
Heim >Technologie-Peripheriegeräte >KI >Reichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort
Reichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 22:49:071226Durchsuche
Deep-Learning-Forscher lassen sich von den Neuro- und Kognitionswissenschaften inspirieren – von versteckten Einheiten und Eingabemethoden bis hin zum Design von Netzwerkverbindungen und Netzwerkarchitekturen – viele bahnbrechende Studien basieren auf der Nachahmung von Gehirnoperationsstrategien. Es besteht kein Zweifel, dass Modularität und Aufmerksamkeit in den letzten Jahren häufig in künstlichen Netzwerken kombiniert eingesetzt wurden und beeindruckende Ergebnisse erzielt haben.
Tatsächlich zeigt die kognitive Neurowissenschaft, dass die Großhirnrinde Wissen auf modulare Weise darstellt, zwischen verschiedenen Modulen kommuniziert und der Aufmerksamkeitsmechanismus die Inhaltsauswahl durchführt. Dies ist die oben erwähnte Kombination von Modularität und Aufmerksamkeit. In neueren Forschungen wurde vermutet, dass dieser Kommunikationsmodus im Gehirn Auswirkungen auf die induktive Verzerrung in tiefen Netzwerken haben könnte. Die spärlichen Abhängigkeiten zwischen diesen Variablen auf hoher Ebene zerlegen das Wissen in rekombinierbare Fragmente, die möglichst unabhängig sind, was das Lernen effizienter macht.
Obwohl sich ein Großteil der neueren Forschung auf solche modularen Architekturen stützt, verwenden Forscher eine Vielzahl von Tricks und Architekturmodifikationen, was es schwierig macht, echte, nutzbare Architekturprinzipien zu analysieren.
Maschinelle Lernsysteme zeigen nach und nach die Vorteile spärlicherer und modularerer Architekturen, die nicht nur eine gute Generalisierungsleistung, sondern auch eine bessere Out-of-Distribution (OoD)-Leistung und Skalierbarkeit bieten Interpretierbarkeit. Ein Schlüssel zum Erfolg solcher Systeme liegt darin, dass davon ausgegangen wird, dass datengenerierende Systeme, die in realen Umgebungen verwendet werden, aus kaum interagierenden Teilen bestehen, und es wäre hilfreich, dem Modell eine ähnliche induktive Ausrichtung zu verleihen. Da diese realen Datenverteilungen jedoch komplex und unbekannt sind, mangelt es auf diesem Gebiet an strengen quantitativen Bewertungen dieser Systeme.
Ein Artikel von drei Forschern der Universität Montreal, Sarthak Mittal, Yoshua Bengio und Guillaume Lajoie, die eine umfassende Bewertung gängiger modularer Architekturen durch einfache und bekannte modulare Datenverteilung durchgeführt haben. Die Studie beleuchtet die Vorteile von Modularität und Sparsity und gibt Einblicke in die Herausforderungen bei der Optimierung modularer Systeme. Der Erstautor und korrespondierende Autor, Sarthak Mittal, ist ein Meisterschüler von Bengio und Lajoie.

- Paper -Adresse: https://arxiv.org/pdf/2206.02713.pdf
- github Adresse: https://github.com/sarthmit/mod_arch
specifical, diese, Die Studie erweitert die Analyse von Rosenbaum et al. und schlägt eine Methode zur Bewertung, Quantifizierung und Analyse gemeinsamer Komponenten modularer Architekturen vor. Zu diesem Zweck entwickelte die Forschung eine Reihe von Benchmarks und Metriken, um die Wirksamkeit modularer Netzwerke zu untersuchen. Daraus ergeben sich wertvolle Erkenntnisse, die nicht nur dabei helfen, herauszufinden, wo aktuelle Ansätze erfolgreich sind, sondern auch, wann und wie diese Ansätze scheitern.
Der Beitrag dieser Forschung kann wie folgt zusammengefasst werden:
- Diese Forschung entwickelt Benchmark-Aufgaben und Metriken auf der Grundlage probabilistischer Auswahlregeln und verwendet Benchmarks und Metriken, um zwei wichtige Phänomene in modularen Systemen zu quantifizieren: Kollaps und Spezialisierung, Spezialisierung.
- Diese Studie extrahiert häufig verwendete modulare induktive Vorspannungen und bewertet sie systematisch anhand einer Reihe von Modellen, die darauf ausgelegt sind, häufig verwendete architektonische Eigenschaften zu extrahieren (monolithische, modulare, modular-optische, GT-modulare Modelle).
- Die Studie ergab, dass die Spezialisierung auf modulare Systeme die Modellleistung erheblich verbessern kann, wenn eine Aufgabe viele latente Regeln enthält, nicht jedoch, wenn nur wenige vorhanden sind.
- Die Studie ergab, dass standardmäßige modulare Systeme sowohl hinsichtlich ihrer Fähigkeit, sich auf die richtigen Informationen zu konzentrieren, als auch hinsichtlich ihrer Spezialisierungsfähigkeit tendenziell suboptimal sind, was auf die Notwendigkeit einer zusätzlichen induktiven Voreingenommenheit hindeutet.
Definition/Terminologie
In diesem Artikel untersuchen wir, wie eine Reihe modularer Systeme allgemeine Aufgaben ausführen, die durch einen synthetischen Datengenerierungsprozess formuliert werden, den wir Regeldaten nennen. Sie stellen die Definition von Schlüsselkomponenten vor, einschließlich (1) Regeln und wie diese Regeln Aufgaben bilden, (2) Module und wie diese Module unterschiedliche Modellarchitekturen übernehmen, (3) Spezialisierung und wie Modelle bewertet werden. Die detaillierten Einstellungen sind in Abbildung 1 unten dargestellt.

Regeln. Um modulare Systeme richtig zu verstehen und ihre Vor- und Nachteile zu analysieren, haben die Forscher einen umfassenden Aufbau in Betracht gezogen, der eine feinkörnige Kontrolle über verschiedene Aufgabenanforderungen ermöglicht. Insbesondere müssen Operationen, die sie Regeln nennen, auf den in Gleichung 1-3 unten gezeigten datengenerierenden Verteilungen erlernt werden.

Angesichts der obigen Verteilung definiert der Forscher eine Regel, um sein Experte zu werden, das heißt, die Regel r ist als p_y(·|x, c = r) definiert, wobei c die darstellende Klassifizierung ist die Kontextvariable, x ist die Eingabesequenz.
Mission. Eine Aufgabe wird durch eine Reihe von Regeln (Datenerzeugungsverteilungen) beschrieben, die in Gleichung 1-3 dargestellt sind. Unterschiedliche Mengen von {p_y(· | x, c)}_c bedeuten unterschiedliche Aufgaben. Für eine bestimmte Anzahl von Regeln wird das Modell auf mehrere Aufgaben trainiert, um aufgabenspezifische Verzerrungen zu beseitigen.
Modul. Ein modulares System besteht aus einer Reihe neuronaler Netzwerkmodule, wobei jedes Modul zur Gesamtleistung beiträgt. Dies lässt sich anhand der folgenden Funktionsform erkennen.

wobei y_m die Ausgabe und p_m die Aktivierung des m^-ten Moduls darstellt.
Modellarchitektur. Die Modellarchitektur beschreibt, welche Architektur für jedes Modul eines modularen Systems oder für einzelne Module eines monolithischen Systems gewählt wird. In diesem Artikel erwägen die Forscher die Verwendung von Multi-Layer-Perceptron (MLP), Multi-Head-Attention (MHA) und Recurrent Neural Network (RNN). Es ist wichtig, dass die Regeln (oder datengenerierenden Verteilungen) an die Modellarchitektur angepasst werden, beispielsweise MLP-basierte Regeln.
Prozess der Datengenerierung
Da die Forscher darauf abzielen, modulare Systeme anhand synthetischer Daten zu erforschen, beschreiben sie den Prozess der Datengenerierung basierend auf dem oben beschriebenen Regelschema. Konkret verwendeten die Forscher einen einfachen Datengenerierungsprozess im Mixed-of-Experts-Stil (MoE) in der Hoffnung, dass unterschiedliche Module für unterschiedliche Experten in den Regeln spezialisiert werden könnten.
Sie erklären den Datengenerierungsprozess für drei Modellarchitekturen: MLP, MHA und RNN. Darüber hinaus gibt es unter jeder Aufgabe zwei Versionen: Regression und Klassifizierung.
MLP. Die Forscher definierten ein für das Lernen geeignetes Datenschema auf Basis modularer MLP-Systeme. Bei diesem Schema zur Generierung synthetischer Daten besteht eine Datenstichprobe aus zwei unabhängigen Zahlen und einer regulären Auswahl, die aus einer bestimmten Verteilung entnommen wird. Unterschiedliche Regeln erzeugen unterschiedliche lineare Kombinationen zweier Zahlen, um eine Ausgabe zu liefern. Das heißt, die Auswahl der linearen Kombination wird gemäß den Regeln dynamisch instanziiert, wie in Gleichung 4-6 unten dargestellt.
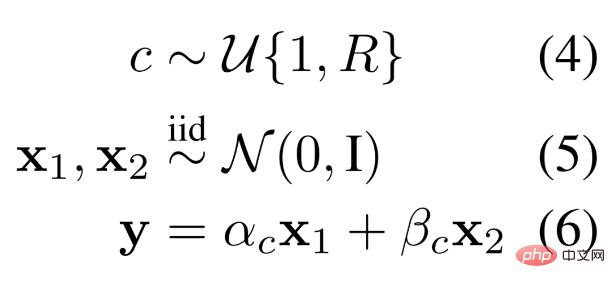

MHA. Jetzt haben Forscher ein Datenschema definiert, das auf das Lernen in einem modularen MHA-System abgestimmt ist. Daher entwarfen sie eine Datengenerierungsverteilung mit der folgenden Eigenschaft: Jede Regel besteht aus unterschiedlichen Such- und Abrufkonzepten und der endgültigen linearen Kombination der abgerufenen Informationen. Forscher beschreiben diesen Prozess mathematisch in der folgenden Gleichung 7-11.

RNN. Für Kreislaufsysteme definierten die Forscher Regeln für ein lineares dynamisches System, bei dem zu jedem Zeitpunkt eine von mehreren Regeln ausgelöst werden kann. Mathematisch wird dieser Prozess in der folgenden Gleichung 12-15 dargestellt.

Modell
Einige frühere Arbeiten behaupteten, dass durchgängig trainierte Modulsysteme monolithischen Systemen überlegen seien, insbesondere in verteilten Umgebungen. Eine detaillierte und tiefgreifende Analyse der Vorteile dieser modularen Systeme und der Frage, ob sie sich aufgrund der Verteilung der Datengenerierung tatsächlich spezialisieren, fehlt jedoch.
Daher betrachteten die Forscher vier Arten von Modellen, die unterschiedliche Spezialisierungsgrade ermöglichen, nämlich monolithisch (einzeln), modular (modular), modular-op und GT-modular. Tabelle 1 unten veranschaulicht diese Modelle.

Monolithisch. Ein monolithisches System ist ein großes neuronales Netzwerk, das einen ganzen Datensatz (x, c) als Eingabe verwendet und darauf basierend eine Vorhersage y^ trifft. Es gibt keine induktive Voreingenommenheit hinsichtlich der Modularität oder Spärlichkeit des im System eingebetteten expliziten Inhalts, und es beruht vollständig auf Backpropagation, um zu lernen, welche funktionale Form zur Lösung der Aufgabe erforderlich ist.
Modular. Ein modulares System besteht aus vielen Modulen, von denen jedes ein neuronales Netzwerk eines bestimmten Architekturtyps (MLP, MHA oder RNN) ist. Jedes Modul m verwendet Daten (x, c) als Eingabe und berechnet eine Ausgabe yˆ_m und einen Konfidenzwert, der über Module hinweg auf die Aktivierungswahrscheinlichkeit p_m normiert wird.
Modular-op. Ein modulares Betriebssystem ist einem modularen System sehr ähnlich, mit einem Unterschied. Anstatt die Aktivierungswahrscheinlichkeit p_m des Moduls m als Funktion von (x, c) zu definieren, stellten die Forscher sicher, dass die Aktivierung nur durch den Regelkontext C bestimmt wird.
GT-Modular. Als Orakel-Benchmark dienen modulare Systeme mit echtem Wert, d. h. perfekt spezialisierte modulare Systeme.
Forscher zeigen, dass Modelle von monolithischen bis hin zu GT-modularen Modellen zunehmend induktive Vorspannungen für Modularität und Sparsität enthalten.
Metriken
Um modulare Systeme zuverlässig zu bewerten, haben Forscher eine Reihe von Metriken vorgeschlagen, die nicht nur die Leistungsvorteile solcher Systeme messen, sondern sie auch in zwei wichtigen Formen bewerten: Zusammenbruch und Spezialisierung.
Leistung. Der erste Satz von Bewertungsmetriken basiert auf der Leistung sowohl in In-Distribution- als auch in Out-of-Distribution-Umgebungen (OoD) und spiegelt die Leistung verschiedener Modelle bei verschiedenen Aufgaben wider. Für die Klassifizierungseinstellung melden wir den Klassifizierungsfehler; für die Regressionseinstellung melden wir den Verlust.
Absturz. Die Forscher schlugen eine Reihe von Metriken vor, Collapse-Avg und Collapse-Worst, um das Ausmaß des Zusammenbruchs zu quantifizieren, dem ein modulares System ausgesetzt ist (d. h. das Ausmaß, in dem Module nicht ausreichend genutzt werden). Abbildung 2 unten zeigt ein Beispiel, in dem Sie sehen können, dass Modul 3 nicht verwendet wird.
Professionalisierung. Um die Kollapsmetriken zu ergänzen, schlagen wir auch den folgenden Satz von Metriken vor, nämlich (1) Ausrichtung, (2) Anpassung und (3) inverse gegenseitige Information, die den Grad der durch ein modulares System erreichten Spezialisierung quantifiziert.
Experimente
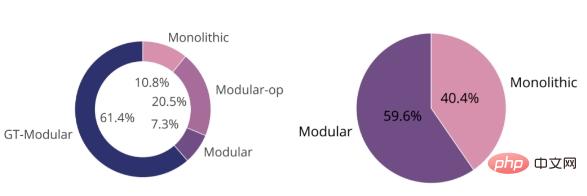
Die Abbildung unten zeigt, dass das GT-Modular-System in den meisten Fällen optimal ist (links), was zeigt, dass eine Spezialisierung von Vorteil ist. Wir sehen auch, dass zwischen dem Standard-End-to-End-Trainingsmodulsystem und dem monolithischen System das erstere das letztere übertrifft, jedoch nicht viel. Zusammengenommen zeigen diese beiden Tortendiagramme, dass aktuelle modulare Systeme für eine ganzheitliche Ausbildung keine gute Spezialisierung erreichen und daher weitgehend suboptimal sind.

Die Studie untersucht dann bestimmte architektonische Entscheidungen und analysiert deren Leistung und Trends anhand einer zunehmenden Anzahl von Regeln.

Abbildung 4 zeigt, dass ein perfekt spezialisiertes System (GT-Modular) zwar Vorteile bringen würde, ein typisches modulares System für End-to-End-Schulungen jedoch suboptimal ist und diese Vorteile nicht erzielen kann, insbesondere bei zunehmender Regelmenge . Darüber hinaus übertreffen solche durchgängigen modularen Systeme zwar häufig monolithische Systeme, der Vorteil ist jedoch meist nur gering.

In Abbildung 7 sehen wir auch die Trainingsmodi verschiedener Modelle. Im Durchschnitt aller anderen Einstellungen umfasst der Durchschnitt sowohl den Klassifizierungsfehler als auch den Regressionsverlust. Wie man sieht, führt eine gute Spezialisierung nicht nur zu einer besseren Leistung, sondern beschleunigt auch das Training.

Die folgende Abbildung zeigt zwei Kollapsmetriken: Collapse-Avg und Collapse-Worst. Darüber hinaus zeigt die folgende Abbildung auch drei Spezialisierungsindikatoren, Ausrichtung, Anpassung und inverse gegenseitige Information für verschiedene Modelle mit unterschiedlicher Anzahl von Regeln: 🎜#
#🎜🎜 # #🎜 🎜 # # 🎜🎜#
# 🎜🎜#
Das obige ist der detaillierte Inhalt vonReichen modulare maschinelle Lernsysteme aus? Bengio-Lehrer und -Schüler sagen Ihnen die Antwort. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr