
Heim >Technologie-Peripheriegeräte >KI >Zehn Python-Bibliotheken für erklärbare KI
Zehn Python-Bibliotheken für erklärbare KI

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 16:46:061728Durchsuche
Das Ziel von
XAI, Explainable AI bezieht sich auf ein System oder eine Strategie, die klare und verständliche Erklärungen für Entscheidungsprozesse und Vorhersagen der künstlichen Intelligenz (KI) liefern kann. Das Ziel von XAI besteht darin, aussagekräftige Erklärungen für ihre Handlungen und Entscheidungen bereitzustellen, was dazu beiträgt, das Vertrauen zu stärken, Verantwortlichkeit und Transparenz bei Modellentscheidungen zu gewährleisten. XAI geht über Erklärungen hinaus und führt ML-Experimente so durch, dass Schlussfolgerungen für Benutzer einfacher zu extrahieren und zu interpretieren sind.
In der Praxis kann XAI durch eine Vielzahl von Methoden erreicht werden, z. B. durch die Verwendung von Merkmalswichtigkeitsmaßen, Visualisierungstechniken oder durch die Erstellung von Modellen, die inhärent interpretierbar sind, wie z. B. Entscheidungsbäume oder lineare Regressionsmodelle. Die Wahl der Methode hängt von der Art des zu lösenden Problems und dem erforderlichen Maß an Interpretierbarkeit ab.
KI-Systeme werden in einer wachsenden Zahl von Anwendungen eingesetzt, darunter im Gesundheitswesen, im Finanzwesen und in der Strafjustiz, wo die potenziellen Auswirkungen von KI auf das Leben der Menschen groß sind und es von entscheidender Bedeutung ist, zu verstehen, warum eine Entscheidung getroffen wurde. Da die Kosten für Fehlentscheidungen in diesen Bereichen hoch sind (es steht viel auf dem Spiel), wird XAI immer wichtiger, da auch von KI getroffene Entscheidungen sorgfältig auf Gültigkeit und Erklärbarkeit überprüft werden müssen.

Datenvorbereitung: Diese Phase umfasst die Erhebung und Verarbeitung von Daten. Die Daten sollten von hoher Qualität, ausgewogen und repräsentativ für das reale Problem sein, das gelöst werden soll. Ausgewogene, repräsentative und saubere Daten reduzieren künftige Anstrengungen, die KI erklärbar zu halten.
Modelltraining: Das Modell wird auf vorbereiteten Daten trainiert, entweder einem traditionellen Modell für maschinelles Lernen oder einem neuronalen Deep-Learning-Netzwerk. Die Wahl des Modells hängt vom zu lösenden Problem und dem erforderlichen Grad der Interpretierbarkeit ab. Je einfacher das Modell, desto einfacher sind die Ergebnisse zu interpretieren, aber die Leistung einfacher Modelle ist nicht sehr hoch.
Modellbewertung: Die Auswahl geeigneter Bewertungsmethoden und Leistungsmetriken ist notwendig, um die Interpretierbarkeit des Modells aufrechtzuerhalten. In dieser Phase ist es auch wichtig, die Interpretierbarkeit des Modells zu bewerten, um sicherzustellen, dass es sinnvolle Erklärungen für seine Vorhersagen liefern kann.
Erklärungsgenerierung: Dies kann mithilfe verschiedener Techniken wie Merkmalswichtigkeitsmaßen, Visualisierungstechniken oder durch die Erstellung inhärent erklärbarer Modelle erfolgen.
Erklärungsüberprüfung: Überprüfen Sie die Richtigkeit und Vollständigkeit der vom Modell generierten Erklärungen. Dies trägt dazu bei, dass die Erklärung glaubwürdig ist.
Bereitstellung und Überwachung: Die Arbeit von XAI endet nicht mit der Modellerstellung und -validierung. Nach der Bereitstellung sind fortlaufende Erklärungsarbeiten erforderlich. Bei der Überwachung in einer realen Umgebung ist es wichtig, die Leistung und Interpretierbarkeit des Systems regelmäßig zu bewerten.
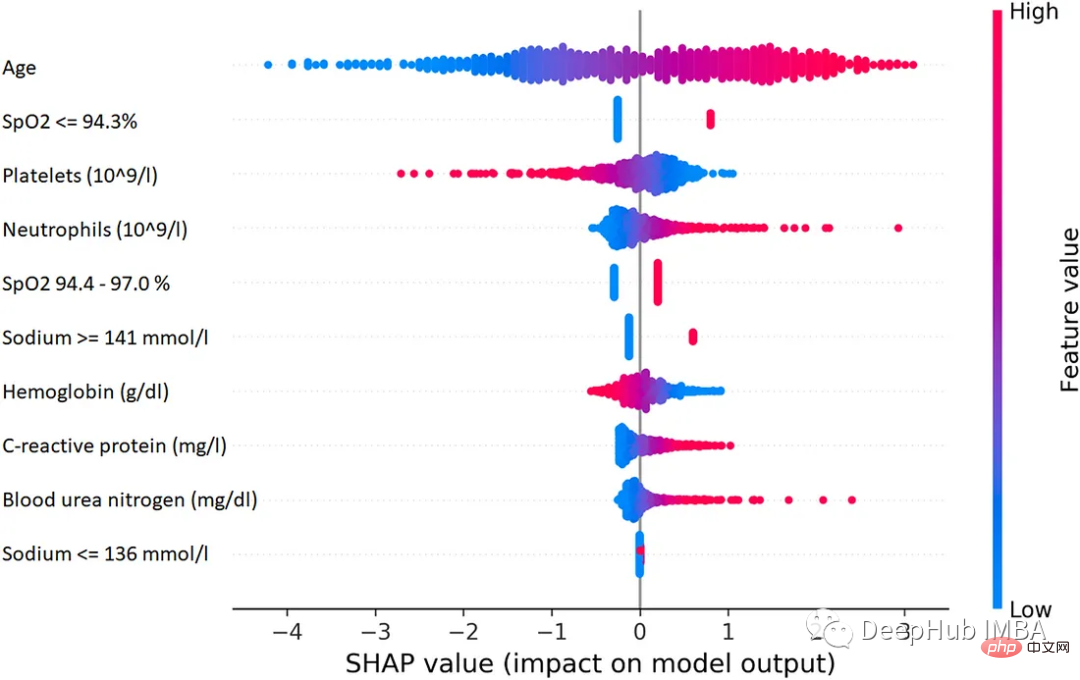
1. SHAP (SHapley Additive exPlanations)
SHAP ist eine spieltheoretische Methode, die verwendet werden kann, um die Ausgabe jedes maschinellen Lernmodells zu erklären. Es nutzt den klassischen Shapley-Wert aus der Spieltheorie und die damit verbundenen Erweiterungen, um die optimale Kreditzuteilung mit lokalen Interpretationen in Beziehung zu setzen.
 2. LIME (Local Interpretable Model-agnostic Explanations)
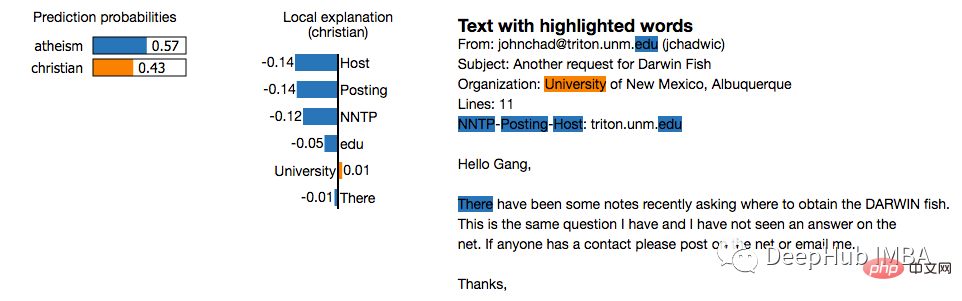
2. LIME (Local Interpretable Model-agnostic Explanations)
LIME ist ein modellunabhängiger Ansatz, der das Verhalten des Modells lokal an eine bestimmte Vorhersage annähert. LIME versucht zu erklären, was ein Modell für maschinelles Lernen tut. LIME unterstützt die Interpretation einzelner Vorhersagen von Textklassifikatoren, Klassifikatoren für Tabellendaten oder Bildern.
 3. Eli5
3. Eli5
ELI5 ist ein Python-Paket, das beim Debuggen von Klassifikatoren für maschinelles Lernen und bei der Interpretation ihrer Vorhersagen hilft. Es bietet Unterstützung für die folgenden Frameworks und Pakete für maschinelles Lernen:
scikit-learn: ELI5 kann die Gewichte und Vorhersagen von linearen Klassifikatoren und Regressoren von scikit-learn interpretieren und Entscheidungsbäume als Text oder SVG drucken, um die Bedeutung von Funktionen anzuzeigen Eigenschaften und erklären Entscheidungsbaum- und Baumensemble-basierte Vorhersagen. ELI5 versteht auch Texthandler in scikit-learn und hebt Textdaten entsprechend hervor.- Keras – Visuelle Interpretation von Bildklassifizierungsvorhersagen über Grad-CAM.
- XGBoost – Zeigt die Wichtigkeit von Funktionen an und erklärt die Vorhersagen von XGBClassifier, XGBRegressor und XGBoost .boost.
- LightGBM – Zeigt die Wichtigkeit von Funktionen an und erklärt die Vorhersagen von LGBTMClassifier und LGBMRegressor.
- CatBoost: Zeigt die Funktionsbedeutung von CatBoostClassifier und CatBoostRegressor an.
- lightning – Erklärt die Gewichte und Vorhersagen von Lightning-Klassifikatoren und Regressoren.
- sklearn-crfsuite. ELI5 ermöglicht die Überprüfung der Gewichte des Modells sklearn_crfsuite.CRF.
- Grundlegende Verwendung:
Show_weights() zeigt alle Gewichte des Modells an, Show_prediction() kann verwendet werden, um einzelne Vorhersagen des Modells zu überprüfen

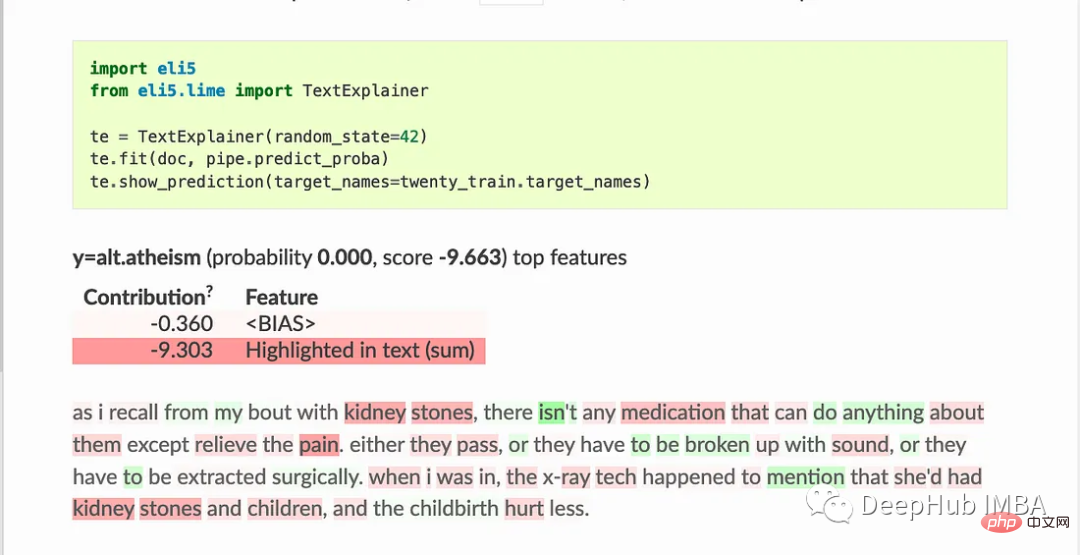
ELI5 implementiert auch einige Algorithmen zur Überprüfung von Black-Box-Modellen:
TextExplainer verwendet den LIME-Algorithmus, um die Vorhersagen eines beliebigen Textklassifikators zu erklären. Die Permutationswichtigkeitsmethode kann zur Berechnung der Merkmalswichtigkeit für Black-Box-Schätzer verwendet werden.
4. Shapash
Shapash bietet verschiedene Arten von Visualisierungen, um das Verständnis des Modells zu erleichtern. Verwenden Sie die Zusammenfassung, um die vom Modell vorgeschlagenen Entscheidungen zu verstehen. Dieses Projekt wird von MAIF-Datenwissenschaftlern entwickelt. Shapash erklärt das Modell hauptsächlich durch eine Reihe hervorragender Visualisierungen.
Shapash funktioniert über den Webanwendungsmechanismus und kann perfekt in Jupyter/ipython integriert werden.
from shapash import SmartExplainer
xpl = SmartExplainer(
model=regressor,
preprocessing=encoder, # Optional: compile step can use inverse_transform method
features_dict=house_dict# Optional parameter, dict specifies label for features name
)
xpl.compile(x=Xtest,
y_pred=y_pred,
y_target=ytest, # Optional: allows to display True Values vs Predicted Values
)
xpl.plot.contribution_plot("OverallQual")
5. Anker
Anker erklären das Verhalten komplexer Modelle mithilfe hochpräziser Regeln, sogenannter Ankerpunkte, die lokale „ausreichende“ Vorhersagebedingungen darstellen. Der Algorithmus kann die Erklärung jedes Black-Box-Modells mit hohen Wahrscheinlichkeitsgarantien effizient berechnen.
Anker können als LIME v2 betrachtet werden, wo einige Einschränkungen von LIME (z. B. die Unfähigkeit, Modelle für unsichtbare Instanzen der Daten anzupassen) korrigiert wurden. Anker nutzen lokale Bereiche und nicht jeden einzelnen Standpunkt. Es ist rechenintensiv als SHAP und kann daher mit hochdimensionalen oder großen Datensätzen verwendet werden. Einige Einschränkungen bestehen jedoch darin, dass Beschriftungen nur ganze Zahlen sein können.

6. BreakDown
BreakDown ist ein Tool, mit dem lineare Modellvorhersagen erklärt werden können. Dabei wird die Ausgabe des Modells in den Beitrag jedes Eingabemerkmals zerlegt. Dieses Paket enthält zwei Hauptmethoden. Explainer() und Explanation()
model = tree.DecisionTreeRegressor() model = model.fit(train_data,y=train_labels) #necessary imports from pyBreakDown.explainer import Explainer from pyBreakDown.explanation import Explanation #make explainer object exp = Explainer(clf=model, data=train_data, colnames=feature_names) #What do you want to be explained from the data (select an observation) explanation = exp.explain(observation=data[302,:],direction="up")

7, Interpret-Text
Interpret-Text kombiniert die von der Community für NLP-Modelle entwickelte Interpretierbarkeitstechnologie und ein Visualisierungspanel zum Anzeigen von Ergebnissen. Experimente können auf mehreren hochmodernen Interpretern durchgeführt und vergleichend analysiert werden. Dieses Toolkit kann Modelle des maschinellen Lernens global für jedes Tag oder lokal für jedes Dokument interpretieren.
Hier ist die Liste der in diesem Paket verfügbaren Dolmetscher:
- Klassischer Text-Erklärer – (Standard: Wortschatz für die logistische Regression)
- Unified Information Explainer
- Introspektive Begründung. Das ist es Die Der Vorteil besteht darin, dass es Modelle wie CUDA, RNN und BERT unterstützt. Und kann ein Panel für die Wichtigkeit von Funktionen im Dokument generieren weit verbreitet auf der Plattform. AI Explainability 360 enthält einen umfassenden Satz von Algorithmen, die verschiedene Erklärungsdimensionen sowie Metriken zur Erklärbarkeit von Agenten abdecken.

- Towards Robust Interpretability with Self-Explaining Neural Networks, 2018. ref
- Boolean Decision Rules via Column Generation, 2018. ref
- Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives, 2018. ref
- Improving Simple Models with Confidence Profiles, , 2018. ref
- Efficient Data Representation by Selecting Prototypes with Importance Weights, 2019. ref
- TED: Teaching AI to Explain Its Decisions, 2019. ref
- Variational Inference of Disentangled Latent Concepts from Unlabeled Data, 2018. ref
- Generating Contrastive Explanations with Monotonic Attribute Functions, 2019. ref
- Generalized Linear Rule Models, 2019. ref
9、OmniXAI
OmniXAI (Omni explable AI的缩写),解决了在实践中解释机器学习模型产生的判断的几个问题。
它是一个用于可解释AI (XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习功能,并能够解决实践中解释机器学习模型所做决策的许多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、ML研究人员和从业者提供可解释的AI。
from omnixai.visualization.dashboard import Dashboard # Launch a dashboard for visualization dashboard = Dashboard( instances=test_instances,# The instances to explain local_explanations=local_explanations, # Set the local explanations global_explanations=global_explanations, # Set the global explanations prediction_explanations=prediction_explanations, # Set the prediction metrics class_names=class_names, # Set class names explainer=explainer# The created TabularExplainer for what if analysis ) dashboard.show()

10、XAI (eXplainable AI)
XAI 库由 The Institute for Ethical AI & ML 维护,它是根据 Responsible Machine Learning 的 8 条原则开发的。它仍处于 alpha 阶段因此请不要将其用于生产工作流程。
Das obige ist der detaillierte Inhalt vonZehn Python-Bibliotheken für erklärbare KI. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr