
Heim >Technologie-Peripheriegeräte >KI >Wie Deep-Learning-Technologie das Problem löst, dass Roboter mit verformbaren Objekten umgehen
Wie Deep-Learning-Technologie das Problem löst, dass Roboter mit verformbaren Objekten umgehen

- 王林nach vorne
- 2023-04-12 09:25:05920Durchsuche
Übersetzer |. Li Rui
Rezensent |. Für Menschen ist die Verarbeitung verformbarer Objekte nicht viel schwieriger als die Verarbeitung starrer Objekte. Menschen lernen von Natur aus, sie zu formen, zu falten und auf unterschiedliche Weise zu manipulieren und sind dennoch in der Lage, sie zu erkennen.
 Aber für Robotik und Systeme der künstlichen Intelligenz ist die Manipulation verformbarer Objekte eine große Herausforderung. Beispielsweise muss ein Roboter eine Reihe von Schritten ausführen, um Teig zu einem Pizzaboden zu formen. Wenn der Teig seine Form ändert, muss er aufgezeichnet und verfolgt werden. Gleichzeitig müssen für jeden Arbeitsschritt die richtigen Werkzeuge ausgewählt werden. Dies sind herausfordernde Aufgaben für aktuelle Systeme der künstlichen Intelligenz, die stabiler sind, wenn sie mit starren Objekten mit vorhersehbareren Zuständen umgehen.
Aber für Robotik und Systeme der künstlichen Intelligenz ist die Manipulation verformbarer Objekte eine große Herausforderung. Beispielsweise muss ein Roboter eine Reihe von Schritten ausführen, um Teig zu einem Pizzaboden zu formen. Wenn der Teig seine Form ändert, muss er aufgezeichnet und verfolgt werden. Gleichzeitig müssen für jeden Arbeitsschritt die richtigen Werkzeuge ausgewählt werden. Dies sind herausfordernde Aufgaben für aktuelle Systeme der künstlichen Intelligenz, die stabiler sind, wenn sie mit starren Objekten mit vorhersehbareren Zuständen umgehen.
Jetzt verspricht eine neue Deep-Learning-Technik, die von Forschern des MIT, der Carnegie Mellon University und der UC San Diego entwickelt wurde, Robotersysteme beim Umgang mit verformbaren Objekten stabiler zu machen. Die Technologie namens DiffSkill nutzt tiefe neuronale Netze zum Erlernen einfacher Fertigkeiten und ein Planungsmodul, um diese Fertigkeiten zu kombinieren, um Aufgaben zu lösen, die mehrere Schritte und Werkzeuge erfordern.
Verarbeitung verformbarer Objekte durch Reinforcement Learning und Deep Learning
Wenn ein System der künstlichen Intelligenz ein Objekt verarbeiten möchte, muss es in der Lage sein, seinen Zustand zu erkennen, zu definieren und vorherzusagen, wie es in der Zukunft aussehen wird. Für starre Objekte ist dies ein weitgehend gelöstes Problem. Mit einer guten Reihe von Trainingsbeispielen kann ein tiefes neuronales Netzwerk starre Objekte aus verschiedenen Winkeln erkennen. Wenn verformbare Objekte beteiligt sind, werden ihre multiplen Zustandsräume noch komplexer.
Lin Zahlen repräsentieren seine Richtung.
Verformbare Objekte wie Teig oder Stoff haben jedoch unendlich viele Freiheitsgrade, was es schwieriger macht, ihren Zustand genau zu beschreiben, und die Art und Weise, wie sie sich verformen, ist auch schwieriger zu verwenden als starre Objekte
Die Entwicklung differenzierbarer Physiksimulatoren ermöglicht die Anwendung von Gradienten-basierten Methoden zur Lösung deformierbarer Objektmanipulationsaufgaben. Dies unterscheidet sich von herkömmlichen Methoden des verstärkenden Lernens, die versuchen, die Dynamik der Umgebung und der Objekte durch reine Versuch-und-Irrtum-Interaktionen zu lernen.
DiffSkill ist von PlasticineLab inspiriert, einem differenzierbaren Physiksimulator und wurde auf der ICLR-Konferenz 2021 vorgestellt. PlasticineLab zeigt, dass differenzierbare Simulatoren bei kurzfristigen Aufgaben helfen können.
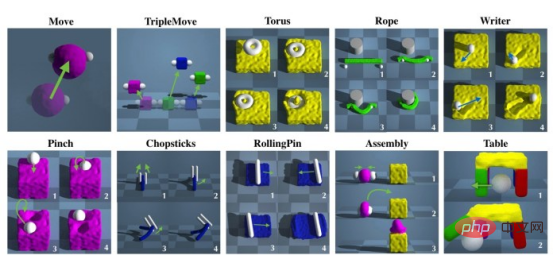 PlasticineLab ist ein Simulator für verformbare Objekte, der auf differenzierbarer Physik basiert. Es eignet sich gut zum Trainieren von auf Gradienten basierenden Modellen
PlasticineLab ist ein Simulator für verformbare Objekte, der auf differenzierbarer Physik basiert. Es eignet sich gut zum Trainieren von auf Gradienten basierenden Modellen
, aber differenzierbare Simulatoren haben immer noch mit dem langfristigen Problem zu kämpfen, dass mehrere Schritte erforderlich sind und unterschiedliche Werkzeuge verwendet werden. Systeme der künstlichen Intelligenz, die auf differenzierbaren Simulatoren basieren, erfordern außerdem Kenntnisse über den vollständigen Simulationszustand und die damit verbundenen physikalischen Parameter der Umgebung. Dies ist besonders einschränkend für reale Anwendungen, bei denen Agenten die Welt typischerweise durch visuelle und Tiefenerfassungsdaten (RGB-D) wahrnehmen.
Lin Dabei lernen Agenten der künstlichen Intelligenz mithilfe differenzierbarer physikalischer Modelle Fertigkeitsabstraktionen und kombinieren diese, um komplexe operative Aufgaben zu erledigen.
Seine bisherige Arbeit konzentrierte sich auf die Nutzung von Verstärkungslernen zur Manipulation verformbarer Objekte wie Stoffe, Seile und Flüssigkeiten. Für DiffSkill entschied er sich wegen der damit verbundenen Herausforderungen für die Teigmanipulation.
Er sagte: „Teigmanipulation ist besonders interessant, weil sie mit einem Robotergreifer nicht einfach zu bewerkstelligen ist, sondern die Verwendung verschiedener Werkzeuge nacheinander erfordert, was Menschen gut können, Roboter jedoch weniger verbreitet sind.“
Nach dem Training DiffSkill Eine Reihe von Teigmanipulationsaufgaben können nur mit RGB-D-Eingabe erfolgreich abgeschlossen werden.
Verwendung neuronaler Netze zum Erlernen abstrakter Fähigkeiten
DiffSkill trainiert die Machbarkeit neuronaler Netze, um Zielzustände aus Anfangszuständen und Parametern vorherzusagen, die aus differenzierbaren Physiksimulatoren erhalten wurden.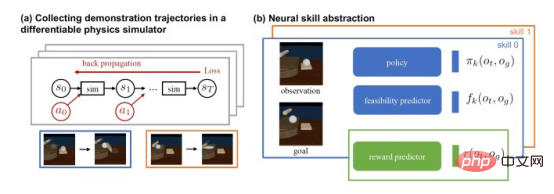 DiffSkill besteht aus zwei Schlüsselkomponenten: Die erste besteht darin, neuronale Netze zu verwenden Ein „Abstraktor für neuronale Fähigkeiten“ zum Erlernen individueller Fähigkeiten und ein weiterer „Planer“ zur Lösung langfristiger Aufgaben.
DiffSkill besteht aus zwei Schlüsselkomponenten: Die erste besteht darin, neuronale Netze zu verwenden Ein „Abstraktor für neuronale Fähigkeiten“ zum Erlernen individueller Fähigkeiten und ein weiterer „Planer“ zur Lösung langfristiger Aufgaben.
DiffSkill verwendet einen differenzierbaren Physiksimulator, um Trainingsbeispiele für Fertigkeitsabstraktoren zu generieren. Diese Beispiele zeigen, wie Sie mit einem einzigen Werkzeug kurzfristige Ziele erreichen können, beispielsweise mit einem Nudelholz zum Ausbreiten von Teig oder mit einem Spatel zum Bewegen von Teig.
Diese Beispiele werden erfahrenen Abstraktoren in Form von RGB-D-Videos präsentiert. Anhand einer Bildbeobachtung muss der Fähigkeitsabstraktor vorhersagen, ob das gewünschte Ziel realisierbar ist. Das Modell lernt und passt seine Parameter an, indem es seine Vorhersagen mit tatsächlichen Ergebnissen eines Physiksimulators vergleicht.
Robotermanipulation verformbarer Objekte wie Teig erfordert langfristige Überlegungen zum Einsatz verschiedener Werkzeuge. Der DiffSkill-Ansatz nutzt differenzierbare Simulatoren, um Fähigkeiten für diese anspruchsvollen Aufgaben zu erlernen und zu kombinieren.
Unterdessen trainiert DiffSkill Variational Autoencoder (VAEs), um latente Raumdarstellungen von Beispielen zu lernen, die von Physiksimulatoren generiert wurden. Variationale Autoencoder (VAE) behalten wichtige Funktionen bei und verwerfen aufgabenirrelevante Informationen. Durch die Umwandlung von hochdimensionalem Bildraum in latenten Raum spielen Variations-Autoencoder (VAEs) eine wichtige Rolle dabei, DiffSkill in die Lage zu versetzen, über längere Sichtfelder zu planen und Ergebnisse aus der Beobachtung sensorischer Daten vorherzusagen.
Eine der wichtigsten Herausforderungen beim Training eines Variational Autoencoders (VAE) besteht darin, sicherzustellen, dass er die richtigen Funktionen lernt und auf die reale Welt verallgemeinert. In der realen Welt unterscheidet sich die Zusammensetzung visueller Daten von den Daten, die von einem physischen Simulator generiert werden. Beispielsweise ist die Farbe des Nudelholzes oder des Schneidebretts für die Aufgabe nicht relevant, wohl aber die Position und der Winkel des Nudelholzes sowie die Position des Teigs.
Derzeit verwenden die Forscher eine Technik namens „Domänen-Randomisierung“, die irrelevante Eigenschaften der Trainingsumgebung, wie Hintergrund und Beleuchtung, randomisiert und wichtige Merkmale wie die Position und Ausrichtung des Werkzeugs beibehält. Dies macht das Training von Variational Autoencodern (VAEs) stabiler, wenn es in der realen Welt angewendet wird.
Lin Xingyu sagte: „Das ist nicht einfach, weil wir alle möglichen Unterschiede zwischen Simulation und realer Welt abdecken müssen (sogenannte sim2real-Lücke). Einfacherer Transfer von der Simulation in die reale Welt. Tatsächlich entwickeln wir ein Folgeprojekt, bei dem Punktwolken als Eingabe verwendet werden Verschiedene Fertigkeitskombinationen und -sequenzen erreicht.
Sobald der Fertigkeitsabstraktor trainiert ist, nutzt DiffSkill das Planermodul, um langfristige Aufgaben zu lösen. Planer müssen die Anzahl und Reihenfolge der erforderlichen Fähigkeiten bestimmen, um vom Ausgangszustand zum Ziel zu gelangen.
Dieser Planer durchläuft mögliche Fähigkeitskombinationen und die Zwischenergebnisse, die sie erzeugen. Hier erweisen sich Variations-Autoencoder als nützlich. Anstatt vollständige Bildergebnisse vorherzusagen, nutzt DiffSkill VAEs, um latente räumliche Ergebnisse für Zwischenschritte zum Endziel vorherzusagen. 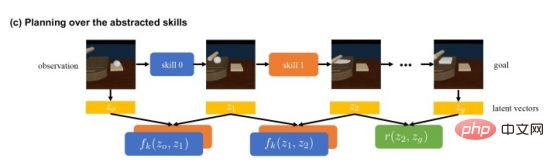
Der Planer von DiffSkill sagt Zwischenschritte sehr genau voraus
Lin in verschiedenen zeitlichen Abstraktionen, anstatt darüber nachzudenken, was in der nächsten Sekunde zu tun ist.“
Allerdings ist auch die Kapazität von DiffSkill begrenzt. Beispielsweise sank die Leistung von DiffSkill erheblich, wenn eine der Aufgaben ausgeführt wurde, die eine dreistufige Planung erforderten (obwohl es andere Techniken immer noch übertraf). Lin Xingyu erwähnte auch, dass der Machbarkeitsprädiktor in einigen Fällen zu falsch positiven Ergebnissen führen kann. Die Forscher glauben, dass das Erlernen besserer latenter Räume zur Lösung dieses Problems beitragen kann.
Die Forscher erkunden auch andere Wege, um DiffSkill zu verbessern, einschließlich eines effizienteren Planungsalgorithmus, der für längere Aufgaben verwendet werden kann.
Lin Xingyu äußerte die Hoffnung, dass er DiffSkill eines Tages auf einem echten Pizza-Roboter einsetzen kann. Er sagte: „Davon sind wir noch weit entfernt. Es sind verschiedene Herausforderungen in Bezug auf Kontrolle, Sim2real-Übertragung und Sicherheit entstanden. Aber wir sind jetzt zuversichtlicher, einige langfristige Missionen zu starten.“ #🎜 🎜# Originaltitel:
Diese Deep-Learning-Technik löst eine der schwierigsten Herausforderungen der Robotik, Autor: Ben Dickson
Das obige ist der detaillierte Inhalt vonWie Deep-Learning-Technologie das Problem löst, dass Roboter mit verformbaren Objekten umgehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr