
Heim >Backend-Entwicklung >Python-Tutorial >Analysieren Sie mit Python 1,4 Milliarden Daten
Analysieren Sie mit Python 1,4 Milliarden Daten

- PHPznach vorne
- 2023-04-12 22:19:251791Durchsuche

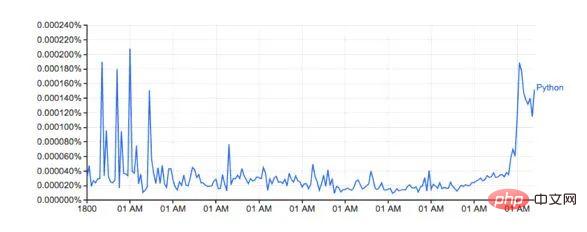
Google Ngram Viewer ist ein unterhaltsames und nützliches Tool, das Googles riesigen Schatz an aus Büchern gescannten Daten nutzt, um Änderungen im Wortgebrauch im Laufe der Zeit darzustellen. Zum Beispiel das Wort Python (Groß-/Kleinschreibung beachten):
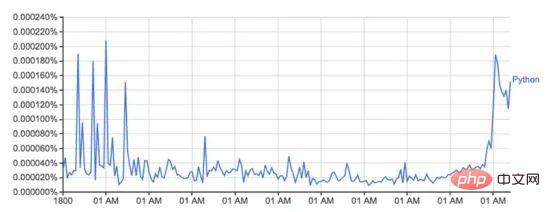
Dieses Bild von: Books.google.com/ngrams… zeigt das Wort „Python-Verwendung vorbei“. Zeit.
Es basiert auf dem N-Gramm-Datensatz von Google, der die Verwendung eines bestimmten Wortes oder einer bestimmten Phrase in Google Books für jedes Jahr aufzeichnet, in dem das Buch gedruckt wurde. Dies ist jedoch nicht vollständig (es umfasst nicht jedes jemals veröffentlichte Buch!), der Datensatz umfasst Millionen von Büchern aus dem Zeitraum vom 16. Jahrhundert bis 2008. Der Datensatz kann hier kostenlos heruntergeladen werden.
Ich habe mich entschieden, Python und meine neue Datenladebibliothek PyTubes zu verwenden, um zu sehen, wie einfach es war, das obige Diagramm neu zu generieren.
Challenge
Ein 1-Gramm-Datensatz kann auf 27 GB Daten auf der Festplatte erweitert werden, was beim Einlesen in Python eine große Datenmenge darstellt. Python kann problemlos Gigabytes an Daten gleichzeitig verarbeiten, aber wenn die Daten beschädigt und verarbeitet werden, werden sie langsamer und weniger speichereffizient.
Insgesamt sind diese 1,4 Milliarden Daten (1.430.727.243) in 38 Quelldateien verstreut, mit insgesamt 24 Millionen (24.359.460) Wörtern (und Wortart-Tags, siehe unten), Berechnet von 1505 bis 2008.
Bei der Verarbeitung von 1 Milliarde Datenzeilen kann es schnell zu Verzögerungen kommen. Und natives Python ist nicht für die Verarbeitung dieses Datenaspekts optimiert. Glücklicherweise ist Numpy wirklich gut im Umgang mit großen Datenmengen. Mit einigen einfachen Tricks können wir diese Analyse mithilfe von Numpy durchführen.
Der Umgang mit Strings in Python/Numpy ist kompliziert. Der Speicheraufwand für Zeichenfolgen in Python ist erheblich, und Numpy kann nur Zeichenfolgen bekannter und fester Länge verarbeiten. Aufgrund dieser Situation sind die meisten Wörter unterschiedlich lang, was nicht ideal ist.
Laden der Daten
Alle folgenden Codes/Beispiele laufen auf einem 2016 MacBook Pro mit 8 GB RAM. Wenn die Hardware oder Cloud-Instanz über eine bessere RAM-Konfiguration verfügt, ist die Leistung besser.
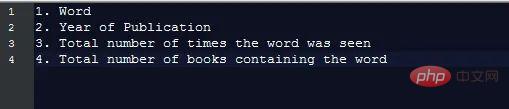
1-Gramm-Daten werden in der Datei in Form einer Tabulatortastentrennung gespeichert, die wie folgt aussieht:

#🎜 🎜#
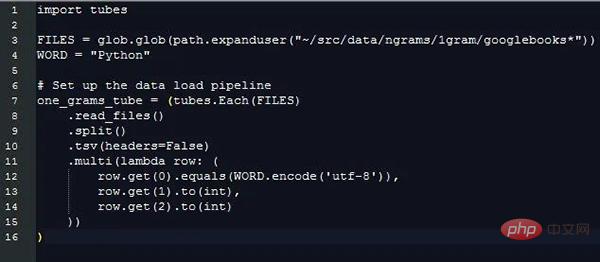
 Durch das Extrahieren dieser Informationen werden die zusätzlichen Kosten für die Verarbeitung von Zeichenfolgendaten unterschiedlicher Länge ignoriert, aber wir müssen die Werte trotzdem vergleichen aus verschiedenen Zeichenfolgen, um zu unterscheiden, welche Datenzeilen es sind. Es gibt Felder, die uns interessieren. Das können Pytubes:
Durch das Extrahieren dieser Informationen werden die zusätzlichen Kosten für die Verarbeitung von Zeichenfolgendaten unterschiedlicher Länge ignoriert, aber wir müssen die Werte trotzdem vergleichen aus verschiedenen Zeichenfolgen, um zu unterscheiden, welche Datenzeilen es sind. Es gibt Felder, die uns interessieren. Das können Pytubes:
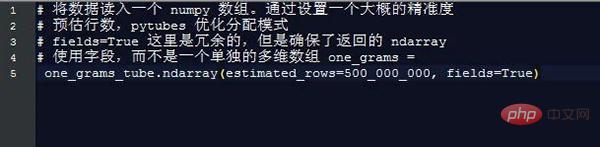 Nach fast 170 Sekunden (3 Minuten) ist one_grams ein Numpy-Array, das fast 1,4 Milliarden Datenzeilen enthält und wie folgt aussieht (zur Veranschaulichung werden Tabellenüberschriften hinzugefügt): ════ ═╪════════╪══════════ 🎜#├───── ────── ┼────────┼─ ────────┤
Nach fast 170 Sekunden (3 Minuten) ist one_grams ein Numpy-Array, das fast 1,4 Milliarden Datenzeilen enthält und wie folgt aussieht (zur Veranschaulichung werden Tabellenüberschriften hinzugefügt): ════ ═╪════════╪══════════ 🎜#├───── ────── ┼────────┼─ ────────┤
│ 0 │ 1804 │ 1 │
├ ──────── ───┼───── ───┼─────────┤
│ 0 │ 1805 │ 1 │
├──── ──────┼─ ───────┼─────────┤
│ 0 │ 1811 │ 1. │
├ ──────── ──┼────────┼─────────┤
│ 0 │ 1820 │ ... │
# 🎜🎜#╘══ ═════════╧════════╧═════ ════╛#🎜 🎜#Von hier aus geht es nur noch darum, Numpy-Methoden zu verwenden, um etwas zu berechnen:
Gesamter Wortgebrauch pro Jahr
Google zeigt jeden Prozentsatz des Vorkommens eines Wortes an (die Häufigkeit, mit der ein Wort in diesem Jahr vorkam / die Gesamtzahl des Vorkommens aller Wörter in diesem Jahr), was nützlicher ist als nur das Zählen der ursprünglichen Wörter. Um diesen Prozentsatz zu berechnen, müssen wir die Gesamtzahl der Wörter kennen.
Glücklicherweise macht Numpy das ganz einfach:
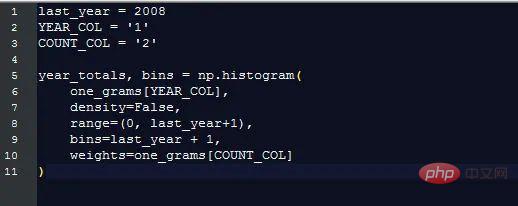
Plotten Sie dieses Diagramm, um zu zeigen, wie viel Google jedes Jahr sammelt. Wie viele Wörter :
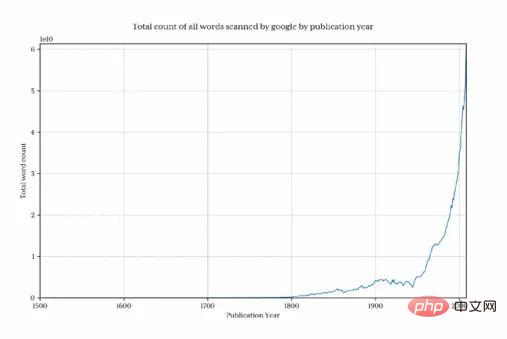
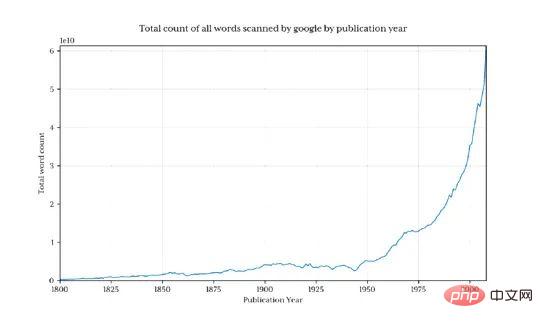
Es ist klar, dass die Gesamtdatenmenge vor 1800 rapide zurückgegangen ist, sodass das Endergebnis diesmal verzerrt und verborgen ist Muster, die uns interessieren . Um dieses Problem zu vermeiden, importieren wir nur Daten nach 1800:
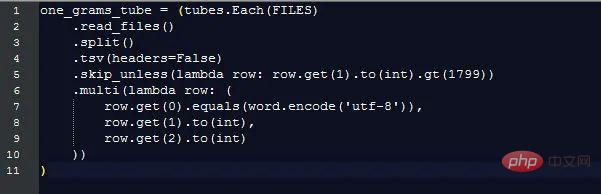
Dies gibt 1,3 Milliarden Datenzeilen zurück (nur 3,7 % der Daten vor 1800).
Pythons Jahresprozentsatz
Pythons Jahresprozentsatz zu erhalten ist jetzt besonders einfach.
Erstellen Sie mit einem einfachen Trick ein Array basierend auf dem Jahr. Die Elementlänge 2008 bedeutet, dass der Index jedes Jahres gleich der Zahl des Jahres ist, sodass beispielsweise 1995 nur die Elemente erhält Problem von 1995.
Es lohnt sich nicht, Numpy für die Operation zu verwenden:

Zeichnen Sie das Ergebnis von word_counts:
#🎜🎜 #
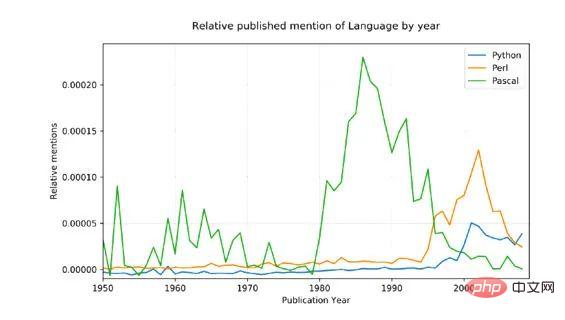
# 🎜🎜#Die Quelldaten sind verrauscht (sie enthalten alle verwendeten englischen Wörter, nicht nur Erwähnungen von Programmiersprachen, und Python hat beispielsweise auch nichttechnische Bedeutungen!), um diesen Aspekt anzupassen, haben wir zwei Dinge getan:
Nur die Namensform mit großgeschriebenem Anfangsbuchstaben kann abgeglichen werden (Python, nicht Python)
Jede Sprache Die Gesamtzahl der Erwähnungen wurde in einen prozentualen Durchschnitt von 1800 umgerechnet bis 1960, was eine vernünftige Grundlage liefern sollte, wenn man bedenkt, dass Pascal erstmals 1970 erwähnt wurde.
Ergebnisse:
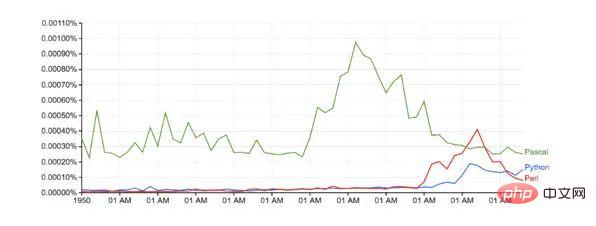
 Im Vergleich zu Google (ohne jegliche Basisanpassung):
Im Vergleich zu Google (ohne jegliche Basisanpassung):
Laufzeit: Etwas mehr als 10 Minuten
Zukünftige PyTubes-Verbesserungen
Zu diesem Zeitpunkt verfügt Pytubes nur über das Konzept einer einzelnen Ganzzahl, also 64 Bit. Dies bedeutet, dass die von pytubes generierten Numpy-Arrays i8-D-Typen für alle Ganzzahlen verwenden. An manchen Stellen (z. B. bei ngrams-Daten) sind 8-Bit-Ganzzahlen etwas übertrieben und verschwenden Speicher (das gesamte ndarray beträgt 38 GB, dtypes kann dies leicht um 60 % reduzieren). Ich habe vor, etwas Ganzzahlunterstützung der Stufen 1, 2 und 4 hinzuzufügen (github.com/stestagg/py…)
Mehr Filterlogik – Tube.skip_unless() ist eine relativ einfache Möglichkeit, Zeilen zu filtern, aber es fehlt die Fähigkeit zum Kombinieren Bedingungen (UND/ODER/NICHT). Dies kann in einigen Anwendungsfällen die Größe der geladenen Daten schneller reduzieren.
Bessere Zeichenfolgenübereinstimmung – einfache Tests wie „startswith“, „endswith“, „contains“ und „is_one_of“ können einfach hinzugefügt werden, um die Effektivität des Ladens von Zeichenfolgendaten erheblich zu verbessern.
Das obige ist der detaillierte Inhalt vonAnalysieren Sie mit Python 1,4 Milliarden Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!