
Heim >Technologie-Peripheriegeräte >KI >Kann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt
Kann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-11 23:04:021347Durchsuche
Wie führt man BERT in einem Faltungs-Neuronalen Netzwerk aus?
Sie können SparK direkt verwenden – Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling, vorgeschlagen vom technischen Team von ByteDance, das kürzlich von der künstlichen Intelligenz anerkannt wurde Als Spotlight-Fokuspapier enthalten:

Papierlink:
https://www.php.c efcdb288dd1
Offener Quellcode:
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f
Dies ist auch der erste Erfolg von BERT auf Convolutional Neural Network (CNN). Lassen Sie uns zunächst die Leistung von SparK im Vortraining erleben.
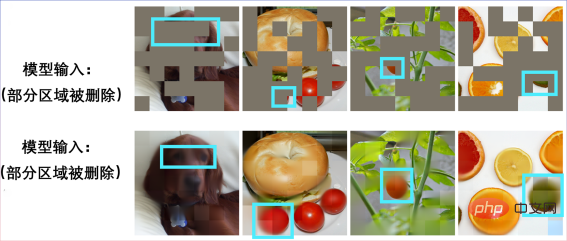
Geben Sie ein unvollständiges Bild ein:

Einen Welpen wiederherstellen:

Noch ein unvollständiges Bild:

Es stellte sich heraus, dass es sich um ein Bagel-Sandwich handelte:

Andere Szenen können auch eine Bildwiederherstellung erreichen:

BERT und Transformer Ein himmlisches Spiel
"Jede großartige Handlung und jeder großartige Gedanke hat einen bescheidenen Anfang."
Hinter dem BERT-Vortrainingsalgorithmus steckt ein einfaches und tiefgreifendes Design. BERT verwendet „Lückentext“: Löschen Sie nach dem Zufallsprinzip mehrere Wörter in einem Satz und lassen Sie das Modell lernen, sich wiederherzustellen.
BERT verlässt sich stark auf das Kernmodell im NLP-Bereich – Transformer.
Transformer eignet sich natürlich für die Verarbeitung von Sequenzdaten variabler Länge (z. B. einen englischen Satz) und kommt daher problemlos mit dem „zufälligen Löschen“ von BERT-Lückentexten zurecht.
CNN im visuellen Bereich möchte auch BERT genießen: Was sind die beiden Herausforderungen?
Rückblickend auf die Geschichte der Computer-Vision-Entwicklung: Das Faltungsmodell für neuronale Netze verdichtet die Essenz vieler klassischer Modelle wie translatorische Äquivarianz, Mehrskalenstruktur usw. und kann als Hauptstütze bezeichnet werden der CV-Welt. Der große Unterschied zu Transformer besteht jedoch darin, dass CNN von Natur aus nicht in der Lage ist, sich an Daten anzupassen, die durch Lückentexte „ausgehöhlt“ und voller „zufälliger Lücken“ sind, sodass es auf den ersten Blick nicht in den Genuss der Vorteile des BERT-Vortrainings kommen kann.
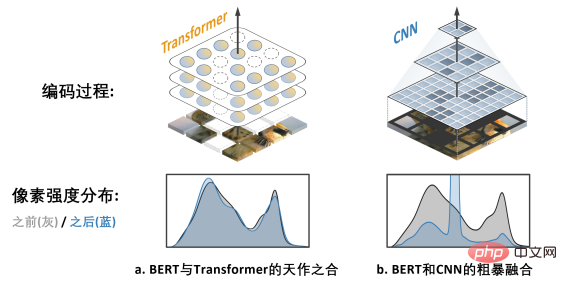
Das obige Bild zeigt die Arbeit von MAE (Masked Autoencoders are Scalable Visual Learners). Da es das Transformer-Modell anstelle des CNN-Modells verwendet, kann es sein flexibel Der Umgang mit Eingaben mit Löchern ist eine „natürliche Ergänzung“ zu BERT.
Das rechte Bild b zeigt eine grobe Möglichkeit, die BERT- und CNN-Modelle zu verschmelzen – das heißt, alle leeren Bereiche zu „schwärzen“ und dieses „schwarze Mosaik“-Bild in CNN einzugeben, das Ergebnis kann man sich vorstellen Dies führt zu einem schwerwiegenden Problem der Verschiebung der Pixelintensitätsverteilung und zu einer sehr schlechten Leistung (später überprüft). Dies ist die
Herausforderung 1, die die erfolgreiche Anwendung von BERT auf CNN behindert. Darüber hinaus wies das Autorenteam auch darauf hin, dass der aus dem NLP-Bereich stammende BERT-Algorithmus natürlich nicht die Eigenschaften von „Multi-Scale“ aufweist und die Multi-Scale-Pyramidenstruktur als beschrieben werden kann der „Goldstandard“ in der langen Geschichte der Computer Vision. Der Konflikt zwischen Single-Scale-BERT und natürlichem Multi-Scale-CNN ist
Herausforderung 2. Lösung SparK: Sparse and Hierarchical Mask Modeling
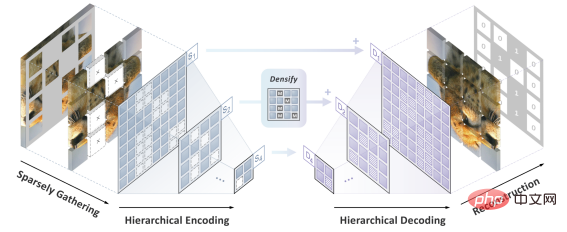
Das Autorenteam schlug SparK (Sparse. and Hierarchische maskierte Modellierung), um die beiden zu lösen bisherige Herausforderungen.
Inspiriert durch die Verarbeitung dreidimensionaler Punktwolkendaten schlug das Autorenteam zunächst vor, die fragmentierten Bilder nach der Maskierungsoperation (Aushöhlungsoperation) als spärliche Punktwolken zu behandeln und eine submanifold spärliche Faltung (Submanifold Sparse) zu verwenden Faltung) zu kodieren. Dadurch kann das Faltungsnetzwerk zufällig gelöschte Bilder problemlos verarbeiten.
Zweitens hat das Autorenteam, inspiriert vom eleganten Design von UNet, natürlich ein Encoder-Decoder-Modell mit seitlichen Verbindungen entworfen, um den Fluss von Multiskalenfunktionen zwischen mehreren Ebenen des Modells zu ermöglichen Multiskalen-Goldstandard für Computer Vision.
Zu diesem Zeitpunkt wurde SparK geboren, ein spärlicher, mehrskaliger Maskenmodellierungsalgorithmus, der auf Faltungsnetzwerke (CNN) zugeschnitten ist.
SparK ist
generisch: Es kann direkt auf jedes Faltungsnetzwerk angewendet werden, ohne dass dessen Struktur geändert oder zusätzliche Komponenten eingeführt werden müssen – sei es das bekannte klassische ResNet oder Mit dem aktuellen Weiterentwicklungsmodell ConvNeXt können Sie direkt von SparK profitieren. Von ResNet zu ConvNeXt: Leistungsverbesserung von drei großen visuellen Aufgaben
Das Autorenteam wählte zwei repräsentative Faltungsmodellfamilien, ResNet und ConvNeXt, aus und verwendete sie in der Bildklassifizierung, Leistung Es wurden Tests zu Zielerkennungs- und Instanzsegmentierungsaufgaben durchgeführt.
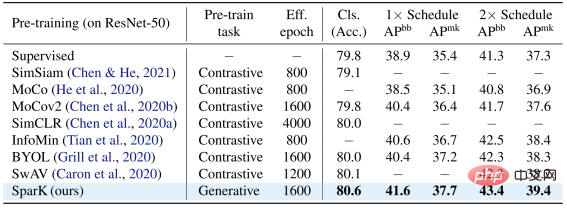
Auf dem klassischen ResNet-50-Modell dient SparK als einziges generatives Vortraining,
erreicht das State-of-the-Art-Niveau:
Auf dem ConvNeXt-Modell ist SparK immer noch führend . Vor dem Vortraining war ConvNeXt gleichauf mit Swin-Transformer; nach dem Vortraining übertraf ConvNeXt Swin-Transformer in drei Aufgaben bei weitem: In der Modellfamilie können Sie Folgendes beobachten:
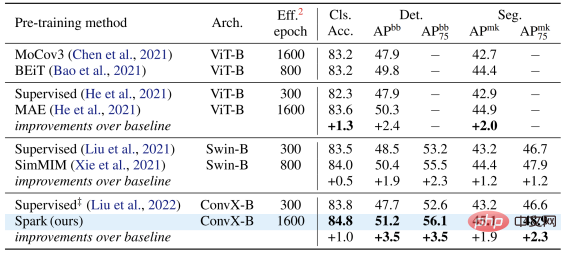 Egal, ob das Modell groß oder klein, neu oder alt ist, Sie können von SparK profitieren, und wenn die Modellgröße/der Schulungsaufwand zunimmt, ist der Anstieg sogar noch höher. was die Skalierungsfähigkeit des SparK-Algorithmus widerspiegelt:
Egal, ob das Modell groß oder klein, neu oder alt ist, Sie können von SparK profitieren, und wenn die Modellgröße/der Schulungsaufwand zunimmt, ist der Anstieg sogar noch höher. was die Skalierungsfähigkeit des SparK-Algorithmus widerspiegelt:
Schließlich entwarf das Autorenteam auch ein bestätigendes Ablationsexperiment, aus dem wir
sparse mask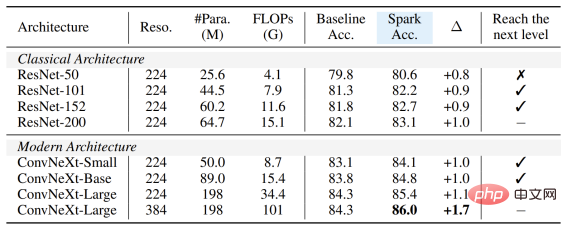
und sehen können Hierarchische Struktur Zeilen 3 und 4) sind beide sehr kritische Designs. Sobald sie fehlen, führt dies zu ernsthaften Leistungseinbußen:
Das obige ist der detaillierte Inhalt vonKann BERT auch auf CNN verwendet werden? Die Forschungsergebnisse von ByteDance wurden für das ICLR 2023 Spotlight ausgewählt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr