
Heim >Technologie-Peripheriegeräte >KI >Eine vorläufige Untersuchung der Entwicklung der Pre-Training-Technologie für natürliche Sprache
Eine vorläufige Untersuchung der Entwicklung der Pre-Training-Technologie für natürliche Sprache

- 王林nach vorne
- 2023-04-11 22:04:041303Durchsuche
Drei Ebenen der künstlichen Intelligenz:
Rechnerfunktionen: Datenspeicherung und Rechenfähigkeiten, Maschinen sind weitaus besser als Menschen.
Wahrnehmungsfunktionen: Sehen, Hören und andere Fähigkeiten sind in den Bereichen Spracherkennung und Bilderkennung bereits mit Menschen vergleichbar.
Kognitive Intelligenz: Für Aufgaben wie die Verarbeitung natürlicher Sprache, die Modellierung des gesunden Menschenverstandes und logisches Denken haben Maschinen noch einen langen Weg vor sich.
Die Verarbeitung natürlicher Sprache gehört zur Kategorie der kognitiven Intelligenz. Da natürliche Sprache die Merkmale Abstraktion, Kombination, Mehrdeutigkeit, Wissen und Evolution aufweist, stellt sie die maschinelle Verarbeitung vor große Herausforderungen Verarbeitung des Kronjuwels der künstlichen Intelligenz. In den letzten Jahren sind durch BERT vorab trainierte Sprachmodelle entstanden, die die Verarbeitung natürlicher Sprache in eine neue Ära führen: vorab trainierte Sprachmodelle + Feinabstimmung für bestimmte Aufgaben. In diesem Artikel wird versucht, die Entwicklung der Pre-Training-Technologie für natürliche Sprache zu ordnen, um mit allen zu kommunizieren und zu lernen. Wir freuen uns über Kritik und die Korrektur von Mängeln und Irrtümern.
1. Alt – Wortdarstellung
1.1 One-Hot-Codierung
Verwenden Sie einen Vektor in der Größe eines Vokabulars zur Darstellung ein WortDer Wert der entsprechenden Position des Wortes ist 1 und die verbleibenden Positionen sind 0. Nachteile:
- Hochdimensionale Sparsität
- Semantische Ähnlichkeit kann nicht ausgedrückt werden: Die One-Hot-Vektorähnlichkeit zweier Synonyme ist 0 #🎜 🎜#
- Textaufgabe mit hoher Häufigkeit.
- Kann keine Beziehungen höherer Ordnung widerspiegeln: (A, B) (B, C) (C, D) !=> (A, D).
- Es gibt immer noch ein Sparsity-Problem.
 1.2.4 LSA
1.2.4 LSA
Durch Durchführen einer Singularwertzerlegung (SVD) für die Worthäufigkeitsmatrix Die niedrigdimensionale, kontinuierliche, dichte Vektordarstellung eines Wortes kann als Darstellung der latenten Semantik des Wortes angesehen werden. Diese Methode wird auch als latente semantische Analyse (LSA) bezeichnet.
 LSA lindert Probleme wie hochfrequente Wörter, Beziehungen hoher Ordnung, Sparsity usw. Der Effekt ist bei herkömmlichen Algorithmen für maschinelles Lernen immer noch gut. Aber es gibt auch einige Mängel:
LSA lindert Probleme wie hochfrequente Wörter, Beziehungen hoher Ordnung, Sparsity usw. Der Effekt ist bei herkömmlichen Algorithmen für maschinelles Lernen immer noch gut. Aber es gibt auch einige Mängel:
- Wenn sich der Korpus ändert oder ein neuer Korpus hinzugefügt wird, muss er neu trainiert werden.
- 2. Moderne Zeiten – statische Wortvektoren
Die Ordnung des Textes und die Koexistenzbeziehung zwischen Wörtern sorgen für die Verarbeitung natürlicher Sprache. Das selbstüberwachte Lernsignal ermöglicht es dem System, Wissen aus Texten zu erlernen, ohne dass zusätzliche manuelle Anmerkungen erforderlich sind.
2.1 Word2Vec
2.1.1 CBOW
CBOW (Continous Bag-of-Words) nutzt den Kontext (Fenster), um das Zielwort vorherzusagen , Nehmen Sie das arithmetische Mittel der Wortvektoren der Kontextwörter und sagen Sie dann die Wahrscheinlichkeit des Zielworts voraus.
 2.1.2 Skip-gram
2.1.2 Skip-gram
Skip-gram Sagen Sie den Kontext wortweise voraus.
 2.2 GloVe
2.2 GloVe
GloVe (Global Vectors for Word Representation) verwendet Wortvektoren, um die Koexistenzmatrix von Wörtern vorherzusagen , Implizite Matrixfaktorisierung implementiert. Zuerst wird eine abstandsgewichtete Koexistenzmatrix

Die Verlustfunktion ist:

2.3 Zusammenfassung
Das Lernen von Wortvektoren nutzt die Informationen zum gleichzeitigen Auftreten von Wörtern im Korpus, und die zugrunde liegende Idee ist die verteilte semantische Hypothese. Unabhängig davon, ob es sich um Word2Vec handelt, das auf dem lokalen Kontext basiert, oder um GloVe, das auf expliziten globalen Informationen zum gemeinsamen Vorkommen basiert, besteht das Wesentliche darin, die Kontextinformationen zum gemeinsamen Auftreten eines Wortes im gesamten Korpus in der Vektordarstellung des Wortes zu aggregieren und gute Ergebnisse zu erzielen . Die Trainingsgeschwindigkeit ist ebenfalls sehr hoch, aber der Vektor der Mängel ist statisch, das heißt, er kann sich nicht mit Kontextänderungen ändern.
3. Modern - vorab trainiertes Sprachmodell
Autoregressives Sprachmodell: Berechnen Sie die bedingte Wahrscheinlichkeit des Wortes zum aktuellen Zeitpunkt basierend auf dem Sequenzverlauf.

Sprachmodell mit automatischer Kodierung: Rekonstruieren Sie die maskierten Wörter anhand des Kontexts.

stellt die maskierte Sequenz dar
3.1 Cornerstone - Transformer
#🎜🎜 ##🎜 🎜# 3.1.1 Aufmerksamkeitsmodell
3.1.1 Aufmerksamkeitsmodell
Das Aufmerksamkeitsmodell kann als Mechanismus zur Gewichtung einer Vektorsequenz und zur Berechnung der Gewichtung verstanden werden.
 3.1.2 Mehrkopf-Selbstaufmerksamkeit
3.1.2 Mehrkopf-Selbstaufmerksamkeit
Das in Transformer verwendete Aufmerksamkeitsmodell kann ausgedrückt werden als: #🎜 🎜#
Wenn Q, K, V aus derselben Vektorsequenz stammen, wird es zu einem Selbstaufmerksamkeitsmodell. 

3.1.3 Positionskodierung 
3.1.4 Sonstiges
Vorteile:
Im Vergleich zu RNN kann es Besser modellieren Bei Abhängigkeiten über große Entfernungen reduziert der Aufmerksamkeitsmechanismus den Abstand zwischen Wörtern auf 1 und bietet so stärkere Modellierungsmöglichkeiten für Daten mit langen Sequenzen.
- Im Vergleich zu RNN kann es die parallele Rechenleistung der GPU besser nutzen.
- Starke Ausdrucksfähigkeit.
- Nachteile:
Im Vergleich zu RNN sind die Parameter größer, was die Schwierigkeit des Trainings erhöht und erfordert mehr Trainingsdaten.
- 3.2 Autoregressives Sprachmodell
#🎜🎜 # Eingabeebene
Sie können die Einbettung des Wortes direkt für das Wort verwenden oder CNN oder andere Modelle für die Zeichenfolge im Wort verwenden.
Modellstruktur

ELMo modelliert unabhängig Vorwärts- und Rückwärtssprachmodelle durch LSTM


Bei Verwendung in nachgelagerten Aufgaben können die Vektoren jeder Schicht gewichtet werden, um eine Vektordarstellung von ELMo zu erhalten, und eine Gewichtung kann zum Skalieren des ELMo-Vektors verwendet werden. 🔜 GPT-1
 Modellstruktur
Modellstruktur

 Wir: Wortvektormatrix
Wir: Wortvektormatrix
Wp: Positionsvektormatrix
- Optimierungsziel
- Maximierung:
Nachgelagerte Anwendungen
In der Downstream-Aufgabe verfügt für einen beschrifteten Datensatz jede Instanz über ein Eingabetoken:, das aus der Beschriftung besteht. Zunächst werden diese Token in das trainierte Vortrainingsmodell eingegeben, um den endgültigen Merkmalsvektor zu erhalten. Dann wird das Vorhersageergebnis über eine vollständig verbundene Schicht erhalten:

Das Ziel der nachgelagerten überwachten Aufgabe besteht darin, Folgendes zu maximieren: 
- Um das Problem des katastrophalen Vergessens zu verhindern, kann ein bestimmtes Gewicht der Vorhersage hinzugefügt werden zum Feinabstimmungsverlust, normalerweise Verlust vor dem Training.
GPT-2
Die Kernidee von GPT-2 lässt sich wie folgt zusammenfassen: Jede überwachte Aufgabe ist eine Teilmenge des Sprachmodells, wenn die Kapazität des Modells sehr groß und die Datenmenge groß genug ist kann durch einfaches Training des Sprachmodells erreicht werden. Daher hat GPT-2 nicht zu viele strukturelle Neuerungen und Designs im GPT-1-Netzwerk vorgenommen. Es wurden lediglich mehr Netzwerkparameter und ein größerer Datensatz verwendet. Das Ziel bestand darin, ein Wortvektor mit stärkerer Generalisierungsfähigkeit zu trainieren.
Von den 8 Sprachmodellaufgaben hat GPT-2 7 allein durch Zero-Shot-Lernen übertroffen (natürlich sind einige Aufgaben immer noch nicht so gut wie das überwachte Modell). Der größte Beitrag von GPT-2 besteht darin, zu überprüfen, dass Wortvektormodelle, die mit umfangreichen Daten und einer großen Anzahl von Parametern trainiert wurden, ohne zusätzliches Training auf andere Aufgabenkategorien übertragen werden können.
Gleichzeitig hat GPT-2 gezeigt, dass mit zunehmender Modellkapazität und Menge (Qualität) der Trainingsdaten Raum für die Weiterentwicklung seines Potenzials besteht. Auf dieser Idee wurde GPT-3 geboren.
GPT-3
Die Modellstruktur bleibt unverändert, aber die Modellkapazität, das Trainingsdatenvolumen und die Qualität werden erhöht, und die Wirkung ist ebenfalls sehr gut.
Zusammenfassung

Von GPT-1 bis GPT-3 wird mit zunehmender Modellkapazität und der Menge an Trainingsdaten das vom Modell erlernte Sprachwissen umfangreicher und auch das Paradigma der Verarbeitung natürlicher Sprache ändert sich von „ „Pre-Training-Modell + Feinabstimmung“ verwandelt sich schrittweise in „Pre-Training-Modell + Zero-Shot/Wenige-Shot-Lernen“. Der Nachteil von GPT besteht darin, dass es ein einseitiges Sprachmodell verwendet. BERT hat bewiesen, dass ein zweiseitiges Sprachmodell den Modelleffekt verbessern kann.
3.2.3 XLNet
XLNet führt über das Permutation Language Model bidirektionale Kontextinformationen ein, ohne spezielle Tags einzuführen, wodurch das Problem einer inkonsistenten Token-Verteilung in der Vortrainings- und Feinabstimmungsphase vermieden wird. Gleichzeitig wird Transformer-XL als Hauptstruktur des Modells verwendet, was bessere Auswirkungen auf lange Texte hat.
Permutationssprachmodell
Das Ziel des Permutationssprachmodells ist:

ist die Menge aller möglichen Permutationen der Textsequenz.
Zwei-Stream-Selbstaufmerksamkeitsmechanismus
- Der Zweck des Zwei-Stream-Selbstaufmerksamkeitsmechanismus (Zwei-Stream-Selbstaufmerksamkeit) besteht darin, das Permutationssprachmodell durch Transformation des Transformators bei der Eingabe einer normalen Textsequenz zu erreichen:
- Inhaltsdarstellung: Enthaltene Informationen
- Abfragedarstellung: Nur enthaltene Informationen


Diese Methode verwendet die Positionsinformationen des vorhergesagten Wortes.
Downstream-Anwendung
Bei der Anwendung nachgelagerter Aufgaben ist keine Abfragedarstellung und keine Maske erforderlich.
3.3 Automatisch kodierendes Sprachmodell
3.3.1 BERT
Maskiertes Sprachmodell
Das maskierte Sprachmodell (MLM) maskiert zufällig einige Wörter und verwendet dann Kontextinformationen zur Vorhersage. Es gibt ein Problem mit MLM, es besteht ein Missverhältnis zwischen Vortraining und Feinabstimmung, da der [MASK]-Token während der Feinabstimmung nie gesehen wird. Um dieses Problem zu lösen, ersetzt BERT nicht immer das „maskierte“ Wortteil-Token durch das tatsächliche [MASK]-Token. Der Trainingsdatengenerator wählt zufällig 15 % der Token aus und dann:
- 80 % Wahrscheinlichkeit: Ersetzt sie durch den [MASK]-Token.
- 10 % Wahrscheinlichkeit: durch einen zufälligen Token aus der Vokabelliste ersetzen.
- 10 % Wahrscheinlichkeit: Token bleibt unverändert.
Token ist im nativen BERT maskiert und ganze Wörter oder Phrasen (N-Gram) können maskiert werden.
Nächste-Satz-Vorhersage
Nächste-Satz-Vorhersage (NSP): Wenn die Sätze A und B als Vortrainingsbeispiele ausgewählt werden, besteht eine 50-prozentige Chance, dass B der nächste Satz von A ist, und eine 50-prozentige Chance, zufällig zu sein Satz aus dem Korpus.
Eingabeebene

Modellstruktur

Das klassische Paradigma „vorab trainiertes Modell + Feinabstimmung“, die Themenstruktur ist ein gestapelter mehrschichtiger Transformator.
3.3.2 RoBERTa
RoBERTa (Robustly Optimized BERT Pretraining Approach) verbessert BERT nicht drastisch, sondern führt nur detaillierte Experimente zu jedem Designdetail von BERT durch, um Raum für Verbesserungen von BERT zu finden.
- Dynamische Maske: Die ursprüngliche Methode besteht darin, die Maske festzulegen und beim Erstellen des Datensatzes zu korrigieren. Die verbesserte Methode besteht darin, die Daten bei der Eingabe der Daten in das Modell in jeder Trainingsrunde zufällig zu maskieren, was die Vielfalt erhöht die Daten.
- NSP-Aufgaben aufgeben: Experimente haben gezeigt, dass der Verzicht auf NSP-Aufgaben die Leistung der meisten Aufgaben verbessern kann.
- Mehr Trainingsdaten, größere Chargen und längere Schritte vor dem Training.
- Großer Wortschatz: Wenn Sie das BPE-Vokabular auf Byte-Ebene wie SentencePiece anstelle des BPE-Vokabulars auf Zeichenebene von WordPiece verwenden, gibt es fast keine nicht registrierten Wörter.
3.3.3 ALBERT
BERT hat eine relativ große Anzahl von Parametern. Das Hauptziel von ALBERT (A Lite BERT) besteht darin, Parameter zu reduzieren:
- BERTs Wortvektordimension ist dieselbe wie die Dimension der verborgenen Ebene Der Wortvektor ist kontextfrei, während BERT Die Transformer-Schicht benötigt und kann ausreichend Kontextinformationen lernen, daher sollte die Vektordimension der verborgenen Schicht viel größer sein als die Wortvektordimension. Bei einer Vergrößerung zur Verbesserung der Leistung besteht keine Notwendigkeit, die Größe zu erhöhen, da der Wortvektorraum möglicherweise für die Menge der einzubettenden Informationen ausreicht.
- Schema: Der Wortvektor wird durch die vollständig verbundene Schicht in die H-Dimension umgewandelt.
- Faktorisierte Einbettungsparametrisierung.
- Ebenenübergreifende Parameterfreigabe: Transformatorblöcke verschiedener Ebenen teilen Parameter.
- Satzordnungsvorhersage (SOP), Erlernen subtiler semantischer Unterschiede und Diskurskohärenz. 3.4 Generative Konfrontation - ELECTRA (RTD) Aufgabe ist es, zu bestimmen, ob das aktuelle Token durch ein Sprachmodell ersetzt wurde, das der Idee von GAN ähnelt.
Der Generator sagt das Token an der Maskenposition im Eingabetext voraus:

 Die Eingabe des Diskriminators ist die Ausgabe des Generators, und der Diskriminator sagt voraus, ob das Wort an jeder Position vorhanden ist ersetzt:
Die Eingabe des Diskriminators ist die Ausgabe des Generators, und der Diskriminator sagt voraus, ob das Wort an jeder Position vorhanden ist ersetzt:

Darüber hinaus wurden einige Optimierungen vorgenommen:
 Der Generator und der Diskriminator sind jeweils ein BERT, und die Parameter des Generator-BERT sind skaliert.
Der Generator und der Diskriminator sind jeweils ein BERT, und die Parameter des Generator-BERT sind skaliert.
Wortvektorparameterzerlegung.
- Gemeinsame Nutzung von Generator- und Diskriminatorparametern: Gemeinsame Nutzung von Parametern der Eingabeebene, einschließlich Wortvektormatrix und Positionsvektormatrix.
- Verwenden Sie in nachgelagerten Aufgaben nur den Diskriminator und nicht den Generator. 3.5 Langtextverarbeitung – Transformer-XL
Um die Modellierung von Langtexten zu optimieren, verwendet Transformer-XL zwei Technologien: Wiederholung auf Segmentebene mit Zustandswiederverwendung und relative Positionskodierungen.
3.5.1 Schleife der Zustandswiederverwendung auf Blockebene
Transformer-XL wird während des Trainings auch in Form von Segmenten fester Länge eingegeben. Der Unterschied besteht darin, dass der Status des vorherigen Segments von Transformer-XL zwischengespeichert wird Durch die Wiederverwendung des verborgenen Zustands der vorherigen Zeitscheibe bei der Berechnung des aktuellen Segments erhält Transformer-XL die Möglichkeit, längerfristige Abhängigkeiten zu modellieren.
Zwei aufeinanderfolgende Segmente der Länge L und. Der Zustand des Knotens der verborgenen Schicht wird ausgedrückt als, wobei d die Dimension des Knotens der verborgenen Schicht ist. Der Berechnungsprozess des Status des Hidden-Layer-Knotens ist: 
Ein weiterer Vorteil der Fragmentrekursion ist die Verbesserung der Argumentationsgeschwindigkeit. Im Vergleich zur autoregressiven Architektur von Transformer, die jeweils nur eine Zeitscheibe vorrücken kann, verbessert sich der Argumentationsprozess von Transformer-XL durch die direkte Wiederverwendung der Darstellung des vorherigen Fragments Durch die Berechnung von Grund auf wird der Denkprozess zu einem Stück-für-Stück-Argumentieren gefördert.

3.5.2 Relative Positionskodierung
In Transformer kann das Selbstaufmerksamkeitsmodell ausgedrückt werden als: #🎜🎜 # Der vollständige Ausdruck von


#🎜🎜 #  Das Problem mit Transformer besteht darin, dass die Positionscodierung unabhängig vom Fragment dieselbe ist. Das heißt, die Positionscodierung von Transformer ist die absolute Positionscodierung relativ zum Fragment (absolute Positionscodierung). was mit dem aktuellen Inhalt im Original übereinstimmt. Die relative Position innerhalb des Satzes spielt keine Rolle.
Das Problem mit Transformer besteht darin, dass die Positionscodierung unabhängig vom Fragment dieselbe ist. Das heißt, die Positionscodierung von Transformer ist die absolute Positionscodierung relativ zum Fragment (absolute Positionscodierung). was mit dem aktuellen Inhalt im Original übereinstimmt. Die relative Position innerhalb des Satzes spielt keine Rolle.
Transfomer-XL hat mehrere Änderungen basierend auf der obigen Formel vorgenommen und die folgende Berechnungsmethode erhalten:
 # 🎜🎜# Änderung 1: Mittel, wird in eine echte Summe aufgeteilt, was bedeutet, dass die Eingabesequenz und die Positionscodierung keine gemeinsamen Gewichte mehr haben.
# 🎜🎜# Änderung 1: Mittel, wird in eine echte Summe aufgeteilt, was bedeutet, dass die Eingabesequenz und die Positionscodierung keine gemeinsamen Gewichte mehr haben.
- Änderung 2: In wird die Kodierung der absoluten Position durch die Kodierung der relativen Position ersetzt.
- Änderung 3: Zwei neue lernbare Parameter werden eingeführt, um die Abfrage im Transformer-Vektor zu ersetzen. Gibt an, dass die entsprechenden Abfragepositionsvektoren für alle Abfragepositionen gleich sind. Das heißt, unabhängig von der Abfrageposition bleibt die Aufmerksamkeitsverzerrung für verschiedene Wörter konsistent.
- Nach der Verbesserung die Bedeutung jedes Teils:
- Inhaltsbasierte Relevanz (): Berechnen Sie die Zuordnung zwischen dem Inhalt der Abfrage und dem Schlüssel Information
- Inhaltsbezogener Positionsoffset (): Berechnen Sie die zugehörigen Informationen zwischen dem Inhalt der Abfrage und der Positionscodierung des Schlüssels.
- Globaler Inhaltsoffset (): Berechnen Sie den Abfrage der zugehörigen Informationen zwischen dem Positionscode und dem Inhalt des Schlüssels
- 3.6 Destillation und Komprimierung – DistillBert
- Wissensdestillation (KD): Normalerweise bestehend aus einem Lehrermodell und einem Schülermodell, wird das Wissen vom Lehrermodell auf das Schülermodell übertragen, sodass das Das Schülermodell kommt dem Lehrermodell so nahe wie möglich. In praktischen Anwendungen muss das Schülermodell häufig kleiner sein als das Lehrermodell und im Wesentlichen die Wirkung des ursprünglichen Modells beibehalten.
- DistillBerts Studentenmodell:
Sechsschichtiges BERT, während die Token-Typ-Einbettung entfernt wird, das ist Segment-Einbettung) .
Verwenden Sie zur Initialisierung die ersten sechs Schichten des Lehrermodells. Für das Training wird nur das maskierte Sprachmodell verwendet, die NSP-Aufgabe wird nicht verwendet.
- Lehrermodell: BERT-Basis:
- Verlustfunktion:
Überwachter MLM-Verlust: Kreuzentropieverlust, der durch Training mit maskiertem Sprachmodell erhalten wird: Gibt die Wahrscheinlichkeit der Kategorieausgabe des Studentenmodells an.
Destillierter MLM-Verlust: Verwenden Sie die Wahrscheinlichkeit des Lehrermodells als Orientierungssignal und berechnen Sie den Kreuzentropieverlust mit der Wahrscheinlichkeit des Schülermodells: #🎜🎜 ##🎜🎜 #
stellt die Bezeichnung der ersten Kategorie des Lehrermodells dar. 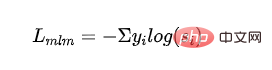
- Wortvektor-Kosinusverlust: Richten Sie die Richtungen der verborgenen Schichtvektoren des Lehrermodells und des Schülermodells aus und verkürzen Sie den Abstand zwischen dem Lehrermodell und dem Schülermodell aus der Dimension der verborgenen Ebene:
-
- und stellen die Ausgabe der verborgenen Ebene der letzten Ebene des Lehrermodells bzw. des Schülermodells dar.
- Endgültiger Verlust:

4 https://www.php. cn/link/664c7298d2b73b3c7fe2d1e8d1781c06
https://www.php.cn/link/67b878df6cd42d142f2924f3ace85c78
https:// www.php.c n/link/f6a673f09493afcd8b129a0bcf1cd5bc
https://www.php.cn/link/82599a4ec94aca066873c99b4c741ed8
https://www.php.cn/link/2e64da0bae6a7533021c760d4ba5d621
https :/ /www.php.cn/link/56d33021e640f5d64a611a71b5dc30a3
https://www.php.cn/link/4e38d30e656da5ae9d3a425109ce9e04
https://www.php.cn /link /c055dcc749c2632fd4dd806301f05ba6
https://www.php.cn/link/a749e38f556d5eb1dc13b9221d1f994f
https://www.php.cn / link/8ab9bb97ce35080338be74dc6375e0ed
https://www.php.cn/link/4f0bf7b7b1aca9ad15317a0b4efdca14
https://www.php.cn/link/b81132591828d622fc335860bffec150
https:// www. php.cn/link/fca758e52635df5a640f7063ddb9cdcb
https://www.php.cn/link/5112277ea658f7138694f079042cc3bb
https://www.php .cn/link/ 257deb66f5366aab34a23d5fd0571da4
https://www.php.cn/link/b18e8fb514012229891cf024b6436526
https://www.php.cn/link. /836a0dcbf5d22652569dc3a708274c 16
https ://www.php.cn/link/a3de03cb426b5e36f5c7167b21395323
https://www.php.cn/link/831b342d8a83408e5960e9b0c5f31f0c
https://www.php .cn /link/6b27e88fdd7269394bca4968b48d8df4
https://www.php.cn/link/682e0e796084e163c5ca053dd8573b0c
https://www.php. .cn/link/9739efc4f01292e764c86caa59af353e
https://www.php.cn/link/b93e78c67fd4ae3ee626d8ec0c412dec
https://www.php.cn/link/c8cc6e90ccbff44c9cee23611711cdc4
Das obige ist der detaillierte Inhalt vonEine vorläufige Untersuchung der Entwicklung der Pre-Training-Technologie für natürliche Sprache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr