
Heim >Technologie-Peripheriegeräte >KI >Auf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage
Auf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 23:34:011757Durchsuche
1. Zusammenfassung
Ranking-Modelle spielen eine wichtige Rolle in Werbe-, Empfehlungs- und Suchsystemen. Im Ranking-Modul steht die Technologie zur Schätzung der Klickrate an erster Stelle. Derzeit verwenden die meisten Technologien zur Vorhersage der Klickrate in der Branche Deep-Learning-Algorithmen, um tiefe neuronale Netze basierend auf dem Datenlaufwerk zu trainieren. Das entsprechende Problem, das durch den Datenlaufwerk verursacht wird, besteht jedoch darin, dass neue Projekte im Empfehlungssystem ein Kaltstartproblem haben.
Exploration-Exploitation (E&E)-Methode wird normalerweise verwendet, um Datenzyklusprobleme in großen Online-Empfehlungssystemen zu lösen. Frühere Forschungen gingen in der Regel davon aus, dass eine hohe Unsicherheit bei Modellvorhersagen ein hohes Renditepotenzial mit sich bringt, weshalb sich die meiste Forschungsliteratur auf die Schätzung der Unsicherheit konzentrierte. Bei Online-Empfehlungssystemen, die Streaming-Training verwenden, hat die Explorationsstrategie einen größeren Einfluss auf die Sammlung von Trainingsbeispielen, was sich wiederum auf das weitere Lernen des Modells auswirkt. Die meisten aktuellen Explorationsstrategien können jedoch nicht gut modellieren, wie sich die untersuchten Proben auf das anschließende Modelllernen auswirken. Aus diesem Grund haben wir ein Pseudo-Explorationsmodul entwickelt, um die Auswirkungen auf das anschließende Lernen des Empfehlungsmodells zu simulieren, nachdem die Stichprobe erfolgreich erkundet und angezeigt wurde.
Der Quasi-Explorationsprozess wird durch das Hinzufügen kontradiktorischer Störungen zur Modelleingabe realisiert. Wir liefern auch die entsprechende theoretische Analyse und den Beweis dieses Prozesses. Auf dieser Grundlage nennen wir diese Methode eine Explorationsstrategie, die auf einem kontradiktorischen Gradienten basiert (Adversarial Gradient Driven Exploration, im Folgenden als AGE bezeichnet). Um die Effizienz der Exploration zu verbessern, schlagen wir außerdem eine dynamische Gating-Einheit zum Filtern von Proben mit geringem Wert vor, um eine Verschwendung von Ressourcen für die Exploration mit geringem Wert zu vermeiden. Um die Wirksamkeit des AGE-Algorithmus zu überprüfen, haben wir nicht nur zahlreiche Experimente mit öffentlichen akademischen Datensätzen durchgeführt, sondern das AGE-Modell auch auf der Display-Werbeplattform Alimama eingesetzt und gute Online-Erträge erzielt. Diese Arbeit wurde als vollständiges Papier in den KDD 2022 Research Track aufgenommen. Sie können gerne gelesen und mitgeteilt werden.
Artikel: Adversarial Gradient Driven Exploration for Deep Click-Through-Rate Prediction
Download: https://arxiv.org/abs/2112.11136
2. Hintergrund
In Werbesystemen, Click-Through-Rate (CTR)-Vorhersagemodell Für das Training wird normalerweise die Streaming-Methode verwendet, und die Quelle der Streaming-Daten wird durch das online bereitgestellte CTR-Modell erzeugt, wodurch das sogenannte Datenschleifenproblem entsteht. Da Kaltstart- und Long-Tail-Anzeigen nicht vollständig angezeigt werden, fehlen dem CTR-Modell Trainingsdaten für diese Anzeigen. Dies führt auch dazu, dass die Schätzung dieser Anzeigen durch das Modell große Fehler aufweisen kann, was die Anzeige dieser Anzeigen erschwert Es ist schwierig, den Kaltstart abzuschließen. Starten Sie den Vorgang. Konkret zeigt Abbildung 1 die Beziehung zwischen der tatsächlichen Klickrate einer Anzeige und der Anzahl der Impressionen: In unserem System muss eine neue Anzeige durchschnittlich etwa 10.000 Mal angezeigt werden, bevor ihre Klickrate einen Konvergenzzustand erreicht . Dies bringt ein häufiges Problem für viele Online-Systeme mit sich, nämlich wie man diese Werbung kaltstartet und gleichzeitig das Benutzererlebnis gewährleistet.
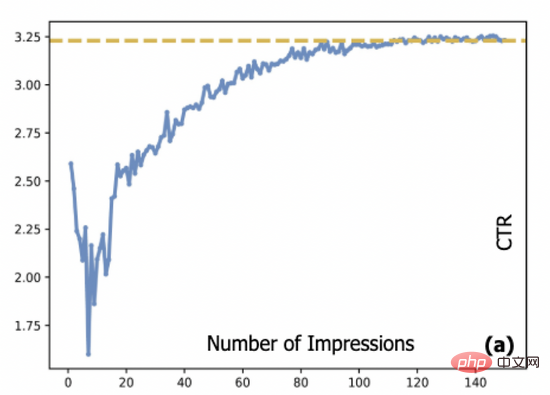
Abbildung 1: Die Beziehung zwischen der Werbe-CTR und der Anzahl der Impressionen
Explorations- und Exploitation-Algorithmen (E&E) werden normalerweise verwendet, um die oben genannten Probleme zu lösen. In Empfehlungs- oder Werbesystemen modellieren gängige Methoden (wie Contextual Multi-Armed Bandits, Contextual Multi-Armed Bandits) dieses Problem im Allgemeinen wie folgt. Bei jedem Schritt wählt das System eine Aktion basierend auf Richtlinie P aus (d. h. empfiehlt dem Benutzer einen Artikel _ _). Um die kumulativen Belohnungen zu maximieren (normalerweise gemessen als Gesamtklicks), muss das System abwägen, ob der aktuelle Schwerpunkt auf Erkundung oder Ausbeutung liegt. Frühere Untersuchungen betrachten eine hohe Unsicherheit im Allgemeinen als Maß für potenzielle Renditen. Einerseits muss Strategie P Projekten mit größerem aktuellen Nutzen Priorität einräumen, um den aktuellen Nutzen zu maximieren, andererseits muss der Algorithmus auch Operationen mit größerer Unsicherheit auswählen, um eine Exploration zu erreichen. Wenn es zur Darstellung der Strategie der Abwägung von Exploration und Ausbeutung verwendet wird, kann die endgültige Bewertung des Projekts durch das System durch die folgende Formel ausgedrückt werden:
Unsicherheitsschätzung ist zum Kernmodul vieler E&E-Algorithmen geworden. Die Unsicherheit kann durch Datenvariabilität, Messrauschen und Modellinstabilität (z. B. Zufälligkeit von Parametern) entstehen, darunter Monte-Carlo-MC-Dropout, Bayesianisches neuronales Netzwerk und Gaußsche Prozesse sowie die Unsicherheitsmodellierung auf der Grundlage von Gradientennormen. Modellgewichte) usw. Auf dieser Grundlage gibt es zwei typische Explorationsstrategien: UCB-basierte Methoden verwenden in der Regel die Obergrenze potenzieller Renditen als Endergebnis [1,2], während auf Thompson-Stichproben basierende Methoden durch Stichproben aus der geschätzten Wahrscheinlichkeitsverteilung erfolgen [3]. ].
3. Einführung in die Methode
Wir glauben, dass die obige Methode keinen vollständigen geschlossenen Kreislauf der Erkundung berücksichtigt. Bei datengesteuerten Online-Systemen ergibt sich der ultimative Vorteil der Exploration aus den Feedback-Daten, die aus dem Explorationsprozess gewonnen werden, sowie aus den Feedback-Daten für das Training und die Aktualisierung des Modells. Die Unsicherheit der Modellschätzung selbst spiegelt nicht vollständig die gesamte Rückkopplungsschleife wider. Zu diesem Zweck haben wir ein Quasi-Explorationsmodul eingeführt, um die Auswirkungen von Feedback-Daten auf das Modell nach Abschluss der Explorationsaktion zu simulieren und damit die Wirksamkeit der Exploration zu messen. Die Analyse ergab, dass die Wirksamkeit der Exploration nicht nur von der geschätzten Unsicherheit des Modells abhängt, sondern auch von der Größe der „Gegenstörung“. Die sogenannte kontradiktorische Störung bezieht sich auf den Störungsvektor mit einer festen Modullänge, der zur Eingabe des Modells hinzugefügt wird und die größte Änderung in der Modellausgabe verursacht. In der Arbeit haben wir auch bewiesen, dass, nachdem das Modell einmal mit den untersuchten Daten trainiert wurde, die Erwartung einer Änderung in der Modellausgabe dem Hinzufügen eines inkrementellen Vektors entspricht, dessen Modul die Unsicherheit ist und dessen Störungsvektor der kontradiktorische Gradient zum Eingabevektor ist . Wir haben bestätigt, dass die Modellierung auf diese Weise die spätere Auswirkung der untersuchten Proben auf das Modell in einem geschlossenen Regelkreis abschätzen und so den wahren Wert der untersuchten Proben abschätzen kann.
Wir nennen diese Methode Adversarial Gradient Driven Exploration, kurz AGE. Das AGE-Modell besteht aus zwei Teilen: dem Pseudo-Explorationsmodul und der dynamischen Gating-Einheit. Seine Gesamtstruktur ist in Abbildung 2 dargestellt.
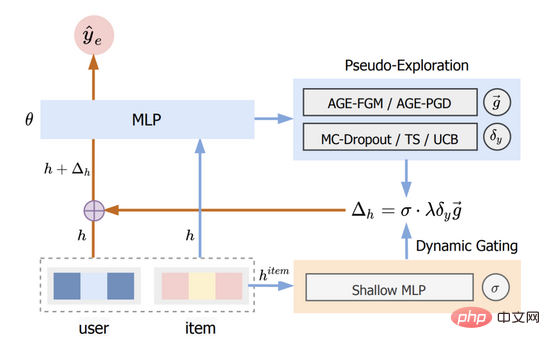
Abbildung 2: AGE-Strukturdiagramm
Siehe Abschnitt 3.1 für Einzelheiten und Abschnitt 3.3 für Einzelheiten. 3.1 Pseudo-Explorationsmodul um die Auswirkungen der Exploration auf das Modell abzuschätzen. Nach der Ableitung haben wir festgestellt, dass der obige Prozess durch Formel (2) abgeschlossen werden kann, die die Punktzahl der Stichprobe nach der Untersuchung durch das Modell darstellt, die wir für die endgültige Rangfolge verwenden.
Die obige Formel bedeutet, dass wir keine Operationen an den ursprünglichen Modellparametern durchführen müssen. Wir müssen lediglich das Produkt aus kontradiktorischem Gradienten, geschätzter Unsicherheit und manuell eingestellten Hyperparametern zur Eingabedarstellung hinzufügen, um die Simulation des Modells abzuschließen geschätzte Punktzahlen. Darunter die Berechnungsmethode für Parameter, die im nächsten Abschnitt vorgestellt wird. Später in diesem Abschnitt werden wir den detaillierten Ableitungsprozess der Formel (2) im vorgeschlagenen Explorationsmodul vorstellen.
3.1.2 Detaillierte Ableitung
Für jede Datenprobe wirkt sich das Modelltraining auf zwei Teile der Parameter aus: die der Probe entsprechende Darstellung (einschließlich Produkt, Benutzereinbettung usw.) und die Modellparameter. Da das Ziel der Modellparameter beim Training darin besteht, sich an alle Stichproben und nicht an eine einzelne Stichprobe anzupassen, können wir davon ausgehen, dass das Training einer einzelnen Stichprobe hauptsächlich die Darstellung der Stichprobe beeinflusst, während die Modellparameter selbst nur geringfügige Anpassungen erfordern. Daher werden wir in nachfolgenden Studien die Anpassung ignorieren und uns nur auf die Änderungen in den Darstellungen konzentrieren, die den Stichproben entsprechen. Unter der Annahme, dass die wahre Bezeichnung der Probe, die die Darstellung enthält, während des Trainings vorliegt, müssen wir die Anzahl der Aktualisierungen ermitteln, um die Verlustfunktion zu minimieren. Auf dieser Grundlage definieren wir:
, was die im Training verwendete Verlustfunktion darstellt, und die Kreuzentropieverlustfunktion wird im Allgemeinen bei CTR-Vorhersageaufgaben verwendet. Gleichzeitig beschränken wir die maximale Änderung der Darstellung. Um das Schreiben zu vereinfachen, schreiben wir die rechte Seite der obigen Formel als.
Gemäß dem Mittelwertsatz von Lagrange können wir, wenn die zweite Norm von nahe bei 0 liegt, die obige Verlustfunktionsformel (3) wie folgt ableiten: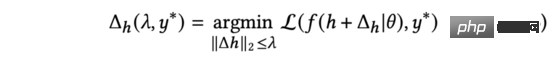
In der Praxis ersetzen wir den normalisierten Gradienten in Gleichung (5). Durch Ableitung der Kettenregel kann diese in zwei Teile erweitert werden: und . Wenn wir weiter rechnen, erhalten wir: 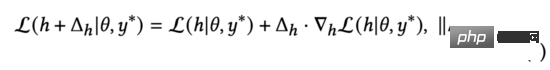
In der obigen Gleichung werden wir neu skalieren, um die Gleichung wahr zu halten. Obwohl die Bedeutung unterschiedlich ist, handelt es sich bei allen um manuell angepasste Hyperparameter, sodass wir die Ersetzung direkt abschließen können. Wir vereinfachen Formel (6) weiter als: 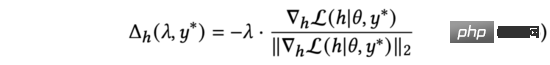
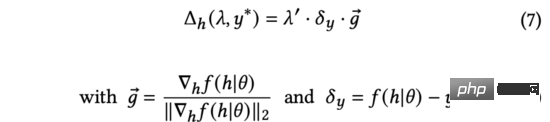
In der obigen Formel stellt der normalisierte Gradient die Richtung der Ableitung der Modellausgabe relativ zur Eingabedarstellung dar. Da zum Zeitpunkt der Erkundung kein echtes Benutzerfeedback verfügbar ist, verwenden wir die Schätzunsicherheit, um den Unterschied zwischen der vorhergesagten Punktzahl und dem echten Benutzerfeedback zu messen.
In Formel (7) finden wir die analytische Lösung, die die Änderung der Modellvorhersageausgabe unter den Einschränkungen von maximieren kann (die Ableitung ist die gleiche wie Formel (3) bis Formel (5)). Darüber hinaus stellen wir auch fest, dass der obige Prozess des Hinzufügens von Eingabedarstellungen die gleiche Form hat wie eine gegnerische Störung (siehe Gleichung (9)).
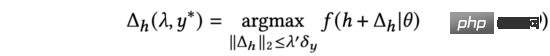
Daher verwenden wir als Ersatz in Formel (7) einen kontradiktorischen Gradienten und bezeichnen unsere Methode als kontradiktorischen Gradienten-basierten Erkundungsalgorithmus.
Formel (9) zeigt, dass der effektivste Weg zur Untersuchung von AGE darin besteht, gegnerische Störungen zur Darstellungseingabe hinzuzufügen und die Ausgabe des gestörten Modells als Rangfolgefaktor zu verwenden: die Richtung des durch den gegnerischen Gradienten dargestellten Störungsvektors als die Eingabe und der Vorhersageunsicherheitsgrad der Störung. Daher können wir nach Erhalt der Summe die folgende Formel verwenden, um den Modellvorhersagewert nach der Erkundung zu berechnen, nämlich die oben genannte Formel (2).
3.2 Implementierungsdetails
In AGE verwenden wir die MC-Dropout-Methode, um die Unsicherheit abzuschätzen. Insbesondere weist MC-Dropout jedem Neuron im Tiefenmodell ein zufälliges Maskengewicht zu. Die spezifische Methode ist in der folgenden Formel (11) dargestellt. Ein Vorteil dieser Methode besteht darin, dass wir die Unsicherheit direkt ermitteln können, ohne die ursprüngliche Struktur des Modells zu ändern. Im tatsächlichen Betrieb kann die Unsicherheit ausgedrückt werden, indem die Varianz des Ausfalls durch die Idee von UCB berechnet wird, oder indem man sich auf die Zufallsstichprobenmethode von Thompson bezieht, indem man die Differenz zwischen der Stichprobe und dem Mittelwert berechnet, also die Formel ( 12) und Formel (13) ).
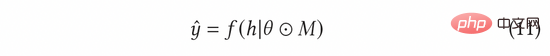
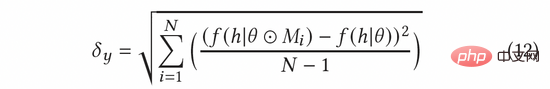
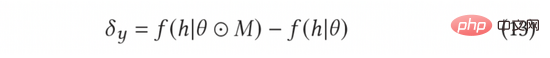
Der normalisierte kontradiktorische Gradient kann gemäß der Fast-Gradient-Methode (FGM) in Formel (8) berechnet werden. Um den kontradiktorischen Gradienten genauer zu berechnen, können wir außerdem die Methode des proximalen Gradientenabstiegs (PGD) verwenden, um den Gradienten iterativ in mehreren Schritten zu aktualisieren, wie in Gleichung (14) gezeigt.
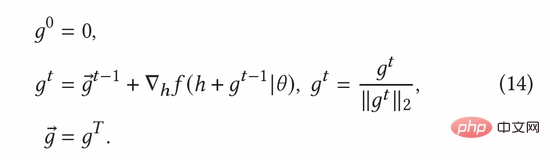
3.3 Dynamische Gating-Einheit
In der Praxis haben wir festgestellt, dass nicht alle Anzeigen eine Erkundung wert sind. In einem allgemeinen Top-K-Werbesystem ist die Anzahl der Anzeigen, die Endbenutzern angezeigt werden können, relativ gering. Daher ist der explorative Wert für Anzeigen mit niedrigen Klickraten (z. B. Anzeigen von geringer Qualität selbst) angesichts der Geschäftsattribute des Werbesystems immer noch sehr gering, selbst wenn das Modell eine hohe Unsicherheit bei der Vorhersage dieser Anzeigen aufweist . . Obwohl wir durch Erkundung eine große Menge an Daten zu diesen Anzeigen erhalten können, sodass diese Anzeigen vom Modell vollständig trainiert und genauer geschätzt werden können, ist es aufgrund der niedrigen Klickrate dieser Anzeigen nicht möglich, diese Anzeigen zu erhalten Selbst nach vollständiger Erkundung ist eine solche Erkundung zweifellos ineffizient. In diesem Artikel haben wir eine einfache Heuristik ausprobiert, um die Erkundung effizienter zu gestalten: Wenn die geschätzte Punktzahl des Modells für die Anzeige höher ist als die durchschnittliche Klickrate für die Anzeige in allen Gruppen, wird die Erkundung andernfalls nicht durchgeführt.
Um die durchschnittliche Klickrate von Anzeigen zu berechnen, führen wir das Modul Dynamic Gating Threshold Unit (DGU) ein. DGU verwendet nur werbeseitige Funktionen als Eingabe, um die durchschnittliche Klickrate von Anzeigen zu schätzen. Wenn die geschätzte Klickrate des Modells niedriger ist als die vom DGU-Modul geschätzte durchschnittliche Klickrate für Werbung, wird keine Erkundung durchgeführt. Andernfalls wird eine normale Erkundung durchgeführt. Der Prozess wird in der folgenden Formel dargestellt:
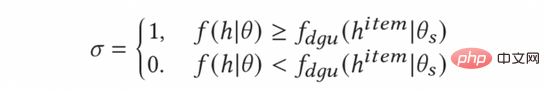
Abschließend werden wir ihn in Formel (10) einsetzen, um die endgültige und vollständige Berechnungsmethode des AGE-Explorationsmodells wie folgt zu erhalten.
4. Experimentelle Auswertung . Es lässt sich beobachten, dass die auf der Thompson Sampling (TS)-Methode erstellten Basismodelle besser sind als die auf UCB basierenden Modelle, was beweist, dass TS ein besserer Algorithmus zur Messung der Modellunsicherheit ist. Darüber hinaus können wir beobachten, dass der AGE-Algorithmus alle Basismethoden übertrifft, was auch die Wirksamkeit der AGE-Methode beweist. Insbesondere übertreffen sowohl AGE-TS als auch AGE-UCB die besten Basislinien UR-Gradient-TS und UR-Gradient-UCB [4] mit Verbesserungswerten von 5,41 % bzw. 15,3 %. Die AGE-TS-Methode steigert die Klicks im Vergleich zur Basismethode ohne Exploration um satte 28,0 %. Es ist erwähnenswert, dass die AGE-basierten UCB- und TS-Algorithmen AGE-UCB und AGE-TS ähnliche Ergebnisse erzielen, was bei den Gradienten-basierten UCB- und TS-Algorithmen nicht der Fall ist, was auch beweist, dass AGE die Instabilität von kompensieren kann die UCB-Methode.Tabelle 1: Offline-Versuchsergebnisse
Wir haben auch eine große Anzahl von Ablationsexperimenten durchgeführt, um die Wirksamkeit jedes Moduls zu beweisen. Wie in Tabelle 2 gezeigt, sind die Schwellenwerteinheit, der kontradiktorische Gradient und die Unsicherheitseinheit unverzichtbar. Um die Wirkung von DGU weiter zu bestimmen, haben wir verschiedene Parameter mit festem Schwellenwert ausprobiert und schließlich festgestellt, dass ihre Wirkung nicht so gut war wie der dynamische Schwellenwert von DGU. 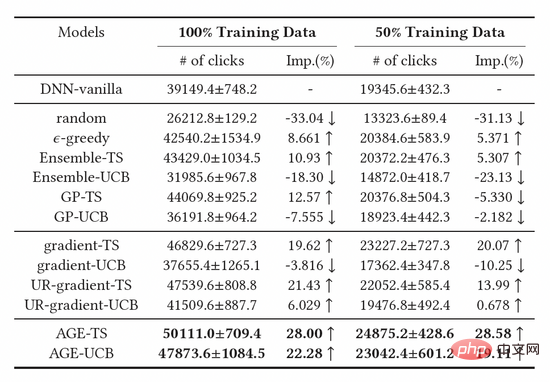
Tabelle 2: Ergebnisse des Ablationsexperiments
4.2 Online-Experiment 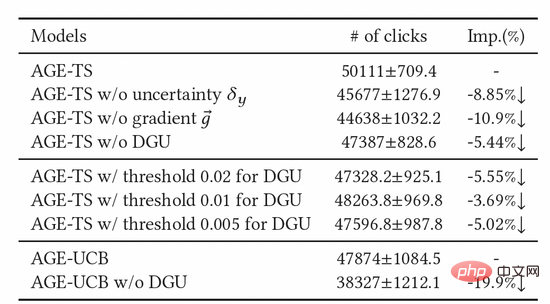
Abbildung 3: Fair-Bucket-Experimentplan
Wie in Tabelle 3 gezeigt, wurden die oben genannten Indikatoren effektiv verbessert. Unter diesen übertrifft AGE alle anderen Methoden deutlich: CTR und PV sind 6,4 % bzw. 3,0 % höher als das Basismodell. Gleichzeitig verbessert die Verwendung des AGE-Modells auch die Vorhersagegenauigkeit des Modells, dh die Vorhersagegenauigkeit PCOC liegt näher bei 1. Noch wichtiger ist, dass auch der AFR-Indikator um 5,5 % gestiegen ist, was zeigt, dass unsere Explorationsmethode das Werbeerlebnis effektiv verbessern kann. 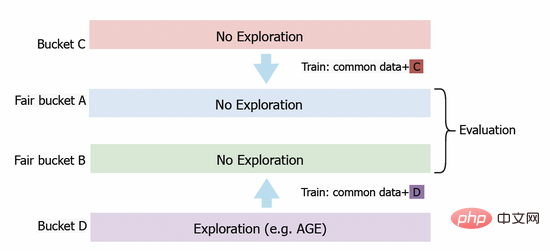
Tabelle 3: Online-Experimentergebnisse
5. Zusammenfassung 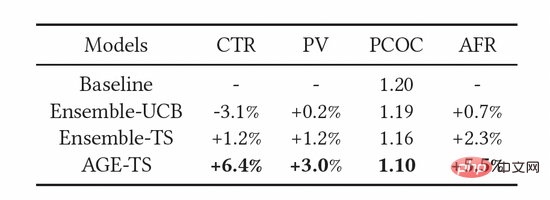
Das obige ist der detaillierte Inhalt vonAuf dem kontradiktorischen Gradienten basierendes Explorationsmodell und seine Anwendung bei der Klickvorhersage. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr