
Heim >Technologie-Peripheriegeräte >KI >Wie werden wir in Zukunft Informationsrecherchen durchführen?
Wie werden wir in Zukunft Informationsrecherchen durchführen?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 14:10:071734Durchsuche
Gast |. Organisiert von Dou Zhicheng
|. Organisiert von Zhang Feng
Suchmaschinen gibt es seit mehr als 20 Jahren und ihre Form und Struktur haben sich kaum verändert. Mit der kontinuierlichen Weiterentwicklung der Internettechnologie wird die Suchumgebung in Zukunft komplexer und vielfältiger, und auch die Art und Weise, wie Benutzer Informationen erhalten, wird sich stark verändern. Verschiedene Eingabeformen wie natürliche Sprache, Stimme und Vision werden zwangsläufig einfache Schlüsselwörter ersetzen ; Mehrere modale Inhaltsausgaben wie Antworten, allgemeines Wissen, Analyseergebnisse und generierte Inhalte ersetzen die einfache Ergebnisliste. Die Interaktionsmethode kann auch von einer einzelnen Abrufrunde zu mehreren Runden natürlicher Sprachinteraktion übergehen.
Welche Eigenschaften wird die zukünftige intelligente Suchtechnologie in der neuen Suchumgebung aufweisen? Kürzlich hielt Dou Zhicheng, stellvertretender Dekan der Hillhouse School of Artificial Intelligence an der Renmin University of China, auf der
AISummit Global Artificial Intelligence Technology Conference, die von 51CTO veranstaltet wurde, eine Grundsatzrede mit dem Titel „Next Generation“. „Intelligent Search Technology“ teilte dem Publikum die Entwicklungstrends und Kernmerkmale der neuen Generation intelligenter Suchtechnologie mit und führte außerdem eine detaillierte Analyse von Technologien wie interaktiver, multimodaler, interpretierbarer Suche und großen modellzentrierten De- indizierte Suche. In diesem Artikel wurde der Inhalt der Rede von Herrn Dou Zhicheng bearbeitet und geordnet, in der Hoffnung, Ihnen neue Inspiration zu geben: Die Hauptmerkmale der zukünftigen Suche
Wir glauben, dass die zukünftige Suche mindestens diese fünf Merkmale aufweisen könnte:Konversation,
- Personen und Suchmaschinen sind eine Möglichkeit für mehrere Interaktionsrunden durch natürliche Sprache.
- Personalisierung, wird je nach den Bedürfnissen verschiedener Benutzer unterschiedliche Ergebnisse zurückmelden, anstatt jedem die gleichen Ergebnisse auf die gleiche Art und Weise zu liefern.
- Multimodal, Der zurückgegebene Inhalt und die Eingabemethode sind möglicherweise nicht auf die Verwendung von Text als Medium oder Methode beschränkt.
- Reiches Wissen, Die von der Suche zurückgegebenen Informationen liegen nicht nur in Form einer Ergebnisliste vor, sondern können auch in verschiedenen Anzeigeformen vorliegen und auf verschiedene Arten von Wissen und Einheiten angezeigt werden.
- De-Indexierung, invertierter Index oder dichter Index müssen ebenfalls dringend große Änderungen vornehmen.
- Konversational
Bei der von herkömmlichen Suchmaschinen verwendeten Methode zum Abrufen von Schlüsselwörtern hoffen wir, alle Kerninformationen, nach denen wir suchen, durch Schlüsselwörter zu beschreiben. Das heißt, wir gehen davon aus, dass eine einzelne Abfrage den Bedarf an diesen Informationen vollständig und genau ausdrücken kann. Wenn jedoch komplexere Informationen ausgedrückt werden, ist es tatsächlich schwierig, die Anforderungen mit Schlüsselwörtern zu erfüllen. Die Konversationssuche kann den Informationsbedarf durch mehrere Interaktionsrunden vollständig ausdrücken, was eher der progressiven Informationsinteraktionsmethode bei der Kommunikation von Menschen entspricht.
Wenn Sie diese Art der interaktiven Suche erreichen möchten, stellt dies große Herausforderungen an das System oder den Algorithmus. Es ist notwendig, dass die Suchmaschine die Absicht des Benutzers aus mehreren Runden natürlicher Sprachinteraktion genau versteht Gleichzeitig muss es auch die Absicht des Benutzers verstehen, die Absicht mit den vom Benutzer gewünschten Informationen abzugleichen.
Im Vergleich zur herkömmlichen Schlüsselwortsuche erfordert die Konversationssuche ein komplexeres Abfrageverständnis (z. B. die Notwendigkeit, Probleme wie Auslassungen und Koreferenzen in der aktuellen Abfrage zu lösen), um die wahre Suchabsicht des Benutzers wiederherzustellen. Der einfachste Weg besteht darin, alle historischen Abfragen zusammenzufügen und sie mithilfe eines vorab trainierten Sprachmodells zu kodieren.
Obwohl die einfache Spleißdialogmethode einfach ist, kann sie zu Rauschen führen. Nicht alle historischen Abfragen sind hilfreich für das Verständnis der aktuellen Abfrage, daher wählen wir nur den Kontext aus, der von ihr abhängt, was auch das Längenproblem lösen kann .
Conversational Retrieval Model COTED
Basierend auf den oben genannten Ideen haben wir das Conversational Dense Retrieval Model COTED vorgeschlagen, das hauptsächlich die folgenden drei Teile umfasst:1 Durch die Identifizierung von Abhängigkeiten in Konversationsabfragen können wir Rauschen beseitigen in Gesprächen, um die Benutzerabsicht besser vorherzusagen.
2. Durch die Datenverbesserung (Imitierung verschiedener Rauschsituationen) und die auf kontrastivem Lernen basierende Entrauschungsverlustfunktion kann das Modell effektiv lernen, irrelevanten Kontext zu ignorieren, und es mit der endgültigen Matching-Verlustfunktion kombinieren, um Multitasking-Lernen durchzuführen.
3. Reduzieren Sie die Lernschwierigkeiten des Modell-Multitasking-Lernens durch Kurslernen und verbessern Sie letztendlich die Modellleistung.
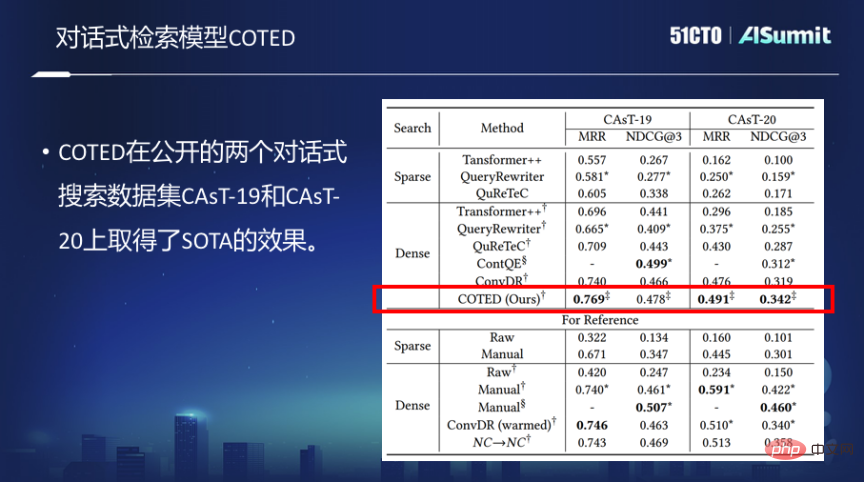
Allerdings sind die für das Training des Konversationssuchmodells ausreichenden Daten tatsächlich sehr begrenzt. Bei wenigen Stichproben ist das Training des Konversationssuchmodells sehr schwierig.
Wie kann dieses Problem gelöst werden? Der Ausgangspunkt ist, ob Suchmaschinenprotokolle für das Training von Konversationssuchmaschinen migriert werden können. Basierend auf dieser Idee werden umfangreiche Websuchprotokolle in Konversationssuchprotokolle umgewandelt und anschließend ein Konversationssuchmodell anhand der konvertierten Daten trainiert. Diese Methode ist jedoch auch mit zwei offensichtlichen Problemen verbunden:
Erstens ist die Konversationssuche bei der herkömmlichen Websuche eine andere Methode für die Konversation in natürlicher Sprache und kann nicht direkt verwendet werden. Zweitens gibt es in der Abfrage selbst viel Rauschen und die Benutzerdaten im Suchprotokoll müssen bereinigt, gefiltert und konvertiert werden, bevor sie in der Konversationssuche verwendet werden können.
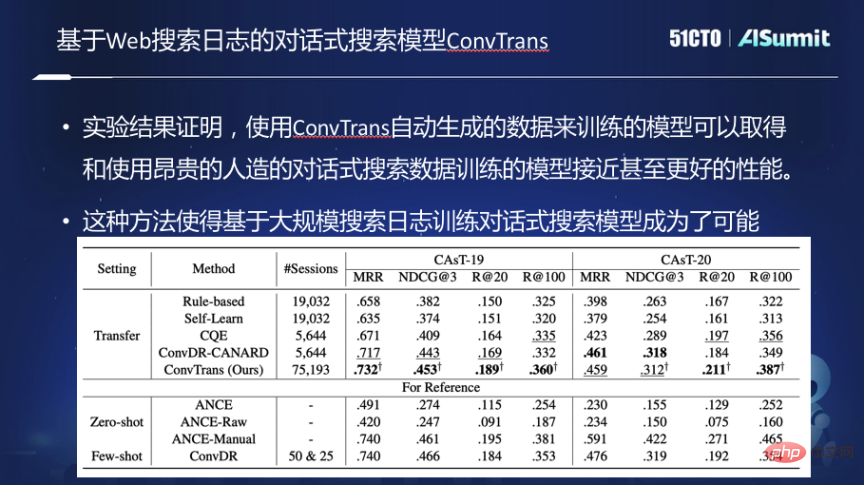
Konversationssuch-Trainingsmodell ConvTrans
Um diese Probleme zu lösen, haben wir ein Konversationssuch-Trainingsmodell ConvTrans erstellt und die folgenden Funktionen implementiert.
Erstens werden die Protokolle in herkömmlichen Websuchmaschinen in einem Diagramm organisiert, und das Diagramm wird erstellt, indem Verbindungen zwischen Abfragen und Abfragen, Abfragen und Dokumenten hergestellt werden. Auf der Grundlage des Diagramms wird ein zweistufiges Abfrageumschreibungsmodell basierend auf T5 verwendet, um eine Schlüsselwortabfrage in die Form einer Frage umzuschreiben. Nach dem Umschreiben verwendet jede Abfrage im Diagramm natürliche Sprache, um die neue Abfrage auszudrücken, und entwirft dann einen Stichprobenalgorithmus, um einen zufälligen Spaziergang durch das Diagramm durchzuführen, um eine Konversationssitzung zu generieren, und trainiert dann das Konversationsmodell basierend auf diesen Daten.
Experimente zeigen, dass mit diesen automatisch generierten Trainingsdaten trainierte Konversationssuchmodelle den gleichen Effekt erzielen können wie die Verwendung teurer künstlicher oder manuell gekennzeichneter Daten, und mit zunehmendem Umfang der automatisch generierten Trainingsdaten wird sich die Leistung weiter verbessern. Dieser Ansatz ermöglicht das Training von Konversationssuchmodellen auf Basis umfangreicher Suchprotokolle.
Obwohl das Konversationssuchmodell einen großen Fortschritt in der Suche gemacht hat, ist diese Konversationsmethode immer noch passiv akzeptierte Benutzereingaben und lieferte Ergebnisse basierend auf den Eingaben. Es gibt keine Initiative um Benutzer zu fragen, wonach sie suchen. Wenn Ihnen im Kommunikationsprozess zwischen Menschen jedoch eine Frage gestellt wird, ergreifen Sie manchmal die Initiative und stellen einige Fragen zur Klärung.
Wenn beispielsweise in der Bing-Suche die Suchanfrage „Kopfschmerzen“ lautet, handelt es sich um Kopfschmerzen. Sie werden gefragt: „Was möchten Sie über diese Krankheit wissen?“ „Was möchten Sie über diese Krankheit wissen“, beispielsweise über ihre Symptome, Behandlung, Diagnose, Ursachen oder Auslöser? Da es sich bei „Kopfschmerzen“ selbst um eine sehr umfassende Abfrage handelt, hofft das System in diesem Fall, die gesuchten Informationen weiter zu klären.
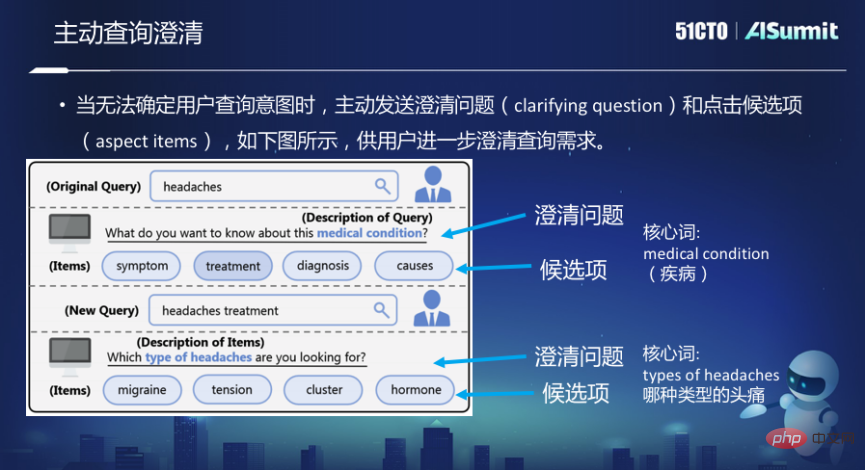
Hier gibt es zwei Probleme. Das erste ist das Kandidatenelement, welches spezifische Element der Benutzer klären soll. Die zweite besteht darin, die Frage zu klären. Die Suchmaschine ergreift die Initiative, dem Benutzer diese Frage zu stellen. Das Kernwort ist der wichtigste Teil zur Klärung des Problems.
In diesem Aspekt der Erkundung besteht der erste darin, über Abfrageprotokolle und Wissensdatenbanken einige Klärungskandidaten zu generieren, wenn eine Abfrage erfolgt. Zweitens können einige Kernwörter dieser Klärungsfrage anhand der Suchergebnisse anhand von Regeln vorhergesagt werden. Gleichzeitig werden einige Daten auch beschriftet und ein überwachtes Modell zur Klassifizierung von Textbeschriftungen verwendet. Drittens trainieren Sie ein generatives End-to-End-Modell basierend auf diesen annotierten Daten weiter.
Personalisierung
Personalisierung bedeutet, dass zukünftige Suche benutzerzentriert sein wird. Heutige Suchmaschinen liefern die gleichen Ergebnisse, egal wer sucht. Dies entspricht nicht den spezifischen Informationsbedürfnissen der Nutzer.
Das aktuelle personalisierte Suchmodell übernimmt ein Modell, das zunächst Wissen und Informationen, mit denen der Benutzer vertraut ist, durch den Benutzerverlauf erlernt und dann eine personalisierte Entitätsdisambiguierung für die Abfrage durchführt. Zweitens wird der personalisierte Abgleich durch eindeutige Abfrageentitäten verbessert.
Darüber hinaus haben wir auch die Konstruktion von Multi-Interessen-Modellen der Benutzer basierend auf Produktkategorien untersucht. Es wird davon ausgegangen, dass Benutzer möglicherweise in allen Kategorien ihre eigenen Vorlieben für einige Marken (Spezifikationen, Modelle) haben, diese Präferenz kann jedoch nicht vorhanden sein einfach durch ein oder zwei Vektoren bestimmt, die kommen und gehen, um zu beschreiben. Ein Wissensgraph sollte auf der Grundlage der Einkaufshistorie des Benutzers erstellt werden, und durch den Wissensgraphen sollten unterschiedliche Interessen für verschiedene Kategorien erlernt werden, sodass letztendlich genauere personalisierte Suchergebnisse gepusht werden können.
Sie können dieselbe personalisierte Methode auch zum Erstellen eines Chatbots verwenden. Die Kernidee besteht darin, die personalisierten Interessen und Sprachmuster des Benutzers durch die historischen Gespräche des Benutzers zu lernen, ein personalisiertes Dialogmodell zu trainieren und die Sprache des Benutzers zu imitieren (Agent). .
Multimodalität
Heutzutage unterliegen Suchmaschinen tatsächlich einigen Einschränkungen bei der Verarbeitung multimodaler Informationen. In Zukunft kann es sich bei den Informationen, die Nutzer erhalten, nicht nur um Texte und Webseiten handeln, sondern auch um Bilder, Videos und komplexere Strukturinformationen. Daher haben zukünftige Suchmaschinen bei der Erfassung multimodaler Informationen noch viel Arbeit vor sich.
Aktuelle Suchmaschinen weisen immer noch viele Mängel auf, wenn es darum geht, den modalübergreifenden Abruf zu verstehen oder durchzuführen, d. h. wenn sie eine Textbeschreibung angeben und das entsprechende Bild finden. Wenn ähnliche Suchen auf Mobiltelefone verlagert werden, werden die Einschränkungen noch größer.
Das sogenannte Multimodal bedeutet, dass Sprache, Bilder, Bilder, Videos und andere Modalitäten einem einheitlichen Raum zugeordnet werden. Das bedeutet, dass Sie Text zum Suchen von Bildern, Bilder zum Suchen von Text und Bilder zum Suchen verwenden können Finden Sie Bilder usw.
Als Reaktion darauf haben wir ein groß angelegtes multimodales Pre-Training-Modell erstellt – Wenlan. Es konzentriert sich auf das Training auf der Grundlage von Informationen, die durch schwach überwachte Korrelationen von massiven Internetbildern und Text in der Nähe bereitgestellt werden. Im Twin-Tower-Modus besteht das endgültige Training aus einem Bild-Encoder und einem Text-Encoder. Diese beiden Encoder verwenden den End-to-End-Matching-Optimierungs-Lernprozess, um die Zuordnung des endgültigen Darstellungsvektors zu einem einheitlichen Raum zu ermöglichen Die feine Körnung des Bildes und die feine Körnung des Textes werden miteinander verbunden.
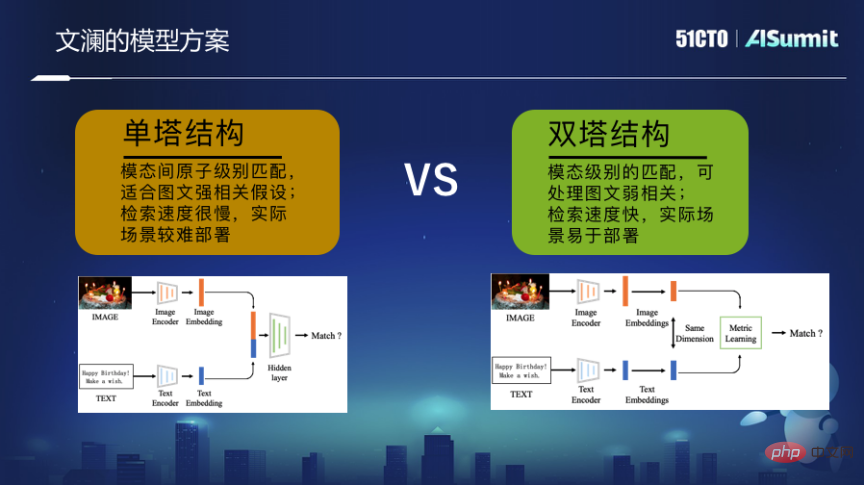
Diese Art der modalübergreifenden Suchfunktion bietet Benutzern nicht nur durchgängig mehr Platz bei der Verwendung von Websuchmaschinen, sondern kann auch viele Anwendungen unterstützen, z. B. die Erstellung, egal ob es sich um soziale Medien handelt Es ist kulturell oder kreativ, Sie können es unterstützen.
Reiches Wissen
Der Hauptteil aktueller Suchmaschinen sind immer noch Webseiten, aber in Zukunft besteht die Einheit der Suchmaschinenverarbeitung nicht nur aus Webseiten, sondern sollte auch auf Wissen basieren, einschließlich der zurückgegebenen Ergebnisse Seien Sie auf hohem Wissensniveau und nicht auf einer seitenweisen Liste. Oft möchten Benutzer Suchmaschinen tatsächlich nutzen, um komplexe Informationsanforderungen zu erfüllen, und hoffen daher, dass Suchmaschinen bei der Analyse der Ergebnisse helfen, anstatt sie einzeln analysieren zu lassen.
Basierend auf dieser Idee haben wir eine Analyse-Engine entwickelt, die einer detaillierten Textanalyse auf Basis einer Suchmaschine entspricht, um Benutzern dabei zu helfen, effizient und schnell hochqualitatives Wissen zu erlangen. Helfen Sie Benutzern, umfangreiche Dokumente zu lesen und zu verstehen und die darin enthaltenen Schlüsselinformationen und Kenntnisse zu extrahieren, zu analysieren und anschließend bereitzustellen Benutzer mit Entscheidungsunterstützung.
Wenn ein Benutzer beispielsweise Informationen zum Thema Dunst finden möchte, kann er direkt „Haze“ eingeben. Das Rich-Wissens-Modell unterscheidet sich von den Ergebnissen herkömmlicher Suchmaschinen. Es gibt möglicherweise eine Zeitleiste zurück, um dem Benutzer die Verteilung von Informationen über Haze auf der Zeitleiste usw. mitzuteilen. Außerdem werden die Unterthemen zu Haze und den Informationen der Institutionen zusammengefasst . Welche, welche Charaktere gibt es? Natürlich kann es auch eine detaillierte Ergebnisliste wie eine Suchmaschine bereitstellen.
Diese Möglichkeit, Analysen und interaktive Analysen direkt bereitzustellen, kann Benutzern dabei helfen, komplexe Informationen besser zu erhalten. Was den Benutzern bereitgestellt wird, ist nicht mehr eine einfache Liste von Suchergebnissen. Natürlich ist diese Art der interaktiven mehrdimensionalen Wissensanalyse nur eine Anzeigemethode, und in Zukunft können weitere Methoden verwendet werden. Eines der Dinge, die wir jetzt tun, ist vom Abrufen bis zur Generierung (vernünftiger) Inhalte.
De-Indexierung
Heutzutage verfolgen Suchmaschinen weitgehend einen abgestuften Ansatz mit der Indexierung als Kern, indem sie den erforderlichen Inhalt aus einer großen Anzahl von Internet-Webseiten zurückkriechen und dann einen Index erstellen, bei dem es sich um einen invertierten Index oder einen dichten Vektorindex handelt . Nachdem die Anfrage des Benutzers eingegangen ist, wird zunächst ein Rückruf durchgeführt und anschließend eine verfeinerte Sortierung basierend auf den Rückrufergebnissen durchgeführt.
Dieses Modell hat viele Nachteile, da es in Phasen unterteilt werden muss. Wenn beispielsweise in einer Phase ein Problem auftritt, wird das gewünschte Ergebnis nicht in der Rückrufphase gefunden, egal wie gut es in der Phase ist In der Sortierphase können keine guten Ergebnisse erzielt werden.
In zukünftigen Suchmaschinen wird diese Struktur möglicherweise durchbrochen. Die neue Idee besteht darin, ein großes Modell zu verwenden, um das aktuelle Indexschema zu ersetzen, und alle Abfragen können über das Modell erfüllt werden. Dadurch entfällt die Notwendigkeit, Indizes zu verwenden, und die gewünschten Ergebnisse werden direkt über dieses Modell zurückgegeben.
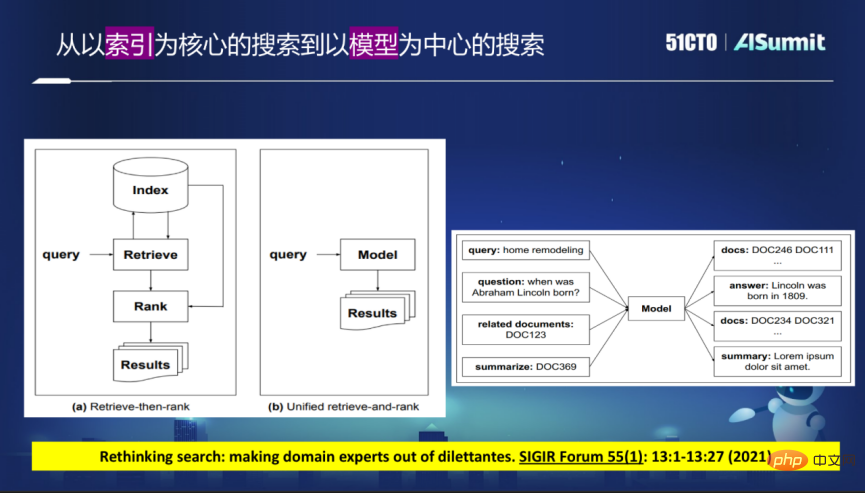
Auf dieser Grundlage kann direkt eine Ergebnisliste bereitgestellt werden, oder die vom Benutzer gewünschte Antwort kann direkt bereitgestellt werden, und die Antwort kann sogar ein Bild sein, um die verschiedenen Modalitäten besser zu integrieren. Das Entfernen des Index und die direkte Rückmeldung der Ergebnisse über das Modell bedeutet, dass das Modell die Dokumentkennung direkt zurückgeben oder zurückgeben kann. Die Dokumentkennung muss in das Modell eingebettet werden, um eine modellzentrierte Suche zu erstellen.
Zusammenfassung
Heutzutage verwenden Suchmaschinen häufig das einfache Modell von Schlüsselwörtern als Eingabe und Dokumentenliste als Ausgabe. Es gibt bereits einige Probleme bei der Erfüllung der komplexen Informationsbeschaffungsbedürfnisse der Menschen. Die Suchmaschine der Zukunft wird dialogorientiert, personalisiert, benutzerzentriert sein und in der Lage sein, Stereotypen zu durchbrechen. Gleichzeitig kann es multimodale Informationen verarbeiten, Wissen verarbeiten und Wissen zurückgeben. In Bezug auf die Architektur werden wir in Zukunft definitiv das bestehende indexzentrierte Modell, das einen invertierten Index oder einen dichten Vektorindex verwendet, durchbrechen und schrittweise zu einem modellzentrierten Modell übergehen.
Gastvorstellung
Dou Zhicheng, Stellvertretender Dekan der Hillhouse School of Artificial Intelligence, Renmin University of China, Projektmanager der Richtung „Intelligent Information Retrieval and Mining“ von Beijing Zhiyuan Artificial Institut für Geheimdienstforschung. Im Jahr 2008 wechselte er zu Microsoft Research Asia und beschäftigte sich mit Arbeiten im Zusammenhang mit der Internetsuche, wobei er umfangreiche Erfahrungen in der Forschung und Entwicklung von Informationsabfragetechnologien sammelte. Seit 2014 lehrt er an der Renmin University of China. Seine Forschungsschwerpunkte sind intelligente Informationsbeschaffung und Verarbeitung natürlicher Sprache. Er hat den Best Paper Nomination Award bei der International Conference on Information Retrieval (SIGIR 2013), den Best Paper Award bei der Asian Conference on Information Retrieval (AIRS 2012) und den Best Paper Award bei der National Academic Conference on Information Retrieval gewonnen ( CCIR 2018, CCIR 2021). Er ist Vorsitzender des Programmausschusses von SIGIR 2019 (kurzer Artikel), Vorsitzender des Programmausschusses der Information Retrieval Evaluation Conference NTCIR-16 und stellvertretender Generalsekretär des Big Data Expert Committee der China Computer Federation . In den letzten zwei Jahren konzentrierte er sich hauptsächlich auf personalisiertes und diversifiziertes Suchranking, interaktive und konversationale Suchmodelle, vorab trainierte Methoden zum Abrufen von Informationen, Interpretierbarkeit von Such- und Empfehlungsmodellen, personalisierte Produktsuche usw.
Das obige ist der detaillierte Inhalt vonWie werden wir in Zukunft Informationsrecherchen durchführen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr