
Heim >Technologie-Peripheriegeräte >KI >Die Geheimwaffe zur Verbesserung der Vorhersagequalität von Deep-Learning-Modellen – kontextsensitive Daten
Die Geheimwaffe zur Verbesserung der Vorhersagequalität von Deep-Learning-Modellen – kontextsensitive Daten

- PHPznach vorne
- 2023-04-11 23:28:011080Durchsuche
Übersetzer |. Zhu Xianzhong
Rezensent |. In diesem Artikel möchte ich Ihnen meine Methode zur Optimierung der Eingabedaten des Deep-Learning-Modells vorstellen. Als Datenwissenschaftler und Dateningenieur habe ich diese Technik erfolgreich auf meine eigene Arbeit angewendet. Anhand einiger konkreter Entwicklungsfälle aus der Praxis erfahren Sie, wie Sie Kontextinformationen nutzen können, um Modelleingabedaten anzureichern. Dies wird Ihnen helfen, robustere und genauere Deep-Learning-Modelle zu entwerfen.

Wenn Sie einen neuen prädiktiven Deep-Learning-Algorithmus entwickeln, können Sie eine Modellarchitektur wählen, die perfekt für Ihren spezifischen Anwendungsfall geeignet ist. Abhängig von den Eingabedaten und der tatsächlichen Vorhersageaufgabe haben Sie möglicherweise an viele Methoden gedacht: Wenn Sie Bilder klassifizieren möchten, wählen Sie wahrscheinlich ein Faltungs-Neuronales Netzwerk, wenn Sie Zeitreihen vorhersagen oder Text analysieren, dann ein LSTM-Netzwerk Könnte eine vielversprechende Option sein. Entscheidungen über die richtige Modellarchitektur werden häufig weitgehend von der Art der in das Modell einfließenden Daten bestimmt.
Daher ist das Finden der richtigen Eingabedatenstruktur (d. h. das Definieren der Eingabeebene des Modells) zu einem der wichtigsten Schritte beim Modelldesign geworden. Normalerweise verbringe ich mehr Entwicklungszeit mit der Gestaltung der Eingabedaten als mit allem anderen. Um es klar auszudrücken: Wir müssen uns nicht mit einer bestimmten Rohdatenstruktur befassen, sondern müssen nur ein geeignetes Modell finden. Die Fähigkeit neuronaler Netze, Feature-Engineering und Feature-Auswahl intern zu übernehmen („End-to-End-Modellierung“), befreit uns nicht davon, die Struktur der Eingabedaten zu optimieren. Wir sollten Daten so bereitstellen, dass Modelle den größtmöglichen Sinn daraus ziehen und die fundiertesten Entscheidungen (d. h. die genauesten Vorhersagen) treffen können. Der „geheime“ Faktor sind hier Kontextinformationen. Das heißt, wir sollten die Rohdaten mit möglichst viel Kontext anreichern.
Was ist Kontext?
Was meine ich also konkret mit „Kontext“ oben? Lassen Sie uns Ihnen ein Beispiel geben. Mary ist eine Datenwissenschaftlerin, die eine neue Stelle antritt und ein Umsatzprognosesystem für ein Getränkeeinzelhandelsunternehmen entwickelt. Kurz gesagt, ihre Aufgabe besteht darin, bei einem bestimmten Geschäft und einem bestimmten Produkt (Limonade, Orangensaft, Bier ...) ihr Modell in der Lage zu sein, die zukünftigen Verkäufe dieses Produkts in dem bestimmten Geschäft vorherzusagen. Vorhersagen werden auf Tausende verschiedener Produkte angewendet, die von Hunderten verschiedener Geschäfte angeboten werden. Bisher hat das System einwandfrei funktioniert. Marys ersten Tag verbrachte sie in der Vertriebsabteilung, wo die Prognosearbeit bereits erledigt wurde, wenn auch manuell von Peters, einem erfahrenen Vertriebsbuchhalter. Ihr Ziel ist es zu verstehen, auf welcher Grundlage der Domänenexperte die zukünftige Nachfrage nach einem bestimmten Produkt bestimmt. Als gute Datenwissenschaftlerin ging Mary davon aus, dass Peters‘ jahrelange Erfahrung bei der Definition, welche Daten für das Modell möglicherweise wertvoller sind, sehr hilfreich sein würde. Um das herauszufinden, stellte Mary Peters zwei Fragen.
Erste Frage: „Welche Daten haben Sie analysiert, um zu berechnen, wie viele Flaschen einer bestimmten Limonadenmarke wir nächsten Monat in unseren Filialen in Berlin verkaufen werden?
Peters antwortete: „Im Laufe der Zeit haben wir unternahm die ersten Schritte im Limonadenverkauf in Berlin.“ Anschließend zeichnete er die folgende Grafik, um seine Strategie zu veranschaulichen:
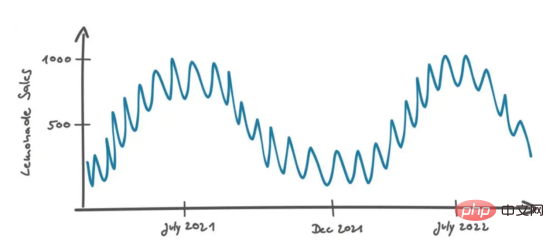
Peters fuhr fort: „Wenn ich das sich wiederholende Muster von steigenden Umsätzen im Sommer und sinkenden Umsätzen im Winter sehe, halte ich es für sehr wahrscheinlich, dass dies auch in Zukunft passieren wird, also schätze ich die Umsätze auf der Grundlage dieser Möglichkeit.“ Das klingt vernünftig.
Peters interpretiert Verkaufsdaten in einem zeitlichen Kontext, wobei der Abstand zweier Datenpunkte durch ihren Zeitunterschied definiert wird. Wenn die Daten nicht in chronologischer Reihenfolge vorliegen, sind sie schwer zu interpretieren. Wenn wir beispielsweise nur die Umsatzverteilung in einem Histogramm betrachten würden, würde der zeitliche Kontext verloren gehen und unsere beste Schätzung zukünftiger Umsätze wäre ein Gesamtwert, etwa der Median aller Werte.
Kontext erscheint, wenn Daten auf eine bestimmte Weise sortiert sind.
Es versteht sich von selbst, dass Sie Ihr Verkaufsprognosemodell mit historischen Verkaufsdaten in der richtigen chronologischen Reihenfolge füttern sollten, um „freien“ Kontext aus der Datenbank zu sparen. Deep-Learning-Modelle sind sehr leistungsfähig, weil sie Kontextinformationen sehr gut integrieren können, ähnlich wie unser Gehirn (in diesem Fall natürlich das Gehirn von Peters).
Haben Sie sich jemals gefragt: Warum Deep Learning für die Bildklassifizierung und Bildobjekterkennung so effektiv ist? Weil in gewöhnlichen Bildern bereits viel „natürlicher“ Kontext vorhanden ist: Bilder sind im Wesentlichen Datenpunkte der Lichtintensität, die nach zwei Hintergrunddimensionen angeordnet sind, nämlich dem räumlichen Abstand in x-Richtung und dem räumlichen Abstand in y-Richtung. Und Film als animierte Form (eine zeitliche Abfolge von Bildern) fügt Zeit als dritte kontextuelle Dimension hinzu.
Da der Kontext für die Vorhersage so vorteilhaft ist, können wir die Modellleistung verbessern, indem wir weitere Kontextdimensionen hinzufügen – auch wenn diese Dimensionen bereits in den Originaldaten enthalten sind. Dies haben wir durch einige clevere Data-Engineering-Methoden erreicht, wie im Folgenden beschrieben.
Wir sollten Daten so bereitstellen, dass Modelle die beste Bedeutung daraus ableiten und fundierte Entscheidungen treffen können. Normalerweise verbringe ich mehr Entwicklungszeit mit der Gestaltung der Eingabedaten als mit allem anderen.
Kontextreiche Daten entwerfen
Kehren wir zur Diskussion von Mary und Peters zurück. Mary wusste, dass die tatsächlichen Daten in den meisten Fällen nicht so gut aussahen wie in der Tabelle oben, also änderte sie die Tabelle leicht, sodass sie so aussieht:
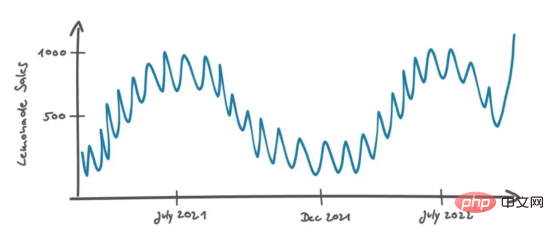
Die zweite Frage, die Mary stellte, war: „Was wäre, wenn …“ Der letzte Verkaufsdatenpunkt liegt über dem üblichen Lärmpegel. Vielleicht hat das Produkt eine erfolgreiche Marketingkampagne durchgeführt und schmeckt jetzt besser und zukünftige Verkäufe werden auf dem gleichen hohen Niveau bleiben, oder es ist einfach eine Anomalie aufgrund zufälliger Ereignisse. Beispielsweise kommt eine Schulklasse in Berlin in den Laden und kauft eine Flasche dieser Limonade In diesem Fall ist das Umsatzwachstum nicht stabil und kann nur als Rauschdaten betrachtet werden. Wie entscheiden Sie in diesem Fall, ob es sich um einen echten Verkaufseffekt handelt? „In diesem Fall schaue ich mir Umsätze in Filialen an, die Berlin ähneln. Zum Beispiel unsere Filialen in Hamburg und München. Die Filialen sind vergleichbar, weil sie sich auch in deutschen Großstädten befinden. Eine Filiale in einer deutschen Stadt würde ich nicht in Betracht ziehen.“ Im ländlichen Raum würde ich unterschiedliche Kunden mit unterschiedlichen Geschmäckern und Vorlieben erwarten.“
Er addierte die Umsatzkurven anderer Geschäfte mit zwei möglichen Szenarien. „Wenn ich eine Umsatzsteigerung in Berlin sehe, halte ich es für Lärm. Aber wenn ich eine Steigerung der Limonadenverkäufe in Hamburg und München sehe, erwarte ich, dass es einen stetigen Effekt gibt.“ In einigen eher schwierigen Situationen zieht Peters mehr Daten in Betracht, um fundiertere Entscheidungen zu treffen. Er fügt eine neue Dimension von Daten im Kontext verschiedener Geschäfte hinzu. Wie oben erwähnt, entsteht Kontext, wenn Daten auf eine bestimmte Weise geordnet sind. Um einen Filialkontext zu erstellen, müssen wir zunächst ein Distanzmaß definieren, um entsprechend Daten aus verschiedenen Filialen zu bestellen. Peters unterscheidet beispielsweise Geschäfte nach der Größe der Stadt, in der sie sich befinden.
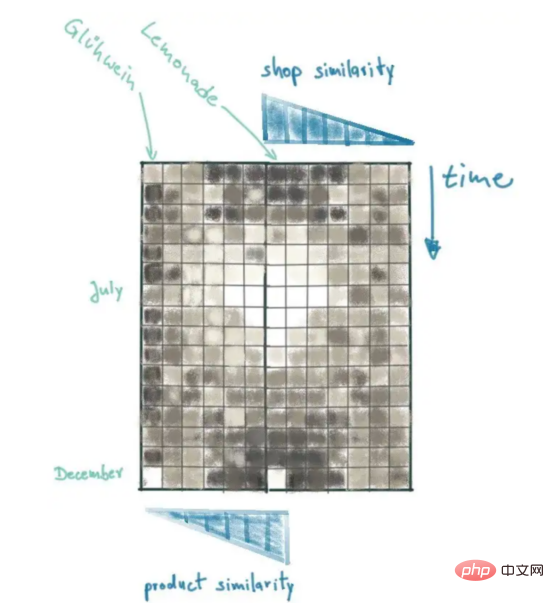
Durch die Anwendung einiger SQL- und Numpy-Programmierkenntnisse können wir einen ähnlichen Kontext für unsere Modelle bereitstellen. Zuerst müssen wir die Bevölkerungszahl der Stadt verstehen, in der sich die Filialen unseres Unternehmens befinden. Anschließend messen wir die Entfernung zwischen allen Filialen anhand der Bevölkerungsunterschiede. Schließlich kombinieren wir alle Verkaufsdaten in einer 2D-Matrix Zeit, die zweite Dimension, ist unsere Messgröße für die Filialentfernung.
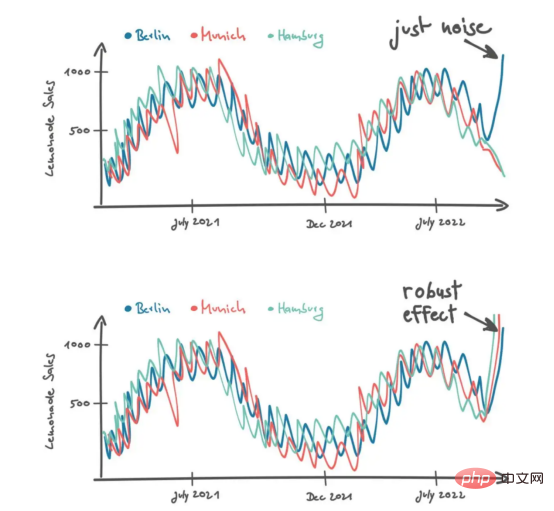
Die Verkaufsmatrix in der Abbildung bietet einen guten Überblick über die letzten Limonadenverkäufe und die daraus resultierenden Muster können visuell erklärt werden. Werfen Sie einen Blick auf den Datenpunkt in der unteren linken Ecke der Umsatzmatrix: Dies sind die aktuellsten Umsatzdaten für Berlin. Beachten Sie, dass dieser Lichtblick wahrscheinlich eine Ausnahme darstellt, da ähnliche Geschäfte (z. B. Burger) den starken Umsatzanstieg nicht wiederholen werden. Im Gegensatz dazu wurde der Umsatzhöchststand im Juli von ähnlichen Geschäften reproduziert.
Wir müssen also immer eine Distanzmetrik hinzufügen, um Kontext zu schaffen.
Jetzt übersetzen wir Peters Aussage in mathematische Begriffe, die auf der Grundlage der Bevölkerungszahl der Stadt, in der sich das Produkt befindet, modelliert werden können. Beim Hinzufügen neuer Kontextdimensionen müssen wir die richtige Distanzmetrik sehr sorgfältig berücksichtigen. Es hängt davon ab, welche Faktoren die Entität beeinflussen, die wir vorhersagen möchten. Die Einflussfaktoren hängen ganz vom Produkt ab und die Abstandsanzeige muss entsprechend angepasst werden. Wenn Sie sich beispielsweise den Bierverkauf in Deutschland ansehen, werden Sie feststellen, dass Verbraucher wahrscheinlich Produkte von lokalen Brauereien kaufen (im ganzen Land gibt es etwa 1.300 verschiedene Brauereien).
Menschen aus Köln trinken normalerweise Kursch, aber wenn man eine halbe Stunde nach Norden in die Region Düsseldorf fährt, meiden die Leute Kursch und bevorzugen das dunklere, malzigere Al Special-Bier. Daher könnte es im Falle des deutschen Bierabsatzes eine sinnvolle Wahl sein, die Filialentfernung anhand der geografischen Entfernung zu modellieren. Für andere Produktkategorien (Limonade, Orangensaft, Sportgetränke…) ist dies jedoch nicht der Fall.
Da wir eine zusätzliche Kontextdimension hinzugefügt haben, haben wir einen kontextreichen Datensatz erstellt, mit dem potenzielle Vorhersagemodelle Limonadenverkaufsprofile zu unterschiedlichen Zeiten und in verschiedenen Geschäften erhalten können. Dies ermöglicht es dem Modell, fundierte Entscheidungen über zukünftige Verkäufe in der Berliner Filiale zu treffen, indem es sich die aktuelle Verkaufshistorie ansieht und nach links und rechts ähnliche Filialen an anderen Standorten betrachtet.
Von hier aus können wir den Produkttyp als zusätzliche kontextbezogene Dimension hinzufügen. Daher reichern wir die Verkaufsmatrix mit Daten anderer Produkte an, sortiert nach ihrer Ähnlichkeit mit Limonade (unser Prognoseziel). Auch hier müssen wir eine gute Ähnlichkeitsmetrik finden. Ist Cola eher Limonade als Orangensaft? Auf der Grundlage welcher Daten können wir Ähnlichkeitsrankings definieren?
Bei Geschäften haben wir ein kontinuierliches Maß, nämlich die Einwohnerzahl der Stadt. Jetzt beschäftigen wir uns mit Produktkategorien. Was wir wirklich wollen, sind Produkte, die ein ähnliches Verkaufsverhalten wie Limonade haben. Im Gegensatz zu Limonade können wir für alle Produkte eine Kreuzkorrelationsanalyse zeitaufgelöster Verkaufsdaten durchführen. Auf diese Weise erhalten wir für jedes Produkt einen Pearson-Korrelationskoeffizienten, der uns sagt, wie ähnlich die Verkaufsmuster sind. Erfrischungsgetränke wie Cola weisen möglicherweise ähnliche Verkaufsmuster wie Limonade auf, wobei die Verkäufe im Sommer steigen. Andere Produkte verhalten sich völlig anders. Beispielsweise kann Gühwein, ein warmer, süßer Wein, der auf Weihnachtsmärkten serviert wird, im Dezember einen starken Verkaufspeak haben und dann im Rest des Jahres kaum verkauft werden.
【Anmerkung des Übersetzers】Zeitaufgelöst: Der Name der Physik oder Statistik. Andere häufig verwendete Wörter im Zusammenhang damit sind zeitaufgelöste Diagnose, zeitaufgelöstes Spektrum usw.
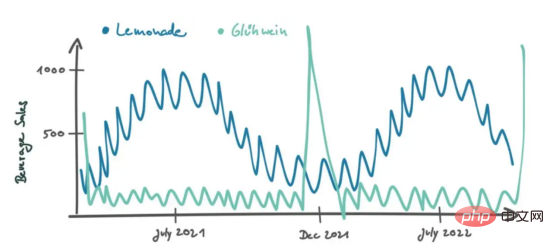
Eine Kreuzkorrelationsanalyse zeigt, dass Glühwein einen niedrigeren Pearson-Koeffizienten (eigentlich negativ) hat, während Cola einen höheren Pearson-Koeffizienten hat.
Obwohl wir der Verkaufsmatrix eine dritte Dimension hinzufügen, können wir den Produktkontext einbeziehen, indem wir die zweite Dimension in die entgegengesetzte Richtung hinzufügen. Damit stehen die wichtigsten Verkaufsdaten (Berliner Limonadenverkäufe) im Mittelpunkt:
Weitere Features hinzufügen
Während wir jetzt über eine sehr informative Datenstruktur verfügen, haben wir bisher nur ein Feature: die Anzahl der Produkte, die für ein bestimmtes Produkt in einem bestimmten Geschäft zu einem bestimmten Zeitpunkt verkauft werden. Dies reicht möglicherweise bereits aus, um robuste und genaue Vorhersagen zu treffen, wir können jedoch auch zusätzliche nützliche Informationen aus anderen Datenquellen hinzufügen.
Zum Beispiel dürfte das Kaufverhalten von Getränken vom Wetter abhängig sein. Beispielsweise kann in sehr heißen Sommern die Nachfrage nach Limonade steigen. Als zweite Schicht der Matrix können wir Wetterdaten (z. B. Lufttemperatur) bereitstellen. Wetterdaten werden im gleichen Kontext (Ladenstandort und Produkt) wie Verkaufsdaten geordnet. Für verschiedene Produkte erhalten wir die gleichen Lufttemperaturdaten. Bei unterschiedlichen Zeiten und Geschäftsstandorten werden wir jedoch feststellen, dass es Unterschiede gibt, die nützliche Informationen für die Daten liefern können.

Auf diese Weise verfügen wir über eine dreidimensionale Matrix, die außerdem Verkaufs- und Temperaturdaten enthält. Beachten Sie, dass wir durch die Einbeziehung von Temperaturdaten keine zusätzliche Kontextdimension hinzugefügt haben. Wie ich bereits erwähnt habe, kommt der Kontext ins Spiel, wenn Daten auf eine bestimmte Weise sortiert werden. Für den von uns erstellten Datenkontext haben wir die Daten nach Zeit, Produktähnlichkeit und Filialähnlichkeit sortiert. Die Reihenfolge der Merkmale (in unserem Fall entlang der dritten Dimension der Matrix) ist jedoch irrelevant. Tatsächlich entspricht unsere Datenstruktur einem RGB-Farbbild. In einem RGB-Bild haben wir zwei Kontextdimensionen (Raumdimensionen x und y) und drei Farbebenen (Rot, Grün, Blau). Für eine korrekte Interpretation des Bildes ist die Reihenfolge der Farbkanäle beliebig. Sobald Sie es definiert haben, müssen Sie es in Ordnung halten. Aber für Daten, die in einem bestimmten Kontext organisiert sind, gibt es keine Distanzmetrik.
Kurz gesagt: Die Struktur der Eingabedaten kann nicht im Voraus bestimmt werden. Daher ist es an der Zeit, dass wir unserer Kreativität und Intuition freien Lauf lassen, um neue Machbarkeitsindikatoren zu entdecken.
Zusammenfassung
Durch das Hinzufügen von zwei zusätzlichen Kontexten und einer zusätzlichen Feature-Ebene zu den zeitaufgelösten Verkaufsdaten erhalten wir ein zweidimensionales „Bild“ mit zwei „Kanälen“ (Umsatz und Temperatur). Diese Datenstruktur bietet einen umfassenden Überblick über die jüngsten Limonadenverkäufe in einem bestimmten Geschäft sowie Verkaufs- und Wetterinformationen von ähnlichen Geschäften und ähnlichen Produkten. Die bisher von uns erstellten Datenstrukturen eignen sich gut für die Interpretation durch tiefe neuronale Netze – beispielsweise mit mehreren Faltungsschichten und LSTM-Einheiten. Aus Platzgründen werde ich jedoch nicht darauf eingehen, wie man auf dieser Grundlage mit dem Entwurf eines geeigneten neuronalen Netzwerks beginnen kann. Dies könnte das Thema meines Folgeartikels sein.
Ich möchte, dass Sie Ihre eigenen Ideen haben können, und auch wenn die Struktur Ihrer Eingabedaten möglicherweise nicht vorbestimmt ist, können (sollten) Sie Ihre ganze Kreativität und Intuition nutzen, um sie zu erweitern.
Im Allgemeinen gibt es kontextreiche Datenstrukturen nicht umsonst. Um verschiedene Produkte in allen Filialen des Unternehmens vorherzusagen, müssen wir Tausende kontextbezogener Verkaufsprofilinformationen generieren (eine Matrix für den Produktmix jeder Filiale). Sie müssen viel zusätzliche Arbeit investieren, um effektive Verarbeitungs- und Puffermaßnahmen zu entwerfen, um die Daten in die benötigte Form zu bringen und sie für nachfolgende schnelle Trainings- und Vorhersagezyklen neuronaler Netze bereitzustellen. Natürlich erhalten Sie auf diese Weise das gewünschte Deep-Learning-Modell, das genaue Vorhersagen treffen kann und selbst bei verrauschten Daten sehr robust ist, da es scheinbar in der Lage ist, „die Regeln zu brechen“ und sehr kluge Entscheidungen zu treffen.
Einführung in den Übersetzer
Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche.
Originaltitel: Context-Enriched Data: The Secret Superpower for Your Deep Learning Model, Autor: Christoph Möhl
Das obige ist der detaillierte Inhalt vonDie Geheimwaffe zur Verbesserung der Vorhersagequalität von Deep-Learning-Modellen – kontextsensitive Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr