
Heim >Technologie-Peripheriegeräte >KI >Verwendung von Softwarevisualisierung und Transferlernen bei der Vorhersage von Softwarefehlern
Verwendung von Softwarevisualisierung und Transferlernen bei der Vorhersage von Softwarefehlern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 14:43:031637Durchsuche
Die Motivation des Artikels besteht darin, die Zwischendarstellung des Quellcodes zu vermeiden, den Quellcode als Bild darzustellen und die semantischen Informationen des Codes direkt zu extrahieren, um die Leistung der Fehlervorhersage zu verbessern.
Sehen Sie sich zunächst das Motivationsbeispiel unten an. Obwohl beide Beispiele von File1.java und File2.java 1 if-Anweisung, 2 for-Anweisungen und 4 Funktionsaufrufe enthalten, sind die Semantik und strukturellen Merkmale des Codes unterschiedlich. Um zu überprüfen, ob die Konvertierung des Quellcodes in Bilder zur Unterscheidung verschiedener Codes beitragen kann, führte der Autor ein Experiment durch: Ordnen Sie den Quellcode entsprechend der ASCII-Dezimalzahl der Zeichen Pixeln zu, ordnen Sie sie in einer Pixelmatrix an und erhalten Sie ein Bild von der Quellcode. Der Autor weist darauf hin, dass es Unterschiede zwischen verschiedenen Quellcode-Bildern gibt.

Abb. 1 Motivationsbeispiel
Die Hauptbeiträge des Artikels sind wie folgt:
Konvertieren Sie den Code in ein Bild und extrahieren Sie semantische und strukturelle Informationen daraus.
Schlagen Sie ein End-to-End-Framework vor kombiniert Selbstaufmerksamkeitsmechanismus und Migration. Lernen, Fehlervorhersagen umzusetzen.
Das im Artikel vorgeschlagene Modell-Framework ist in Abbildung 2 dargestellt und in zwei Phasen unterteilt: Quellcode-Visualisierung und Deep-Transfer-Learning-Modellierung.
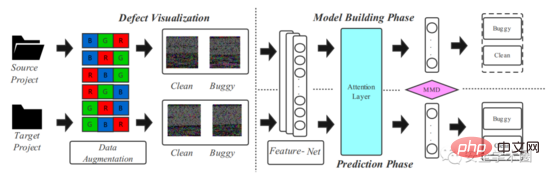
Abb. 2 Framework
1 Quellcode-Visualisierung
Der Artikel wandelt den Quellcode in 6 Bilder um und der Vorgang ist in Abbildung 3 dargestellt. Konvertieren Sie die dezimalen ASCII-Codes der Quellcodezeichen in 8-Bit-Ganzzahlvektoren ohne Vorzeichen, ordnen Sie diese Vektoren nach Zeilen und Spalten an und generieren Sie eine Bildmatrix. 8-Bit-Ganzzahlen entsprechen direkt den Graustufen. Um das Problem des kleinen Originaldatensatzes zu lösen, schlug der Autor im Artikel eine auf Farbverstärkung basierende Datensatzerweiterungsmethode vor: Die Werte der drei Farbkanäle R, G und B werden angeordnet und kombiniert, um 6 Farbbilder zu erzeugen. Es sieht hier sehr verwirrend aus, nachdem der Kanalwert geändert wurde, sollten sich die semantischen und strukturellen Informationen ändern, oder? Aber der Autor erklärt es in einer Fußnote, wie in Abbildung 4 dargestellt.
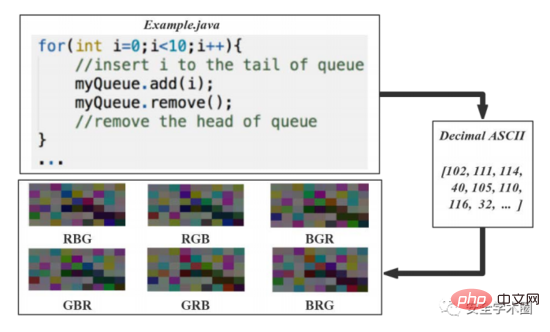
Abb. 3 Quellcode-Visualisierungsprozess

Abb. 4 Artikel-Fußnote 2
2. Der Artikel verwendet das DAN-Netzwerk, um die semantischen und strukturellen Informationen des Quellcodes zu erfassen. Um die Fähigkeit des Modells, wichtige Informationen auszudrücken, zu verbessern, fügte der Autor der ursprünglichen DAN-Struktur eine Aufmerksamkeitsschicht hinzu. Der Trainings- und Testprozess ist in Abbildung 5 dargestellt, in der conv1-conv5 von AlexNet stammt und vier vollständig verbundene Schichten fc6-fc9 als Klassifikatoren verwendet werden. Der Autor erwähnte, dass für ein neues Projekt das Training eines Deep-Learning-Modells eine große Menge an gekennzeichneten Daten erfordert, was schwierig ist. Daher trainierte der Autor zunächst ein vorab trainiertes Modell auf ImageNet 2012 und verwendete die Parameter des vorab trainierten Modells als Anfangsparameter zur Feinabstimmung aller Faltungsschichten, wodurch der Unterschied zwischen Codebildern und Bildern in ImageNet 2012 verringert wurde.
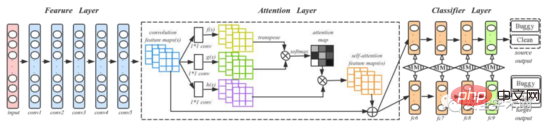 Abb. 5 Trainings- und Testprozess
Abb. 5 Trainings- und Testprozess
3. Modelltraining und Vorhersage
Generieren Sie Codebilder für den beschrifteten Code im Quellprojekt und den unbeschrifteten Code im Zielprojekt und senden Sie sie an das Modell Gleichzeitig werden die Faltungsschicht und die Aufmerksamkeitsschicht gemeinsam genutzt, um ihre jeweiligen Merkmale zu extrahieren. Berechnen Sie MK-MDD (Multi Kernel Variant Maximum Mean Discrepancy) zwischen Quelle und Ziel in der vollständig verbundenen Schicht. Da das Ziel keine Bezeichnung hat, wird die Kreuzentropie nur für die Quelle berechnet. Das Modell wird entlang der Verlustfunktion mithilfe eines stochastischen Mini-Batch-Gradientenabstiegs trainiert. Wählen Sie für jedes
Paar von 500 Epochen eine Epoche basierend auf dem besten F-Maß aus.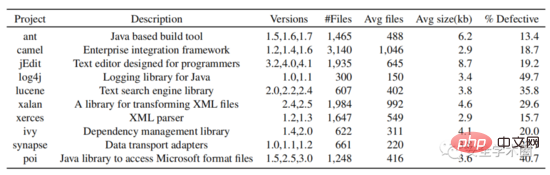 Abb. 6 Datensatzstruktur
Abb. 6 Datensatzstruktur
Für die projektinterne Fehlervorhersage wählt der Artikel das folgende Basismodell zum Vergleich:
Für die projektübergreifende Fehlervorhersage wählt der Artikel das folgende Basismodell zum Vergleich aus:

Zusammenfassend lässt sich sagen, dass die Idee, obwohl es sich um eine Arbeit vor zwei Jahren handelte, immer noch relativ neu ist und eine Reihe von Code-Zwischendarstellungen wie z als AST. Konvertieren Sie Code direkt in Bilder, um Features zu extrahieren. Aber ich bin immer noch verwirrt. Enthält das aus dem Code konvertierte Bild wirklich die semantischen und strukturellen Informationen des Quellcodes? Es fühlt sich nicht sehr erklärbar an, haha. Wir müssen später einige experimentelle Analysen durchführen.
Das obige ist der detaillierte Inhalt vonVerwendung von Softwarevisualisierung und Transferlernen bei der Vorhersage von Softwarefehlern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr