
Heim >Technologie-Peripheriegeräte >KI >Spracherkennung mit dem Whisper-Modell von OpenAI
Spracherkennung mit dem Whisper-Modell von OpenAI

- 王林nach vorne
- 2023-04-12 17:28:032043Durchsuche
Spracherkennung ist ein Bereich der künstlichen Intelligenz, der es Computern ermöglicht, menschliche Sprache zu verstehen und in Text umzuwandeln. Die Technologie wird in Geräten wie Alexa und verschiedenen Chatbot-Anwendungen eingesetzt. Am häufigsten führen wir Sprachtranskriptionen durch, die in Transkripte oder Untertitel umgewandelt werden können.

Die jüngsten Entwicklungen bei hochmodernen Modellen wie wav2vec2, Conformer und Hubert haben den Bereich der Spracherkennung erheblich vorangebracht. Diese Modelle verwenden Techniken, die aus Rohaudio lernen, ohne dass von Menschen beschriftete Daten erforderlich sind, sodass sie große Datensätze unbeschrifteter Sprache effizient nutzen können. Sie wurden außerdem auf die Verwendung von bis zu 1.000.000 Stunden Trainingsdaten erweitert, was weit über die traditionellen 1.000 Stunden hinausgeht, die in akademisch überwachten Datensätzen verwendet werden. Es wurde jedoch festgestellt, dass Modelle, die auf überwachte Weise über mehrere Datensätze und Domänen vorab trainiert wurden, eine bessere Robustheit und Generalisierung aufweisen Datensätze, daher erfordert die Ausführung von Aufgaben wie der Spracherkennung noch eine Feinabstimmung, was ihr volles Potenzial einschränkt. Um dieses Problem zu lösen, hat OpenAI Whisper entwickelt, ein Modell, das schwache Überwachungsmethoden nutzt.
In diesem Artikel werden die für das Training verwendeten Datensatztypen und die Trainingsmethoden des Modells sowie die Verwendung von Whisper erläutert.
Whisper-Modelleinführung
Verwendung des Datensatzes:
Das Whisper-Modell basiert auf einem Datensatz von 680.000 Stunden beschriftetes Audiodatentraining, darunter 117.000 Stunden Sprachunterricht in 96 verschiedenen Sprachen und 125.000 Stunden Übersetzungsdaten von „jeder Sprache“ ins Englische. Das Modell nutzt im Internet generierten Text, der von anderen automatischen Spracherkennungssystemen (ASR) generiert und nicht von Menschen erstellt wurde. Der Datensatz enthält außerdem einen auf VoxLingua107 trainierten Sprachdetektor, eine Sammlung kurzer Sprachclips, die aus YouTube-Videos extrahiert und basierend auf der Sprache des Videotitels und der Beschreibung getaggt wurden, mit zusätzlichen Schritten zum Entfernen von Fehlalarmen.
Modell:
Die Hauptstruktur ist die Encoder-Decoder-Struktur.
Resampling: 16000 Hz
Funktionsextraktionsmethode: Berechnen Sie die 80-Kanal-Log-Mel-Spektrogrammdarstellung mit einem 25-ms-Fenster und einem 10-ms-Schritt.
Funktionsnormalisierung: Die Eingabe wird global auf einen Wert zwischen -1 und 1 skaliert und weist im vorab trainierten Datensatz einen Mittelwert von ungefähr Null auf.
Encoder/Decoder: Der Encoder und Decoder dieses Modells verwenden Transformer.
Encoder-Prozess:
Der Encoder verarbeitet zunächst die Eingabedarstellung mithilfe eines Stamms, der zwei Faltungsschichten (Filterbreite 3) enthält, und verwendet dabei die GELU-Aktivierungsfunktion.
Der Schritt der zweiten Faltungsschicht beträgt 2.
Fügen Sie dann die sinusförmige Positionseinbettung zum Ausgang des Schafts hinzu und wenden Sie dann den Encoder-Transformer-Block an.
Transformer verwenden voraktivierte Restblöcke und die Ausgabe des Encoders wird mithilfe einer Normalisierungsschicht normalisiert.
Modellblockdiagramm:

Dekodierungsprozess:
Im Decoder werden die Einbettung von Lernpositionen sowie die Darstellung von Bindungs- und Ausgabemarkierungen verwendet.
Encoder und Decoder haben die gleiche Breite und Anzahl an Transformer-Blöcken.
Training
Um die Skalierungseigenschaften des Modells zu verbessern, wird es auf verschiedene Eingabegrößen trainiert.
Trainieren Sie das Modell mit FP16, dynamischer Verlustskalierung und Datenparallelität.
Mit AdamW und Gradientennorm-Clipping sinkt die lineare Lernrate nach dem Aufwärmen der ersten 2048-Updates auf Null.
Verwenden Sie eine Stapelgröße von 256 und trainieren Sie das Modell für 220 Aktualisierungen, was zwei bis drei Vorwärtsdurchläufen des Datensatzes entspricht.
Da das Modell nur für wenige Epochen trainiert wurde, stellte die Überanpassung kein wesentliches Problem dar und es wurden keine Datenerweiterungs- oder Regularisierungstechniken verwendet. Dies beruht stattdessen auf der Vielfalt innerhalb großer Datensätze, um Verallgemeinerung und Robustheit zu fördern.
Whisper hat bei zuvor verwendeten Datensätzen eine gute Genauigkeit gezeigt und wurde im Vergleich zu anderen hochmodernen Modellen getestet.
Vorteile:
- Whisper wurde anhand realer Daten sowie Daten anderer Modelle und unter schwacher Aufsicht trainiert.
- Die Genauigkeit des Modells wird mit menschlichen Zuhörern getestet und seine Leistung bewertet.
- Es erkennt stimmlose Bereiche und wendet NLP-Technologie an, um Satzzeichen in Transkripten korrekt einzugeben.
- Das Modell ist skalierbar und ermöglicht das Extrahieren von Transkripten aus Audiosignalen, ohne das Video in Blöcke oder Stapel aufzuteilen, wodurch das Risiko fehlender Töne verringert wird.
- Das Modell erreicht bei verschiedenen Datensätzen eine höhere Genauigkeit.
Vergleichsergebnisse von Whisper bei verschiedenen Datensätzen: Im Vergleich zu wav2vec wurde bisher die niedrigste Wortfehlerrate erreicht

Das Modell wurde nicht am Timit-Datensatz getestet. Um seine Wortfehlerrate zu überprüfen, zeigen wir hier, wie wir Whisper zur Selbstvalidierung des Timit-Datensatzes verwenden, d. h. wie wir Whisper verwenden, um unsere eigene Sprache zu erstellen Anerkennungsantrag.
Verwendung des Whisper-Modells zur Spracherkennung
TIMIT Der Reading Speech Corpus ist eine Sammlung von Sprachdaten, die speziell für die akustische Sprachforschung und die Entwicklung und Bewertung automatischer Spracherkennungssysteme verwendet werden . Es enthält Aufnahmen von 630 Sprechern aus den acht wichtigsten Dialekten des amerikanischen Englisch, die jeweils zehn phonetisch reichhaltige Sätze vorlesen. Das Korpus umfasst zeitlich ausgerichtete orthografische, phonetische und Worttranskriptionen sowie 16-Bit- und 16-kHz-Sprachwellenformdateien für jede Stimme. Das Korpus wurde vom Massachusetts Institute of Technology (MIT), SRI International (SRI) und Texas Instruments (TI) entwickelt. Die Transkriptionen des TIMIT-Korpus wurden manuell verifiziert, wobei Test- und Trainingsteilmengen spezifiziert wurden, um die phonetische und dialektische Abdeckung auszugleichen.
Installation:
!pip install git+https://github.com/openai/whisper.git !pip install jiwer !pip install datasets==1.18.3
Der erste Befehl installiert alle für das Whisper-Modell erforderlichen Abhängigkeiten. jiwer wird zum Herunterladen des Textfehlerratenpakets verwendet. Die Datensätze werden von Hugface bereitgestellt. Sie können den Timit-Datensatz herunterladen.
Bibliothek importieren
import whisper from pytube import YouTube from glob import glob import os import pandas as pd from tqdm.notebook import tqdm
Timit-Datensatz laden
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")Berechnen Sie die Word-Fehlerrate unter verschiedenen Modellgrößen
Berücksichtigen Um der Notwendigkeit gerecht zu werden, englische und nicht-englische Daten zu filtern, entscheiden wir uns hier für die Verwendung eines mehrsprachigen Modells anstelle eines speziell für Englisch entwickelten Modells.
Aber der TIMIT-Datensatz ist ausschließlich auf Englisch, daher müssen wir denselben Spracherkennungs- und Erkennungsprozess anwenden. Darüber hinaus wurde der TIMIT-Datensatz in Trainings- und Verifizierungssätze unterteilt, sodass wir ihn direkt verwenden können.
Um Whisper nutzen zu können, müssen wir zunächst die Parameter, Größe und Geschwindigkeit verschiedener Modelle verstehen.

Modell laden
model = whisper.load_model('tiny')tiny kann durch den oben genannten Modellnamen ersetzt werden.
Funktion zum Definieren des Sprachdetektors
def lan_detector(audio_file):
print('reading the audio file')
audio = whisper.load_audio(audio_file)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
if max(probs, key=probs.get) == 'en':
return True
return FalseFunktion zum Konvertieren von Sprache in Text
def speech2text(audio_file): text = model.transcribe(audio_file) return text["text"]
Führen Sie die obige Funktion unter verschiedenen Modellgrößen aus, limitieren Sie das Training und die Die durch den Test ermittelte Wortfehlerrate ist wie folgt:
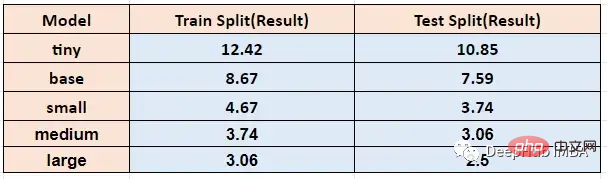
Transkribierte Sprache von u2b
Verglichen mit anderen Spracherkennungsmodellen, Whisper kann nicht nur Sprache erkennen, sondern auch die Zeichensetzung und Intonation in der Stimme einer Person interpretieren und entsprechende Satzzeichen einfügen. Zum Testen verwenden wir unten das Video von u2b.
Hier benötigen wir ein Paket pytube, das uns leicht dabei helfen kann, Audio herunterzuladen und zu extrahieren.
def youtube_audio(link):
youtube_1 = YouTube(link)
videos = youtube_1.streams.filter(only_audio=True)
name = str(link.split('=')[-1])
out_file = videos[0].download(name)
link = name.split('=')[-1]
new_filename = link+".wav"
print(new_filename)
os.rename(out_file, new_filename)
print(name)
return new_filename,linkNachdem wir die WAV-Datei erhalten haben, können wir die obige Funktion anwenden, um Text daraus zu extrahieren .
Zusammenfassung
Der Code dieses Artikels ist hier
https://drive.google.com/file/d/1FejhGseX_S1Ig_Y5nIPn1OcHN8DLFGIO/view# 🎜🎜 #
Es gibt viele andere Vorgänge, die mit Whisper ausgeführt werden können. Sie können es anhand des Codes in diesem Artikel selbst ausprobieren.Das obige ist der detaillierte Inhalt vonSpracherkennung mit dem Whisper-Modell von OpenAI. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr