
Heim >Backend-Entwicklung >Python-Tutorial >Super einfach! Entfernen Sie Wasserzeichen aus Bildern und PDFs mit Python
Super einfach! Entfernen Sie Wasserzeichen aus Bildern und PDFs mit Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 23:43:012692Durchsuche

Einige online heruntergeladene PDF-Lernmaterialien weisen Wasserzeichen auf, was das Lesen erheblich beeinträchtigt. Das folgende Bild wurde beispielsweise aus einer PDF-Datei ausgeschnitten. Heute werden wir Python verwenden, um dieses Problem zu lösen.

Installieren Sie das Modul
PIL: Die Python Imaging Library ist eine sehr leistungsstarke Standardbibliothek für die Bildverarbeitung in Python, kann jedoch nur Python 2.7 unterstützen. Daher haben einige Freiwillige ein Kissen erstellt, das Python 3 basierend auf PIL unterstützt einige neue Funktionen.
pip install pillow
pymupdf kann Python verwenden, um auf Dateien mit den Erweiterungen *.pdf, .xps, .oxps, .epub, .cbz oder *.fb2 zuzugreifen. Viele gängige Bildformate werden ebenfalls unterstützt, einschließlich mehrseitiger TIFF-Bilder.
pip install PyMuPDF
Importieren Sie die Module, die Sie verwenden müssen. Holen Sie sich das RGB-PDF des Bildes. Das Prinzip der Wasserzeichenentfernung ähnelt dem der Bildwasserzeichenentfernung.
Freunde, die sich mit Computern beschäftigt haben, wissen alle, dass RGB in Computern für Rot, Grün und Blau steht, (255, 0, 0) für Rot, (0, 255, 0) für Grün und (0, 0, 255) für Blau , (255, 255, 255) steht für Weiß, (0, 0, 0) steht für Schwarz. Das Prinzip der Wasserzeichenentfernung besteht darin, die Farbe des Wasserzeichens in Weiß (255, 255, 255) zu ändern.
Ermitteln Sie zunächst die Breite und Höhe des Bildes und verwenden Sie das Modul itertools, um das kartesische Produkt aus Breite und Höhe in Pixeln zu erhalten. Die Farbe jedes Pixels setzt sich aus den ersten drei Bits von RGB und dem vierten Bit des Alpha-Kanals zusammen. Ein Alphakanal ist nicht erforderlich, nur RGB-Daten.
from PIL import Image from itertools import product import fitz import os
Wasserzeichen aus Bildern entfernen
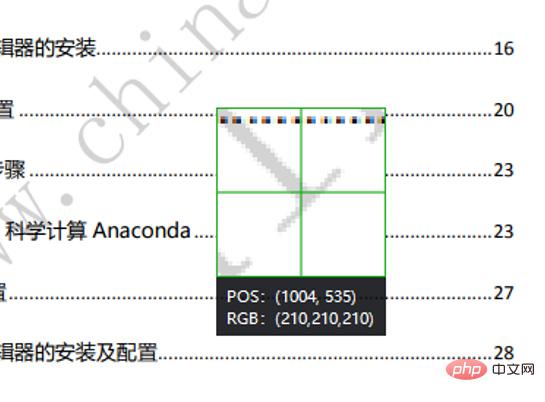
Verwenden Sie den WeChat-Screenshot, um das RGB der Wasserzeichenpixel anzuzeigen.
Sie können sehen, dass der RGB-Wert des Wasserzeichens (210, 210, 210) beträgt. Wenn die RGB-Summe 620 überschreitet, wird die Pixelfarbe zu diesem Zeitpunkt bestimmt durch Weiß ersetzt. Speichern Sie abschließend das Bild.def remove_img():
image_file = input("请输入图片地址:")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)
 Beispielergebnisse:
PDF-Wasserzeichenentfernung
Beispielergebnisse:
PDF-Wasserzeichenentfernung PDF Das Prinzip der Wasserzeichenentfernung ist ungefähr das gleiche wie das Prinzip der Bildwasserzeichenentfernung. Nach dem Öffnen der PDF-Datei mit PyMuPDF wird jede Seite der PDF-Datei konvertiert ein Bild pixmap, pixmap Es hat sein eigenes RGB. Ändern Sie einfach das RGB im PDF-Wasserzeichen in (255, 255, 255) und speichern Sie es schließlich als Bild.
PDF Das Prinzip der Wasserzeichenentfernung ist ungefähr das gleiche wie das Prinzip der Bildwasserzeichenentfernung. Nach dem Öffnen der PDF-Datei mit PyMuPDF wird jede Seite der PDF-Datei konvertiert ein Bild pixmap, pixmap Es hat sein eigenes RGB. Ändern Sie einfach das RGB im PDF-Wasserzeichen in (255, 255, 255) und speichern Sie es schließlich als Bild.
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')
Beispielergebnisse:
Bilder in PDF konvertieren Bilder in PDF konvertieren Zu beachten ist, dass numerische Dateinamen zuerst in den Typ „int“ konvertiert und dann sortiert werden müssen. Nachdem Sie das Bild mit dem PyMuPDF-Modul geöffnet haben, verwenden Sie die Funktion „convertToPDF()“, um das Bild in ein einseitiges PDF zu konvertieren. In neue PDF-Datei einfügen.
Bilder in PDF konvertieren Zu beachten ist, dass numerische Dateinamen zuerst in den Typ „int“ konvertiert und dann sortiert werden müssen. Nachdem Sie das Bild mit dem PyMuPDF-Modul geöffnet haben, verwenden Sie die Funktion „convertToPDF()“, um das Bild in ein einseitiges PDF zu konvertieren. In neue PDF-Datei einfügen.
def remove_pdf():
page_num = 0
pdf_file = input("请输入 pdf 地址:")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f"第{page_num}水印去除完成")
page_num = page_num + 1
Zusammenfassung
Die lästigen Wasserzeichen auf PDFs und Bildern können endlich vor dem leistungsstarken Python verschwinden. Habt ihr genug gelernt?
Das obige ist der detaillierte Inhalt vonSuper einfach! Entfernen Sie Wasserzeichen aus Bildern und PDFs mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!