
Heim >Technologie-Peripheriegeräte >KI >Erforschung und Praxis der groben Ranking-Optimierung der Meituan-Suche
Erforschung und Praxis der groben Ranking-Optimierung der Meituan-Suche

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 11:31:092030Durchsuche
Autor:Xiaojiang Suogui, Li Xiang et al.
Grobes Ranking ist ein wichtiges Modul des Such- und Werbesystems in der Branche. Bei der Erforschung und Praxis der Optimierung des groben Ranking-Effekts optimierte das Suchranking-Team von Meituan das grobe Ranking unter zwei Gesichtspunkten: Feinranking-Verknüpfung und gemeinsame Optimierung von Effekt und Leistung basierend auf tatsächlichen Geschäftsszenarien, wodurch der Effekt des groben Rankings verbessert wurde.
1. Einführung
Wie wir alle wissen, verwenden Sortiersysteme in großen industriellen Anwendungsbereichen wie Suche, Empfehlung und Werbung im Allgemeinen eine Kaskadenarchitektur, um Leistung und Wirkung auszugleichen [1,2] , wie in Abbildung 1 unten dargestellt. Am Beispiel des Meituan-Suchrankingsystems ist das gesamte Ranking in die Stufen Grobsortierung, Feinsortierung, Neuordnung und gemischte Sortierung unterteilt. Die Grobsortierung liegt zwischen Rückruf und Feinsortierung und es ist erforderlich, ein Element mit hundert Ebenen herauszufiltern Geben Sie es aus einem tausendstufigen Kandidaten-Item-Set an die feine Ruderschicht weiter. Abbildung 1 Sortiertrichter Stichprobenauswahlverzerrung
: Beim Kaskadensortierungssystem ist die grobe Sortierung weit von der endgültigen Ergebnisanzeige entfernt, was zu einem großen Unterschied zwischen dem Offline-Trainingsprobenraum des groben Sortiermodells und dem vorherzusagenden Probenraum führt Es besteht eine schwerwiegende Verzerrung bei der Stichprobenauswahl. 
Verknüpfung von Grobsortierung und Feinsortierung
: Die Grobsortierung erfolgt zwischen Rückruf und Feinsortierung, um mehr Informationen über nachfolgende Verknüpfungen zu erhalten und zu verwenden, um den Effekt zu verbessern.
- Leistungsbeschränkungen: Die Kandidatenmenge für die Online-Grobranking-Vorhersage ist viel höher als die des Feinranking-Modells. Allerdings stellt das tatsächliche gesamte Suchsystem strenge Anforderungen an die Leistung, was dazu führt, dass man sich auf die Vorhersage konzentrieren muss Leistung für grobes Ranking. Dieser Artikel konzentriert sich auf die oben genannten Herausforderungen, um die relevante Erforschung und Praxis der groben Ranking-Layer-Optimierung der Meituan-Suche zu teilen. Darunter werden wir das Problem der Stichprobenauswahlverzerrung im Feinranking-Verknüpfungsproblem lösen. Dieser Artikel ist hauptsächlich in drei Teile gegliedert: Im ersten Teil wird kurz die Entwicklungsroute der groben Ranking-Ebene des Meituan-Suchrankings vorgestellt. Der zweite Teil stellt die damit verbundene Erforschung und Praxis der groben Ranking-Optimierung vor Destillation und vergleichendes Lernen zur Optimierung des Grobsortierungseffekts. Die zweite Aufgabe besteht darin, die Grobsortierungsleistung und den Effekt der Grobsortierungsoptimierung zu berücksichtigen Der Effekt ist erheblich; der letzte Teil ist die Zusammenfassung und der Ausblick. Der Inhalt ist für alle hilfreich und inspirierend.
- 2. Grobe Route der Ranking-Entwicklung Die grobe Entwicklung der Ranking-Technologie von Meituan Search ist in die folgenden Phasen unterteilt:
- 2016
: basierend auf Relevanz, Qualität und Conversion-Rate. Die Informationen sind Diese Methode ist einfach, aber die Ausdrucksfähigkeit der Merkmale ist schwach. Die Gewichte werden manuell bestimmt und es gibt viel Raum für Verbesserungen beim Sortiereffekt.
2017
: Punktweises prädiktives Ranking unter Verwendung eines einfachen LR-Modells basierend auf maschinellem Lernen.
- 2018: Unter Verwendung des Zwei-Turm-Modells basierend auf dem inneren Vektorprodukt werden auf beiden Seiten Abfragewörter, Benutzer, Kontextmerkmale und Händlermerkmale eingegeben. Nach einer umfassenden Netzwerkberechnung werden Benutzer- und Abfragewortvektoren eingegeben Generieren Sie jeweils einen Händlervektor und berechnen Sie dann das innere Produkt, um die geschätzte Punktzahl für die Sortierung zu erhalten. Mit dieser Methode können Händlervektoren im Voraus berechnet und gespeichert werden, sodass die Online-Vorhersage schnell ist, die Möglichkeit, Informationen auf beiden Seiten zu kreuzen, jedoch begrenzt ist.
- 2019: Um das Problem zu lösen, dass das Twin-Tower-Modell Cross-Features nicht gut modellieren kann, wird die Ausgabe des Twin-Tower-Modells als Feature verwendet und mit anderen Cross-Features fusioniert das GBDT-Baummodell.
- 2020 bis heute: Aufgrund der Verbesserung der Rechenleistung begann ich, das NN-End-to-End-Grobmodell zu erforschen und das NN-Modell weiter zu iterieren. Zu den derzeit in der Branche am häufigsten verwendeten grobkörnigen Modellen gehören das Twin-Tower-Modell wie Tencent [3] und iQiyi [4] sowie das interaktive NN-Modell wie Alibaba [1, 2]. Im Folgenden wird hauptsächlich die damit verbundene Optimierungsarbeit von Meituan Search im Prozess der Aktualisierung des groben Rankings auf das NN-Modell vorgestellt, die hauptsächlich zwei Teile umfasst: Optimierung des groben Ranking-Effekts und gemeinsame Effekt- und Leistungsoptimierung.
3. Grobe Ranking-Optimierungspraxis
Mit vielen Effektoptimierungsarbeiten [5,6], die im Meituan Search Fine Ranking NN-Modell implementiert wurden, begannen wir auch, das grobe Ranking zu untersuchen Optimierung von NN-Modellen. Da die Grobsortierung strengen Leistungsbeschränkungen unterliegt, ist es nicht möglich, die Optimierungsarbeit der Feinsortierung direkt für die Grobsortierung wiederzuverwenden. Im Folgenden wird die Optimierung des Verknüpfungseffekts der Feinsortierung durch die Migration der Sortierfähigkeiten der Feinsortierung auf die Grobsortierung sowie die Kompromissoptimierung des Effekts und der Leistung der automatischen Suche basierend auf der neuronalen Netzwerkstruktur vorgestellt.
3.1 Optimierung des Feinranking-Verknüpfungseffekts
Das grobe Ranking-Modell ist durch Scoring-Leistungsbeschränkungen begrenzt, die dazu führen, dass die Modellstruktur verglichen wird mit dem Feinsortierungsmodell Es ist einfacher und die Anzahl der Merkmale ist viel geringer als bei der Feinsortierung, sodass der Sortiereffekt schlechter ist als bei der Feinsortierung. Um den Effektverlust auszugleichen, der durch die einfache Struktur und die geringeren Merkmale des Grobranking-Modells verursacht wird, haben wir versucht, das Feinranking mit der Wissensdestillationsmethode [7] zu verknüpfen und das Grobranking zu optimieren.
Wissensdestillation ist eine gängige Methode in der Branche, um die Modellstruktur zu vereinfachen und den Effektverlust zu minimieren. Sie übernimmt ein Lehrer-Schüler-Paradigma: ein Modell mit komplexer Struktur und starke Lernfähigkeit Als Lehrermodell wird ein Modell mit einer relativ einfachen Struktur als Schülermodell verwendet. Das Lehrermodell wird verwendet, um die Ausbildung des Schülermodells zu unterstützen und so das „Wissen“ des Lehrermodells auf das Schülermodell zu übertragen, um es zu verbessern die Wirkung des Student-Modells. Das schematische Diagramm der Feinreihendestillation und der Grobreihendestillation ist in Abbildung 2 dargestellt. Das Destillationsschema ist in die folgenden drei Typen unterteilt: Feinreihenergebnisdestillation, Feinreihenvorhersage-Score-Destillation und Merkmalsdarstellungsdestillation. Die praktischen Erfahrungen dieser Destillationsschemata im groben Ranking der Meituan-Suche werden im Folgenden vorgestellt.

Abbildung 2 Schematische Darstellung der Feinreihendestillation und der Grobreihendestillation
#🎜🎜 #3.1.1 Destillation der Ergebnisliste der FeinsortierungDie Grobsortierung ist das Vormodul der Feinsortierung. Ihr Ziel ist es, zunächst eine Reihe von Kandidaten mit besserer Qualität auszusortieren und in die Feinsortierung einzugeben , ausgewählt aus Trainingsbeispielen. Betrachten Sie zusätzlich zu den regulären Elementen, bei denen Benutzer Aktionen ausgeführt haben (klicken, eine Bestellung aufgeben, ), als positive Beispiele und die Elemente, bei denen keine Exposition aufgetreten ist, als negativ Bei Stichproben können Sie auch eine gewisse Sortierung durch das Feinranking-Modell einführen. Die als Ergebnis erstellten positiven und negativen Stichproben können nicht nur die Stichprobenauswahlverzerrung des Grobranking-Modells bis zu einem gewissen Grad mildern, sondern auch die Sortierfähigkeit des Feinrankings auf übertragen grobe Rangfolge. Im Folgenden werden die praktischen Erfahrungen bei der Verwendung der Feinsortierungsergebnisse zur Destillation des Grobsortierungsmodells im Meituan-Suchszenario vorgestellt.
Strategie 1: Wählen Sie unten auf der Grundlage der positiven und negativen Proben, die von Benutzern zurückgesendet wurden, zufällig eine kleine Anzahl unbelichteter Proben aus des verfeinerten Rankings als Das Komplement der groben Zeilennegativproben ist in Abbildung 3 dargestellt. Diese Änderung hat einen Offline-Recall@150 (eine Erklärung des Indikators finden Sie im Anhang ) +5PP und eine Online-CTR +0,1 %. Nr #Strategie 2: Stichproben direkt aus dem fein sortierten Satz, um Trainingsbeispiele zu erhalten, und die fein sortierten Positionen als Beschriftungen verwenden, um Paare für das Training zu erstellen, wie in Abbildung 4 unten dargestellt. Im Vergleich zu Strategie 1 beträgt der Offline-Effekt Recall@150 +2PP und die Online-CTR +0,06 %.
Abbildung 4 Von vorne nach hinten sortieren, um ein Paarpaarmuster zu bilden
#🎜 🎜 #Strategie 3: Basierend auf der Stichprobensatzauswahl von Strategie 2 wird das Etikett durch Binning der verfeinerten Sortierposition erstellt und dann das Paar gemäß dem Binning-Label für erstellt Ausbildung. Im Vergleich zu Strategie 2 beträgt der Offline-Effekt Recall@150 +3PP und die Online-CTR +0,1 %.
3.1.2 Destillation der Feinranking-Vorhersagebewertung
Die vorherige Verwendung der Sortierergebnisdestillation ist eine grobe Möglichkeit, Feinranking-Informationen zu verwenden Auf dieser Grundlage fügen wir außerdem die Vorhersagebewertungsdestillation [8] hinzu, in der Hoffnung, dass die vom groben Bewertungsmodell ausgegebene Bewertung und die vom feinen Bewertungsmodell ausgegebene Bewertungsverteilung so gut wie möglich übereinstimmen, wie in Abbildung 5 unten dargestellt: #🎜 🎜## 🎜🎜#
Abbildung 5 Feinranking-Vorhersage-Score-Konstruktion Hilfsverlust
In Bezug auf die spezifische Implementierung verwenden wir ein zweistufiges Destillationsparadigma, um das Grobklassifizierungsmodell basierend auf dem vorab trainierten Feinklassifizierungsmodell zu destillieren. Der Destillationsverlust verwendet den minimalen quadratischen Fehler der Ausgabe des Grobklassifizierungsmodells und der Feinklassifizierung Modellausgabe und fügt einen hinzu. Der Parameter Lambda wird verwendet, um die Auswirkung des Destillationsverlusts auf den Endverlust zu steuern, wie in Formel (1) gezeigt. Bei Verwendung der präzisen fraktionierten Destillationsmethode beträgt der Offline-Effekt Recall@150 +5PP und der Online-Effekt CTR +0,05 %.
3.1.3 Feature-Repräsentationsdestillation
Die Branche nutzt die Wissensdestillation, um eine grobe Ranking-Repräsentationsmodellierung zu erreichen. Es wurde jedoch bestätigt, dass dies eine effektive Möglichkeit ist, den Modelleffekt zu verbessern [7]. Die Verwendung herkömmlicher Methoden zur Destillationsdarstellung weist die folgenden Mängel auf: Der erste besteht darin, dass die Sortierbeziehung zwischen Grobsortierung und Feinsortierung nicht destilliert werden kann. Wie oben erwähnt, hat die Sortierergebnisdestillation in unserem Szenario verbesserte Auswirkungen dass die traditionelle Verwendung von KL als Wissensdestillationsschema zur Repräsentationsmessung jede Dimension der Repräsentation unabhängig behandelt und hochrelevante und strukturierte Informationen nicht effektiv destillieren kann [9]. Herkömmliche Wissensdestillationsstrategien für die Repräsentationsdestillation sind möglicherweise nicht in der Lage, dieses strukturierte Wissen gut zu erfassen.
Wir wenden kontrastive Lerntechnologie auf das grobe Ranking-Modell an, sodass das grobe Ranking-Modell bei der Destillation der Darstellung des feinen Ranking-Modells auch die Ordnungsbeziehung destillieren kann. Wir verwenden
zur Darstellung des Grobmodells und zur Darstellung des Feinmodells. Angenommen, q ist eine Anfrage im Datensatz. ist ein positives Beispiel unter dieser Anfrage und sind die entsprechenden k negativen Beispiele unter dieser Anfrage. Wir geben
in das Grobranking- bzw. Feinranking-Netzwerk ein, um die entsprechenden Darstellungen zu erhalten Gleichzeitig geben wir in das Grobranking-Netzwerk ein, um die Codierung des Grobranking-Modells zu erhalten endgültige Darstellung. Für die Auswahl negativer Beispielpaare für vergleichendes Lernen übernehmen wir die Lösung in Strategie 3, um die Reihenfolge der Feinsortierung in Behälter zu unterteilen. Die Darstellungspaare der Feinsortierung und der Grobsortierung im gleichen Behälter werden als positive Beispiele und die groben Sortierpaare betrachtet und Feinsortierung zwischen verschiedenen Bins werden als positive Beispiele betrachtet, und dann wird InfoNCE Loss verwendet, um dieses Ziel zu optimieren: der Temperaturkoeffizient. Durch die Analyse der Eigenschaften des InfoNCE-Verlusts ist es nicht schwer herauszufinden, dass die obige Formel im Wesentlichen einer Untergrenze entspricht, die die gegenseitige Information zwischen der Grobdarstellung und der Feindarstellung maximiert. Daher maximiert diese Methode im Wesentlichen die Konsistenz zwischen Feindarstellung und Grobdarstellung auf der Ebene der gegenseitigen Information und kann strukturiertes Wissen effektiver destillieren. Abbildung 6: Verfeinerter Informationstransfer durch vergleichendes Lernen Einzelheiten zu verwandten Arbeiten finden Sie in unserem Artikel [10] (in der Einreichung). 3.2 Gemeinsame Optimierung von Effekt und Leistung
Wie bereits erwähnt, ist der grobe Ranking-Kandidatensatz für die Online-Vorhersage groß, wenn man die Einschränkungen der vollständigen Linkleistung des Systems berücksichtigt muss die Vorhersageeffizienz berücksichtigen. Die oben erwähnte Arbeit basiert alle auf dem Paradigma der einfachen DNN + -Destillation, es gibt jedoch zwei Probleme: Um die Leistung zu verbessern, werden nur einfache Funktionen verwendet, und es werden keine umfangreicheren Cross-Features eingeführt, was Raum für weitere Verbesserungen bietet Modelleffekt.
- Bei der Destillation mit einer festen groben Modellstruktur geht der Destillationseffekt verloren, was zu einer suboptimalen Lösung führt [11].
- Nach unserer praktischen Erfahrung kann die direkte Einführung von Cross-Features in die Rohschicht die Online-Latenzanforderungen nicht erfüllen. Um die oben genannten Probleme zu lösen, haben wir daher eine grobe Ranking-Modellierungslösung basierend auf der Suche nach neuronalen Netzwerkarchitekturen untersucht und implementiert. Diese Lösung optimiert gleichzeitig die Wirkung und Leistung des groben Ranking-Modells und wählt die beste Merkmalskombination und das beste Modell aus Die grobe Rangfolge-Verzögerungsanforderungen Struktur, das Gesamtarchitekturdiagramm ist in Abbildung 7 unten dargestellt: und Modellstruktur basierend auf NAS#🎜 🎜#
Nachfolgend suchen wir nach der neuronalen Netzwerkarchitektur (NAS
) und Einführung der Effizienzmodellierung. Eine kurze Einführung in die wichtigsten technischen Punkte:Suche nach neuronaler Netzwerkarchitektur: Wie in Abbildung 7 oben gezeigt, verwenden wir eine Modellierungsmethode Basierend auf ProxylessNAS [12] fügt das gesamte Modelltraining zusätzlich zu den Netzwerkparametern Funktionsmaskenparameter und Netzwerkarchitekturparameter hinzu. Diese Parameter sind differenzierbar und werden zusammen mit den Modellzielen gelernt. Im Merkmalsauswahlteil führen wir für jedes Merkmal einen auf der Bernoulli-Verteilung basierenden Maskenparameter ein, siehe Formel (4), in dem der θ-Parameter der Bernoulli-Verteilung durch Backpropagation aktualisiert wird und schließlich die Bedeutung jedes Merkmals ermittelt wird. Im Strukturauswahlteil wird die L-Schicht-Mixop-Darstellung verwendet. Jede Gruppe von Mixop enthält N optionale Netzwerkstruktureinheiten. Im Experiment haben wir mehrschichtige Perzeptrone mit unterschiedlicher Anzahl verborgener Schicht-Neuronaleinheiten verwendet, wobei N = {1024, 512, 256, 128, 64}, und wir haben auch Struktureinheiten mit einer versteckten Einheitennummer von 0 hinzugefügt, um neuronale Netze mit unterschiedlicher Anzahl von Schichten auszuwählen.
Effizienzmodellierung: Um Effizienzmetriken im Modellziel zu modellieren, benötigen wir Verwenden Sie ein differenzierbares Lernziel, um den Zeitverbrauch des Modells darzustellen. Der Zeitverbrauch des groben Modells ist hauptsächlich in den Zeitverbrauch der Funktionen und den Zeitverbrauch der Modellstruktur unterteilt.
- Für den Feature-Zeitverbrauch kann die Verzögerungserwartung jedes Feature-Fi wie in Formel (5) modelliert werden, wobei# 🎜🎜##🎜 🎜# ist die Verzögerung jedes vom Server aufgezeichneten Merkmals.
- In tatsächlichen Situationen können Funktionen in zwei Kategorien unterteilt werden, ein Teil ist die transparente Upstream-Übertragungsfunktion und Das andere ist die Funktion der transparenten Upstream-Übertragung. Die Zeit ergibt sich hauptsächlich aus der Upstream-Übertragungsverzögerung; eine andere Art von Funktion ergibt sich aus der lokalen Erfassung (Lesen von KV oder Berechnung), dann kann die Verzögerung jeder Funktionskombination wie folgt modelliert werden: #🎜🎜 #
wobei
und die Anzahl der entsprechenden Feature-Sets darstellen, und Modellsystem-Feature-Pull-Parallelität. Informationen zur Verzögerungsmodellierung der Modellstruktur finden Sie im rechten Teil von Abbildung 7 oben. Da die Ausführung dieser Mixops sequentiell erfolgt, können wir die Modellstrukturverzögerung und den Zeitverbrauch des gesamten Modells rekursiv berechnen Teil. Es kann durch die letzte Schicht von Mixop ausgedrückt werden. Das schematische Diagramm ist in Abbildung 8 dargestellt: Abbildung 8 Modellverzögerungsberechnungsdiagramm Abbildung 8 Die linke Seite ist ein grobes Netzwerk mit Auswahl der Netzwerkarchitektur, wobei Stellt das Gewicht der neuronalen Einheit der Schicht dar. Auf der rechten Seite sehen Sie ein schematisches Diagramm zur Berechnung der Netzwerkverzögerung. Daher kann der Zeitverbrauch des gesamten Modellvorhersageteils durch die letzte Schicht des Modells ausgedrückt werden, wie in Formel (7) gezeigt:
Abschließend führen wir den Effizienzindex in das Modell ein, und zwar endgültig Der Verlust des Modelltrainings ist wie in Formel (8) unten dargestellt, wobei f das Feinranking-Netzwerk darstellt, den Gleichgewichtsfaktor darstellt und die Bewertungsausgabe der groben bzw. feinen Rangfolge darstellt.
Verwenden Sie die Modellierung der neuronalen Netzwerkarchitektursuche, um gemeinsam den Effekt und die Vorhersageleistung des groben Ranking-Modells zu optimieren, Offline-Recall@150 +11PP und schließlich, ohne die Online-Verzögerung zu erhöhen, den Online-Indikator CTR + 0,12 %; detaillierte Arbeiten finden sich in [13], das von KDD 2022 angenommen wurde. 4. Zusammenfassung Ab 2020 haben wir das MLP-Modell für die grobe Ranking-Ebene durch eine Vielzahl technischer Leistungsoptimierungen implementiert. Im Jahr 2021 werden wir das grobe Ranking-Modell auf Basis des MLP weiter iterieren Modell zur Verbesserung des groben Ranking-Effekts. Zunächst haben wir auf das in der Branche übliche Destillationsschema zurückgegriffen, um das Feinranking zu verknüpfen und das Grobranking zu optimieren. Wir haben eine große Anzahl von Experimenten auf drei Ebenen durchgeführt: Destillation des Feinranking-Ergebnisses, Destillation des Feinranking-Vorhersage-Scores, und Feature-Darstellungsdestillation, ohne die Anzahl der Online-Verzögerungen zu erhöhen, wird der Effekt des groben Layoutmodells verbessert. Zweitens haben wir angesichts der Tatsache, dass herkömmliche Destillationsmethoden merkmalsstrukturierte Informationen in Sortierszenarien nicht gut verarbeiten können, ein selbst entwickeltes Schema zur Übertragung von Feinsortierungsinformationen auf Grobsortierung basierend auf kontrastivem Lernen entwickelt.
Abschließend haben wir darüber nachgedacht, dass die grobe Optimierung im Wesentlichen ein Kompromiss zwischen Effekt und Leistung ist. Wir haben die Idee der Multi-Ziel-Modellierung übernommen, um Effekt und Leistung gleichzeitig zu optimieren, und eine automatische Suchtechnologie für die Architektur neuronaler Netzwerke implementiert um das Problem zu lösen und das Modell automatisch Feature-Sets und Modellstrukturen mit der besten Effizienz und Effektivität auswählen zu lassen. In Zukunft werden wir die Rauschichttechnologie unter folgenden Gesichtspunkten weiterentwickeln:
- Mehrobjektive Modellierung der Grobsortierung: Die aktuelle Grobsortierung ist im Wesentlichen ein Einobjektivmodell. Wir versuchen derzeit, die Mehrobjektivmodellierung der Feinsortierungsschicht auf die Grobsortierung anzuwenden.
- Systemweite dynamische Rechenleistungszuweisung in Verbindung mit der Grobsortierung: Die Grobsortierung kann die Rechenleistung des Abrufs und die Rechenleistung der Feinsortierung steuern. Für verschiedene Szenarien ist die vom Modell benötigte Rechenleistung unterschiedlich Die dynamische Rechenleistungszuteilung kann den Rechenleistungsverbrauch des Systems reduzieren, ohne die Online-Effekte zu verringern. Derzeit haben wir in diesem Aspekt bestimmte Online-Effekte erzielt.
Traditionelle Offline-Sortierungsindikatoren basieren hauptsächlich auf NDCG-, MAP- und AUC-Indikatoren. Bei der groben Sortierung geht es eher um Rückrufaufgaben, die auf die Auswahl von Sätzen abzielen, sodass der herkömmliche Sortierindex nicht förderlich ist zur Messung des Iterationseffekts des groben Sortiermodells. Wir beziehen uns auf den Recall-Indikator in [6] als Maß für den Offline-Effekt der Grobsortierung, d. Die spezifische Definition des Recall-Indikators lautet wie folgt:
Die physikalische Bedeutung dieser Formel besteht darin, die Überlappung zwischen den Top-K-Elementen bei der Grobsortierung und den Top-K-Elementen bei der Feinsortierung zu messen die Essenz der groben Sortiersatzauswahl.
6. Vorstellung des AutorsXiao Jiang, Suo Gui, Li Xiang, Cao Yue, Pei Hao, Xiao Yao, Dayao, Chen Sheng, Yun Sen, Li Qian usw., alle von der Meituan-Plattform/Suchempfehlungsalgorithmus Abteilung .



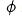
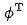
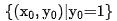
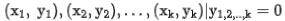
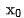

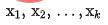
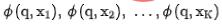
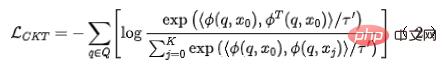


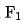
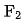
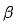
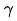

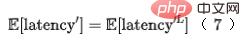 Verwenden Sie die Modellierung der neuronalen Netzwerkarchitektursuche, um gemeinsam den Effekt und die Vorhersageleistung des groben Ranking-Modells zu optimieren, Offline-Recall@150 +11PP und schließlich, ohne die Online-Verzögerung zu erhöhen, den Online-Indikator CTR + 0,12 %; detaillierte Arbeiten finden sich in [13], das von KDD 2022 angenommen wurde.
Verwenden Sie die Modellierung der neuronalen Netzwerkarchitektursuche, um gemeinsam den Effekt und die Vorhersageleistung des groben Ranking-Modells zu optimieren, Offline-Recall@150 +11PP und schließlich, ohne die Online-Verzögerung zu erhöhen, den Online-Indikator CTR + 0,12 %; detaillierte Arbeiten finden sich in [13], das von KDD 2022 angenommen wurde.  4. Zusammenfassung
4. Zusammenfassung 
 Ab 2020 haben wir das MLP-Modell für die grobe Ranking-Ebene durch eine Vielzahl technischer Leistungsoptimierungen implementiert. Im Jahr 2021 werden wir das grobe Ranking-Modell auf Basis des MLP weiter iterieren Modell zur Verbesserung des groben Ranking-Effekts.
Ab 2020 haben wir das MLP-Modell für die grobe Ranking-Ebene durch eine Vielzahl technischer Leistungsoptimierungen implementiert. Im Jahr 2021 werden wir das grobe Ranking-Modell auf Basis des MLP weiter iterieren Modell zur Verbesserung des groben Ranking-Effekts. 
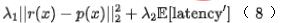
Das obige ist der detaillierte Inhalt vonErforschung und Praxis der groben Ranking-Optimierung der Meituan-Suche. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr