
Heim >Technologie-Peripheriegeräte >KI >Überblick über Ensemble-Methoden beim maschinellen Lernen
Überblick über Ensemble-Methoden beim maschinellen Lernen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-15 13:52:071123Durchsuche
Stellen Sie sich vor, Sie kaufen online ein und finden zwei Geschäfte, die dasselbe Produkt mit derselben Bewertung verkaufen. Allerdings wurde die erste von nur einer Person bewertet und die zweite von 100 Personen. Welcher Bewertung würden Sie mehr vertrauen? Für welches Produkt werden Sie sich am Ende entscheiden? Die Antwort ist für die meisten Menschen einfach. Die Meinungen von 100 Menschen sind sicherlich vertrauenswürdiger als die Meinungen von nur einem. Dies wird als „Weisheit der Menge“ bezeichnet und ist der Grund, warum der Ensemble-Ansatz funktioniert.

Ensemble-Methoden
Normalerweise erstellen wir nur einen Lernenden (Lerner = Trainingsmodell) aus den Trainingsdaten (d. h. wir trainieren nur ein maschinelles Lernmodell auf den Trainingsdaten). Die Ensemble-Methode besteht darin, mehrere Lernende das gleiche Problem lösen zu lassen und sie dann miteinander zu kombinieren. Diese Lernenden werden Basislerner genannt und können jeden zugrunde liegenden Algorithmus haben, wie zum Beispiel neuronale Netze, Support-Vektor-Maschinen, Entscheidungsbäume usw. Wenn alle diese Basislerner aus demselben Algorithmus bestehen, werden sie als homogene Basislerner bezeichnet, während sie, wenn sie aus unterschiedlichen Algorithmen bestehen, als heterogene Basislerner bezeichnet werden. Im Vergleich zu einem einzelnen Basislerner verfügt ein Ensemble über bessere Generalisierungsfähigkeiten, was zu besseren Ergebnissen führt.
Wenn die Ensemble-Methode aus schwachen Lernenden besteht. Daher werden grundlegende Lerner manchmal als schwache Lerner bezeichnet. Während Ensemble-Modelle oder starke Lernende (die Kombinationen dieser schwachen Lernenden sind) eine geringere Voreingenommenheit/Varianz aufweisen und eine bessere Leistung erzielen. Die Fähigkeit dieses integrierten Ansatzes, schwache Lernende in starke Lernende umzuwandeln, ist populär geworden, weil schwache Lernende in der Praxis leichter verfügbar sind.
In den letzten Jahren haben integrierte Methoden kontinuierlich verschiedene Online-Wettbewerbe gewonnen. Neben Online-Wettbewerben werden Ensemble-Methoden auch in realen Anwendungen wie Computer-Vision-Technologien wie Objekterkennung, -erkennung und -verfolgung eingesetzt.
Haupttypen von Ensemble-Methoden
Wie werden schwache Lernende generiert?
Je nachdem, wie der Basislerner generiert wird, können Integrationsmethoden in zwei Hauptkategorien unterteilt werden, nämlich sequentielle Integrationsmethoden und parallele Integrationsmethoden. Wie der Name schon sagt, werden bei der Sequential-Ensemble-Methode Basislerner nacheinander generiert und dann kombiniert, um Vorhersagen zu treffen, beispielsweise Boosting-Algorithmen wie AdaBoost. Bei der Parallel-Ensemble-Methode werden die grundlegenden Lernenden parallel generiert und dann zur Vorhersage kombiniert, beispielsweise durch Bagging-Algorithmen wie Random Forest und Stacking. Die folgende Abbildung zeigt eine einfache Architektur, die parallele und sequentielle Ansätze erläutert.
Entsprechend den unterschiedlichen Generierungsmethoden grundlegender Lernender können Integrationsmethoden in zwei Hauptkategorien unterteilt werden: sequentielle Integrationsmethoden und parallele Integrationsmethoden. Wie der Name schon sagt, werden bei der sequentiellen Ensemble-Methode Basislerner der Reihe nach generiert und dann kombiniert, um Vorhersagen zu treffen, beispielsweise Boosting-Algorithmen wie AdaBoost. Bei parallelen Ensemble-Methoden werden Basislerner parallel generiert und dann zur Vorhersage kombiniert, beispielsweise Bagging-Algorithmen wie Random Forest und Stacking. Die folgende Abbildung zeigt eine einfache Architektur, die sowohl parallele als auch sequentielle Ansätze erläutert.
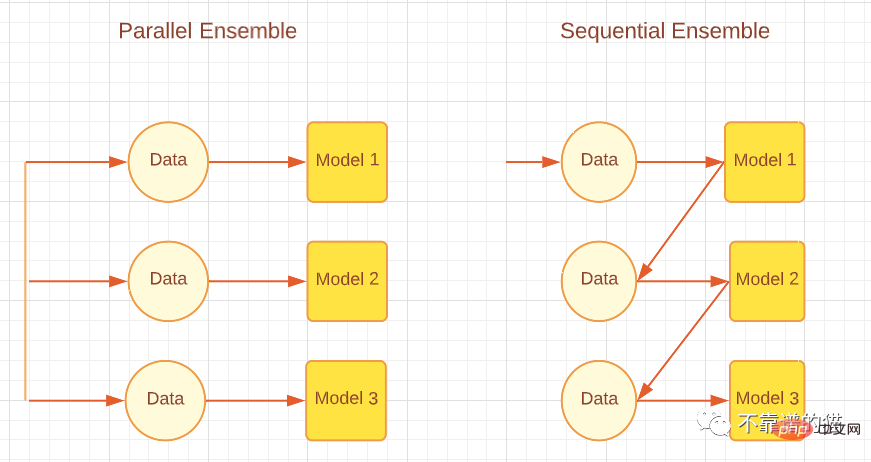
Parallele und sequentielle Integrationsmethoden
Sequentielle Lernmethoden machen sich die Abhängigkeiten zwischen schwachen Lernenden zunutze, um die Gesamtleistung in einer Weise zu verbessern, die den Restwert verringert, sodass spätere Lernende den Fehlern früherer Lernender mehr Aufmerksamkeit schenken können. Grob gesagt (bei Regressionsproblemen) wird die durch Boosting-Methoden erzielte Reduzierung des Ensemble-Modellfehlers hauptsächlich durch die Reduzierung der hohen Voreingenommenheit schwacher Lernender erreicht, obwohl manchmal eine Reduzierung der Varianz beobachtet wird. Andererseits reduziert die Parallel-Ensemble-Methode den Fehler durch die Kombination unabhängiger schwacher Lernender, d. h. sie nutzt die Unabhängigkeit zwischen schwachen Lernenden aus. Diese Fehlerreduzierung ist auf eine Verringerung der Varianz des maschinellen Lernmodells zurückzuführen. Daher können wir zusammenfassen, dass Boosting hauptsächlich Fehler reduziert, indem es die Verzerrung von Modellen für maschinelles Lernen verringert, während Bagging Fehler reduziert, indem es die Varianz von Modellen für maschinelles Lernen verringert. Dies ist wichtig, da die Wahl der Ensemble-Methode davon abhängt, ob die schwachen Lernenden eine hohe Varianz oder eine hohe Voreingenommenheit aufweisen.
Wie kann man schwache Lernende kombinieren?
Nachdem wir diese sogenannten Basislerner generiert haben, wählen wir nicht die besten dieser Lernenden aus, sondern kombinieren sie zur besseren Verallgemeinerung miteinander. Die Art und Weise, wie wir dies tun, spielt im Ensemble-Ansatz eine wichtige Rolle.
Mittelwertbildung: Wenn es sich bei der Ausgabe um eine Zahl handelt, ist die Mittelwertbildung die gebräuchlichste Methode zur Kombination von Basislernern. Der Durchschnitt kann ein einfacher Durchschnitt oder ein gewichteter Durchschnitt sein. Bei Regressionsproblemen ist der einfache Durchschnitt die Summe der Fehler aller Basismodelle geteilt durch die Gesamtzahl der Lernenden. Der gewichtete durchschnittliche kombinierte Output wird erreicht, indem jedem Basislerner unterschiedliche Gewichtungen zugewiesen werden. Bei Regressionsproblemen multiplizieren wir den Fehler jedes Basislerners mit der angegebenen Gewichtung und summieren ihn dann.
Abstimmung: Bei nominalen Ergebnissen ist die Abstimmung die häufigste Methode zur Kombination von Basislernern. Es gibt verschiedene Arten von Abstimmungen wie Mehrheitsabstimmung, Mehrheitsabstimmung, gewichtete Abstimmung und sanfte Abstimmung. Bei Klassifizierungsproblemen gibt eine Supermehrheitsabstimmung jedem Lernenden eine Stimme für eine Klassenbezeichnung. Welches Klassenlabel mehr als 50 % der Stimmen erhält, ist das vorhergesagte Ergebnis des Ensembles. Erhält jedoch kein Klassenlabel mehr als 50 % der Stimmen, besteht eine Ablehnungsmöglichkeit, was bedeutet, dass das kombinierte Ensemble keine Vorhersagen treffen kann. Bei der Abstimmung mit relativer Mehrheit ist die Klassenbezeichnung mit den meisten Stimmen das Vorhersageergebnis, und mehr als 50 % der Stimmen sind für die Klassenbezeichnung nicht erforderlich. Das heißt, wenn wir drei Ausgabebezeichnungen haben und alle drei Ergebnisse von weniger als 50 % erhalten, z. B. 40 % 30 % 30 %, dann ist das Vorhersageergebnis des Ensemblemodells das Erhalten von 40 % der Klassenbezeichnungen. . Bei der gewichteten Abstimmung werden, ebenso wie bei der gewichteten Mittelung, Klassifikatoren Gewichtungen zugewiesen, basierend auf ihrer Wichtigkeit und der Stärke eines bestimmten Lernenden. Soft Voting wird für Klassenausgaben mit Wahrscheinlichkeiten (Werten zwischen 0 und 1) anstelle von Beschriftungen (binär oder anders) verwendet. Soft Voting wird weiter unterteilt in einfaches Soft Voting (ein einfacher Durchschnitt von Wahrscheinlichkeiten) und gewichtetes Soft Voting (den Lernenden werden Gewichte zugewiesen, und die Wahrscheinlichkeiten werden mit diesen Gewichten multipliziert und addiert).
Lernen: Eine andere Möglichkeit zum Kombinieren ist das Lernen, das bei der Stacking-Ensemble-Methode zum Einsatz kommt. Bei diesem Ansatz wird ein separater Lernender, ein sogenannter Meta-Lernender, an einem neuen Datensatz trainiert, um andere Basis-/schwache Lernende zu kombinieren, die aus dem ursprünglichen Datensatz für maschinelles Lernen generiert wurden.
Bitte beachten Sie, dass alle drei Ensemble-Methoden, egal ob Boosting, Bagging oder Stacking, mit homogenen oder heterogenen schwachen Lernenden generiert werden können. Der gebräuchlichste Ansatz besteht darin, homogene schwache Lerner für Bagging und Boosting und heterogene schwache Lerner für Stacking zu verwenden. Die folgende Abbildung bietet eine gute Klassifizierung der drei wichtigsten Ensemble-Methoden.
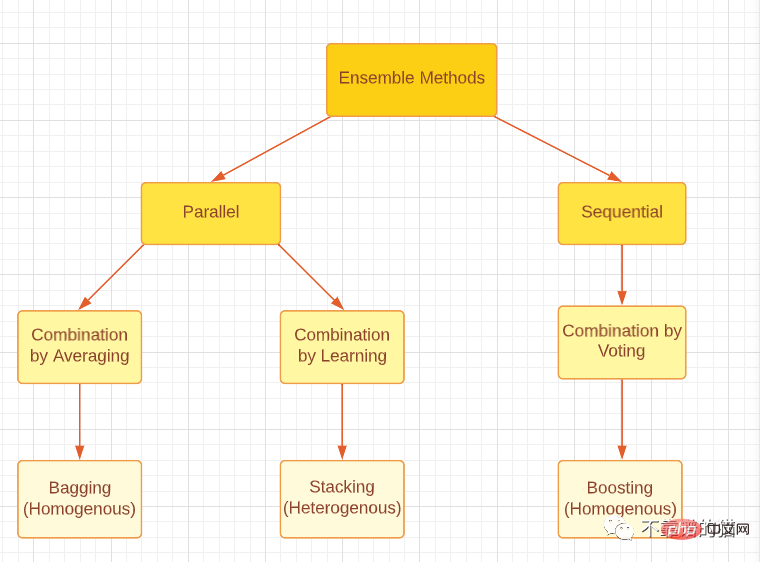
Klassifizieren Sie die wichtigsten Arten von Ensemble-Methoden.
Ensemble-Vielfalt.
Ensemble-Vielfalt bezieht sich darauf, wie unterschiedlich die Basislernenden sind, was für die Generierung guter Ensemble-Modelle von großer Bedeutung ist. Es ist theoretisch erwiesen, dass durch unterschiedliche Kombinationsmethoden völlig unabhängige (diverse) Basislerner Fehler minimieren können, während vollständig (hoch) verwandte Lernende keine Verbesserung bringen. Dies ist im wirklichen Leben ein herausforderndes Problem, da wir allen schwachen Lernenden beibringen, dasselbe Problem mithilfe desselben Datensatzes zu lösen, was zu einer hohen Korrelation führt. Darüber hinaus müssen wir sicherstellen, dass schwache Lernende keine wirklich schlechten Vorbilder sind, da dies sogar zu einer Verschlechterung der Ensembleleistung führen kann. Andererseits ist die Kombination starker und genauer Basislerner möglicherweise nicht so effektiv wie die Kombination einiger schwacher Lernender mit einigen starken Lernenden. Daher muss ein Gleichgewicht zwischen der Genauigkeit des Basislerners und den Unterschieden zwischen den Basislernern hergestellt werden.
Wie erreicht man integrierte Vielfalt?
1. Datenverarbeitung
Wir können unseren Datensatz in Teilmengen für grundlegende Lernende aufteilen. Wenn der Datensatz für maschinelles Lernen groß ist, können wir den Datensatz einfach in gleiche Teile aufteilen und diese in das Modell für maschinelles Lernen einspeisen. Wenn der Datensatz klein ist, können wir eine Zufallsstichprobe mit Ersetzung verwenden, um aus dem ursprünglichen Datensatz einen neuen Datensatz zu generieren. Die Bagging-Methode verwendet die Bootstrapping-Technik, um neue Datensätze zu generieren, bei der es sich im Grunde um eine Zufallsstichprobe mit Ersetzung handelt. Mit Bootstrapping können wir eine gewisse Zufälligkeit erzeugen, da alle generierten Datensätze unterschiedliche Werte haben müssen. Beachten Sie jedoch, dass die meisten Werte (etwa 67 % laut Theorie) immer noch wiederholt werden, sodass die Datensätze nicht vollständig unabhängig sind.
2. Eingabefunktionen
Alle Datensätze enthalten Funktionen, die Informationen über die Daten liefern. Anstatt alle Features in einem Modell zu verwenden, können wir Teilmengen von Features erstellen und verschiedene Datensätze generieren und diese in das Modell einspeisen. Diese Methode wird von der Random-Forest-Technik übernommen und ist effektiv, wenn die Daten eine große Anzahl redundanter Merkmale enthalten. Die Wirksamkeit nimmt ab, wenn der Datensatz nur wenige Features enthält.
3. Lernparameter
Diese Technik erzeugt Zufälligkeit im Basislerner, indem sie verschiedene Parametereinstellungen auf den Basislernalgorithmus anwendet, d. h. Hyperparameter-Tuning. Beispielsweise können durch Änderung der Regularisierungsterme einzelnen neuronalen Netzen unterschiedliche Anfangsgewichte zugewiesen werden.
Integration Pruning
Schließlich kann die Integration Pruning-Technologie in einigen Fällen dazu beitragen, eine bessere Integrationsleistung zu erzielen. Ensemble Pruning bedeutet, dass wir nur eine Teilmenge der Lernenden kombinieren, anstatt alle schwachen Lernenden. Darüber hinaus können kleinere Integrationen Speicher- und Rechenressourcen einsparen und so die Effizienz steigern.
Endlich
Dieser Artikel ist nur ein Überblick über die Ensemble-Methoden des maschinellen Lernens. Ich hoffe, dass jeder eine tiefergehende Recherche durchführen und, was noch wichtiger ist, in der Lage ist, die Forschung auf das wirkliche Leben anzuwenden.
Das obige ist der detaillierte Inhalt vonÜberblick über Ensemble-Methoden beim maschinellen Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr