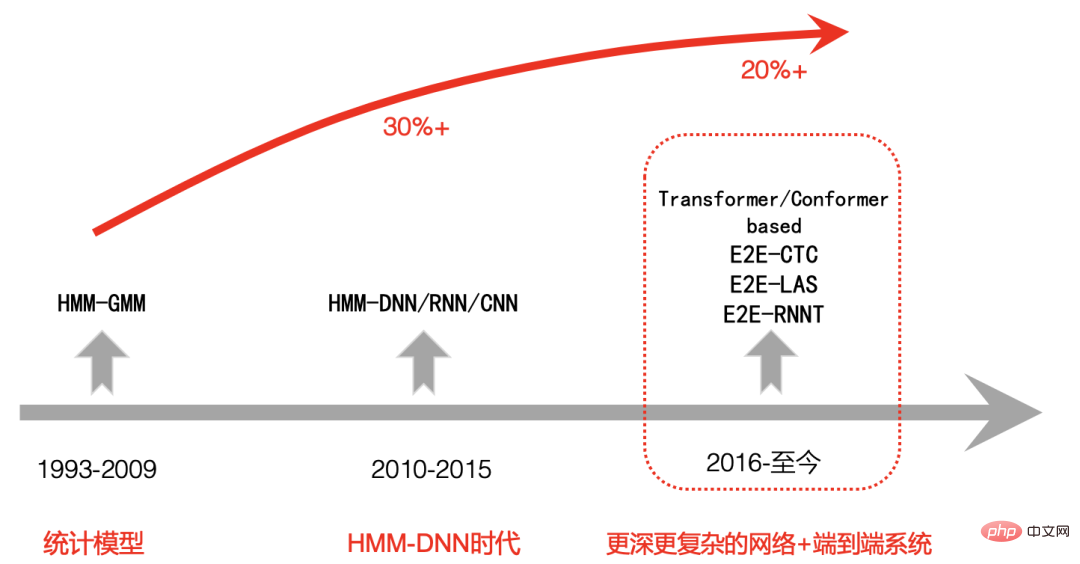
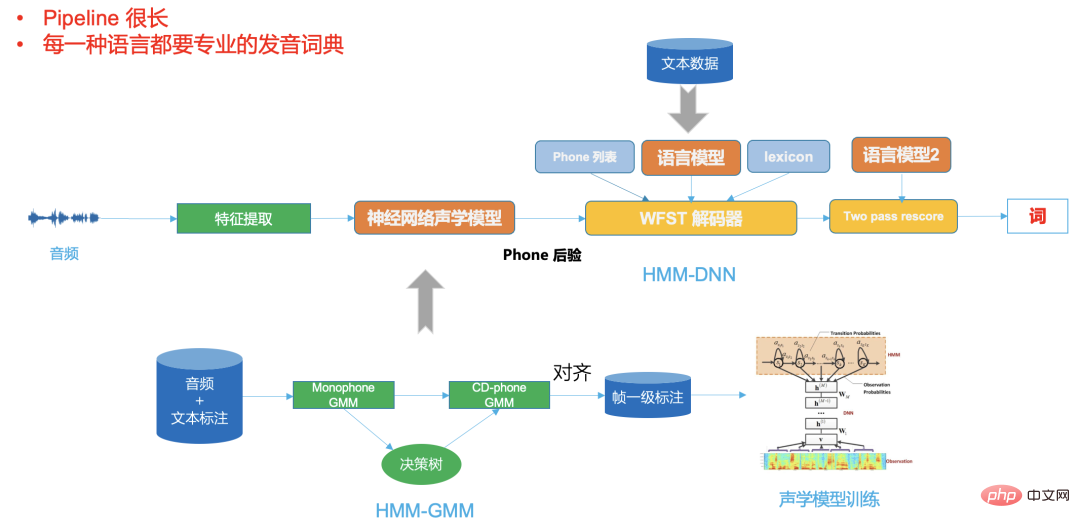
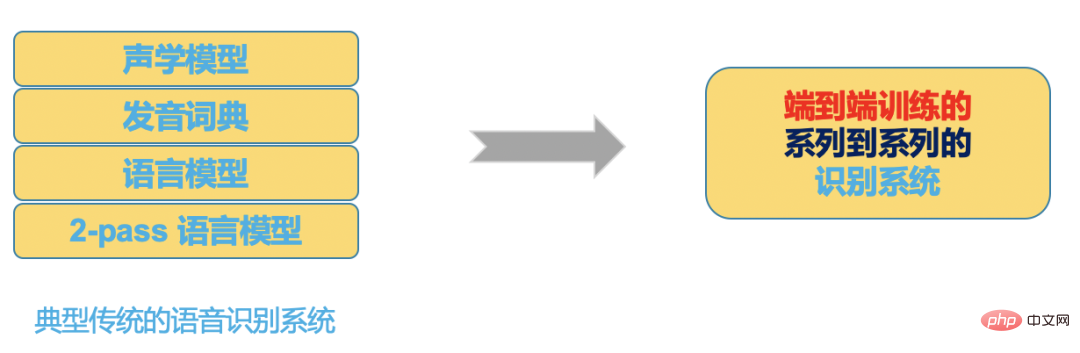
|
Die folgende Tabelle zeigt das optimale Ergebnis (CER) typischer Datensätze basierend auf repräsentativen Tools:
|
Hybrid Framework. (hy Braut) |
End-to-End Framework (E2E) |
steht für Tools |
Kaldi |
Espnet |
steht für Technologie |
tdnn+chain+rnnlm-Rescoring G igaspeech |
14.84 |
10.80 |
aishell-1
|
7.43 |
4.72 |
WenetSpeech |
12.83 |
8.80 |
Kurz gesagt: Durch die Wahl eines End-to-End-Systems können wir im Vergleich zum herkömmlichen Hybrid-Framework mit bestimmten Ressourcen schneller und besser ein qualitativ hochwertiges ASR-System entwickeln.
Natürlich können wir basierend auf dem Hybrid-Framework, wenn wir auch gleichermaßen fortschrittliche Modelle und hochoptimierte Decoder verwenden, Ergebnisse nahezu durchgängig erzielen, aber wir müssen möglicherweise ein Vielfaches investieren Manpower und Ressourcen, um dieses System zu entwickeln und zu optimieren.
End-to-End-Lösungsauswahl
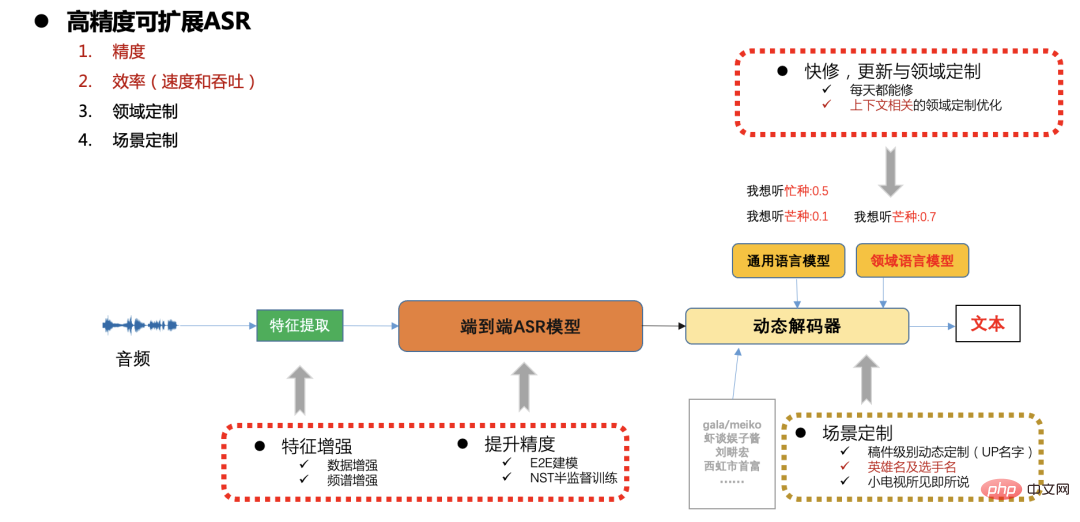
Bilibili jeden Tag Es müssen Hunderttausende Stunden Audio transkribiert werden, was einen hohen Durchsatz und eine hohe Geschwindigkeit des ASR-Systems erfordert. Gleichzeitig ist auch die Szenenabdeckung von Station B sehr groß und effizientes ASR-System ist für uns von großer Bedeutung.
Ideales ASR-System
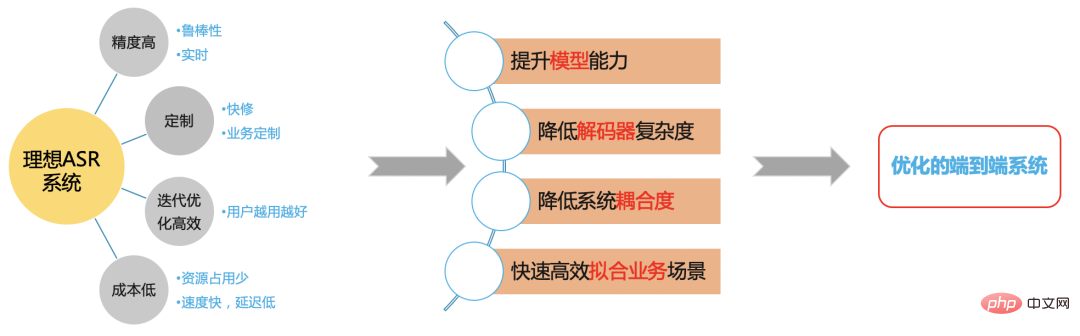
Abbildung 5
Wir hoffen, auf der Grundlage des End- End-Framework Ein effizientes ASR-System löst das Problem im B-Station-Szenario.
End-to-End-Systemvergleich
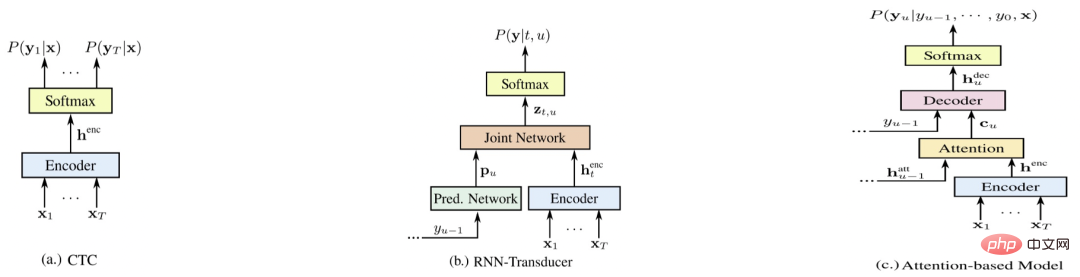
Abbildung 6
Abbildung 4 ist nun repräsentativ Drei End-to-End-Systeme [5], nämlich E2E-CTC, E2E-RNNT und E2E-AED. Im Folgenden werden die Vor- und Nachteile der einzelnen Systeme unter verschiedenen Aspekten verglichen (je höher die Punktzahl, desto besser)#🎜🎜 # # 🎜🎜#Systemvergleich
#🎜 🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#e2e-aed#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜#E2E-RNNT# 🎜🎜#
Optimiert Erkenntnis Accuracy#🎜🎜 ## 🎜🎜 ## 🎜🎜#6#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#5#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #6#🎜🎜 #
| Live (Streaming) | 3#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#5#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#5#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 🎜🎜 ##🎜🎜 #Kosten&Geschwindigkeit |
4 |
3 |
5#🎜🎜 # |
| schnelle Reparatur
|
3#🎜 Schnelle und effiziente Iteration |
6 |
4 |
#🎜🎜 #5 |
- Nicht-Streaming-Genauigkeitsvergleich (CER)
|
2000 Stunden |
15000 Stunden |
|
Kaldi Chain-Modell+LM |
13,7 NT |
12.4 |
--|
| E2E-CTC(gierig) |
13,1 |
7,1 |
Optimiertes E2E-CTC+LM |
1 0,2 |
5.8 |
Das Obige sind die Ergebnisse von Lebens- und Essensszenen an Station B, basierend auf 2000 Stunden bzw. 15000 Stunden Videotrainingsdaten. Chain und E2E-CTC verwenden das erweiterte Sprachmodell, das mit demselben Korpus trainiert wurde,
E2E-AED und E2E -RNNT verwendet die Erweiterung nicht. Das Sprachmodell und das End-to-End-System basieren auf dem Conformer-Modell.
Aus der zweiten Tabelle ist ersichtlich, dass die Genauigkeit eines einzelnen E2E-CTC-Systems nicht wesentlich schwächer ist als die anderer End-to-End-Systeme, gleichzeitig bietet das E2E-CTC-System jedoch folgende Vorteile:
- Da es keine automatische Regression der neuronalen Netzwerkstruktur (AED-Decoder und RNNT-Vorhersage) gibt, bietet das E2E-CTC-System natürliche Vorteile in Bezug auf Streaming, Decodierungsgeschwindigkeit und Bereitstellungskosten.
- In Bezug auf die Geschäftsanpassung bietet das E2E-CTC-System Vorteile Es ist auch einfacher, verschiedene Sprachmodelle (nnlm und ngram) extern zu verbinden. Dadurch ist die Generalisierungsstabilität deutlich besser als bei anderen End-to-End-Systemen in allgemeinen offenen Bereichen, in denen die Datenabdeckung unzureichend ist. „Hochwertige ASR-Lösung“ Es besteht auch Bedarf an schnellen Aktualisierungen und Anpassungen in verschiedenen Szenarien (z. B. Entitätswörter im Zusammenhang mit Manuskripten, Anpassung beliebter Spiele und Sportveranstaltungen usw.
Hier übernehmen wir im Allgemeinen ein End-to-End-CTC-System und lösen es). Das Problem wird durch Probleme bei der Skalierbarkeitsanpassung verursacht. Im Folgenden liegt der Schwerpunkt auf der Optimierung der Modellgenauigkeit, -geschwindigkeit und -skalierbarkeit.
End-to-End-CTC-Unterscheidungstraining
Unser System verwendet chinesische Schriftzeichen plus englische BPE-Modellierung. Nach dem Multitasking-Training basierend auf AED und CTC behalten wir nur den CTC-Teil bei und führen später ein Unterscheidungstraining durch. Wir übernehmen ein durchgängiges, gitterfreies MMI[6][7]-Diskriminierungstraining:
diskriminatives Trainingskriterium
diskriminatives Kriterium-MMI
und traditionelle Diskriminierung Unterschiede im sexuellen Training
a. Generieren Sie zunächst das Ausrichtungs- und Dekodierungsgitter, das dem gesamten Trainingskorpus auf der CPU entspricht; 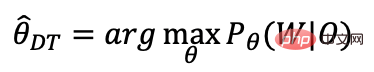 b. Während des Trainings berechnet jeder Minibatch den Zähler bzw. das Gitter aus dem vorab generierten Ausrichtung und Gitter. 2. Unser Ansatz: Während des Trainings berechnet jeder Minibatch den Zähler- und Nennergradienten.
- Der Unterschied zwischen Kaldi und Kaldi Telefonbasiertes gitterfreies MMI-Diskriminierungstraining

1. Modellieren Sie Zeichen und englisches BPE direkt durchgängig und verzichten Sie auf die Telefon-HMM-Zustandsübertragungsstruktur
2. Die Modellierungsgranularität ist groß, die Trainingseingabe nicht Ungefähr gekürzt, und der Kontext ist der gesamte Satz.
- Die folgende Tabelle basiert auf 15.000 Stunden an Daten. Nach Abschluss des CTC-Trainings werden 3.000 Stunden für das Unterscheidungstraining ausgewählt Bis auf die Genauigkeit sind die Ergebnisse des gitterfreien MMI-Diskriminierungstrainings besser als beim herkömmlichen DT-Training. Durch die Verbesserung kann der gesamte Trainingsprozess in der Tensorflow/Pytorch-GPU abgeschlossen werden. B-Station-Videotestset
Traditionelles DT
|
6.63 |
E2E LFMMI DT | #🎜 🎜#6.13
|
Im Vergleich zu Hybridsystemen sind die Zeitstempel der End-to-End-System-Dekodierungsergebnisse nicht sehr genau. Das CTC-Trainingsmodell ist viel genauer als AED-Zeitstempel, es gibt jedoch auch ein Spitzenproblem. Die Dauer jedes Wortes ist ungenau.
Nach dem End-to-End-Diskriminierungstraining wird die Modellausgabe flacher und die Zeitstempelgrenzen der Dekodierungsergebnisse werden genauer Bei der Entwicklung der Spracherkennungstechnologie ist der Decoder eine sehr wichtige Komponente, unabhängig davon, ob es sich um die erste Stufe basierend auf GMM-HMM oder die zweite Stufe basierend auf dem DNN-HMM-Hybrid-Framework handelt. Die Leistung des Decoders bestimmt direkt die Geschwindigkeit und Genauigkeit des endgültigen ASR-Systems. Auch die Geschäftserweiterung und -anpassung basiert größtenteils auf flexiblen und effizienten Decoderlösungen. Herkömmliche Decoder, unabhängig davon, ob es sich um dynamische Decoder oder statische Decoder auf WFST-Basis handelt, sind nicht nur auf viel theoretisches Wissen angewiesen, sondern erfordern auch ein professionelles Software-Engineering-Design In der Anfangsphase ist viel Personalentwicklung erforderlich, und die anschließenden Wartungskosten sind ebenfalls sehr hoch. Ein typischer herkömmlicher WFST-Decoder muss HMM, Triphone-Kontext, Wörterbuch und Sprachmodell in einem einheitlichen Netzwerk, nämlich HCLG, in einem einheitlichen FST-Netzwerksuchraum kompilieren, was die Geschwindigkeit und Genauigkeit der Decodierung verbessern kann. Mit der Reife der End-to-End-Systemtechnologie weist die End-to-End-Systemmodellierungseinheit eine größere Granularität auf, z. B. chinesische Wörter oder englische Wortteile, da die traditionelle HMM-Übertragungsstruktur, der Triphonkontext und das Aussprachewörterbuch entfernt werden Dadurch wird der Suchraum für die nachfolgende Dekodierung viel kleiner, daher wählen wir einen einfachen und effizienten dynamischen Dekoder, der auf der Strahlsuche basiert. Die folgende Abbildung zeigt zwei Dekodierungsrahmen im Vergleich zum herkömmlichen WFST-Dekodierer die folgenden Vorteile:
Beansprucht nur wenige Ressourcen, typischerweise 1/5 der WFST-Dekodierungsressourcen
Der geringe Kopplungsgrad erleichtert die Anpassung des Geschäfts und die Integration der Dekodierung in verschiedene Sprachmodelle Die Dekodierungsgeschwindigkeit ist hoch und verwendet die wortsynchrone Dekodierung [8], die normalerweise fünfmal schneller ist als die WFST-Dekodierungsgeschwindigkeit. Abbildung 8: Modellinferenzbereitstellung. Unter einem angemessenen und effizienten Ende. Im End-ASR-Framework sollte der Teil mit dem größten Rechenaufwand die Inferenz des neuronalen Netzwerkmodells sein, und dieser rechenintensive Teil kann die Rechenleistung der GPU voll ausnutzen. Wir optimieren die Modellinferenzbereitstellung aus der Inferenz Service, Modellstruktur und Modellquantifizierung:
-
Das Modell verwendet F16-Inferenz mit halber Genauigkeit. - Das Modell wird in FasterTransformer[9] konvertiert, basierend auf dem hochoptimierten Transformator von NVIDIA.
- Verwendung von Triton zur automatischen Bereitstellung des Inferenzmodells Gruppierung von Stapeln, wodurch die Effizienz der GPU-Nutzung vollständig verbessert wird.
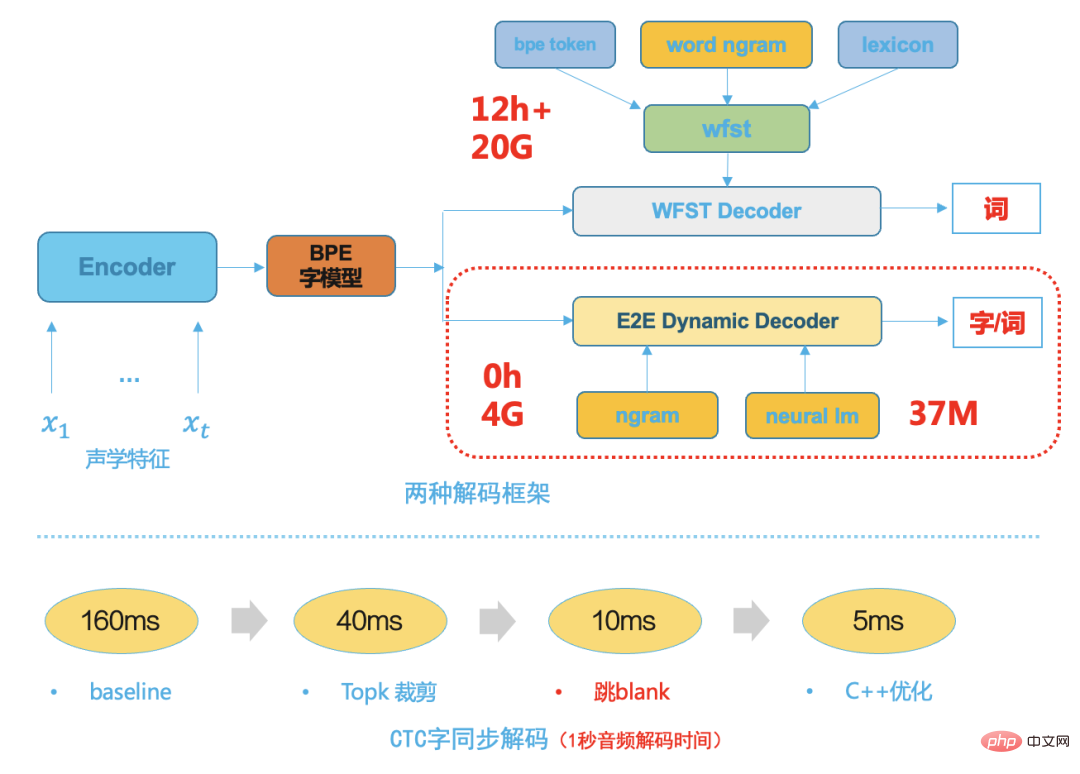 Auf einer einzelnen GPU T4 wird die Download-Geschwindigkeit um 30 % erhöht, der Durchsatz wird um das Zweifache erhöht und 3.000 Stunden langes Audio können in einer Stunde transkribiert werden Auf einer einzelnen GPU T4 wird die Download-Geschwindigkeit um 30 % erhöht, der Durchsatz wird um das Zweifache erhöht und 3.000 Stunden langes Audio können in einer Stunde transkribiert werden
Zusammenfassung
Dieser Artikel stellt hauptsächlich die Implementierung der Spracherkennungstechnologie in der Bilibili-Szene vor, wie man das Trainingsdatenproblem von Grund auf löst, die Auswahl der gesamten technischen Lösung sowie deren Einführung und Optimierung Untermodul, einschließlich Modellschulung, Decoderoptimierung und Service-Inferenzbereitstellung usw. In Zukunft werden wir das Benutzererlebnis in relevanten Landing-Szenarien weiter verbessern, z. B. durch den Einsatz von Instant-Hot-Word-Technologie, um die Genauigkeit relevanter Entitätswörter auf Manuskriptebene zu optimieren, kombiniert mit Streaming-ASR-bezogener Technologie, effizienterer, maßgeschneiderter Unterstützung für Real-; Zeitliche Untertiteltranskription von Spielen und Sportveranstaltungen.
- Referenzen
- [1] A Baevski, H Zhou, et al. wav2vec 2.0: Ein Rahmen für selbstüberwachtes Lernen von Sprachdarstellungen
- [2] A Baevski, W Hsu, et al. data2vec: Ein allgemeiner Rahmen für Selbstüberwachtes Lernen in Sprache, Sehen und Sprache
[3] Daniel S, Y Zhang, et al. Verbessertes Training für laute Schüler zur automatischen Spracherkennung[4] C Lüscher, E Beck, et al LibriSpeech: Hybrid vs. Aufmerksamkeit – ohne Datenerweiterung[5] R. Prabhavalkar, K. Rao, et al., Ein Vergleich von Sequenz-zu-Sequenz-Modellen für die Spracherkennung[6] D. Povey, V. Peddinti1, et al, Rein sequenztrainierte neuronale Netze für ASR basierend auf gitterfreiem MMI[7] H Xiang, Z Ou, CRF-BASIERTE EINSTUFIGE AKUSTISCHE MODELLIERUNG MIT CTC-TOPOLOGIE[8] Z Chen, W Deng, et Al, Telefonsynchrondecodierung mit CTC -Gitter [9] https://www.php.cn/link/2ea6241cf767c279cf1e80a790df1885
the Autor dieser Ausgabe: Deng Weii
senior algorithmer Leiter der Spracherkennungsabteilung bei Bilibili
|
|


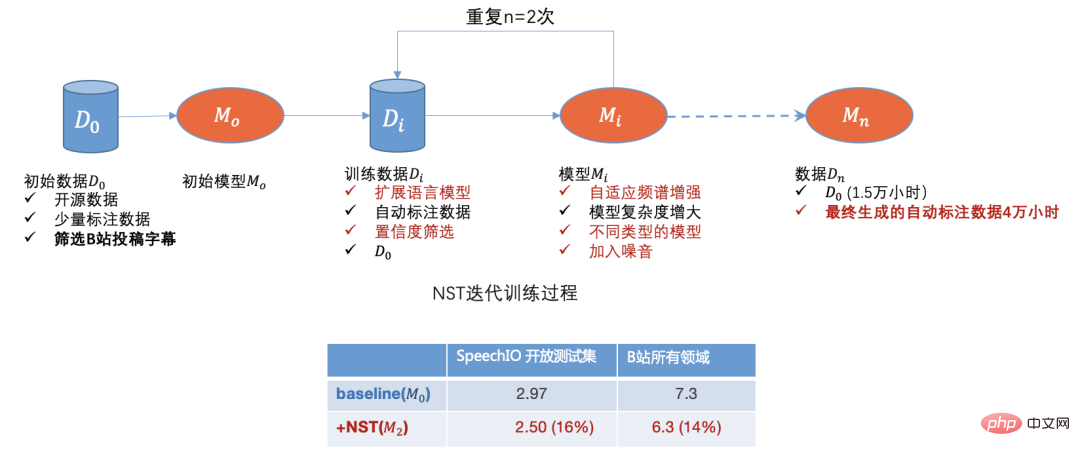 Mithilfe von Open-Source-Daten, Übermittlungsdaten von Standort B, manuellen Annotationsdaten und automatischen Annotationsdaten haben wir zunächst das Datenkaltstartproblem gelöst. Mit der Iteration des Modells können wir die Daten weiter herausfiltern Domänendaten mit schlechter Erkennung,
Mithilfe von Open-Source-Daten, Übermittlungsdaten von Standort B, manuellen Annotationsdaten und automatischen Annotationsdaten haben wir zunächst das Datenkaltstartproblem gelöst. Mit der Iteration des Modells können wir die Daten weiter herausfiltern Domänendaten mit schlechter Erkennung,