
Heim >Technologie-Peripheriegeräte >KI >Die Harvard University hat es vermasselt: DALL-E 2 ist nur ein „Klebermonster' und die Genauigkeit seiner Erzeugung beträgt nur 22 %
Die Harvard University hat es vermasselt: DALL-E 2 ist nur ein „Klebermonster' und die Genauigkeit seiner Erzeugung beträgt nur 22 %

- WBOYnach vorne
- 2023-04-15 17:40:031203Durchsuche
Als DALL-E 2 zum ersten Mal veröffentlicht wurde, konnten die generierten Bilder den Eingabetext nahezu perfekt reproduzieren. Die hochauflösende Auflösung und die starke Zeichenphantasie führten auch dazu, dass verschiedene Internetnutzer es als „zu cool“ bezeichneten.

Eine neue Forschungsarbeit der Harvard University zeigt jedoch, dass die von DALL-E 2 erzeugten Bilder zwar exquisit sind, aber möglicherweise mehrere Elemente im Text zusammenkleben, ohne die räumliche Beziehung auszudrücken!

Papierlink: https://arxiv.org/pdf/2208.00005.pdf
Datenlink: https://osf.io/sm68h/
Eine Textaufforderung wird beispielsweise als „Eine Tasse“ angegeben Auf einem Löffel können Sie sehen, dass unter den von DALL-E 2 generierten Bildern einige Bilder die „Ein“-Beziehung nicht erfüllen.
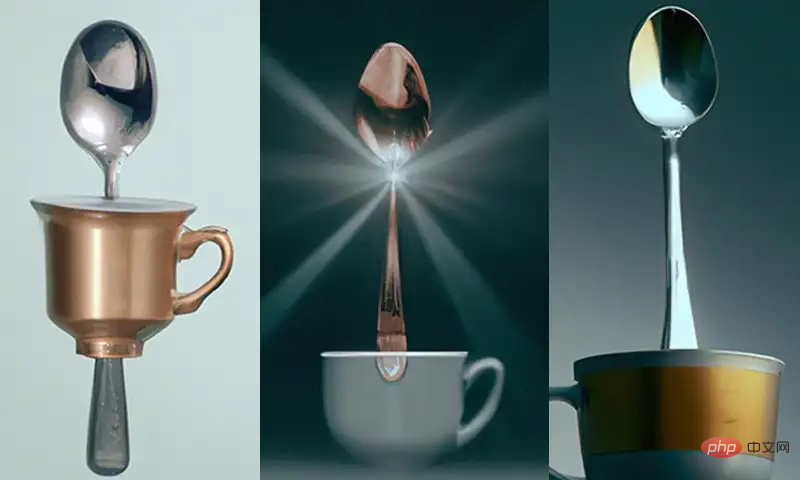
Aber im Trainingssatz sind die Kombinationen von Teetassen und Löffeln, die DALL-E 2 möglicherweise sieht, alle „in“, während „ein“ relativ selten vorkommt, sodass die Genauigkeit beim Generieren der beiden Beziehungen nicht gleich ist . Nicht dasselbe.

Um zu untersuchen, ob DALL-E 2 die semantischen Beziehungen im Text wirklich verstehen kann, wählten die Forscher 15 Arten von Beziehungen aus, von denen 8 räumliche Beziehungen (physische Beziehungen) sind, darunter „in“, „on“, „under“. , bedeckend, in der Nähe, verdeckt durch, hängend und gebunden an; 7 Agentenbeziehungen, einschließlich Stoßen, Ziehen, Berühren, Schlagen, Treten, Helfen und Verstecken
Die im Text festgelegte Entität ist auf 12 beschränkt, ausgewählt. Sie sind alle einfache und allgemeine Elemente in jedem Datensatz, nämlich: Schachtel, Zylinder, Decke, Schüssel, Teetasse, Messer; Mann, Frau, Kind, Roboter, Affe und Leguan.

Erstellen Sie für jede Klassenbeziehung 5 Eingabeaufforderungen nach dem Zufallsprinzip Wählen Sie jedes Mal 2 Entitäten zum Ersetzen aus und generieren Sie schließlich 75 Textaufforderungen. Nach der Übermittlung an die DALL-E 2-Rendering-Engine wurden die ersten 18 generierten Bilder ausgewählt, was 1350 Bilder ergab.
Dann wählten die Forscher 169 von 180 Annotatoren durch einen Test zum gesunden Menschenverstand aus, um am Annotationsprozess teilzunehmen.
Experimentelle Ergebnisse ergaben, dass die durchschnittliche Konsistenz zwischen den von DALL-E 2 generierten Bildern und den zur Generierung der Bilder verwendeten Textaufforderungen nur 22,2 % von 75 Eingabeaufforderungen betrug
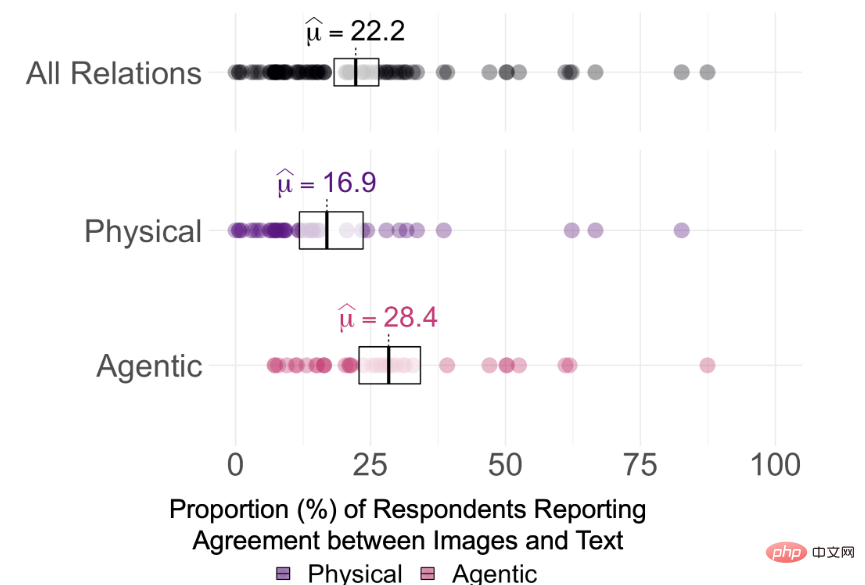
Aber es ist schwer zu sagen, was DALL-E 2 ist Ob die Beziehung im Text wirklich „verstanden“ wird, wird durch Beobachtung der Konsistenzwerte der Annotatoren und der Holm-korrigierten Einzelstichprobensignifikanz jeder Beziehung basierend auf den Konsensschwellenwerten von 0 %, 25 % und 50 % bestimmt. Der Test zeigt, dass die Zustimmungsraten der Teilnehmer für alle 15 Beziehungen bei α = 0,95 (pHolm
Fakt ist also, dass das von DALL-E 2 generierte Bild die Beziehung zwischen den beiden Objekten im Text auch ohne Korrektur mehrerer Vergleiche nicht versteht.
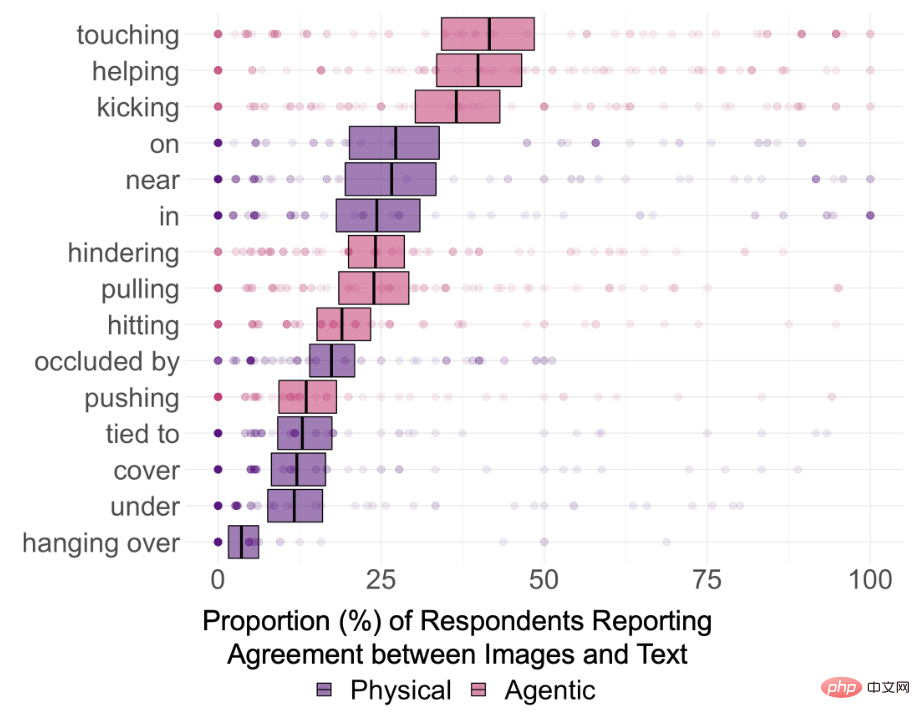
Die Ergebnisse zeigen auch, dass die Fähigkeit von DALL-E, zwei nicht miteinander verbundene Objekte zu verbinden, möglicherweise nicht so stark ist wie angenommen. Beispielsweise erreichte die Konsistenz von „Ein Kind berührt eine Schüssel“ 87 %, weil in der realen Welt Bilder, Kinder und Schalen kommen recht häufig zusammen vor.

Allerdings beträgt die endgültige Konsistenzrate des von „Ein berührender Affe und Leguan“ erzeugten Bildes nur 11 %, und es können sogar Artenfehler im gerenderten Bild auftreten.

Daher sind einige Bildkategorien in DALL-E 2 relativ gut entwickelt, wie z. B. Kinder und Lebensmittel, einige Datenkategorien erfordern jedoch noch weiteres Training.
Allerdings zeigt DALL-E 2 derzeit hauptsächlich seinen hochauflösenden und realistischen Stil auf der offiziellen Website an. Es ist noch nicht klar, ob es „zwei Objekte zusammenklebt“ oder ob es die Textinformationen tatsächlich versteht, bevor Bilder generiert werden. .
Forscher gaben an, dass relationales Verständnis ein grundlegender Bestandteil der menschlichen Intelligenz ist, und die schlechte Leistung von DALL-E 2 in grundlegenden räumlichen Beziehungen (z. B. auf, von) deutet darauf hin, dass es noch nicht in der Lage ist, so flexibel und robust zu konstruieren und zu konstruieren wie Menschen . Die Welt verstehen.
Allerdings sagten Internetnutzer, dass die Fähigkeit, „Kleber“ zum Zusammenkleben von Dingen zu entwickeln, bereits eine große Leistung sei! DALL-E 2 ist kein AGI und es gibt noch viel Raum für Verbesserungen in der Zukunft. Zumindest haben wir die Tür zur automatischen Generierung von Bildern geöffnet!
DALL-E 2 Was ist sonst noch los?
Tatsächlich führten zahlreiche Praktiker unmittelbar nach der Veröffentlichung von DALL-E 2 eine eingehende Analyse seiner Vor- und Nachteile durch.

Blog-Link: https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot -do
Das Schreiben von Romanen mit GPT-3 ist etwas eintönig. DALL-E 2 kann einige Illustrationen für den Text und sogar Comics für lange Texte generieren.
Zum Beispiel kann DALL-E 2 Funktionen zu Bildern hinzufügen, wie zum Beispiel „Eine Frau in einem Coffeeshop, die an ihrem Laptop arbeitet und Kopfhörer trägt, malt von Alphonse Mucha“ und kann Malstile präzise generieren, Cafés, Kopfhörer, Laptop usw. tragen.

Aber wenn die Funktionsbeschreibung im Text zwei Personen betrifft, vergisst DALL-E 2 möglicherweise, welche Funktionen zu welcher Person gehören, zum Beispiel die Eingabe Der Text lautet:
ein junger dunkelhaariger Junge, der im Bett ruht, und eine grauhaarige ältere Frau, die auf einem Stuhl neben dem Bett unter einem Fenster sitzt, durch das die Sonne scheint, digitale Kunst im Pixar-Stil.#🎜 🎜#
Ein junger dunkelhaariger Junge liegt auf dem Bett und eine alte grauhaarige Frau sitzt auf einem Stuhl neben dem Bett unter dem Fenster, durch das Sonnenlicht scheint, Digitale Kunst im Pixar-Stil.

#🎜🎜 ##🎜 🎜#
Zwei Hunde blicken durch ein Fernglas auf New York City wie römische Soldaten auf einem Piratenschiff. Diesmal hat DALL-E 2 einfach aufgehört zu arbeiten und konnte es nicht herausfinden. Am Ende musste er in „New York City“ spielen Piratenschiff“ oder „mit Teleskop und römischer Soldatenuniform“. Wählen Sie zwischen „Hunden“. Dall-E 2 kann Bilder mit einem generischen Hintergrund erstellen, beispielsweise einer Stadt oder einem Bücherregal in einer Bibliothek. Wenn dies jedoch nicht der Hauptfokus des Bildes ist, ist es oft schwierig, die feineren Details zu erhalten Problem. Es ist sehr schwierig. Obwohl DALL-E 2 gängige Objekte wie verschiedene schicke Stühle erzeugen kann, sieht das resultierende Bild ein wenig wie ein Fahrrad aus, wenn Sie es auffordern, ein „Alto-Fahrrad“ zu erzeugen, aber nicht genau . . Und die Otto-Fahrradsuche unter Google Bilder sieht wie folgt aus. 
DALL-E 2 kann ebenfalls nicht buchstabieren, schreibt aber gelegentlich ein Wort durch völligen Zufall richtig, beispielsweise wenn es auf einem Stoppschild steht STOP
Bei der Generierung von Bildern im Zusammenhang mit Musikinstrumenten scheint sich DALL-E 2 an die Position der menschlichen Hand beim Spielen zu erinnern, jedoch ohne Saiten beim Spielen scheint ein wenig peinlich zu sein. 
DALL-E 2 bietet auch eine Bearbeitungsfunktion. Nach dem Erstellen eines Bildes können Sie beispielsweise den Cursor verwenden, um dessen Bereich hervorzuheben und Änderungen hinzuzufügen vollständig. Einfach erklären. 
Die Technologie wird immer noch aktualisiert und weiterentwickelt, wir freuen uns auf DALL-E 3! 
Das obige ist der detaillierte Inhalt vonDie Harvard University hat es vermasselt: DALL-E 2 ist nur ein „Klebermonster' und die Genauigkeit seiner Erzeugung beträgt nur 22 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr