
Heim >Technologie-Peripheriegeräte >KI >Deep Convolutional Generative Adversarial Network in der Praxis
Deep Convolutional Generative Adversarial Network in der Praxis

- 王林nach vorne
- 2023-04-12 14:22:12936Durchsuche
Übersetzer |. Zhu Xianzhong
Rezensent | Dies liegt daran, dass das Unternehmen die meisten der gesammelten Daten niemals analysiert oder in irgendeiner Form verwendet. Genauer gesagt wird dies als „Dark Data“ bezeichnet.
„Dunkle Daten“ beziehen sich auf Daten, die durch verschiedene Computernetzwerkvorgänge gewonnen, aber in keiner Weise zur Ableitung von Erkenntnissen oder zur Entscheidungsfindung verwendet werden. Die Fähigkeit einer Organisation, Daten zu sammeln, übersteigt möglicherweise ihren Analysedurchsatz. In einigen Fällen wissen Organisationen möglicherweise nicht einmal, dass Daten erfasst werden. IBM schätzt, dass etwa 90 % der von Sensoren und der Analog-Digital-Umwandlung generierten Daten nie genutzt werden. – Wikipedia-Definition von „Dark Data“ 
Architektur von Deep Convolutional GAN
Wie wir bereits besprochen haben, werden wir mit DCGAN arbeiten, das versucht, die Kernidee von GAN, einem Faltungsnetzwerk zur Erzeugung realistischer Bilder, umzusetzen.
DCGAN besteht aus zwei unabhängigen Modellen: einem Generator (G), der versucht, zufällige Rauschvektoren als Eingabe zu modellieren und die Datenverteilung zu lernen, um gefälschte Stichproben zu generieren, und einem weiteren Diskriminator (D), der die Trainingsdaten (echte Stichproben) erhält. und generierte Daten (gefälschte Proben) und versuchen, diese zu klassifizieren. Den Kampf zwischen diesen beiden Modellen nennen wir einen kontradiktorischen Trainingsprozess, bei dem der Verlust der einen Partei der Gewinn der anderen ist.
Generator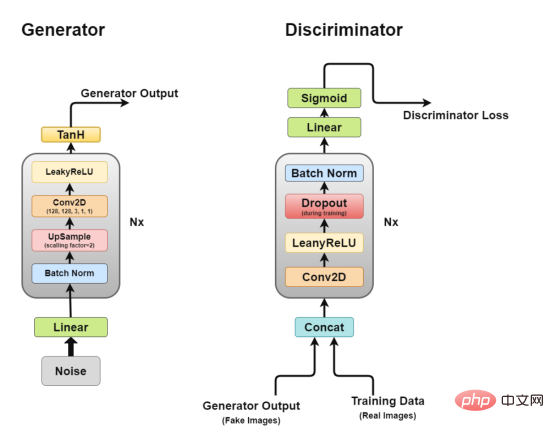
Generator-Architekturdiagramm
Der Generator ist der Teil, der uns am meisten interessiert, da es sich um einen Generator handelt, der gefälschte Bilder generiert, um den Diskriminator zu täuschen.
Schauen wir uns nun die Generatorarchitektur genauer an.
- Lineare Ebene: Rauschvektoren werden in eine vollständig verbundene Ebene eingegeben und deren Ausgabe in einen 4D-Tensor umgewandelt.
- Batch-Normalisierungsschicht: Stabilisiert das Lernen durch Normalisierung der Eingabe auf den Mittelwert Null und die Einheitsvarianz. Dies vermeidet Trainingsprobleme wie verschwindende oder explodierende Gradienten und ermöglicht den Fluss von Gradienten durch das Netzwerk.
- Upsampling-Schicht: Nach meiner Interpretation des Papiers wird darin erwähnt, dass man Upsampling verwendet und dann eine einfache Faltungsschicht darauf anwendet, anstatt eine Faltungstranspositionsschicht für das Upsampling zu verwenden. Aber ich habe gesehen, dass einige Leute Faltungstransponierung verwenden, daher liegt die spezifische Anwendungsstrategie bei Ihnen.
- 2D-Faltungsschicht: Wenn wir eine Matrix hochsampeln, leiten wir sie mit einer Schrittweite von 1 durch die Faltungsschicht und verwenden die gleiche Auffüllung, sodass sie aus den hochgetasteten Daten lernen kann.
- ReLU-Ebene: In diesem Artikel wird die Verwendung von ReLU anstelle von LeakyReLU als Generator erwähnt, da das Modell dadurch schnell gesättigt werden und den Farbraum der Trainingsverteilung abdecken kann.
- TanH-Aktivierungsschicht: In diesem Artikel wird empfohlen, die TanH-Aktivierungsfunktion zur Berechnung der Generatorleistung zu verwenden, es wird jedoch nicht erläutert, warum. Wenn wir eine Vermutung anstellen müssten, dann deshalb, weil die Eigenschaften von TanH eine schnellere Konvergenz des Modells ermöglichen.
Unter diesen bilden Schicht 2 bis Schicht 5 den Kerngeneratorblock, der N-mal wiederholt werden kann, um die gewünschte Ausgabebildform zu erhalten.
Das Folgende ist der Schlüsselcode, wie wir ihn in PyTorch implementieren (den vollständigen Quellcode finden Sie unter der Adresse https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
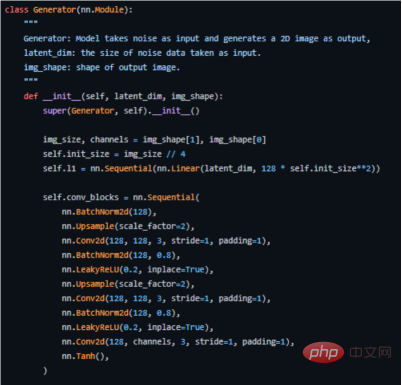
Verwenden Sie den Generator des PyTorch-Frameworks, um den Schlüsselcode zu implementieren einige kleine Anpassungen vornehmen. Anstatt beispielsweise Pooling-Schichten für das Downsampling zu verwenden, verwendet es eine spezielle Faltungsschicht namens Stride Convolutional Layer, die es ihm ermöglicht, sein eigenes Downsampling zu erlernen.
Lassen Sie uns nun einen genaueren Blick auf die Diskriminatorarchitektur werfen.
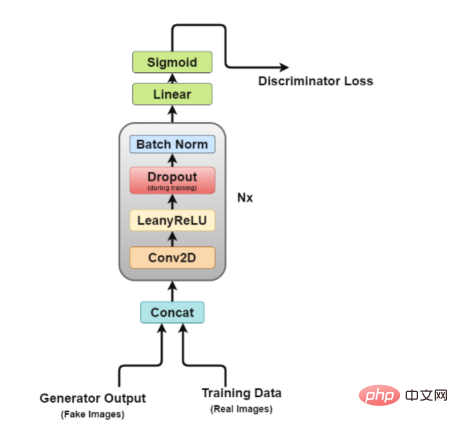 Concat-Schicht: Diese Schicht kombiniert gefälschte und echte Bilder in einem Stapel, um sie dem Diskriminator zuzuführen. Dies kann jedoch auch separat erfolgen, nur um den Generatorverlust zu ermitteln.
Concat-Schicht: Diese Schicht kombiniert gefälschte und echte Bilder in einem Stapel, um sie dem Diskriminator zuzuführen. Dies kann jedoch auch separat erfolgen, nur um den Generatorverlust zu ermitteln.
Faltungsschicht: Wir verwenden hier die Schrittfaltung, die es uns ermöglicht, Bilder herunterzurechnen und Filter in einer Trainingssitzung zu lernen.
LeakyReLU-Schicht: Wie im Papier erwähnt, wurde festgestellt, dass Leakyrelus für den Diskriminator sehr nützlich ist, da es im Vergleich zur maximalen Ausgabefunktion des ursprünglichen GAN-Papiers ein einfacheres Training ermöglicht.
Dropout-Schicht: Wird nur für das Training verwendet und hilft, eine Überanpassung zu vermeiden. Das Modell neigt dazu, sich reale Bilddaten zu merken. An diesem Punkt kann das Training abbrechen, da der Diskriminator nicht mehr vom Generator „getäuscht“ werden kann.
- Batch-Normalisierungsschicht: In dem Dokument wird erwähnt, dass am Ende jedes Diskriminatorblocks (außer dem ersten) eine Batch-Normalisierung angewendet wird. Der in der Arbeit genannte Grund ist, dass die Anwendung der Chargennormalisierung auf jeder Schicht zu Probenoszillationen und Modellinstabilität führen kann.
- Lineare Ebene: Eine vollständig verbundene Ebene, die einen umgeformten Vektor aus einer angewendeten 2D-Stapelnormalisierungsebene übernimmt.
- Sigmoid-Aktivierungsschicht: Da es sich um eine binäre Klassifizierung der Diskriminatorausgabe handelt, wird die logische Wahl der Sigmoid-Schicht getroffen.
- In dieser Architektur bilden Schicht 2 bis Schicht 5 den Kernblock des Diskriminators, und die Berechnung kann N-mal wiederholt werden, um das Modell für alle Trainingsdaten komplexer zu machen.
- So implementieren wir es in PyTorch (den vollständigen Quellcode finden Sie unter der Adresse https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
- Schlüsselcodeabschnitt des in PyTorch implementierten Diskriminators
Gegnerisches Training
Wir trainieren den Diskriminator (D), um die Wahrscheinlichkeit zu maximieren, Trainingsproben und Proben vom Generator (G), die dies tun, die richtige Bezeichnung zuzuweisen kann durch Minimieren von log(D(x)) erfolgen. Gleichzeitig trainieren wir G, um log(1 − D(G(z))) zu minimieren, wobei z den Rauschvektor darstellt. Mit anderen Worten, sowohl D als auch G verwenden die Wertfunktion V (G, D), um das folgende Minimax-Spiel für zwei Spieler zu spielen:
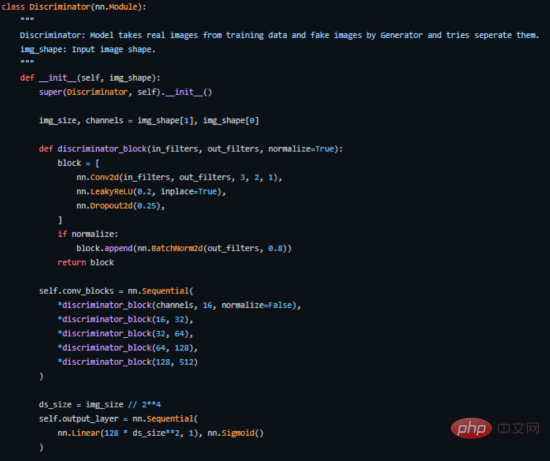
Berechnungsformel der kontradiktorischen Kostenfunktion
In einer praktischen Anwendungsumgebung bietet die obige Gleichung möglicherweise nicht genügend Gradienten, damit G gut lernen kann. In den frühen Phasen des Lernens, wenn G schlecht ist, kann D Proben mit hoher Sicherheit ablehnen, da sie sich erheblich von den Trainingsdaten unterscheiden. In diesem Fall erreicht die Funktion log(1 − D(G(z))) die Sättigung. Anstatt G zu trainieren, um log(1 − D(G(z))) zu minimieren, trainieren wir G, um logD(G(z)) zu maximieren. Diese Zielfunktion generiert die gleichen Fixpunkte für dynamisches G und D, bietet jedoch zu Beginn des Lernens stärkere Gradientenberechnungen. ——arxiv paper
Da wir zwei Modelle gleichzeitig trainieren, kann dies schwierig sein, und GANs sind bekanntermaßen schwer zu trainieren, das werden wir tun Eines der bekannten Probleme, die später besprochen werden, ist der sogenannte Moduskollaps.
Das Papier empfiehlt die Verwendung des Adam-Optimierers mit einer Lernrate von 0,0002. Eine so niedrige Lernrate weist darauf hin, dass GANs dazu neigen, sehr schnell zu divergieren. Außerdem nutzt es Impulse erster und zweiter Ordnung mit Werten von 0,5 und 0,999, um das Training weiter zu beschleunigen. Das Modell wird auf eine normalgewichtete Verteilung mit einem Mittelwert von Null und einer Standardabweichung von 0,02 initialisiert.
Im Folgenden wird gezeigt, wie wir hierfür eine Trainingsschleife implementieren (siehe https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py für den vollständigen Quellcode) . #? Vielzahl von Ausgängen. Wenn es beispielsweise Gesichter generiert, sollte es für jede zufällige Eingabe ein neues Gesicht generieren. Wenn der Generator jedoch eine hinreichend gute und plausible Ausgabe erzeugt, um den Diskriminator zu täuschen, kann es sein, dass er immer wieder die gleiche Ausgabe erzeugt.
Irgendwann wird der Generator einen einzelnen Diskriminator überoptimieren und zwischen einem kleinen Satz von Ausgängen wechseln, eine Situation, die als „Moduskollaps“ bezeichnet wird. 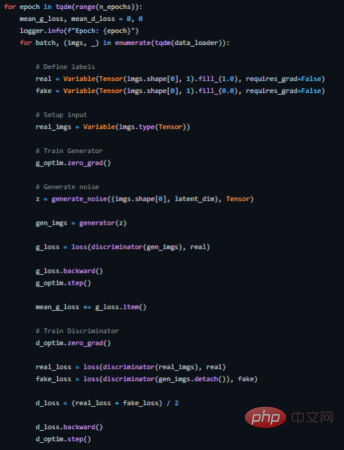
Wasserstein-Verlustfunktionsmethode (Wasserstein-Verlust): Die Wasserstein-Verlustfunktion mildert den Moduskollaps, indem Sie den Diskriminator optimal trainieren können, ohne sich Gedanken über verschwindende Gradienten machen zu müssen. Wenn der Diskriminator nicht in einem lokalen Minimum hängen bleibt, lernt er, die stabile Ausgabe des Generators abzulehnen. Daher müssen Generatoren neue Dinge ausprobieren.
Unrolled GAN-Methode (Unrolled GANs): Unrolled GAN verwendet eine Generatorverlustfunktion, die nicht nur die Klassifizierung des aktuellen Diskriminators, sondern auch die Ausgabe zukünftiger Diskriminatorversionen enthält. Daher kann der Generator nicht für einen einzelnen Diskriminator überoptimiert werden.
APP- Stiltransformation: Apps zur Gesichtsretusche liegen derzeit voll im Trend. Unter anderem sind Gesichtsalterung, weinendes Gesicht und Gesichtsverformung von Prominenten nur einige der Anwendungen, die in den sozialen Medien große Popularität erlangt haben.
- Videospiele: Texturgenerierung von 3D-Objekten und bildbasierte Szenengenerierung sind nur einige der Anwendungen, die der Videospielbranche dabei helfen, größere Spiele schneller zu entwickeln.
- Filmindustrie: CGI (computergenerierte Bilder) ist zu einem wichtigen Bestandteil von Modellfilmen geworden, und mit dem Potenzial von GANs können Filmemacher jetzt größere Träume als je zuvor haben.
Sprachgenerierung: Einige Unternehmen nutzen GANs, um Text-to-Speech-Anwendungen zu verbessern, indem sie damit realistischere Sprache erzeugen.
- Bildwiederherstellung: Verwenden Sie GANs, um beschädigte Bilder zu entrauschen und wiederherzustellen, historische Bilder einzufärben und alte Videos zu verbessern, indem Sie fehlende Frames generieren, um die Bildraten zu erhöhen.
- Fazit
- Kurz gesagt, das oben in diesem Artikel erwähnte Papier zu GAN und DCGAN ist einfach ein wegweisendes Papier, weil es einen beispiellosen neuen Ansatz hat wurden im überwachten Lernen eröffnet. Die darin vorgeschlagene kontradiktorische Trainingsmethode bietet eine neue Methode zum Trainieren von Modellen, die den realen Lernprozess genau simulieren. Es wird also sehr interessant sein zu sehen, wie sich dieser Bereich entwickelt.
- Den vollständigen Implementierungsquellcode des Beispielprojekts finden Sie schließlich in diesem Artikel in meinem GitHub-Quellcode-Repository
- .
Originaltitel:
Implementing Deep Convolutional GAN
, Autor: Akash Agnihotri
Das obige ist der detaillierte Inhalt vonDeep Convolutional Generative Adversarial Network in der Praxis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr