
Heim >Backend-Entwicklung >Python-Tutorial >Schreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen
Schreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 10:07:022006Durchsuche

Anhand des obigen Beispiels zum Crawlen des Kapitalflusses einzelner Aktien sollten Sie lernen, Ihren eigenen Crawling-Code zu schreiben. Konsolidieren Sie es nun und machen Sie eine ähnliche kleine Übung. Sie müssen Ihr eigenes Python-Programm schreiben, um den Geldfluss von Online-Sektoren zu crawlen. Die gecrawlte URL lautet http://data.eastmoney.com/bkzj/hy.html und die Anzeigeoberfläche ist in Abbildung 1 dargestellt.金 Abbildung 1 Die Schnittstelle der Fondsfluss-Website
1, suchen Sie nach JS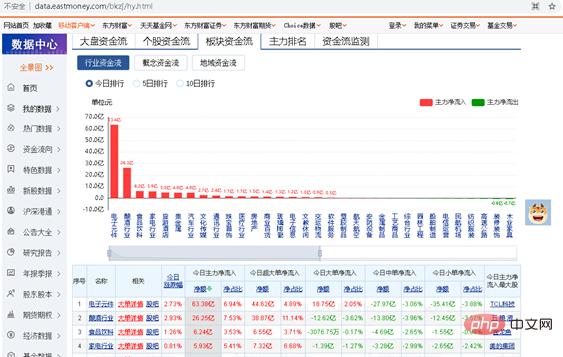
Abbildung 2 Suchen Sie die Webseite, die JS entspricht
Geben Sie dann die URL in den Browser ein. Die URL ist relativ lang. 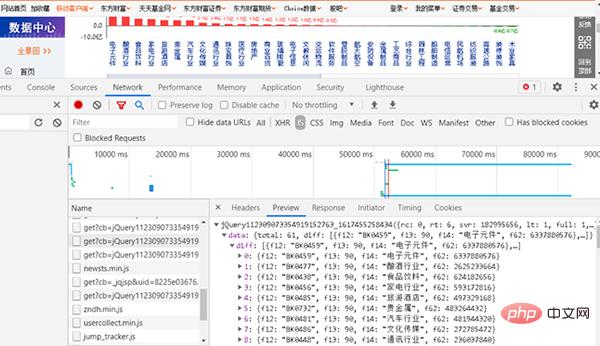
Abbildung 3 Abrufen von Abschnitten und Geldflüssen von der Website
Der dieser URL entsprechende Inhalt ist der Inhalt, den wir crawlen möchten. 
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)r.status_code zeigt 200 an, was darauf hinweist, dass der Antwortstatus normal ist. r.text verfügt auch über Daten, die darauf hinweisen, dass das Crawlen der Kapitalflussdaten erfolgreich war, wie in Abbildung 4 dargestellt.
Abbildung 4 Antwortstatus
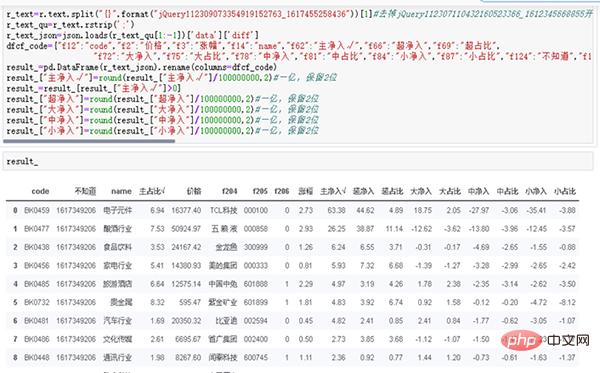
3, str in JSON-Standardformat bereinigen 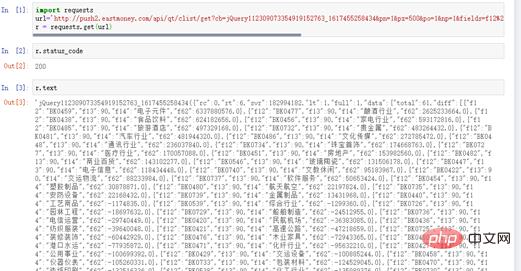
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_textDie laufenden Ergebnisse sind in Abbildung 5 dargestellt.的 Abbildung 5 Entfernen Sie die laufenden Ergebnisse des Präfixes (2) Sortieren Sie die JSON-Daten. Einzelheiten finden Sie im folgenden Code: r_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_ Die laufenden Ergebnisse sind in Abbildung 6 dargestellt.

 (3) Verwenden Sie Crawler, um Daten zu erhalten und zu speichern.
(3) Verwenden Sie Crawler, um Daten zu erhalten und zu speichern.
Durch Fallanalysen und tatsächliche Auseinandersetzungen müssen wir lernen, unseren eigenen Code zum Crawlen von Finanzdaten zu schreiben und ihn in das JSON-Standardformat konvertieren zu können. Führen Sie die täglichen Daten-Crawling- und Datenspeicherungsarbeiten durch, um eine effektive Datenunterstützung für zukünftige historische Tests und historische Datenanalysen bereitzustellen.
Natürlich können fähige Leser die Ergebnisse in Datenbanken wie MySQL, MongoDB oder sogar der Cloud-Datenbank Mongo Atlas speichern. Der Autor wird sich hier nicht auf die Erklärung konzentrieren. Wir konzentrieren uns ausschließlich auf das Studium des quantitativen Lernens und der Strategie. Durch die Verwendung des TXT-Formats zum Speichern von Daten kann das Problem der frühen Datenspeicherung vollständig gelöst werden, und die Daten sind außerdem vollständig und effektiv.
Das obige ist der detaillierte Inhalt vonSchreiben Sie ein Python-Programm, um den Geldfluss von Sektoren zu crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!