
Heim >Technologie-Peripheriegeräte >KI >Entwurf und Implementierung eines Systems zur Überwachung von Datenbankanomalien basierend auf einem KI-Algorithmus
Entwurf und Implementierung eines Systems zur Überwachung von Datenbankanomalien basierend auf einem KI-Algorithmus

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 18:37:06976Durchsuche
Autor: Cao Zhen Weiyuan
Das Forschungs- und Entwicklungsteam der Meituan-Datenbankplattform steht vor der immer dringenderen Notwendigkeit, Datenbankanomalien schneller und intelligenter zu erkennen, zu lokalisieren und zu stoppen. Wir haben einen auf KI basierenden Dienst zur Erkennung von Datenbankanomalien entwickelt Algorithmen.
1. Hintergrund
Datenbanken werden in den Kerngeschäftsszenarien von Meituan häufig verwendet, mit hohen Stabilitätsanforderungen und einer sehr geringen Toleranz für Ausnahmen. Daher werden die schnelle Erkennung, Lokalisierung und Stop-Loss von Datenbankanomalien immer wichtiger. Als Reaktion auf das Problem der abnormalen Überwachung erfordert die herkömmliche Alarmmethode mit festem Schwellenwert Expertenerfahrung zum Konfigurieren von Regeln und kann den Schwellenwert nicht flexibel und dynamisch an unterschiedliche Geschäftsszenarien anpassen, wodurch kleine Probleme leicht zu großen Fehlern werden können.
Die KI-basierte Funktion zur Erkennung von Datenbankanomalien kann 7*24-Stunden-Inspektionen von Schlüsselindikatoren basierend auf der historischen Leistung der Datenbank durchführen. Sie kann Risiken im Keim von Anomalien erkennen, Anomalien früher aufdecken und das Forschungs- und Entwicklungspersonal unterstützen . Lokalisieren und stoppen Sie Verluste, bevor sich die Probleme verschlimmern. Basierend auf den Überlegungen der oben genannten Faktoren beschloss das Forschungs- und Entwicklungsteam der Meituan-Datenbankplattform, ein Servicesystem zur Erkennung von Datenbankanomalien zu entwickeln. Als Nächstes werden in diesem Artikel einige unserer Gedanken und Praktiken aus verschiedenen Dimensionen wie Merkmalsanalyse, Algorithmusauswahl, Modelltraining und Echtzeiterkennung näher erläutert. 2. Merkmalsanalyse Somit kann ein geeigneter Algorithmus basierend auf den Merkmalen der Datenverteilung ausgewählt werden. Im Folgenden sind einige repräsentative Indikatorverteilungsdiagramme aufgeführt, die wir aus historischen Daten ausgewählt haben:
Abbildung 1 Datenbank-Indikatorformular
Aus der obigen Abbildung können wir erkennen, dass die Datenmuster hauptsächlich drei Zustände darstellen: Periode, Drift und Plateau  [1]
[1]
2.1.1 Zyklische Änderungen
In vielen Geschäftsszenarien schwanken die Indikatoren aufgrund morgendlicher und abendlicher Spitzen oder einiger geplanter Aufgaben regelmäßig. Wir glauben, dass es sich hierbei um eine inhärente regelmäßige Fluktuation der Daten handelt und das Modell in der Lage sein sollte, periodische Komponenten zu identifizieren und kontextbezogene Anomalien zu erkennen. Für Zeitreihenindikatoren, die keine langfristige Trendkomponente haben, wenn der Indikator eine zyklische Komponente hat, , wobei T die Periodenspanne der Zeitreihe darstellt. Das Autokorrelationsdiagramm kann berechnet werden, d. h. der Wert von
, wenn t unterschiedliche Werte annimmt, und dann kann die Periodizität durch Analyse der Intervalle der Autokorrelationsspitzen bestimmt werden. Der Hauptprozess umfasst die folgenden Schritte: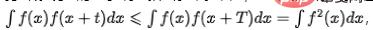 Extrahieren Sie die Trendkomponenten, um die Restsequenz zu isolieren. Verwenden Sie die Methode des gleitenden Durchschnitts, um den langfristigen Trendterm zu extrahieren, und machen Sie die Differenz zur ursprünglichen Sequenz, um die Restsequenz zu erhalten (
Extrahieren Sie die Trendkomponenten, um die Restsequenz zu isolieren. Verwenden Sie die Methode des gleitenden Durchschnitts, um den langfristigen Trendterm zu extrahieren, und machen Sie die Differenz zur ursprünglichen Sequenz, um die Restsequenz zu erhalten (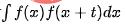 Hier hat die periodische Analyse nichts mit dem Trend zu tun. Wenn die Trendkomponente nicht getrennt ist , wird die Autokorrelation erheblich beeinträchtigt, was es schwierig macht, den Zeitraum zu identifizieren
Hier hat die periodische Analyse nichts mit dem Trend zu tun. Wenn die Trendkomponente nicht getrennt ist , wird die Autokorrelation erheblich beeinträchtigt, was es schwierig macht, den Zeitraum zu identifizieren
- ).
- Berechnen Sie die rollierende Autokorrelationssequenz (Rollierende Korrelation ) der Residuen. Die Autokorrelationssequenz wird berechnet, indem eine Vektorpunktmultiplikationsoperation mit der Restsequenz durchgeführt wird, nachdem die Restsequenz zyklisch verschoben wurde (
- zyklische Autokorrelation kann einen verzögerten Zerfall vermeiden). Die Periode T wird basierend auf der Peakkoordinate der Autokorrelationssequenz bestimmt. Extrahieren Sie eine Reihe lokal höchster Spitzen der Autokorrelationssequenz und nehmen Sie das Intervall der Abszisse als Periode (Wenn der dem periodischen Punkt entsprechende Autokorrelationswert unter dem angegebenen Schwellenwert liegt, wird davon ausgegangen, dass er keine signifikante Periodizität aufweist) .
- Der spezifische Prozess ist wie folgt:

Abbildung 2 Schema des Zyklusextraktionsprozesses
2.1.2 Driftänderungen
Für die zu modellierende Sequenz ist es in der Regel erforderlich, dass sie keinen offensichtlichen langfristigen Trend oder eine globale Drift aufweist Phänomen, da sich die generierten Modelle sonst oft nicht gut an aktuelle Indikatorentrends anpassen [2]. Wir beziehen uns auf Situationen, in denen sich der Mittelwert einer Zeitreihe im Laufe der Zeit erheblich ändert oder es einen globalen Mutationspunkt gibt, was zusammenfassend als Driftszenario bezeichnet wird. Um den neuesten Trend der Zeitreihe genau zu erfassen, müssen wir in der frühen Phase der Modellierung feststellen, ob eine Abweichung in den historischen Daten vorliegt. Globale Drift und periodische Reihen bedeuten Drift, wie im folgenden Beispiel gezeigt:

Abbildung 3 Datendrift
Datenbankindikatoren werden von komplexen Faktoren wie Geschäftsaktivitäten beeinflusst, und viele Daten sind nicht periodisch Und die Modellierung muss diese Veränderungen tolerieren. Daher müssen wir im Gegensatz zum klassischen Problem der Änderungspunkterkennung im Anomalieerkennungsszenario nur die Situation erkennen, in der die Daten im Verlauf stabil sind und dann driften. Basierend auf der Leistung des Algorithmus und der tatsächlichen Leistung haben wir die auf Medianfilterung basierende Drifterkennungsmethode verwendet:
1. Entsprechend der angegebenen Größe des Fensters und der Median innerhalb des Fensters wird extrahiert, um die Trendkomponente der Zeitreihe zu erhalten.
b. Das Fenster muss groß genug sein, um den Einfluss periodischer Faktoren zu vermeiden und eine Filterverzögerungskorrektur durchzuführen.
c. Der Grund für die Verwendung der Median- statt der Mittelwertglättung besteht darin, den Einfluss abnormaler Stichproben zu vermeiden.
2. Bestimmen Sie, ob die geglättete Folge zunimmt oder abnimmt
a: Wenn jeder Punkt größer (kleiner als) der vorherige Punkt ist steigende (Abnehmende
) Reihenfolge.b. Wenn die Sequenz streng steigend oder streng fallend ist, weist der Indikator offensichtlich einen langfristigen Trend auf und kann vorzeitig beendet werden.
3. Durchlaufen Sie die glatte Sequenz und verwenden Sie die folgenden zwei Regeln, um festzustellen, ob eine Drift vorliegt.
a Wenn der Maximalwert der Sequenz links vom aktuellen Abtastpunkt liegt Wenn der Mindestwert der Sequenz rechts vom aktuellen Abtastpunkt liegt, kommt es zu einer plötzlichen Drift (Aufwärtstrend).
b. Wenn der Minimalwert der Sequenz links vom aktuellen Abtastpunkt größer ist als der Maximalwert der Sequenz rechts vom aktuellen Abtastpunkt, liegt eine plötzliche Abfalldrift vor (Abwärtstrend). ).
2.1.3 Stationäre ÄnderungenWenn sich bei einem Zeitreihenindikator seine Eigenschaften zu keinem Zeitpunkt mit der Änderung der Beobachtungszeit ändern, gehen wir davon aus, dass diese Zeitreihe stationär ist. Daher sind Zeitreihen mit langfristigen Trendkomponenten oder zyklischen Komponenten alle instationär. Das spezifische Beispiel ist in der folgenden Abbildung dargestellt:
Abbildung 4 Datenstationaritätsanzeige
In diesem Fall können wir anhand des Einheitswurzeltests (
Erweiterter Dickey-Fuller-Test) urteilen[3]
Ob eine bestimmte Zeitreihe stationär ist. Insbesondere für einen Teil der historischen Daten eines bestimmten Zeitbereichsindikators glauben wir, dass die Zeitreihe stabil ist, wenn die folgenden Bedingungen gleichzeitig erfüllt sind:- Der durch den Adfuller-Test ermittelte p-Wert für die Zeitreihendaten des letzten Tages beträgt weniger als 0,05.
- Der durch den Adfuller-Test ermittelte p-Wert für die Zeitreihendaten der letzten 7 Tage beträgt weniger als 0,05. 3. Algorithmusauswahl 3.1 Verteilungsgesetz und Algorithmenauswahl Linienanalyse Basierend auf der Stichprobenanalyse tatsächlicher Indikatoren entsprechen ihre Wahrscheinlichkeitsdichtefunktionen der folgenden Verteilung:
Mit dem Ziel der obigen Verteilung haben wir einige gängige Algorithmen untersucht und Box ermittelt Als endgültiger Anomalieerkennungsalgorithmus werden Diagramm, absolute Mediandifferenz und Extremwerttheorie verwendet. Das Folgende ist eine Vergleichstabelle von Algorithmen für die Erkennung gängiger Zeitreihendaten:

Der Hauptgrund, warum wir uns nicht für 3Sigma entschieden haben, ist, dass es eine geringere Toleranz für Anomalien aufweist, während die absolute Mediandifferenz theoretisch bessere Anomalien aufweist Toleranz. Wenn die Daten also eine hochsymmetrische Verteilung aufweisen, wird zur Erkennung die absolute Mediandifferenz (
MAD) anstelle von 3Sigma verwendet. Wir verwenden unterschiedliche Erkennungsalgorithmen für die Verteilung verschiedener Daten (Informationen zu den Prinzipien verschiedener Algorithmen finden Sie im Anhang am Ende des Artikels, ich werde hier nicht zu sehr darauf eingehen
):
Geringe Schiefe und hohe Symmetrieverteilung: Absolute Mediandifferenz (MAD)
- Mäßig schiefe Verteilung : Boxplot (Boxplot)
- Hochschiefe Verteilung : Extremwerttheorie (EVT)
- Mit der obigen Analyse können wir den spezifischen Prozess der Modellausgabe anhand der Stichprobe ermitteln:
Der Gesamtmodellierungsprozess des Algorithmus ist in dargestellt Die obige Abbildung deckt hauptsächlich die folgenden Zweige ab: Timing-Drift-Erkennung, Timing-Stabilitätsanalyse, Timing-Periodizitätsanalyse und Schiefeberechnung. Folgendes wird separat vorgestellt:

- Timing-Drift-Erkennung. Wenn die Szene erkannt wird, in der eine Drift vorliegt, muss die Eingabezeitreihe entsprechend dem durch die Erkennung erhaltenen Driftpunkt t geschnitten werden, und die Zeitreihenabtastwerte nach dem Driftpunkt werden als Eingabe für den nachfolgenden Modellierungsprozess verwendet und als aufgezeichnet S={Si}, wobei i>t.
- Zeitreihen-Stationaritätsanalyse. Wenn die Eingabezeitreihe S den Stationaritätstest erfüllt, erfolgt sie direkt durch den Boxplot (Standard ) oder den absoluten Median Differenzmethode zum Modellieren.
- Periodische Zeitreihenanalyse. Im Fall der Periodizität wird die Periodenspanne als T aufgezeichnet, die Eingabezeitreihe S entsprechend der Spanne T geschnitten und der Modellierungsprozess für den Datenbereich durchgeführt, der aus jedem Zeitindex j∈{0,1, ⋯,T−1} . Liegt keine Periodizität vor, wird der Modellierungsprozess für alle Eingabezeitreihen S als Datenbuckets durchgeführt.
Fall : Gegeben eine Zeitreihe ts={t0,t # 🎜🎜#1,⋯,tn}, unter der Annahme, dass es Periodizität gibt und die Periodenspanne T ist, für den Zeitindex j, wobei j∈{0,1, ⋯ ,T−1}, die zur Modellierung erforderlichen Abtastpunkte bestehen aus dem Intervall [tj−kT−m, tj−kT+m] , Dabei ist m ein Parameter, der die Fenstergröße darstellt, k ist eine ganze Zahl, die j−kT−m≥0 und j−kT+m≤n erfüllt. Angenommen, die gegebene Zeitreihe beginnt vom 01.03.2022 um 00:00:00 Uhr bis zum 08.03.2022 um 00:00:00 Uhr, die gegebene Fenstergröße beträgt 5 und die Zeitspanne beträgt einen Tag, dann für der Zeitindex 30. Mit anderen Worten, die zur Modellierung erforderlichen Stichprobenpunkte stammen aus dem folgenden Zeitraum: [01.03. 00:25:00, 01.03. 00:35:00][02.03 00:25:00 , 02.03. 00:35:00]
...
[07.03. 00:25:00, 07.03. 00:35:00]
# 🎜🎜##🎜 🎜#- Schiefeberechnung
- . Die Zeitreihenindikatoren werden in Wahrscheinlichkeitsverteilungsdiagramme umgewandelt und die Schiefe der Verteilung berechnet. Wenn der Absolutwert der Schiefe den Schwellenwert überschreitet, wird die Extremwerttheorie zur Modellierung des Ausgabeschwellenwerts verwendet. Wenn der absolute Wert der Schiefe kleiner als der Schwellenwert ist, wird der Schwellenwert modelliert und per Boxplot oder absoluter Mediandifferenz ausgegeben. 3.2 Fallbeispielmodellierung
Hier wird ein Fall ausgewählt, um den Datenanalyse- und Modellierungsprozess klarer darzustellen Verstehen Sie den obigen Prozess. Abbildung (a) ist die ursprüngliche Sequenz, Abbildung (b) ist die entsprechend der Tagesspanne gefaltete Sequenz, Abbildung (c) ist die verstärkte Trendleistung der Stichproben in einem bestimmten Zeitindexintervall in Abbildung (b), Abbildung ( d) ) ist der untere Schwellenwert, der dem Zeitindex in Abbildung (c) entspricht. Das Folgende ist ein Fall der Modellierung historischer Stichproben einer bestimmten Zeitreihe:
 Abbildung 7 Modellierungsfall#🎜🎜 #
Abbildung 7 Modellierungsfall#🎜🎜 #Das Probenverteilungshistogramm und der Schwellenwert im Bereich (c) der obigen Abbildung (hat einige abnormale Proben eliminiert
), das können Sie sehen In diesem Szenario mit stark verzerrter Verteilung ist der vom EVT-Algorithmus berechnete Schwellenwert sinnvoller.Abbildung 8 Vergleich der schiefen Verteilungsschwellenwerte

4. Modelltraining und Echtzeiterkennung4.1 Datenflussprozess
Um umfangreiche Daten der zweiten Ebene in Echtzeit zu erkennen, haben wir mit Echtzeit begonnen Stream-Verarbeitung basierend auf Flink und entworfen. Die folgenden technischen Lösungen wurden vorgeschlagen:- Echtzeiterkennungsteil: Basierend auf der Flink-Echtzeit-Stream-Verarbeitung werden Mafka-Nachrichten (Nachrichtenwarteschlangenkomponente in Meituan) zur Online-Erkennung verwendet und die Ergebnisse werden in Elasticsearch gespeichert (im Folgenden als ES bezeichnet) ) und einen Ausnahmedatensatz generieren.
- Offline-Trainingsteil: Verwenden Sie Squirrel (Meituans interne KV-Datenbank) als Aufgabenwarteschlange, lesen Sie Trainingsdaten aus MOD (Meituans internes Betriebs- und Wartungsdatenlager) und lesen Sie Parameter aus der Konfigurationstabelle. Das Trainingsmodell wird in ES gespeichert, unterstützt die automatische und manuelle Auslösung des Trainings und lädt und aktualisiert das Modell durch regelmäßiges Lesen der Modellbibliothek.
Das Folgende ist das spezifische Design der Offline-Schulung und der Online-Erkennungstechnologie:

Abbildung 9 Design der Offline-Schulung und Online-Erkennungstechnologie
4.2 Anomalieerkennungsprozess
Der allgemeine Anomalieerkennungsalgorithmus wird übernommen Teile und herrsche Die Idee besteht darin, dass in der Modelltrainingsphase Merkmale basierend auf der Identifizierung historischer Daten extrahiert und ein geeigneter Erkennungsalgorithmus ausgewählt wird. Dies ist in zwei Teile unterteilt: Offline-Training und Online-Erkennung. Offline führt hauptsächlich Datenvorverarbeitung, Zeitreihenklassifizierung und Zeitreihenmodellierung basierend auf historischen Bedingungen durch. Online lädt und verwendet hauptsächlich offline trainierte Modelle für die Online-Echtzeit-Anomalieerkennung. Das spezifische Design ist in der folgenden Abbildung dargestellt:

Abbildung 10 Anomalieerkennungsprozess
5. Produktbetrieb
Um die Effizienz des iterativen Optimierungsalgorithmus zu verbessern und den Betrieb weiter zu verbessern Präzision und Rückruf: Mit Hilfe der Fallüberprüfungsfunktionen von Horae (Meituans internes skalierbares System zur Erkennung von Zeitreihendatenanomalien) wird ein geschlossener Kreislauf aus Online-Erkennung, Fallspeicherung, Analyseoptimierung, Ergebnisauswertung und Freigabe realisiert. Abbildung 11: Betriebsprozess Wählen Sie einen Teil der Fälle aus, in denen Anomalien vorliegen erkannt, und überprüfen Sie sie manuell. Es ist tatsächlich ein abnormaler Anteil, 81 %.
Rückrufrate

: Überprüfen Sie anhand von Fehlern, Alarmen und anderen Quellen die abnormalen Bedingungen jedes Indikators der entsprechenden Instanz und berechnen Sie die Rückrufrate basierend auf den Überwachungsergebnissen, die 82 % beträgt.
F1-Score: Das harmonische Mittel aus Präzision und Erinnerung, das 81 % beträgt.
- 6. ZukunftsaussichtenZurzeit ist die Funktion zur Überwachung von Datenbankanomalien im Wesentlichen abgeschlossen
- Hat die Fähigkeit, Ausnahmetypen zu identifizieren . Es kann abnormale Typen wie mittlere Änderungen, Schwankungsänderungen, Spitzen usw. erkennen, unterstützt die Alarmabonnementierung entsprechend abnormaler Typen und gibt sie als Merkmale in das nachfolgende Diagnosesystem ein. Perfekte Datenbankautonomie-Ökologie [4].
- Aufbau einer Human-in-Loop-Umgebung . Unterstützen Sie automatisches Lernen basierend auf Feedback-Anmerkungen, , um eine kontinuierliche Optimierung des Modells [5] sicherzustellen.
- Unterstützung für mehrere Datenbankszenarien. Die Anomalieerkennungsfunktion ist plattformbasiert, um mehr Datenbankszenarien zu unterstützen, wie z. B. DB-End-to-End-Fehlerberichte, Knotennetzwerküberwachung usw.
7. Anhang
7.1 Absolute Mediandifferenz
Die absolute Mediandifferenz ist Median Absolut Abweichung (MAD) ist eine robuste Messung der Stichprobenabweichung univariater numerischer Daten [6], normalerweise berechnet durch die folgende Formel: Get: #🎜 🎜#
Wenn der Prior eine Normalverteilung ist, wählt C im Allgemeinen 1,4826 und k wählt 3. MAD geht davon aus, dass der 50 %-Bereich in der Mitte der Probe eine normale Probe ist, während die abnormalen Proben auf beiden Seiten in den 50 %-Bereich fallen. Wenn die Stichprobe der Normalverteilung folgt, kann sich der MAD-Indikator besser an Ausreißer im Datensatz anpassen als die Standardabweichung. Für die Standardabweichung wird das Quadrat des Abstands zwischen den Daten und dem Mittelwert verwendet. Je größer die Abweichung, desto größer das Gewicht. Bei MAD kann eine kleine Anzahl von Ausreißern nicht ignoriert werden Einfluss auf die Ergebnisse des Experiments. Der MAD-Algorithmus hat keinen Einfluss auf die Daten. Es gelten höhere Anforderungen an die Normalität.
7.2 BoxplotDer Boxplot beschreibt hauptsächlich die Streuung und Symmetrie der Stichprobenverteilung durch mehrere Statistiken, darunter:
- Q0: Minimum (Minimum) #Q1: Unteres Quartil (Unteres Quartil) #🎜🎜 #
- Q2: Median (Median#🎜🎜 #)
- Q3: Oberes Quartil (#🎜 🎜#Oberes Quartil) # 🎜🎜#Q4: Maximum ( Maximum
- ) #🎜🎜 #
- Abbildung 12 Boxplot
Kombinieren Q
1
mit Q Der Abstand zwischen 3
wird als IQR bezeichnet Wenn der Wert im oberen Quartil um das 1,5-fache des IQR (oder vom unteren Quartil um das 1,5-fache des IQR abweicht), gilt die Stichprobe als Ausreißer. Im Gegensatz zu drei Standardabweichungen, die auf der Normalitätsannahme basieren, treffen Boxplots im Allgemeinen keine Annahmen über die zugrunde liegende Datenverteilung der Stichprobe, können die diskrete Situation der Stichprobe beschreiben und weisen ein höheres Vertrauen in die in der Stichprobe enthaltenen potenziell abnormalen Stichproben auf . Toleranz. Bei verzerrten Daten ist die kalibrierte Modellierung von Boxplot konsistenter mit der Datenverteilung [7]. 7.3 ExtremwerttheorieDaten aus der realen Welt lassen sich nur schwer mit einer bekannten Verteilung verallgemeinern, beispielsweise für einige Extremereignisse (#🎜 🎜#Anomalie), probabilistische Modelle (wie die Gaußsche Verteilung) neigen dazu, ihre Wahrscheinlichkeit mit 0 anzugeben. Die Extremwerttheorie[8] besteht darin, die Verteilung extremer Ereignisse abzuleiten, die wir ohne Verteilungsannahmen auf der Grundlage der Originaldaten beobachten können. Dies ist die Extremwertverteilung (
EVD #🎜 🎜#). Sein mathematischer Ausdruck lautet wie folgt (Komplementäre kumulative Verteilungsfunktionsformel
):wobei t den empirischen Schwellenwert der Stichprobe darstellt. Für verschiedene Szenarien können verschiedene Werte festgelegt werden. Dies sind die Formparameter und Skalenparameter in der verallgemeinerten Pareto-Verteilung. Wenn eine bestimmte Stichprobe den künstlich festgelegten empirischen Schwellenwert t überschreitet Die Zufallsvariable X-t folgt der verallgemeinerten Pareto-Verteilung. Mithilfe der Maximum-Likelihood-Schätzmethode können wir die Parameterschätzungen und berechnen und den Modellschwellenwert mithilfe der folgenden Formel ermitteln:
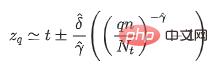
In der obigen Formel stellt q den Risikoparameter dar, n ist die Anzahl aller Stichproben und Nt ist die Anzahl der Stichproben für x-t>0. Da für die Schätzung des empirischen Schwellenwerts t in der Regel keine A-priori-Informationen vorliegen, kann anstelle des Zahlenwerts t das empirische Stichprobenquantil verwendet werden. Der Wert des empirischen Quantils kann hierbei entsprechend der tatsächlichen Situation ausgewählt werden.
8. Referenzen
[1] Ren, H., Xu, B., Wang, Y., Yi, C., Huang, C., Kou, X., ... & Zhang, Q . (2019, Juli). In Proceedings der 25. ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (S. 3009-3017). , A., Dong, F., Gu, F., Gama, J. & Zhang, G. (2018) Lernen unter Konzeptdrift: Eine Überprüfung von IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346 -2363.
[3] Mushtaq, R. (2011). Augmented Dickey Fuller Test.
[4] Ma, M., Yin, Z., Zhang, S., Wang, S., Zheng, C., Jiang, X., ... & Pei, D. (2020). 5] Holzinger, A. (2016). Interaktives maschinelles Lernen für die Gesundheitsinformatik: Wann brauchen wir die Human-in-the-Loop?, 3(2), 119-131.
[6] Leys , C., Ley, C., Klein, O., Bernard, P., & Licata, L. (2013) Ausreißer erkennen: Verwenden Sie keine Standardabweichung um den Mittelwert, sondern eine absolute Abweichung um den Median Sozialpsychologie, 49(4), 764-766.
[7] Hubert, M., & Vandervieren, E. (2008) Ein angepasster Boxplot für schiefe Verteilungen, 52(12). 5186-5201.
[8] Siffer, A., Fouque, P. A., Termier, A. & Largouet, C. (2017, August). Internationale SIGKDD-Konferenz zu Knowledge Discovery und Data Mining (S. 1067-1075).
Das obige ist der detaillierte Inhalt vonEntwurf und Implementierung eines Systems zur Überwachung von Datenbankanomalien basierend auf einem KI-Algorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr