
Heim >Technologie-Peripheriegeräte >KI >In einem Artikel wird kurz die Generalisierungsfähigkeit von Deep Learning erörtert
In einem Artikel wird kurz die Generalisierungsfähigkeit von Deep Learning erörtert

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 09:19:021182Durchsuche

1. Das Problem der DNN-Generalisierungsfähigkeit
Der Artikel diskutiert hauptsächlich, warum das überparametrisierte neuronale Netzwerkmodell eine gute Generalisierungsleistung haben kann? Das heißt, es merkt sich nicht einfach den Trainingssatz, sondern fasst eine allgemeine Regel aus dem Trainingssatz zusammen, sodass diese an den Testsatz angepasst werden kann (Verallgemeinerungsfähigkeit).

Nehmen Sie das klassische Entscheidungsbaummodell als Beispiel: Wenn das Baummodell die allgemeinen Regeln des Datensatzes lernt: Eine gute Situation ist, dass der Baum, wenn er zuerst den Knoten teilt, nur Proben mit unterschiedlichen Bezeichnungen gut unterscheiden kann Da die Tiefe sehr gering ist und die entsprechende Anzahl von Stichproben auf jedem Blatt ausreicht (dh die auf statistischen Regeln basierende Datenmenge ist ebenfalls relativ groß), ist es wahrscheinlicher, dass die erhaltenen Regeln auf andere Daten verallgemeinert werden . (d. h. gute Anpassungsfähigkeit und Generalisierungsfähigkeit).
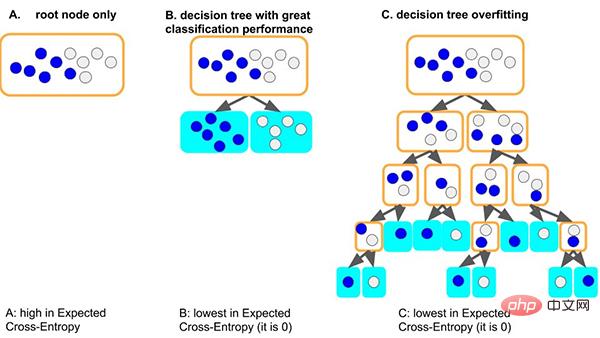
Eine weitere schlimmere Situation besteht darin, dass, wenn der Baum einige allgemeine Regeln nicht lernen kann, der Baum zum Erlernen dieses Datensatzes immer tiefer wird und jeder Blattknoten einer kleinen Anzahl von Stichproben (weniger) entsprechen kann Die durch die Daten gelieferten statistischen Informationen können nur Rauschen sein. Und schließlich müssen alle Daten auswendig gelernt werden (d. h. Überanpassung und keine Verallgemeinerungsfähigkeit). Wir können sehen, dass zu tiefe Baummodelle leicht überpassen können.
Wie kann also ein überparametrisiertes neuronales Netzwerk eine gute Generalisierung erreichen?
2. Die Gründe für die Generalisierungsfähigkeit von DNN
Dieser Artikel erläutert aus einer einfachen und allgemeinen Perspektive die Gründe für die Generalisierungsfähigkeit im Gradientenabstiegsoptimierungsprozess neuronaler Netze:
Wir haben die Gradientenkohärenztheorie zusammengefasst: Aus den Gradienten verschiedener Proben entsteht Kohärenz, weshalb neuronale Netze über gute Generalisierungsfähigkeiten verfügen. Wenn die Gradienten verschiedener Proben während des Trainings gut ausgerichtet sind, das heißt, wenn sie kohärent sind, ist der Gradientenabstieg stabil, kann schnell konvergieren und das resultierende Modell kann gut verallgemeinert werden. Andernfalls kann es zu keiner Verallgemeinerung kommen, wenn zu wenige Stichproben vorhanden sind oder die Trainingszeit zu lang ist.

Basierend auf dieser Theorie können wir die folgende Erklärung abgeben.
2.1 Generalisierung breiter neuronaler Netze
Modelle breiterer neuronaler Netze verfügen über gute Generalisierungsfähigkeiten. Dies liegt daran, dass größere Netzwerke über mehr Subnetzwerke verfügen und mit größerer Wahrscheinlichkeit eine Gradientenkohärenz erzeugen als kleinere Netzwerke, was zu einer besseren Generalisierung führt. Mit anderen Worten, der Gradientenabstieg ist ein Merkmalsselektor, der Generalisierungsgradienten (Kohärenzgradienten) priorisiert, und breitere Netzwerke können bessere Merkmale aufweisen, einfach weil sie mehr Merkmale haben.
- Originalarbeit: Generalisierung und Breite [2018b] haben herausgefunden, dass breitere Netzwerke auf jeder Ebene mehr Subnetzwerke haben mit maximaler Kohärenz in einem breiteren Netzwerk kann kohärenter sein als sein Gegenstück in einem dünneren Netzwerk und lässt sich daher besser verallgemeinern. Mit anderen Worten, da – wie in Abschnitt 10 erläutert – der Gradientenabstieg ein Merkmalsselektor ist, der eine gute Verallgemeinerung (kohärent) priorisiert. Breitere Netzwerke verfügen wahrscheinlich einfach deshalb über bessere Funktionen, weil sie über mehr Funktionen verfügen. Siehe in diesem Zusammenhang auch die Lottery Ticket Hypothesis [Frankle und Carbin, 2018]
- Papierlink: https://github.com/aialgorithm/Blog
Aber ich persönlich denke, es muss immer noch zwischen der Breite der Netzwerkeingabeschicht und der verborgenen Schicht unterschieden werden. Insbesondere für die Eingabeebene von Data-Mining-Aufgaben müssen Sie die Feature-Auswahl in Betracht ziehen (d. h. die Breite der Eingabeebene verringern), da die Eingabe-Features normalerweise manuell entworfen werden. Andernfalls wird die Gradientenkohärenz durch die direkte Eingabe von Feature-Rauschen beeinträchtigt . .
2.2 Generalisierung tiefer neuronaler Netze
Je tiefer das Netzwerk ist, desto stärker wird das Phänomen der Gradientenkohärenz und die Generalisierungsfähigkeit ist besser.

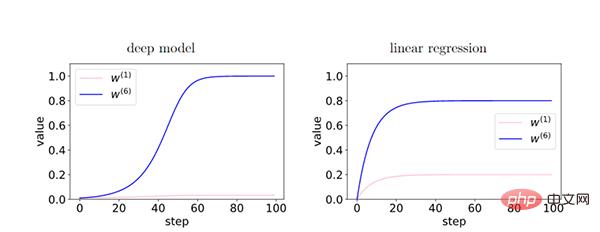
Da im Tiefenmodell die Rückkopplung zwischen den Schichten den kohärenten Gradienten stärkt, besteht während des Trainingsprozesses ein relativer Unterschied zwischen den Merkmalen des kohärenten Gradienten (W6) und den Merkmalen des inkohärenten Gradienten (W1) Exponentiell verstärkt. Dies führt dazu, dass tiefere Netzwerke kohärente Gradienten bevorzugen, was zu besseren Generalisierungsfähigkeiten führt.
2.3 Frühes Stoppen
Durch frühes Stoppen können wir den übermäßigen Einfluss inkohärenter Gradienten reduzieren und die Generalisierung verbessern.
Während des Trainings passen einige einfache Proben früher als andere Proben (harte Proben). In der frühen Trainingsphase dominiert der Korrelationsgradient dieser einfachen Stichproben und lässt sich leicht anpassen. In der späteren Trainingsphase dominiert der inkohärente Gradient schwieriger Proben den durchschnittlichen Gradienten g (wt), was zu einer schlechten Generalisierungsfähigkeit führt. Zu diesem Zeitpunkt ist es notwendig, frühzeitig aufzuhören.

- (Hinweis: Einfache Stichproben sind solche, die viele Steigungen im Datensatz gemeinsam haben. Aus diesem Grund sind die meisten Steigungen vorteilhaft und konvergieren schneller.)
2.4 Vollgradientenabstieg vs. Lernrate
Wir haben festgestellt, dass ein vollständiger Gradientenabstieg auch eine gute Generalisierungsfähigkeit aufweisen kann. Darüber hinaus zeigen sorgfältige Experimente, dass der stochastische Gradientenabstieg nicht unbedingt zu einer besseren Verallgemeinerung führt. Dies schließt jedoch nicht die Möglichkeit aus, dass stochastische Gradienten eher aus lokalen Minima herausspringen, eine Rolle bei der Regularisierung spielen usw.
- Basierend auf unserer Theorie sind endliche Lernrate und Mini-Batch-Stochastizität für die Generalisierung nicht erforderlich.
Wir glauben, dass eine niedrigere Lernrate den Generalisierungsfehler möglicherweise nicht verringert, da eine niedrigere Lernrate mehr Iterationen bedeutet (das Gegenteil des vorzeitigen Anhaltens).
- Unter der Annahme einer ausreichend kleinen Lernrate kann sich die Generalisierungslücke mit fortschreitendem Training nicht verringern. Dies folgt aus der iterativen Stabilitätsanalyse des Trainings: Mit 40 weiteren Schritten kann sich die Stabilität nur verschlechtern würde auf eine interessante Einschränkung der Theorie hinweisen. w) und der L2-Gradient ist w. Am Beispiel der L2-Regularisierung lautet die entsprechende Aktualisierungsformel für den Gradienten W(i+1): Bild
Wir können „L2-Regularisierung (Gewichtsabschwächung)“ als „Hintergrundkraft“ betrachten und jeden Parameter drücken nahe an einem datenunabhängigen Nullwert (mit L1 lässt sich leicht eine spärliche Lösung erhalten, mit L2 lässt sich leicht eine glatte Lösung nahe 0 erhalten), um den Einfluss in der Richtung des schwachen Gradienten zu eliminieren. Nur bei kohärenten Gradientenrichtungen können die Parameter relativ von der „Hintergrundkraft“ getrennt und die Gradientenaktualisierung auf Basis der Daten abgeschlossen werden.
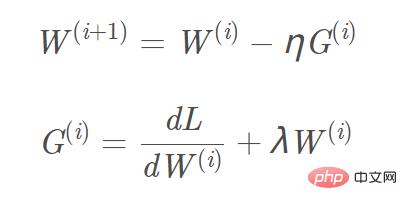
2.6 Weiterentwicklung des Gradientenabstiegsalgorithmus
 Momentum, Adam und andere Gradientenabstiegsalgorithmen
Momentum, Adam und andere Gradientenabstiegsalgorithmen
- Gradientenabstieg in schwachen Gradientenrichtungen unterdrücken
Zusammenfassung
Ein paar Worte am Ende des Artikels. Wenn Sie sich für die Theorie des Deep Learning interessieren, können Sie die im Artikel erwähnte verwandte Forschung lesen. 

Das obige ist der detaillierte Inhalt vonIn einem Artikel wird kurz die Generalisierungsfähigkeit von Deep Learning erörtert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr