
Heim >Technologie-Peripheriegeräte >KI >Wird Verstärkungslernen überbewertet?
Wird Verstärkungslernen überbewertet?

- PHPznach vorne
- 2023-04-13 09:31:021151Durchsuche
Übersetzer |. Li Rui
Rezensent |. Sun Shujuan
verstehtdie Spielregeln nicht. Aber Diese App versteht, dass sie danach strebt, ein Ziel zu erreichen, nämlich im Spiel zu gewinnen. Da das Computerprogramm die Regeln nicht kennt, sind die Züge, mit denen Sie anfangen, Schach zu spielen, zufällig. Einige dieser Tricks sind völlig bedeutungslos und werden für Sie leicht zu gewinnen sein. Nehmen wir an, dass es Ihnen so viel Spaß macht, mit diesem Freund Schach zu spielen, dass Sie süchtig nach dem Spiel sind.
Aber das Computerprogramm wird irgendwann gewinnen, weil es nach und nach Wege und Tricks lernen wird, um dich zu besiegencount. Obwohl dieses hypothetische Szenario
weit hergeholt erscheinen mag, sollte es Ihnen ein grundlegendes Verständnis dafür vermitteln, wie Reinforcement Learning (ein Bereich des maschinellen Lernens) im Allgemeinen funktioniert. Wie intelligent ist Reinforcement Learning? Die menschliche Intelligenz umfasst viele Eigenschaften, darunter den Erwerb von Wissen, den Wunsch, intellektuelle Fähigkeiten zu erweitern, und intuitives Denken. Die menschliche Intelligenz wurde in Zweifel gezogen, als Schachweltmeister Garry Kasparov gegen einen IBM-Computer namens Deep Blue verlor. Apokalyptische Szenarien, die eine Zukunft darstellen, in der Roboter die Menschheit beherrschen, erregen nicht nur die Aufmerksamkeit der Öffentlichkeit, sondern beherrschen auch das Mainstream-Bewusstsein. Allerdings ist „Deep Blue“
kein gewöhnlicher Gegner. Schach spielen mit diesem
mit diesem
Berechnungsprogramm
ist wie Schach spielen mit einem tausendjährigen alten
Mann, der ununterbrochen Schach gespielt hat. Sein ganzes Leben lang . Aber „Deep Blue“ ist gut darin, ein bestimmtes Spiel zu spielen, nicht aber andere intellektuelle Aktivitäten wie das Spielen eines Instruments, ein Buch schreiben, die Durchführung wissenschaftlicher Experimente, Kindererziehung oder das Reparieren von Autos. Dies soll auf keinen Fall die Errungenschaften von „Deep Blue“ schmälern . Im Gegensatz zu bedarf die Vorstellung, dass Computer den Menschen an intellektuellen Fähigkeiten übertreffen können, einer sorgfältigen Prüfung, beginnend mit einer Analyse, wie Reinforcement Learning funktioniert . Wie Reinforcement Learning funktioniert? kumulative Belohnungen.
Einfach ausgedrückt: Bestärkendes LernenRoboter werden mit einem Belohnungs- und Bestrafungsmechanismus trainiert, Sie werden für richtige Handlungen belohnt, und falsche Handlungen werden für falsche Handlungen bestraft. Reinforcement Learning Bots „denken“ nicht, wie man bessere Maßnahmen ergreifen kann, sie machen einfach alle Maßnahmen möglich, um die Erfolgsaussichten zu maximieren.
Nachteile des Reinforcement Learning
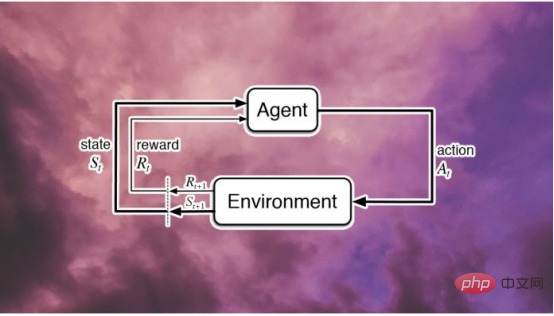
Der Hauptnachteil des Reinforcement Learning besteht darin, dass es den Einsatz einer großen Menge an Ressourcen erfordert, um seine Ziele zu erreichen. Der Erfolg des Reinforcement Learning im Go-Spiel verdeutlicht diesen Punkt. Hierbei handelt es sich um ein beliebtes Spiel für zwei Spieler, bei dem das Ziel darin besteht, mit den eigenen Figuren die größtmögliche Fläche auf dem Spielbrett zu besetzen und gleichzeitig den Verlust von Figuren zu vermeiden.
AlphaGo Master ist ein Computerprogramm, das menschliche Spieler im Go-Spiel schlägt. Es verbraucht viel Geld und Arbeitskraft, darunter viele Ingenieure, sehr umfangreiche Spielerfahrung sowie 256 GPUs und 128.000 CPUs.
In den Prozess zu lernen, wie man das Spiel gewinnt, müssen viele Ressourcen und Energie investiert werden. Das wirft die Frage auf: Ist es sinnvoll, eine KI zu entwickeln, die nicht intuitiv denken kann? Sollte die KI-Forschung nicht versuchen, die menschliche Intelligenz zu imitieren? KI verhält sich wie ein Mensch und ihr Einsatz zur Lösung komplexer Probleme erfordert eine Weiterentwicklung. Gegen Reinforcement Learning spricht dagegen, dass sich die KI-Forschung darauf konzentrieren sollte, Maschinen dazu zu bringen, Dinge zu tun, zu denen derzeit nur Menschen und Tiere in der Lage sind. Aus dieser Perspektive ist der Vergleich zwischen künstlicher Intelligenz und menschlicher Intelligenz angebracht.
Quantum Reinforcement LearningReinforcement Learning ist ein aufstrebendes Feld, das angeblich einige der oben genannten Probleme lösen kann. Quantum Reinforcement Learning (QRL) ist eine Methode zur Beschleunigung des Rechnens.
Erstens soll Quantum Reinforcement Learning (QRL) das Lernen beschleunigen, indem die Phasen der Exploration (Entdeckung der Strategie) und Exploitation (Auswahl der besten Strategie) optimiert werden. Einige aktuelle Anwendungen und vorgeschlagene Quantencomputer verbessern die Datenbanksuche, faktorisieren große Zahlen in Primzahlen und vieles mehr.
Obwohl Quantum Reinforcement Learning (QRL) nicht auf bahnbrechende Weise entstanden ist, verspricht es, einige der größten Herausforderungen des konventionellen Reinforcement Learning zu lösen.
Business Case für Reinforcement Learning
Wie oben erwähnt, ist die Forschung und Entwicklung von Reinforcement Learning von entscheidender Bedeutung. Hier sind einige praktische Beispiele für Reinforcement Learning aus einer McKinsey & Company-Umfrage, die Folgendes bewirken können:
- Optimieren Sie das Halbleiter- und Chipdesign, optimieren Sie Herstellungsprozesse und steigern Sie die Produktion der Halbleiterindustrie.
- Steigern Sie die Fabrikproduktion, optimieren Sie die Logistik, um Abfall und Kosten zu reduzieren und steigern Sie die landwirtschaftlichen Gewinne.
- Reduzieren Sie die Markteinführungszeit für neue Systeme in der Luft- und Raumfahrt- und Verteidigungsindustrie.
- Optimieren Sie den Designprozess und verbessern Sie die Produktionseffizienz der Automobilindustrie.
- Steigern Sie den Umsatz, verbessern Sie das Kundenerlebnis und bieten Sie Kunden erweiterte Personalisierung bei Finanzdienstleistungen durch Echtzeittransaktionen und Preisstrategien .
- Minendesign optimieren, Stromerzeugung verwalten, allgemeine Logistikplanung anwenden, Abläufe optimieren, Kosten senken und Produktion steigern.
- Steigern Sie die Produktion durch Echtzeitüberwachung und präzises Bohren, optimieren Sie die Fahrtrouten von Tankern, erreichen Sie vorausschauende Wartung und verhindern Sie Geräteausfälle die Öl- und Gasindustrie.
- Arzneimittelentwicklung fördern, Forschungsprozesse optimieren, Produktion automatisieren und Biomethoden in der Pharmaindustrie optimieren.
- Optimieren Sie die Lieferkette, implementieren Sie eine erweiterte Bestandsmodellierung und bieten Sie Kunden im Einzelhandel fortschrittliche personalisierte Dienstleistungen an.
- Optimieren und verwalten Sie Netzwerke und wenden Sie Kundenpersonalisierung in der Telekommunikationsbranche an.
- Optimieren Sie Transportlogistikrouten, Netzwerkplanung und Lagerabläufe.
- Verwenden Sie Proxys der nächsten Generation, um Daten von Websites zu extrahieren .
Reflexion über verstärkendes Lernen
Die Fähigkeit, das Lernen zu stärken, kann begrenzt sein, aber es wird nicht überbewertet. Darüber hinaus nehmen mit der Zunahme von Forschungs- und Entwicklungsprojekten für Reinforcement Learning auch die potenziellen Anwendungsfälle in nahezu allen Wirtschaftszweigen zu.
Die groß angelegte Einführung von Reinforcement Learning hängt von mehreren Faktoren ab, darunter der Optimierung des Algorithmusdesigns, der Konfiguration der Lernumgebung usw Verfügbarkeit von Rechenleistung.
Originaltitel: Wird Verstärkungslernen überbewertet? Aleksandras Šulženko 🎜 🎜#
Das obige ist der detaillierte Inhalt vonWird Verstärkungslernen überbewertet?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr