
Heim >Backend-Entwicklung >Python-Tutorial >Zehn interessante fortgeschrittene Python-Skripte, zum Sammeln empfohlen!
Zehn interessante fortgeschrittene Python-Skripte, zum Sammeln empfohlen!

- 王林nach vorne
- 2023-04-14 20:46:012383Durchsuche

Bei unserer täglichen Arbeit werden wir immer wieder mit verschiedenen Problemen konfrontiert.
Viele dieser Probleme können mit einigen einfachen Python-Codes gelöst werden.
Vor nicht allzu langer Zeit verwendete beispielsweise ein Fudan-Chef 130 Zeilen Python-Code, um Nukleinsäurestatistiken zu vervollständigen, was die Effizienz erheblich verbesserte und viel Zeit sparte.
Heute bringt Ihnen Xiao F 10 Python-Skriptprogramme bei.
Obwohl es einfach ist, ist es dennoch sehr nützlich.
Wer Interesse hat, kann es selbst umsetzen und Techniken finden, die ihm weiterhelfen.
1. Konvertierung des Bildformats von JPG in PNG. Früher dachte Xiao F vielleicht zuerst an die Software [Format Factory].
Heutzutage kann das Schreiben eines Python-Skripts die Konvertierung verschiedener Bildformate abschließen. Hier nehmen wir die Konvertierung von JPG in PNG.
Es gibt zwei Lösungen, die beide mit allen geteilt werden.
# 图片格式转换, Jpg转Png
# 方法①
from PIL import Image
img = Image.open('test.jpg')
img.save('test1.png')
# 方法②
from cv2 import imread, imwrite
image = imread("test.jpg", 1)
imwrite("test2.png", image)
2. PDF-Verschlüsselung und -Entschlüsselung
Wenn Sie 100 oder mehr PDF-Dateien haben, die verschlüsselt werden müssen, ist eine manuelle Verschlüsselung definitiv nicht machbar und äußerst zeitaufwändig.
Verwenden Sie das Pikepdf-Modul von Python, um Dateien zu verschlüsseln, und schreiben Sie eine Schleife, um Dokumente stapelweise zu verschlüsseln.
# PDF加密
import pikepdf
pdf = pikepdf.open("test.pdf")
pdf.save('encrypt.pdf', encryption=pikepdf.Encryption(owner="your_password", user="your_password", R=4))
pdf.close()
Wenn eine Verschlüsselung vorhanden ist, erfolgt eine Entschlüsselung. Der Code lautet wie folgt.
# PDF解密
import pikepdf
pdf = pikepdf.open("encrypt.pdf",password='your_password')
pdf.save("decrypt.pdf")
pdf.close()
3. Erhalten Sie Informationen zur Computerkonfiguration
Viele Freunde verwenden möglicherweise Master Lu, um ihre Computerkonfiguration zu überprüfen, was das Herunterladen einer Software erfordert.
Verwenden Sie das WMI-Modul von Python, um Ihre Computerinformationen einfach anzuzeigen.
# 获取计算机信息
import wmi
def System_spec():
Pc = wmi.WMI()
os_info = Pc.Win32_OperatingSystem()[0]
processor = Pc.Win32_Processor()[0]
Gpu = Pc.Win32_VideoController()[0]
os_name = os_info.Name.encode('utf-8').split(b'|')[0]
ram = float(os_info.TotalVisibleMemorySize) / 1048576
print(f'操作系统: {os_name}')
print(f'CPU: {processor.Name}')
print(f'内存: {ram} GB')
print(f'显卡: {Gpu.Name}')
print("n计算机信息如上 ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑")
System_spec()
Am Beispiel des eigenen Computers von Xiao F können Sie die Konfiguration sehen, indem Sie den Code ausführen.
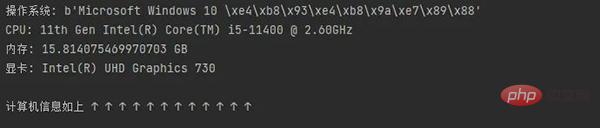 4. Dateien dekomprimieren
4. Dateien dekomprimieren
Verwenden Sie das Zipfile-Modul, um Dateien zu dekomprimieren.
# 解压文件
from zipfile import ZipFile
unzip = ZipFile("file.zip", "r")
unzip.extractall("output Folder")
5. Excel-Arbeitsblattzusammenführung
hilft Ihnen, Excel-Arbeitsblätter in einer Tabelle zusammenzuführen. Der Tabelleninhalt ist wie folgt.
 6 Tabellen, der Inhalt der restlichen Tabellen ist derselbe wie in der ersten Tabelle.
6 Tabellen, der Inhalt der restlichen Tabellen ist derselbe wie in der ersten Tabelle.
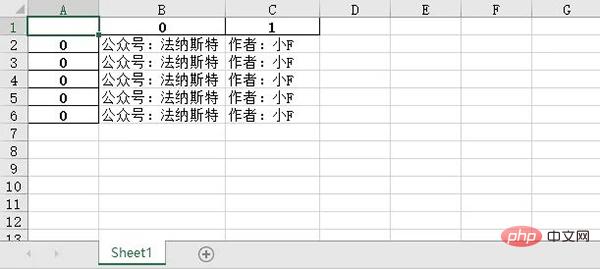
Stellen Sie die Anzahl der Tabellen auf 5 ein und der Inhalt der ersten 5 Tabellen wird zusammengeführt.
import pandas as pd # 文件名 filename = "test.xlsx" # 表格数量 T_sheets = 5 df = [] for i in range(1, T_sheets+1): sheet_data = pd.read_excel(filename, sheet_name=i, header=None) df.append(sheet_data) # 合并表格 output = "merged.xlsx" df = pd.concat(df) df.to_excel(output)
Die Ergebnisse sind wie folgt.
 6. Bild in Skizze konvertieren
6. Bild in Skizze konvertieren
ähnelt in gewisser Weise der vorherigen Bildformatkonvertierung, bei der das Bild verarbeitet wird.
Früher haben Sie vielleicht Meitu Xiuxiu verwendet, aber jetzt sind es vielleicht die Filter von Douyin.
Tatsächlich können Sie mit Pythons OpenCV schnell viele der gewünschten Effekte erzielen.
# 图像转换
import cv2
# 读取图片
img = cv2.imread("img.jpg")
# 灰度
grey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
invert = cv2.bitwise_not(grey)
# 高斯滤波
blur_img = cv2.GaussianBlur(invert, (7, 7), 0)
inverse_blur = cv2.bitwise_not(blur_img)
sketch_img = cv2.divide(grey, inverse_blur, scale=256.0)
# 保存
cv2.imwrite('sketch.jpg', sketch_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
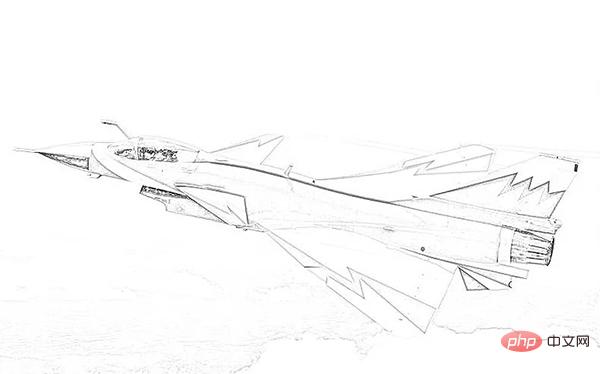
Das Originalbild ist wie folgt.
 Die Skizze ist wie folgt, sie ist ganz nett.
Die Skizze ist wie folgt, sie ist ganz nett.
 7. Ermitteln Sie die CPU-Temperatur
7. Ermitteln Sie die CPU-Temperatur
Mit diesem Python-Skript benötigen Sie keine Software, um die CPU-Temperatur zu ermitteln.
# 获取CPU温度
from time import sleep
from pyspectator.processor import Cpu
cpu = Cpu(monitoring_latency=1)
with cpu:
while True:
print(f'Temp: {cpu.temperature} °C')
sleep(2)
8. PDF-Tabellen extrahieren
Manchmal müssen wir Tabellendaten aus PDF extrahieren.
Eine Zeit lang denken Sie vielleicht zuerst an die manuelle Endbearbeitung, aber wenn die Arbeitsbelastung besonders hoch ist, kann die manuelle Arbeit mühsamer sein.
Dann denken Sie vielleicht an Software und Web-Tools zum Extrahieren von PDF-Tabellen.
Mit diesem einfachen Skript unten können Sie dasselbe in nur einer Sekunde tun.
# 方法①
import camelot
tables = camelot.read_pdf("tables.pdf")
print(tables)
tables.export("extracted.csv", f="csv", compress=True)
# 方法②, 需要安装Java8
import tabula
tabula.read_pdf("tables.pdf", pages="all")
tabula.convert_into("table.pdf", "output.csv", output_format="csv", pages="all")
Der Inhalt des PDF-Dokuments ist wie folgt, einschließlich einer Tabelle.
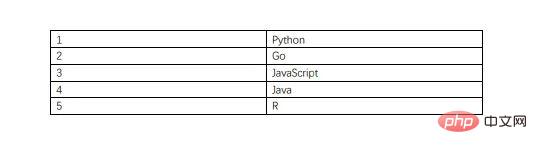 Der Inhalt der extrahierten CSV-Datei ist wie folgt.
Der Inhalt der extrahierten CSV-Datei ist wie folgt.
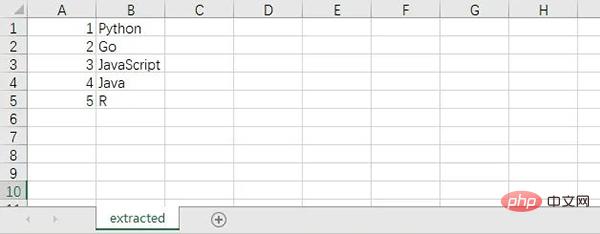 9. Screenshot
9. Screenshot
Dieses Skript erstellt einfach einen Screenshot, ohne dass eine Screenshot-Software verwendet werden muss.
Im folgenden Code zeige ich Ihnen zwei Methoden zum Erstellen von Screenshots in Python.
# 方法①
from mss import mss
with mss() as screenshot:
screenshot.shot(output='scr.png')
# 方法②
import PIL.ImageGrab
scr = PIL.ImageGrab.grab()
scr.save("scr.png")
10. Dieses Python-Skript kann natürlich nur die Rechtschreibung prüfen. Chinesisch ist schließlich umfassend und tiefgründig.
# 拼写检查
# 方法①
import textblob
text = "mussage"
print("original text: " + str(text))
checked = textblob.TextBlob(text)
print("corrected text: " + str(checked.correct()))
# 方法②
import autocorrect
spell = autocorrect.Speller(lang='en')
# 以英语为例
print(spell('cmputr'))
print(spell('watr'))
print(spell('survice'))
Das obige ist der detaillierte Inhalt vonZehn interessante fortgeschrittene Python-Skripte, zum Sammeln empfohlen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!