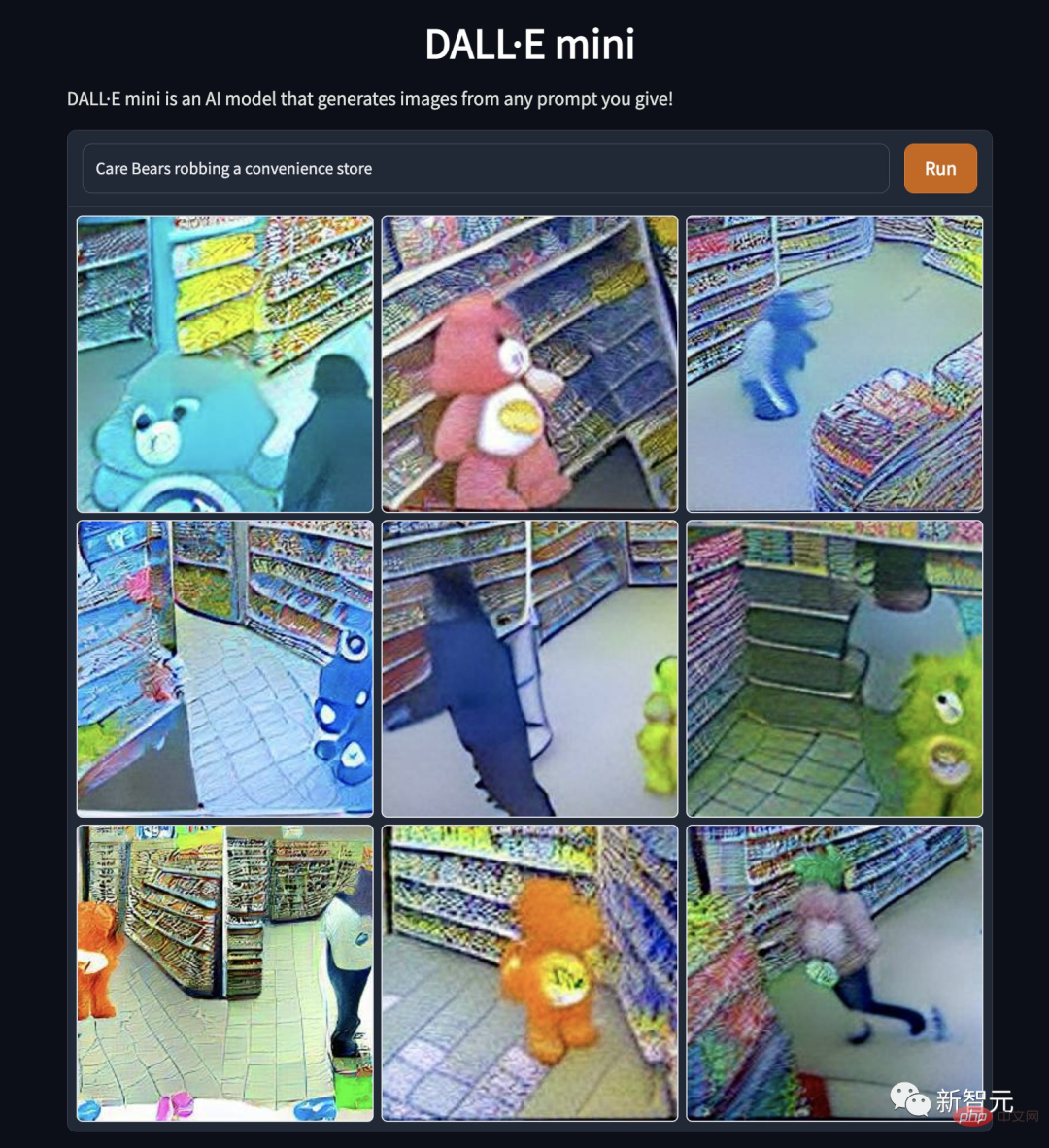
„Care Bears rauben Supermarkt aus“. Warum sind Cartoon-Idole so gefallen? Liegt es an der Verzerrung der Bärennatur oder am Verlust der Moral ... beim Wandern auf wilden Pfaden festgehalten. Dabei handelt es sich um „einen kleinen Dinosaurier, der auf einer wilden Spur läuft, aufgenommen mit der Kamera.“ #? vor der Kamera."
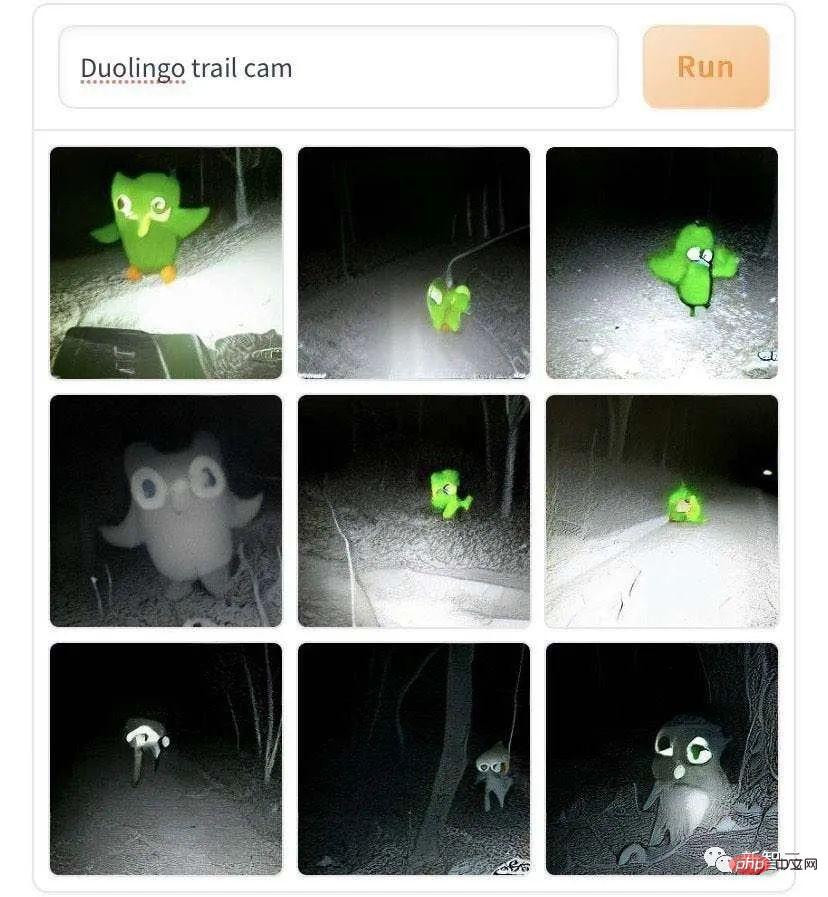
Erstellt von DALL·E Mini Auf diesen Bildern von wandelnden Fabelwesen sind die hinteren Figuren so einsam und trostlos. Dies könnte jedoch auf den von der KI simulierten Low-Light-Fotografie-Effekt zurückzuführen sein. Auch alle in der Redaktion machten es nach: „Auf Gras- und Schlammpferden über die Straße gehen“, und der Ton wurde immer heller.

Die von DALL·E Mini erzeugten Bilder von Göttern und Menschen sind Nr besser als die Bilder von Fabelwesen Unterschied. Bei diesem Bild von „Jesus‘ feurigem Breakdance“ zum Beispiel wusste ich wirklich nicht, dass sein Körper so flexibel ist. Es scheint, dass die „Stretching with the Lord“-Werbung auf verschiedenen Fitness-Websites einen Grund hat. Es gibt auch diese „Farbe“. „Der Rapper Gou Ye auf dem Glas“ hat wirklich den Stil einer Kirchenikonenscheibe und eines impressionistischen Gemäldes.
Mit DALL·E Mini Charaktere in der Film- und Fernsehbranche fälschen ist mittlerweile auch in der Mode beliebt. Das Folgende ist „R2D2's Baptism“ aus dem Star Wars-Universum. Vielleicht unterscheiden sich die Gesetze der Physik und Chemie im Star Wars-Universum von denen in der realen Welt. Roboter verlieren weder Strom noch rosten sie, wenn sie Wasser ausgesetzt werden.

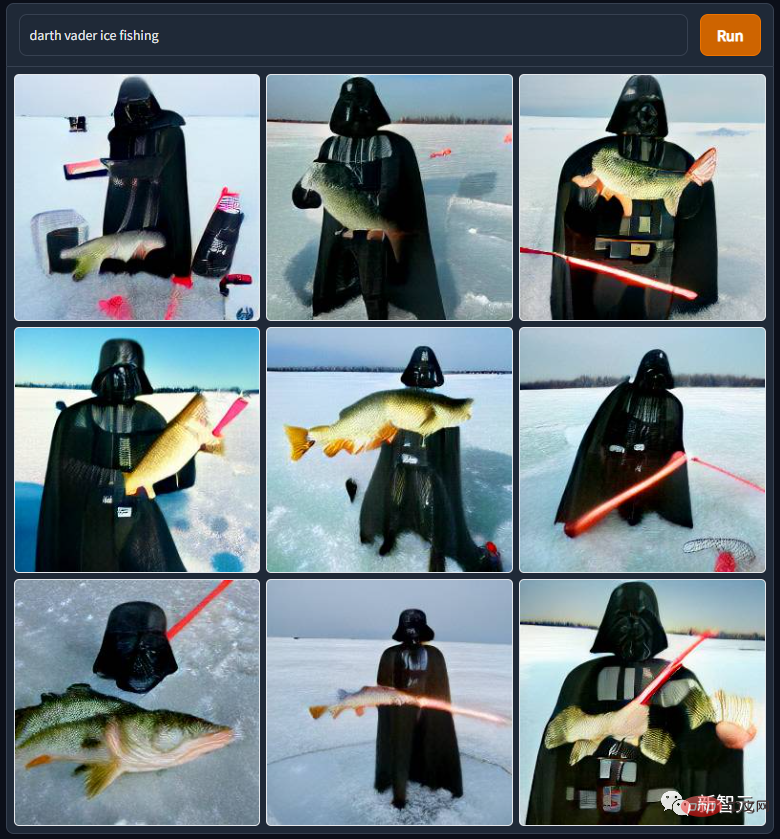
„Darth Vader Ice Fishing“ stammt ebenfalls aus dem Star Wars-Universum. Mr. Darth Vader ist wirklich miserabel. Er wurde von seinem Herrn niedergehauen und gezwungen, in der Lava eines Vulkans zu baden. Nachdem er ein behinderter Mensch geworden war, wurde er von seinem eigenen Sohn verfolgt um mit den Eskimos ums Geschäft zu konkurrieren...
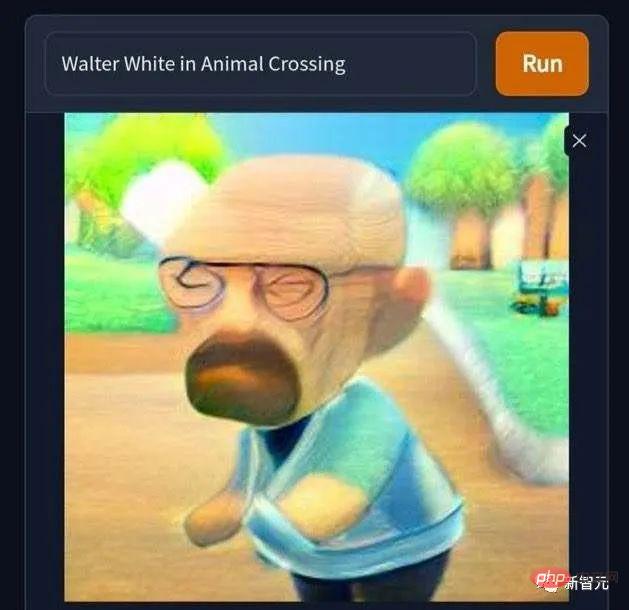
Da ist auch dieses Bild von „Walter White betritt versehentlich die Welt von Animal Crossing“. Der kahlköpfige, einsame und verzweifelte Drogenboss wird plötzlich süß . Es ist schade, dass Nintendo Animal Crossing in den 2000er Jahren nicht wirklich auf den Markt gebracht hat, sonst hätte ich festgestellt, dass das Geldverdienen durch virtuelle Transaktionen in Animal Crossing viel problemloser und problemloser war, als hart daran zu arbeiten, blaues Eis in physischer Form herzustellen Waren, um meine Familie zu unterstützen. Lasst uns singen: „Lehne Pornografie ab, lehne Drogen ab, lehne Pornografie, Glücksspiel und Drogen ab.“
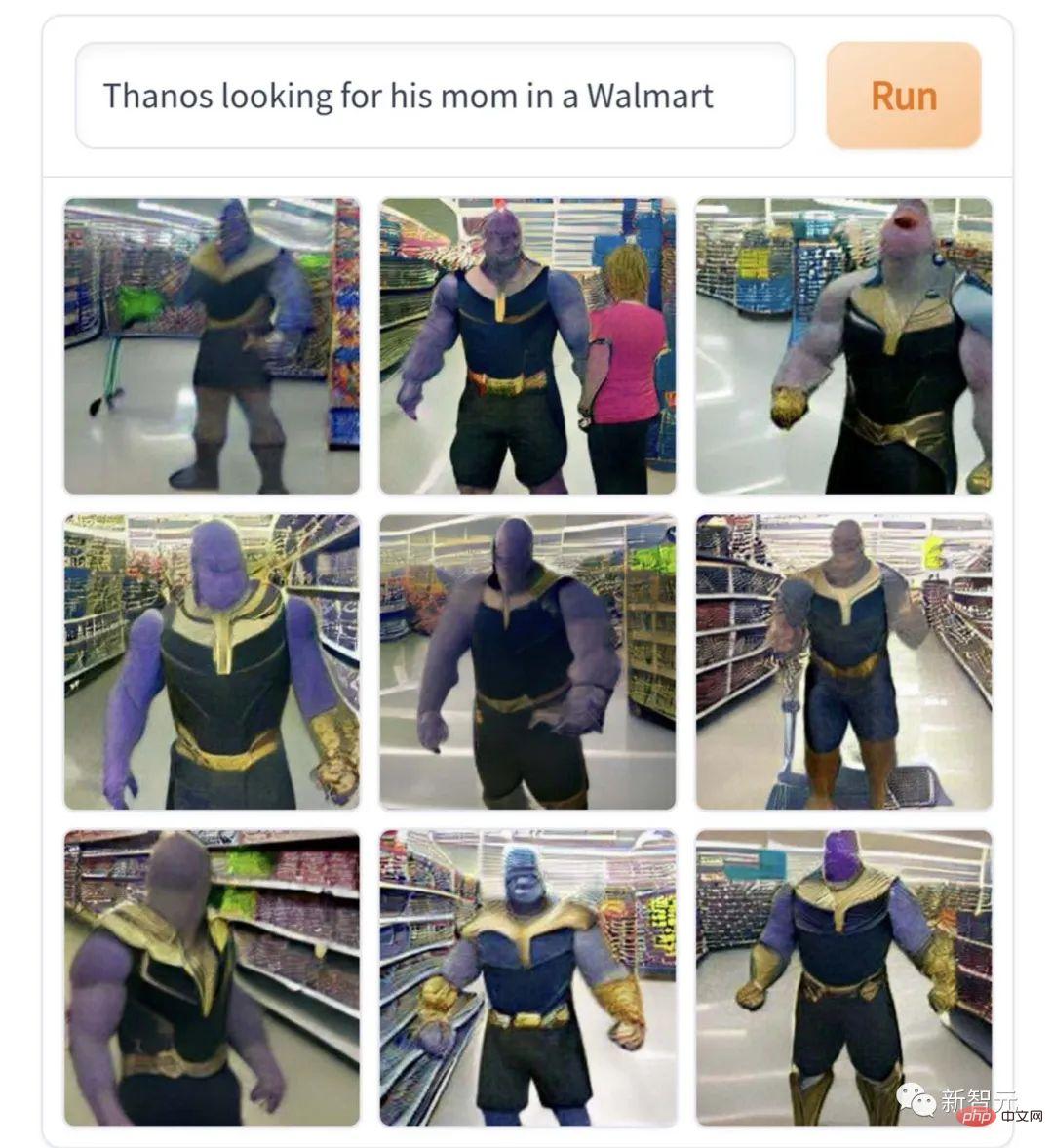
Dieses Bild von „Thanos sucht im Supermarkt nach seiner Mutter“ passt wirklich zum Kern der Figur und ist eine sehr professionelle Interpretation des Dramas. Wenn Sie unglücklich sind, werden Sie einen Völkermord begehen, und wenn Sie nicht einverstanden sind, werden Sie das Universum zerstören. Dies ist die Figur eines riesigen Babys, das bitterlich weint, wenn es seine Mutter nicht finden kann.
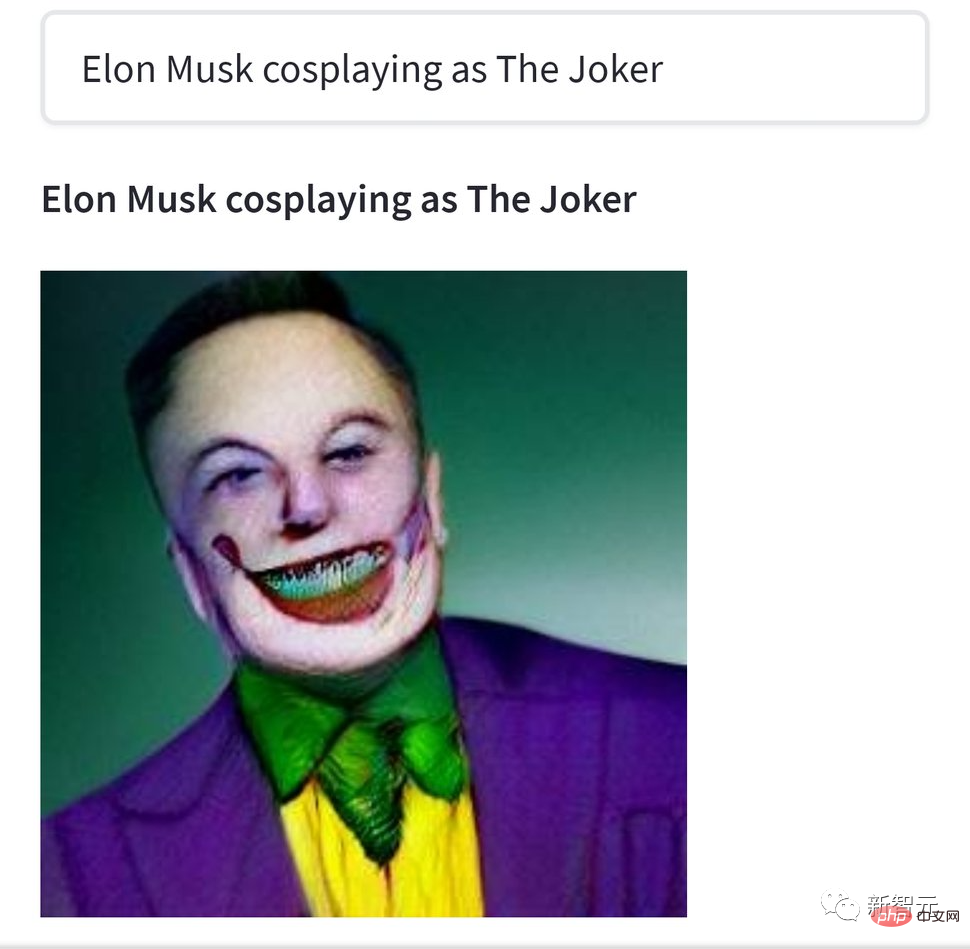
Allerdings sind diese Kreationen alle leicht im Geschmack, verglichen mit den Werken von Cthulhu-Enthusiasten mit starkem Geschmack, einfach nur wässrig. Zum Beispiel ist dieses Bild „Elon Musk spielt den Cracked Clown“ etwas gruselig.
„Der Teufel spielt Basketball“ traute sich der Redakteur wirklich nicht, die Sendung „Stranger Things“ weiter zu verfolgen.
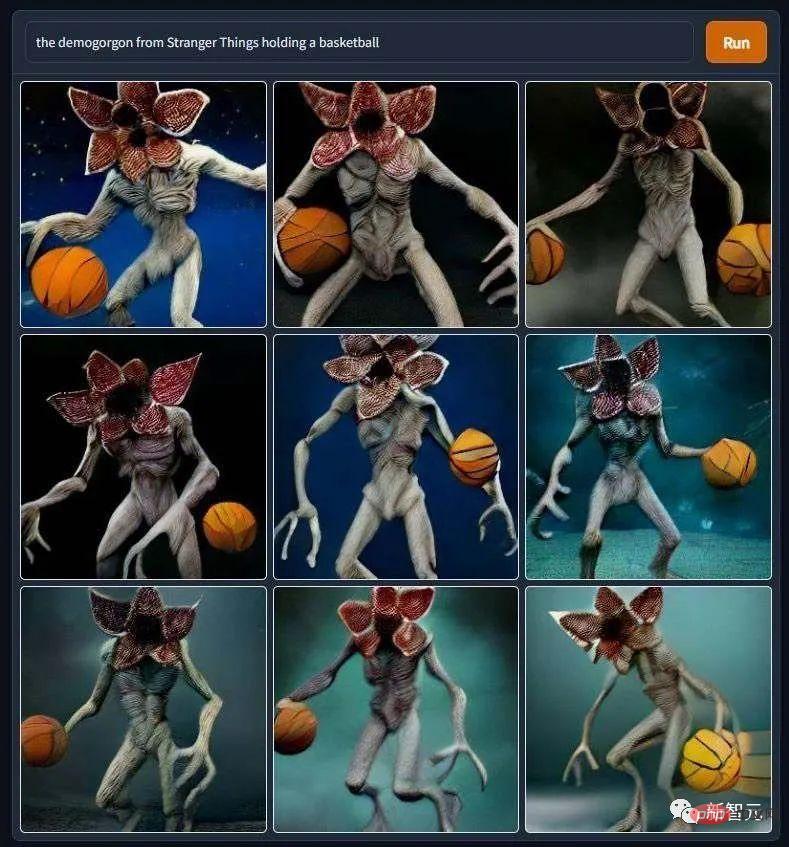
Die Protagonisten verschiedener Horrorfilmreihen sind ebenfalls in Arbeit, wie beispielsweise dieser „Masked Jason Devil Eats. Burrito“

und dieses hier „A Nightmare on Elm Street Killer Eats Pasta“ ... das Muster ist so gruselig, dass es den Redakteur an die grünen Tage erinnert, als er diese Horrorfilme im DVD-Zeitalter sah und bis zur Panik Angst hatte.

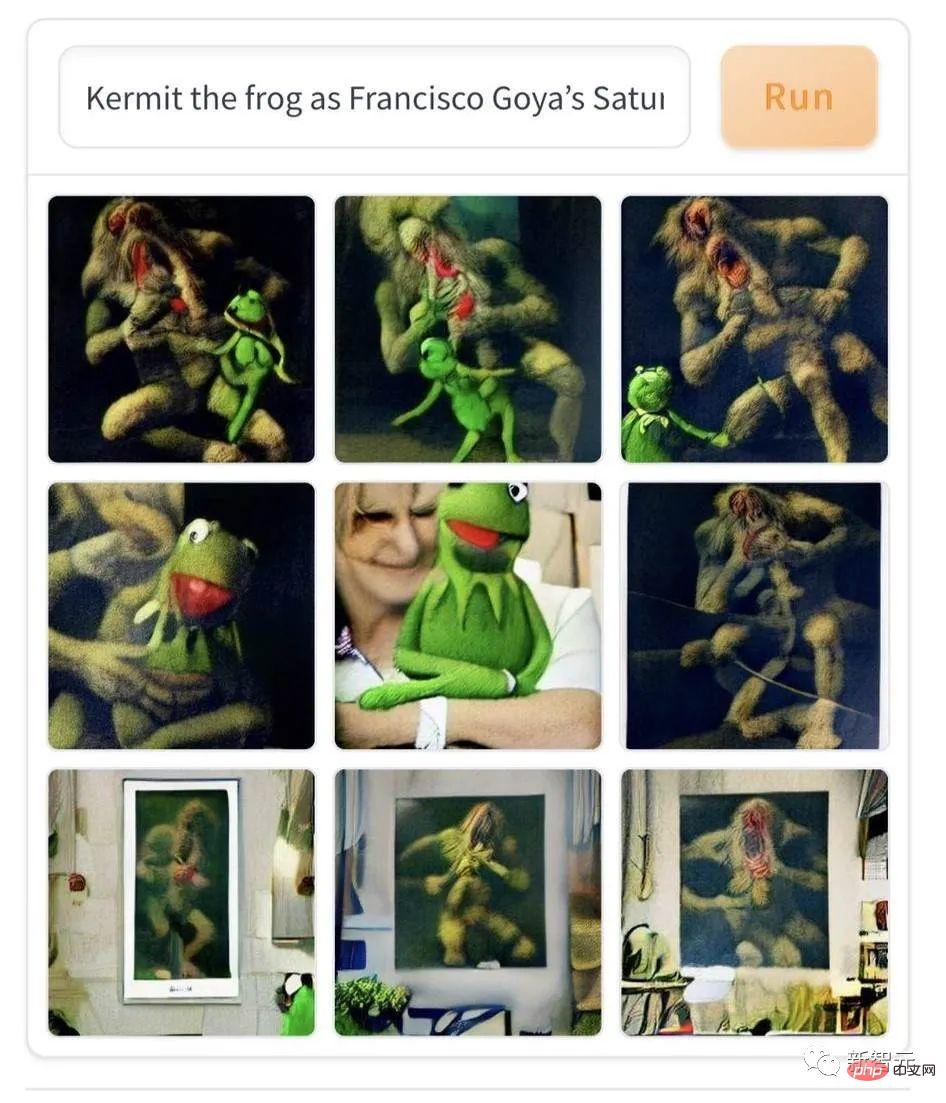
Allerdings sind zeitgenössische Populärliteratur und Kunst der klassischen Kunst etwas unterlegen, wenn es darum geht, Menschen Angst zu machen, wie zum Beispiel dieses Stück „Komi Frog Photogenic in Goyas „Torma“-Ölgemälde.“ AI kombiniert zeitgenössische Cartoons mit expressionistischen Ölgemälden des 19. Jahrhunderts, was jedem, der es zum ersten Mal sieht, Angst und Schrecken einjagen kann.
Es gibt auch dieses Bild „Der Tod klickt auf die goldenen Bögen“. Werden Sie es wagen, in Zukunft zu spät zur Arbeit und zur Schule zu kommen?

Demo hat nur 60 Zeilen Code!
Natürlich werden Leser, die aufmerksam sind und die Dynamik der DALL·E-Serie verfolgen, feststellen, dass es offensichtliche Unterschiede in den von DALL·E Mini und den vorherigen DALL·E-Großmodellen generierten Bildern gibt: In den von DALL·E generierten Porträts ·E Mini, Die Gesichter sind verschwommener als die ursprünglich von DALL·E generierten. Boris Dayma, der Hauptentwickler des DALL·E Mini-Projekts, erklärte in den Entwicklungsnotizen: Dies ist eine benutzerfreundliche Version mit reduzierten Spezifikationen. Die Demo umfasst nur 60 Codezeilen und es ist normal, dass die Funktionen schwach sind .
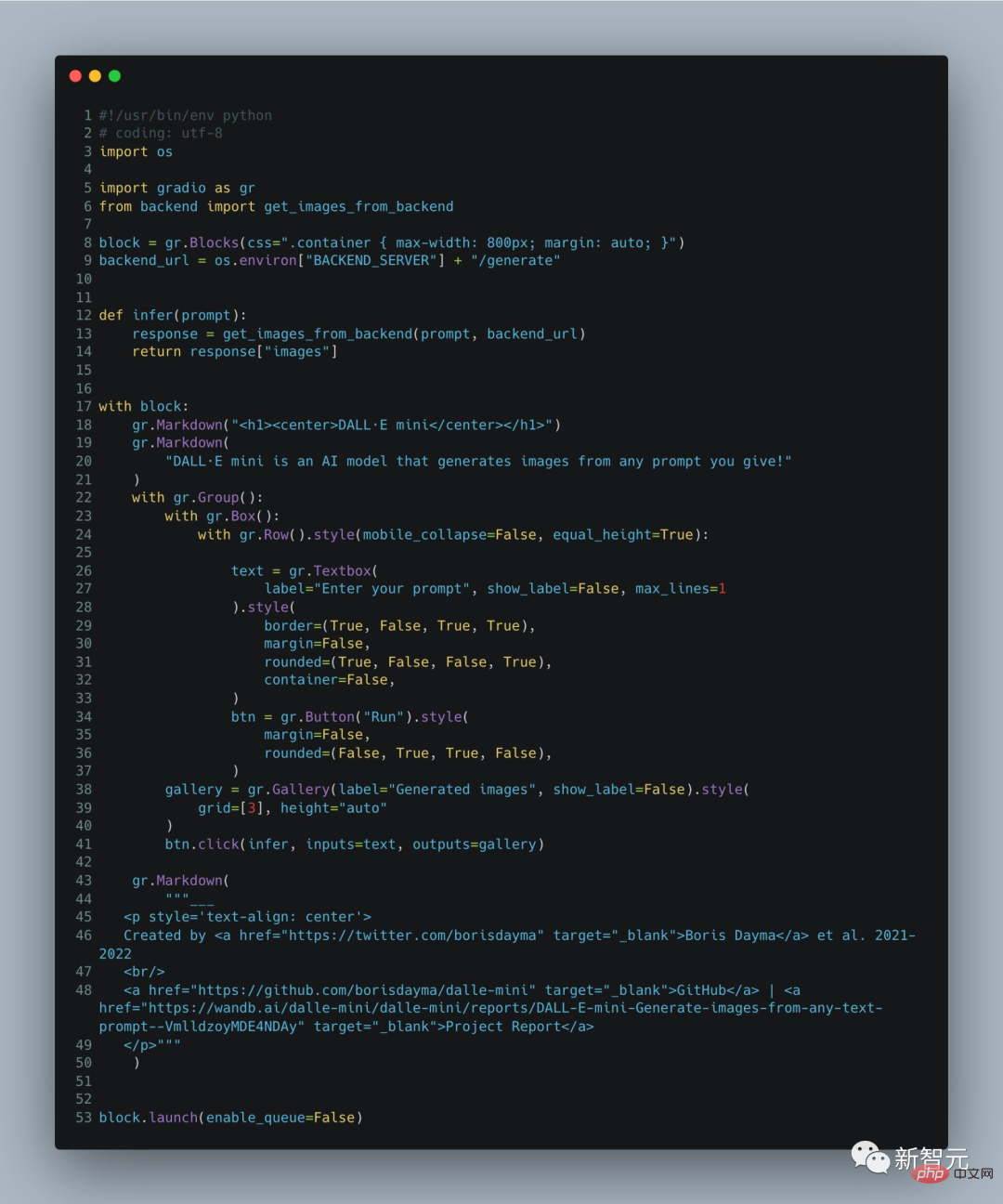
Das Folgende ist Boris Daymas Erklärung des Projekts in seinen Notizen. Schauen wir uns zunächst die konkrete Umsetzung des Projekts an. Basierend auf dem Text werden entsprechende Bilder generiert:
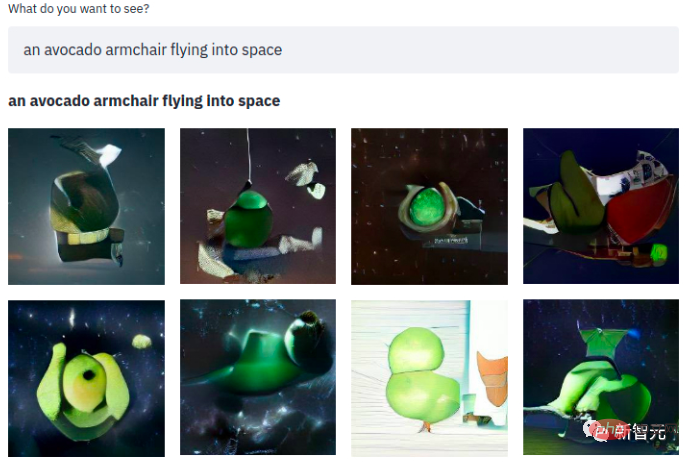
Ein einfacher Satz, und was folgt, ist ein Avocado-Sessel, der in den Weltraum blitzt. Das Modell verwendet drei Datensätze:
1. „Conceptual Captions Dataset“ mit 3 Millionen Bildern und Bildunterschriftenpaaren; „YFCC100M“ enthält etwa 15 Millionen Bilder. Aus Speicherplatzgründen hat der Autor jedoch 2 Millionen Bilder weiter heruntergerechnet. Verwenden Sie Titel und Textbeschreibungen gleichzeitig als Tags und löschen Sie entsprechende HTML-Tags, Zeilenumbrüche und zusätzliche Leerzeichen
3.
In der Trainingsphase:
1. Zuerst wird das Bild vom VQGAN-Encoder codiert, um das Bild in eine Token-Sequenz umzuwandeln.
2 der BART-Encoder;
3, die Ausgabe des BART-Encoders und das vom VQGAN-Encoder kodierte Sequenz-Token werden zusammen an den BART-Dekodierer gesendet. Der Dekoder ist ein autoregressives Modell und sein Zweck besteht darin, die nächste Token-Sequenz vorherzusagen.
4. Die Verlustfunktion ist der Kreuzentropieverlust, der zur Berechnung des Verlustwerts zwischen dem vom Modell vorhergesagten Bildcodierungsergebnis und der realen VQGAN-Bildcodierung verwendet wird.
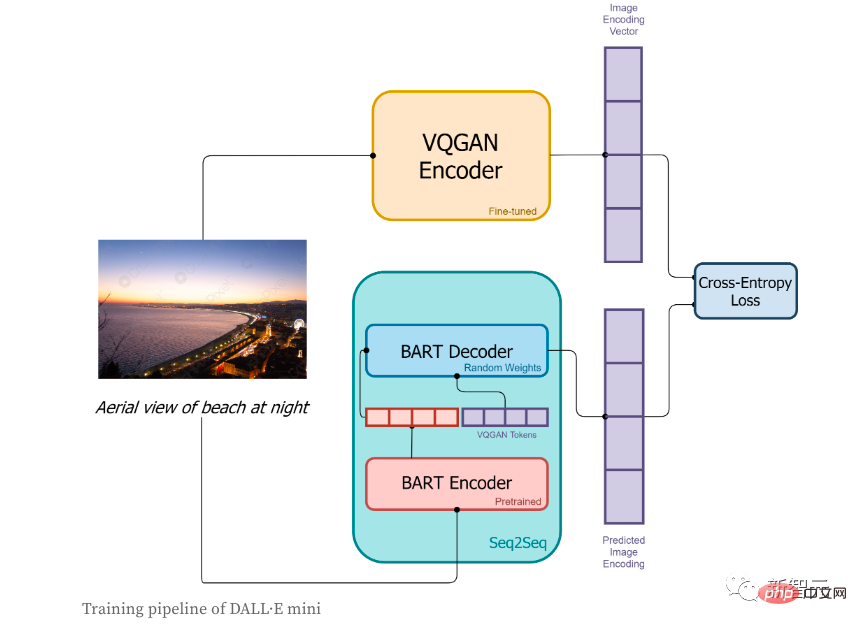 In der Inferenzphase hat der Autor nur kurze Etiketten verwendet und versucht, die entsprechenden Bilder zu generieren. Der spezifische Prozess ist wie folgt:
In der Inferenzphase hat der Autor nur kurze Etiketten verwendet und versucht, die entsprechenden Bilder zu generieren. Der spezifische Prozess ist wie folgt:
1. Die Etiketten werden über den BART-Encoder codiert.
Start eins Das spezielle Sequenzflag, das Startflag, wird an den BART-Decoder gesendet
3 Basierend auf der vom BART-Decoder vorhergesagten Verteilung werden die Bildtoken der Reihe nach abgetastet; Die Bild-Token-Sequenz wird zur Dekodierung an den VQGAN-Decoder gesendet.
Als nächstes werfen wir einen Blick auf die Funktionsweise des VQGAN-Bild-Encoders und -Decoders. Das Transformer-Modell muss jedem bekannt sein. Seit seiner Geburt dominiert es nicht nur den NLP-Bereich, sondern auch das Faltungs-CNN-Netzwerk im CV-Bereich. Der Zweck des Autors bei der Verwendung von VQGAN besteht darin, das Bild in eine diskrete Token-Sequenz zu kodieren, die direkt im Transformer-Modell verwendet werden kann. Aufgrund der Verwendung von Pixelwertsequenzen wird der Einbettungsraum diskreter Werte zu groß, was es letztendlich extrem schwierig macht, das Modell zu trainieren und den Speicherbedarf der Selbstaufmerksamkeitsschicht zu erfüllen.
VQGAN lernt ein „Codebuch“ von Pixeln durch die Kombination von Wahrnehmungsverlust und diskriminierendem GAN-Verlust. Der Encoder gibt den Indexwert aus, der dem „Codebuch“ entspricht. Da das Bild in einer Token-Sequenz codiert ist, kann es in jedem Transformer-Modell verwendet werden. In diesem Modell kodiert der Autor Bilder aus einem Vokabular der Größe 16.384 in diskrete „16x16=256“-Token, wobei er einen Komprimierungsfaktor von f=16 verwendet (die Breite und Höhe von 4 Blöcken werden jeweils durch 2 geteilt). Das dekodierte Bild ist 256 x 256 (16 x 16 auf jeder Seite). Weitere Informationen zu VQGAN finden Sie unter „Taming Transformers for High-Resolution Image Synthesis“. 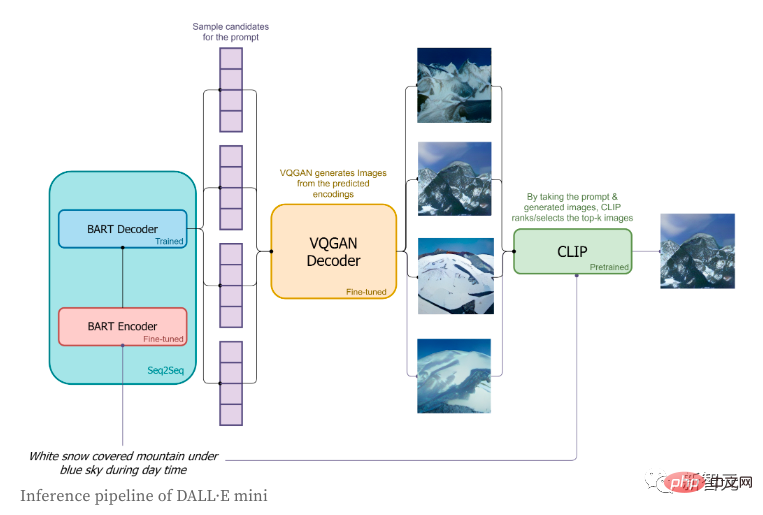
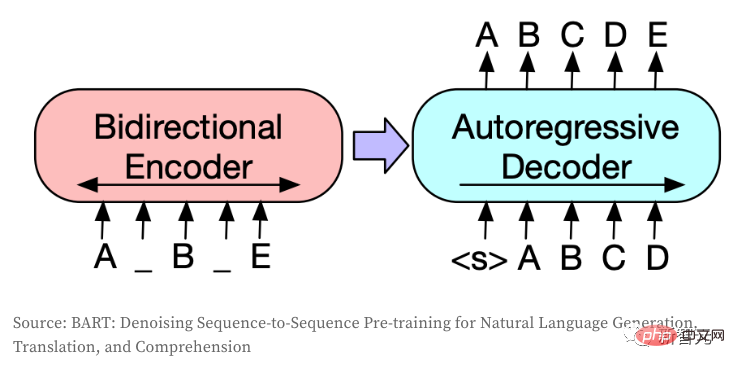
Das Seq2Seq-Modell wandelt eine Token-Sequenz in eine andere Token-Sequenz um und wird im NLP normalerweise für Aufgaben wie Übersetzung, Zusammenfassung oder Dialogmodellierung verwendet. Die gleiche Idee lässt sich auch auf das CV-Feld übertragen, wenn Bilder in diskrete Token kodiert werden. Dieses Modell verwendet BART, und der Autor hat gerade die ursprüngliche Architektur verfeinert:
1 Erstellt eine unabhängige Einbettungsschicht für den Encoder und den Decoder (die beiden können normalerweise gemeinsam genutzt werden, wenn es denselben Ein- und Ausgabetyp gibt) ;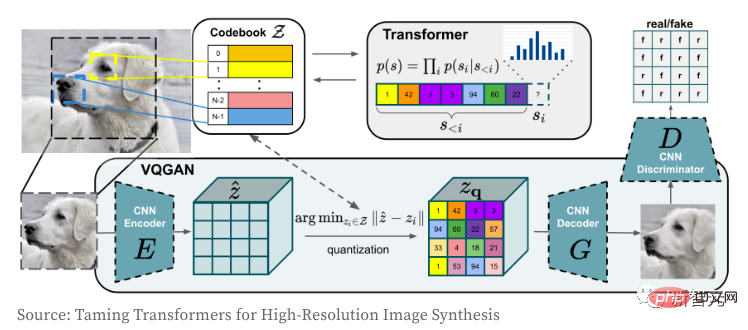
und
), die den Anfang und das Ende der Sequenz markieren.
Wie schneidet CLIP im Vergleich zu OpenAI DALL·E ab? Nicht alle Details zu DAL sind der Öffentlichkeit bekannt, aber hier sind laut Autor die Hauptunterschiede:
1. DALL·E verwendet die 12-Milliarden-Parameter-Version von GPT-3. Im Vergleich dazu ist das Modell des Autors 27-mal größer und verfügt über etwa 400 Millionen Parameter.
2. Der Autor nutzt in großem Umfang vorab trainierte Modelle (VQGAN, BART-Encoder und CLIP), während OpenAI alle Modelle von Grund auf trainieren muss. Die Modellarchitektur berücksichtigt die verfügbaren vorab trainierten Modelle und deren Effizienz.
3. DALL·E kodiert Bilder mit einer größeren Anzahl von Token (1.024 vs. 256) aus einem kleineren Vokabular (8.192 vs. 16.384).
4. DALL·E verwendet VQVAE, während der Autor VQGAN verwendet. DALL·E liest Text und Bilder als einen einzigen Datenstrom, wenn die Autoren zwischen Seq2Seq-Encoder und -Decoder aufteilen. Dies ermöglicht ihnen auch die Verwendung eines separaten Vokabulars für Text und Bilder.
5. DALL·E liest Text mithilfe eines autoregressiven Modells, während der Autor einen bidirektionalen Encoder verwendet.
6. DALL·E hat 250 Millionen Bild- und Textpaare trainiert, während der Autor nur 15 Millionen Paare verwendet hat. von.
7. DALL·E verwendet weniger Token (bis zu 256 vs. 1024) und ein kleineres Vokabular (16384 vs. 50264), um Text zu kodieren. Beim Training von VQGAN begann der Autor zunächst mit dem vorab trainierten Prüfpunkt auf ImageNet mit einem Komprimierungsfaktor von f = 16 und einer Vokabulargröße von 16.384. Obwohl der vorab trainierte Prüfpunkt beim Kodieren einer breiten Palette von Bildern sehr effizient ist, eignet er sich nicht gut zum Kodieren von Personen und Gesichtern (da beides in ImageNet nicht üblich ist). Daher hat der Autor beschlossen, ihn auf einer 2 x RTX A6000-Cloud-Instanz zu testen 20 Stunden Feintuning. Es ist offensichtlich, dass sich die Qualität des erzeugten Bildes auf dem menschlichen Gesicht nicht wesentlich verbessert hat und es sich möglicherweise um einen „Modellkollaps“ handelt. Sobald das Modell trainiert ist, konvertieren wir das Pytorch-Modell zur Verwendung in der nächsten Stufe in JAX.
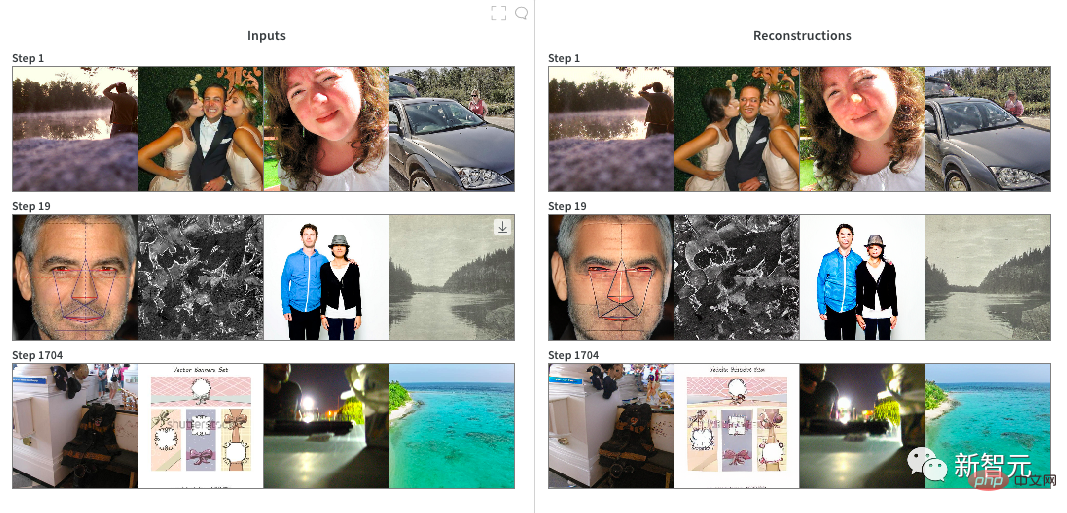
Training DALL·E Mini: Dieses Modell nutzt JAX-Programmierung und nutzt die Vorteile von TPU voll aus. Der Autor kodiert alle Bilder mit einem Bildkodierer vor, um das Laden der Daten zu beschleunigen. Während des Trainings hat der Autor schnell mehrere nahezu realisierbare Parameter ermittelt:
1. Bei jedem Schritt beträgt die Batchgröße jeder TPU, was dem maximal verfügbaren Speicher für jede TPU entspricht.
2 beträgt 56 × 8 TPU-Chips × 8 Schritte = 3.584 Bilder pro Update
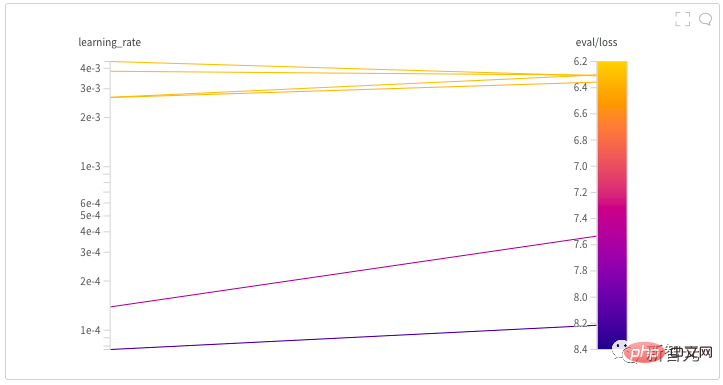
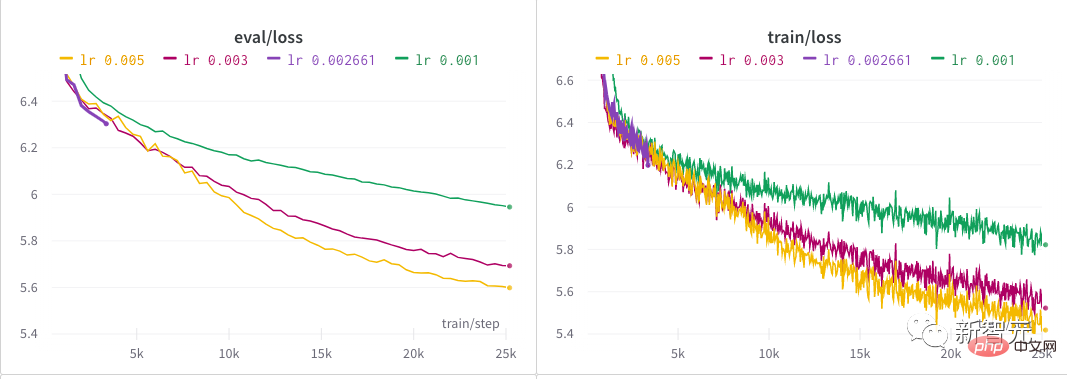
3 zerfällt linear. Der Autor verbrachte fast einen halben Tag damit, eine gute Lernrate für das Modell zu finden, indem er eine Hyperparametersuche startete. Hinter jedem NB-Modell steckt wahrscheinlich ein mühsamer Prozess der Suche nach Hyperparametern! Nach der anfänglichen Erkundung durch den Autor wurden über einen längeren Zeitraum mehrere unterschiedliche Lernraten ausprobiert, bis sie sich schließlich bei 0,005 einpendelten.
Das obige ist der detaillierte Inhalt vonDer Aufstieg des GAN-Netzwerks der zweiten Generation? Die Grafiken von DALL·E Mini sind so gruselig, dass Ausländer verrückt werden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr