
Heim >Technologie-Peripheriegeräte >KI >Befassen Sie sich mit der Praxis der AI-Deep-Learning-Modell-Inferenzoptimierung im Standardisierungsdienst
Befassen Sie sich mit der Praxis der AI-Deep-Learning-Modell-Inferenzoptimierung im Standardisierungsdienst

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-11 19:28:111904Durchsuche
Einführung
Deep Learning wurde in tatsächlichen Geschäftsszenarien in Bereichen wie der Verarbeitung natürlicher Sprache weithin implementiert, und die Optimierung seiner Inferenzleistung ist zu einem wichtigen Teil des Bereitstellungsprozesses geworden. Verbesserung der Argumentationsleistung: Einerseits kann die Leistungsfähigkeit der eingesetzten Hardware voll ausgeschöpft werden, die Reaktionszeit des Benutzers verkürzt und Kosten gespart werden. Andererseits können Deep-Learning-Modelle mit komplexeren Strukturen verwendet werden, während die Reaktionszeit beibehalten wird unverändert, wodurch die Geschäftsgenauigkeitsindikatoren verbessert werden.
In diesem Artikel werden Arbeiten zur Optimierung der Inferenzleistung für das Deep-Learning-Modell im Adressstandardisierungsdienst durchgeführt. Durch Optimierungsmethoden wie Hochleistungsoperatoren, Quantifizierung und Kompilierungsoptimierung kann die End-to-End-Inferenzgeschwindigkeit des KI-Modells um das bis zu 4,11-fache verbessert werden, ohne den Genauigkeitsindex zu verringern. 1. Methodik zur Optimierung der Modellinferenzleistung
Die Optimierung der Modellinferenzleistung ist einer der wichtigen Aspekte bei der Bereitstellung von KI-Diensten. Einerseits kann es die Effizienz der Modellinferenz verbessern und die Leistung der Hardware vollständig freigeben. Andererseits kann es dem Unternehmen ermöglichen, komplexere Modelle zu übernehmen und gleichzeitig die Argumentationsverzögerung unverändert zu lassen, wodurch der Genauigkeitsindex verbessert wird. Es gibt jedoch einige Schwierigkeiten bei der Optimierung der Argumentationsleistung in tatsächlichen Szenarien.1.1 Schwierigkeiten bei der Optimierung von Szenarien zur Verarbeitung natürlicher Sprache
Bei typischen Aufgaben zur Verarbeitung natürlicher Sprache (NLP) sind Recurrent Neural Network (RNN) und BERT[7] (Bidirektionale Encoderdarstellungen von Transformers.) zwei Arten von Modellen Bauwerke mit hohen Nutzungsraten. Um den elastischen Skalierungsmechanismus und die hohe Kosteneffizienz der Bereitstellung von Onlinediensten zu ermöglichen, werden Aufgaben zur Verarbeitung natürlicher Sprache normalerweise auf x86-CPU-Plattformen wie Intel® Xeon®-Prozessoren bereitgestellt. Da Geschäftsszenarien jedoch immer komplexer werden, werden die Anforderungen an die Inferenz-Computing-Leistung von Diensten immer höher. Am Beispiel der oben genannten RNN- und BERT-Modelle ergeben sich bei der Bereitstellung auf der CPU-Plattform folgende Leistungsherausforderungen:
RNN
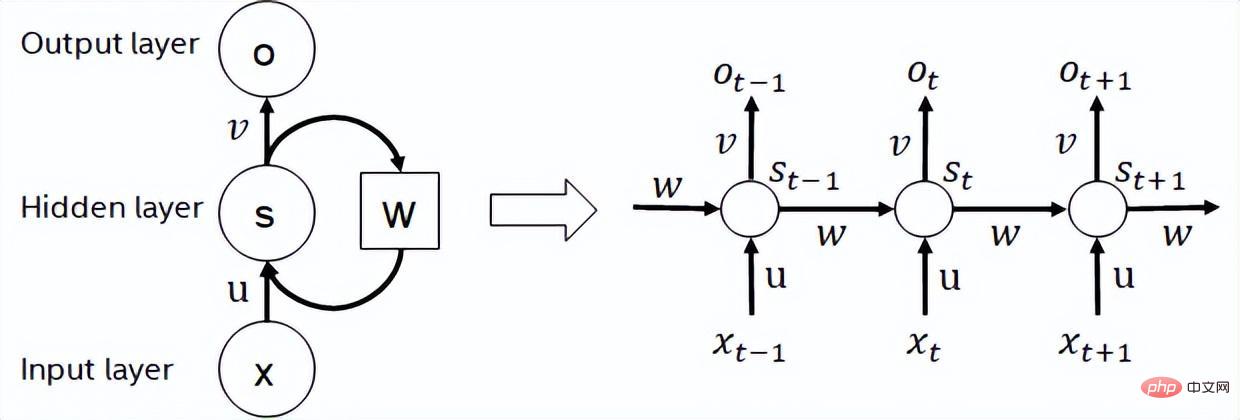
- Rekurrentes neuronales Netzwerk ist eine Art neuronales Netzwerk, das Sequenzdaten verarbeitet Eingabe Ein rekursives neuronales Netzwerk, das eine Rekursion in Evolutionsrichtung durchführt und bei dem alle Knoten (zyklische Einheiten) in einer Kette verbunden sind. Zu den in der Praxis häufig verwendeten RNNs gehören LSTM, GRU und einige abgeleitete Varianten. Während des Berechnungsprozesses, wie in der folgenden Abbildung dargestellt, hängt die Ausgabe jeder nachfolgenden Stufe in der RNN-Struktur von der entsprechenden Eingabe und der Ausgabe der vorherigen Stufe ab. Daher kann RNN sequenzartige Aufgaben erledigen und wurde in den letzten Jahren häufig im Bereich NLP und sogar Computer Vision eingesetzt. Im Vergleich zu BERT erfordert RNN weniger Berechnungen und teilt Modellparameter, aber seine Abhängigkeit vom Berechnungszeitpunkt macht es unmöglich, parallele Berechnungen für die Sequenz durchzuführen.
RNN-Strukturdiagramm
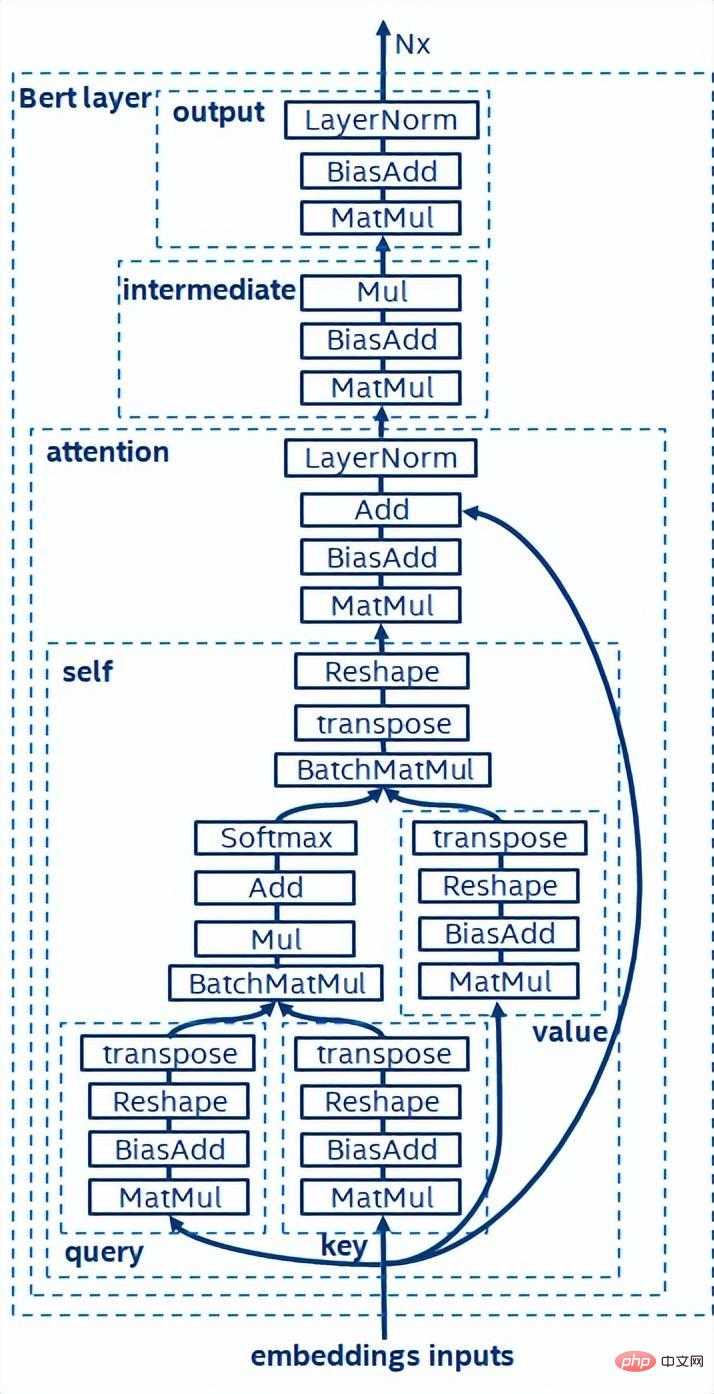
- BERT [7] hat bewiesen, dass es ein unbeaufsichtigtes Vortraining (unüberwachtes Vortraining) für große Datensätze mit einem tieferen Netzwerk durchführen kann Strukturieren und dann ein Modell zur Feinabstimmung für bestimmte Aufgaben bereitstellen. Es verbessert nicht nur die Genauigkeit dieser spezifischen Aufgaben, sondern vereinfacht auch den Trainingsprozess. Die Modellstruktur von BERT ist einfach und leicht zu erweitern, indem Sie das Netzwerk einfach vertiefen und erweitern, um eine bessere Genauigkeit als die RNN-Struktur zu erzielen. Andererseits geht die Verbesserung der Genauigkeit mit einem höheren Rechenaufwand einher. Das BERT-Modell enthält eine große Anzahl von Matrixmultiplikationsoperationen, was eine große Herausforderung für die CPU darstellt.
Schematische Darstellung der BERT-Modellstruktur
Basierend auf der Analyse der oben genannten Herausforderungen bei der Inferenzleistung glauben wir, dass die folgenden Strategien hauptsächlich zur Optimierung der Modellinferenz aus verwendet werden Software-Stack-Ebene:
Modellkomprimierung: einschließlich Quantisierung, Sparseness, Pruning usw.
- Hochleistungsoperatoren für bestimmte Szenarien
- KI-Compiler-Optimierung
- Quantisierung
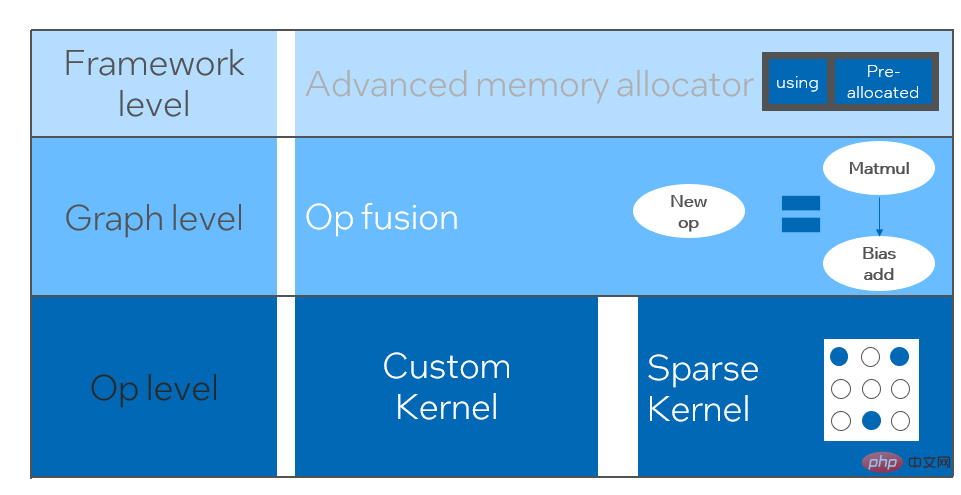
Modellquantisierung bezieht sich auf den Prozess der Annäherung von Gleitkomma-Aktivierungswerten oder -gewichten (normalerweise dargestellt durch 32-Bit-Gleitkommazahlen) an Ganzzahlen mit niedriger Bitzahl (16 Bit oder 8 Bit) und den anschließenden Abschluss der Berechnung in einer Low-Bit-Darstellung. Im Allgemeinen kann die Modellquantisierung Modellparameter komprimieren, wodurch der Modellspeicheraufwand reduziert wird und indem der Speicherzugriff reduziert und Low-Bit-Computing-Anweisungen (wie Intel® Deep Learning Boost Vector Neural Network Instructions, VNNI) effektiv genutzt werden, um Inferenz zu erreichen Geschwindigkeit Verbesserung. Anhand eines Gleitkommawerts können wir ihn mithilfe der folgenden Formel einem Low-Bit-Wert zuordnen: wobei die Summe durch den Quantisierungsalgorithmus erhalten wird. Basierend darauf nehmen wir als Beispiel die Gemm-Operation und gehen davon aus, dass es einen Gleitkommaberechnungsprozess gibt: Wir können den entsprechenden Berechnungsprozess im Low-Bit-Bereich abschließen: Hochleistungsoperatoren im Deep-Learning-Framework Um die Vielseitigkeit aufrechtzuerhalten und verschiedene Prozesse (z. B. Schulungen) zu berücksichtigen, ist der Inferenzaufwand des Bedieners redundant. Wenn die Modellstruktur bestimmt ist, ist der Argumentationsprozess des Bedieners nur eine Teilmenge des ursprünglichen Gesamtprozesses. Daher können wir bei der Bestimmung der Modellstruktur leistungsstarke Inferenzoperatoren implementieren und die allgemeinen Operatoren im Originalmodell ersetzen, um die Inferenzgeschwindigkeit zu verbessern. Der Schlüssel zur Implementierung von Hochleistungsoperatoren auf der CPU liegt in der Reduzierung von Speicherzugriffen und der Verwendung eines effizienteren Befehlssatzes. Im Berechnungsprozess des ursprünglichen Operators gibt es einerseits eine große Anzahl von Zwischenvariablen, und diese Variablen führen eine große Anzahl von Lese- und Schreibvorgängen im Speicher aus, wodurch die Argumentationsgeschwindigkeit verlangsamt wird. Als Reaktion auf diese Situation können wir die Berechnungslogik ändern, um die Kosten für Zwischenvariablen zu reduzieren. Andererseits können wir den vektorisierten Befehlssatz direkt aufrufen, um einige Berechnungsschritte innerhalb des Operators zu beschleunigen, z. B. die Intel® Xeon®-Verarbeitung AVX512-Befehlssatz auf dem Prozessor. KI-Compiler-Optimierung Mit der Entwicklung des Bereichs Deep Learning haben die Struktur des Modells und die eingesetzte Hardware einen Trend der diversifizierten Entwicklung gezeigt. Bei der Bereitstellung des Modells auf verschiedenen Hardwareplattformen nennen wir normalerweise die von jedem Hardwarehersteller gestartete Laufzeit. In tatsächlichen Geschäftsszenarien kann dies auf einige Herausforderungen stoßen, wie zum Beispiel: Der KI-Compiler wurde vorgeschlagen, um die oben genannten Probleme zu lösen. Er abstrahiert mehrere Ebenen, um einige der oben genannten Probleme zu lösen. Zunächst akzeptiert es das Modellberechnungsdiagramm jedes Front-End-Frameworks als Eingabe und generiert über verschiedene Konverter eine einheitliche Zwischendarstellung. Anschließend werden Graphoptimierungsdurchgänge wie Operatorfusion und Schleifenerweiterung auf die Zwischendarstellung angewendet, um die Argumentationsleistung zu verbessern. Schließlich führt der KI-Compiler eine Codegenerierung für bestimmte Hardwareplattformen basierend auf dem optimierten Berechnungsdiagramm durch, um ausführbaren Code zu generieren. In diesem Prozess werden Optimierungsstrategien wie Stich- und Formbeschränkungen eingeführt. Der KI-Compiler ist sehr robust, anpassungsfähig, einfach zu bedienen und kann erhebliche Optimierungsvorteile erzielen. In diesem Artikel hat sich das PAI-Team der Alibaba Cloud-Plattform für maschinelles Lernen mit dem Intel-Rechenzentrumssoftwareteam, dem Intel-Team für künstliche Intelligenz und Analyse und dem NLP-Adressstandardisierungsteam der DAMO Academy zusammengetan, um die Inferenzleistungsherausforderung der Adressstandardisierung zu lösen Service und Zusammenarbeit, um ein leistungsstarkes Inferenzoptimierungsschema zu erreichen. Öffentliche Sicherheit und Regierungsangelegenheiten, E-Commerce-Logistik, Energie (Wasser, Strom und Gas), Betreiber, neuer Einzelhandel, Finanzen, Medizin und andere Branchen erfordern oft eine große Menge an Adressen Daten im Prozess der Geschäftsentwicklung, und diese Daten haben oft keine Standardstrukturspezifikation und es gibt Probleme wie fehlende Adressen und mehrere Namen an einer Stelle. Mit der fortschreitenden Digitalisierung ist das Problem nicht standardmäßiger städtischer Adressen immer deutlicher geworden. Bestehende Probleme bei der Adressanwendung Adressstandardisierung[2] (Adressreinigung) ist eine hochwertige Lösung, die vom NLP-Team der Alibaba Damo Academy entwickelt wurde und sich auf den riesigen Adresskorpus von Alibaba Cloud und seine Super-NLP-Algorithmusstärke stützt . Standard-Adressalgorithmusdienst mit hoher Leistung und hoher Genauigkeit. Adressstandardisierungsprodukte bieten leistungsstarke Adressalgorithmen im Hinblick auf die Standardisierung von Adressdaten und die Einrichtung einer einheitlichen Standardadressbibliothek. Vorteile der Adressstandardisierung Dieser Adressalgorithmusdienst kann Adressdaten automatisch standardisieren, wodurch das Problem mehrerer Namen an einem Ort, Adressidentifizierung, Adressauthentizitätsidentifizierung und andere Unregelmäßigkeiten bei Adressdaten und Zeit- Aufwändige manuelle Verwaltung Es löst die Probleme des Arbeitsaufwands und der Duplizierung beim Aufbau von Adressdatenbanken und bietet Funktionen zur Adressdatenbereinigung und Adressstandardisierung für Unternehmen, Regierungsbehörden und Entwickler, sodass Adressdaten das Geschäft besser unterstützen können. Adressstandardisierungsprodukte weisen die folgenden Merkmale auf: Multitask-geografische Sprachmodellbasis vor dem TrainingBasierend auf der MLM-Aufgabe (Masked Language Model) kombiniert es die Klassifizierung verwandter Interessenpunkte und die Identifizierung von Adresselementen (Provinz, Stadt, Bezirk, POI usw.). Durch die Meta-Learning-Methode (Meta Learning) wird die Stichprobenwahrscheinlichkeit mehrerer Aufgaben adaptiv angepasst und allgemeines Adresswissen in das Sprachmodell integriert. Das Multitask-Vektorrückrufmodell wird basierend auf der oben genannten Basis trainiert, einschließlich Zwillingsturmähnlichkeit, Geohash (Adresskodierung). ) Vorhersage, Wortsegmentierung und Begriffsgewichtung (Wortgewichtung) ) vier Aufgaben. Schematisches Diagramm des Multi-Task-Vektor-Recall-Modells Als Kernmodul zur Berechnung des Adressähnlichkeits-Matchings basiert das Fine-Ranking-Modell auf der oben genannten Basis und führt umfangreiche Klickdaten und Anmerkungsdaten für ein Training [3] und Verbesserung der Effizienz des Modells durch Modelldestillationstechnologie [4]. Schließlich nachbestellt mit Adressbibliotheksdokumenten, die auf den Rückruf des Rückrufmodells angewendet wurden. Das auf dem oben genannten Prozess trainierte 4-Schicht-Einzelmodell kann bei der chinesischen NLP-Adresskorrelationsaufgabe CCKS2021 [5] bessere Ergebnisse erzielen als das 12-Schicht-Basismodell (Einzelheiten finden Sie im Abschnitt „Leistungsanzeige“). Schematische Darstellung des verfeinerten Modells Das vom PAI-Team der Alibaba Cloud-Plattform für maschinelles Lernen eingeführte Blade-Produkt unterstützt alle oben genannten Optimierungslösungen, bietet eine einheitliche Benutzeroberfläche und verfügt über mehrere Software-Backends wie Hochleistungsoperatoren, Intel Custom Backend, BladeDISC usw. „Blade-Modell-Inferenzoptimierungsarchitekturdiagramm“ Durch das Modellsystem optimiert, damit das Modell eine optimale Argumentationsleistung erzielen kann. Es integriert auf organische Weise die Optimierung von Computergraphen, Bibliotheken zur Anbieteroptimierung wie Intel® oneDNN, die BladeDISC-Kompilierungsoptimierung, die Blade-Hochleistungsoperatorbibliothek, Costom Backend, Blade Mixed Precision und andere Optimierungsmethoden. Gleichzeitig senkt die einfache Nutzung die Schwelle zur Modelloptimierung und verbessert das Benutzererlebnis und die Produktionseffizienz. Blade-Optimierungsdiagramm Um den maximalen Optimierungseffekt zu erzielen und gleichzeitig die Erfolgsquote der Bereitstellung sicherzustellen, wendet PAI-Blade eine „Kreisdiagramm“-Methode zur Optimierung an, das heißt: wird be Im optimierten Unterberechnungsdiagramm werden die Teile, die vom Inferenz-Backend/Hochleistungsoperator unterstützt werden können, in das entsprechende optimierte Unterdiagramm konvertiert. Der nicht optimierte Untergraph wird auf zurückgesetzt Ausführung des entsprechenden nativen Frameworks (TF/Torch). Blade-Kreisdiagramm einfache Benutzeroberfläche bietet Unterstützung für eine Vielzahl von Backends Integrieren Sie verschiedene vom PAI-Blade-Team selbst entwickelte Algorithmen in den tatsächlichen Produktionsbetrieb, um eine
BladeDISC-Architekturdiagramm 3.2 Hochleistungsoperator basierend auf Intel® Es ist das Grundmodul für den Modellbau und ist für bestimmte Funktionen verantwortlich. Durch unterschiedliche Kombinationen dieser Module können verschiedene Modelle erhalten werden, und diese Module sind auch der Schlüssel Optimierungsziele des KI-Compilers. Um die leistungsstärksten Basismodule zu erhalten und damit das leistungsstärkste Modell zu erhalten, hat Intel eine mehrstufige Optimierung dieser Basismodule für die X86-Architektur durchgeführt, einschließlich der Ermöglichung effizienter AVX512-Anweisungen, der betreiberinternen Berechnungsplanung und des Operators Fusion, Cache-Optimierung, parallele Optimierung usw. In Adressstandardisierungsdiensten kommt häufig das RNN-Modell (Recurrent Neural Network) vor, und die Module, die die Leistung im RNN-Modell am stärksten beeinflussen, sind Module wie LSTM oder GRU. In diesem Kapitel wird LSTM als Beispiel verwendet in einer variablen Länge und mehrdimensional So erreichen Sie die ultimative Leistungsoptimierung von LSTM bei der Eingabe von Stapeln. Um den Bedürfnissen und Anforderungen verschiedener Benutzer gerecht zu werden, stapeln Cloud-Dienste, die eine hohe Leistung und niedrige Kosten anstreben, normalerweise verschiedene Benutzeranforderungen, um die Nutzung der Computerressourcen zu maximieren. Wie in der folgenden Abbildung gezeigt, gibt es insgesamt drei Einbettungssätze, und der Inhalt und die Eingabelänge sind unterschiedlich. Ursprüngliche Eingabedaten Ursprüngliche Eingabedaten LSTMs Berechnungsschritte für die Eingabe LSTM-Computing-Fusion[8] Intel Custom Backend[9] beschleunigt als Software-Backend von Blade die Modellquantisierung und die Leistung spärlicher Inferenzen erheblich, darunter hauptsächlich drei Optimierungsebenen. Erstens wird die Primitive-Cache-Strategie verwendet, um den Speicher zu optimieren. Zweitens wird eine Optimierung der Graphenfusion durchgeführt. Schließlich wird auf Operatorebene eine effiziente Operatorbibliothek einschließlich spärlicher und quantisierter Operatoren implementiert. Intel Custom Backend Architecture Diagram Quantisierung mit geringer Präzision Hochgeschwindigkeitsoperatoren wie Sparse und Quantisierung profitieren vom Intel® DL Boost-Beschleunigungsbefehlssatz, wie z. B. dem VNNI-Befehlssatz.
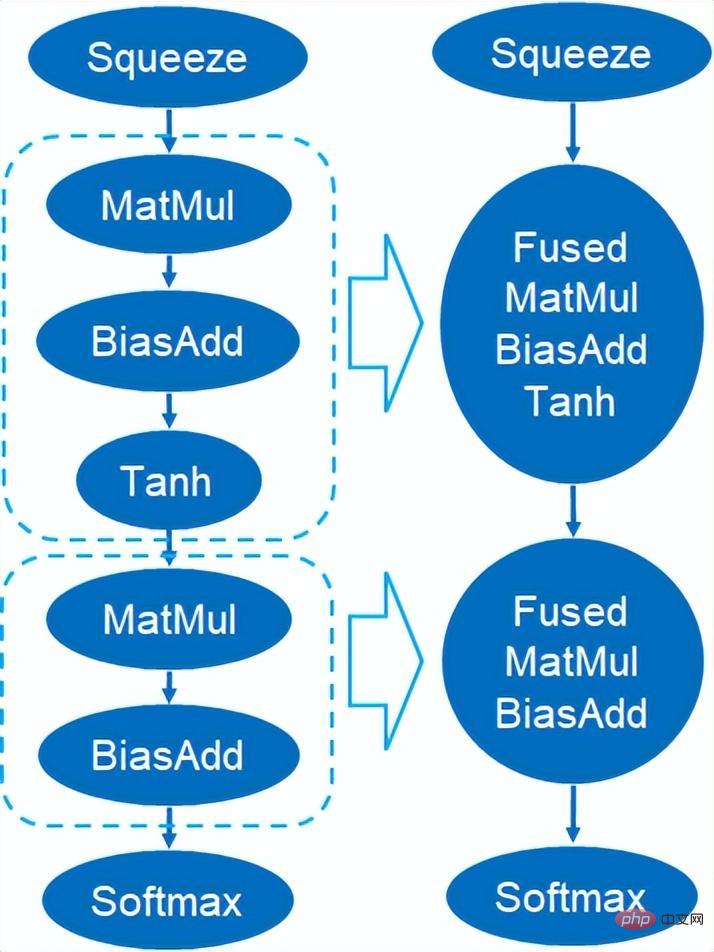
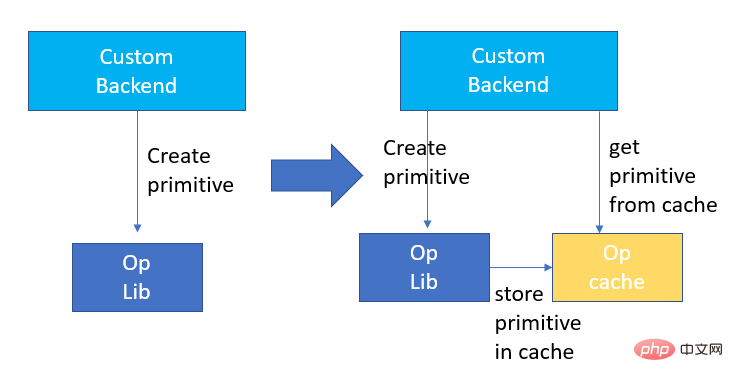
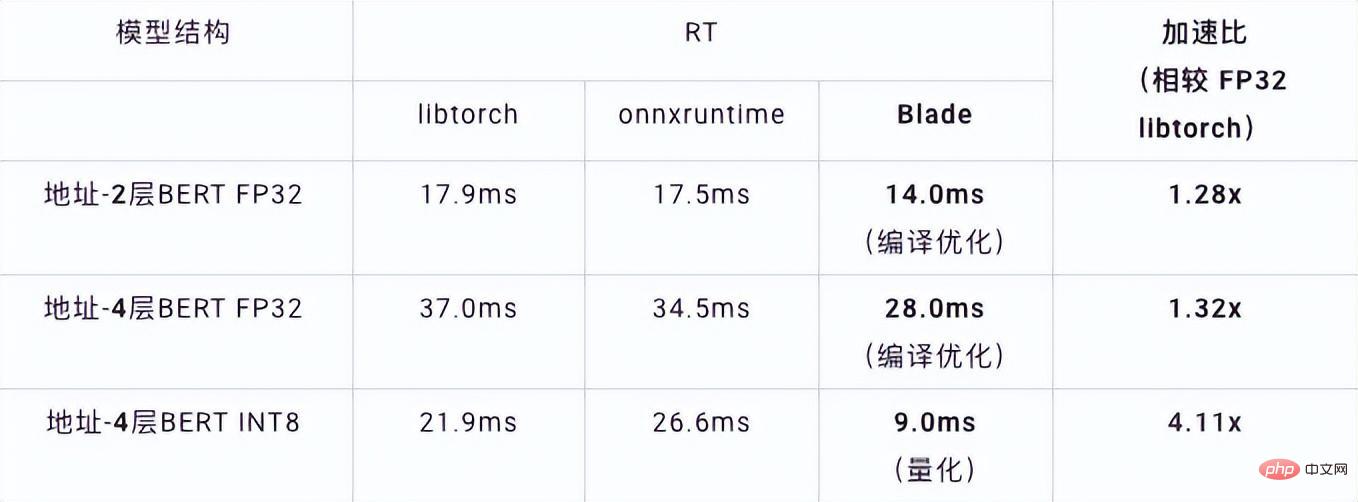
Einführung in den VNNI-Befehl Das Bild oben zeigt, dass der VNNI-Befehl zunächst mit drei AVX512-BW-Befehlen multipliziert und 2 Array-Paare addiert, um 16-Bit-Daten zu erhalten. Holen Sie sich 32-Bit-Daten und fügen Sie schließlich eine Konstante zu VPADDD hinzu. Diese drei Funktionen können eine AVX512_VNNI bilden. Diese Anweisung kann verwendet werden, um die Matrixmultiplikation in der Inferenz zu beschleunigen. Graph-Fusion Darüber hinaus bietet Custom Backend auch Graph-Fusion. Beispielsweise wird nach der Matrixmultiplikation der temporäre Zwischentensor nicht ausgegeben, sondern die nachfolgenden Anweisungen werden direkt ausgeführt, also der Beitrag Der letztere Begriff wird mit dem vorherigen Operator verschmolzen, wodurch die Datenbewegung und damit die Laufzeit verkürzt werden. Die folgende Abbildung ist ein Beispiel. Nachdem der Operator im roten Feld fusioniert wurde, kann er entfernt werden ein neuer Betreiber. Graph-Fusion Speicheroptimierung Speicherzuweisung und -freigabe kommunizieren mit dem Betriebssystem, was zu einer erhöhten Laufzeitverzögerung führt. Um diesen Teil des Overheads zu reduzieren, wird ein benutzerdefiniertes Backend hinzugefügt Das Design des Primitive Cache wird geändert, um erstellte Primitive zwischenzuspeichern, sodass Primitive nicht vom System recycelt werden können, wodurch der Erstellungsaufwand für den nächsten Aufruf verringert wird. Gleichzeitig wurde ein Cache-Mechanismus für zeitaufwändige Operatoren eingerichtet, um den Betrieb der Operatoren zu beschleunigen, wie in der folgenden Abbildung dargestellt: Primitive Cache Wie bereits erwähnt , die Modellgröße Nach der Reduzierung werden der Berechnungs- und Zugriffsaufwand erheblich reduziert, was zu einer enormen Leistungsverbesserung führt. Wir haben zwei typische Modellstrukturen im Adresssuchdienst ausgewählt, um die Wirkung der oben genannten Optimierungslösung zu überprüfen. Die Testumgebung ist wie folgt: 4.1. ESIM ESIM[6 ] Es handelt sich um eine erweiterte Version von LSTM, die für die Inferenz in natürlicher Sprache entwickelt wurde. Der Inferenzaufwand ergibt sich hauptsächlich aus der LSTM-Struktur im Modell. Blade nutzt den vom Intel-Rechenzentrumssoftwareteam entwickelten „Hochleistungs-Allzweck-LSTM-Operator“, um ihn zu beschleunigen, und ersetzt den Standard-LSTM (Baseline) im PyTorch-Modul. Die diesmal getestete ESIM enthält zwei LSTM -Strukturen. Optimierte RT Beschleunigung LSTM - A 7x200 0,199 ms 0,066 ms +3,02x 202x200 0,914ms. 0,307 ms +2,98x LSTM - B 70x50 0,266 ms 0,098 ms +2,71x 202x50 0,804ms 0,209 ms +3,85x LSTM-Einzeloperator-Inferenzleistung vor und nach der Optimierung Vor und nach der Optimierung ist die ESIM-End-to-End-Inferenzgeschwindigkeit wie in der Tabelle gezeigt, während die Genauigkeit des Modells vor und nach der Optimierung erhalten bleibt unverändert. Modellstruktur ESIM[6] ESIM[6]+Blade-Operator. Optimieren Geschwindigkeit RT 6,3 ms 3,4 ms +1,85x ESIM-Modellinferenzleistung vor und nach der Optimierung 4.2 BERT BERT [7] wurde in den letzten Jahren in der Verarbeitung natürlicher Sprache (NLP), Computer Vision (CV) und anderen Bereichen weit verbreitet. Blade verfügt für diese Struktur über verschiedene Methoden wie Kompilierungsoptimierung (FP32) und Quantisierung (INT8). Im Geschwindigkeitstest ist die Form der Testdaten auf 10x53 festgelegt. Die Geschwindigkeitsleistung verschiedener Backends und verschiedener Optimierungsmethoden ist in der folgenden Tabelle dargestellt. Es ist ersichtlich, dass die Modellinferenzgeschwindigkeit nach der Blade-Kompilierung und -Optimierung oder nach der INT8-Quantisierung besser ist als bei libtorch und onnxruntime, wo das Backend der Inferenz Intel Custom Backend & BladeDisc ist. Es ist erwähnenswert, dass die Geschwindigkeit des 4-Schicht-BERT nach der quantitativen Beschleunigung das 1,5-fache der Geschwindigkeit des 2-Schicht-BERT beträgt, was bedeutet, dass das Unternehmen bei gleichzeitiger Beschleunigung ein größeres Modell verwenden und eine bessere Geschäftsgenauigkeit erzielen kann. Anzeige der Adress-BERT-Inferenzleistung In Bezug auf die Genauigkeit demonstrieren wir die entsprechende Modellleistung basierend auf der chinesischen NLP-Adresskorrelationsaufgabe CCKS2021 [5], wie in der folgenden Tabelle dargestellt. Die Genauigkeit des vom Adressteam der DAMO Academy selbst entwickelten 4-Schicht-BERT-Makros F1 ist höher als die der standardmäßigen 12-Schicht-BERT-Basis. Durch die Optimierung der Blade-Kompilierung kann eine verlustfreie Genauigkeit erreicht werden, und die Genauigkeit des real quantisierten Modells nach dem Quantisierungstraining mit Blade-Komprimierung ist etwas höher als die des ursprünglichen Gleitkommamodells. Modellstruktur Makro F1 (je höher desto besser) 12- Schicht BERT-Basis 77,24 Adress-4-Schicht-BERT 78,72(+1,48) Adress-4-Schicht-BERT + Blade-Optimierung 78,72( +1,48) Adresse – 4-Schicht-BERT + Blade-Quantisierung 78,85 (+1,61) Adressieren Sie BERT-bezogene Genauigkeitsergebnisse
2. Einführung in die Adressstandardisierung
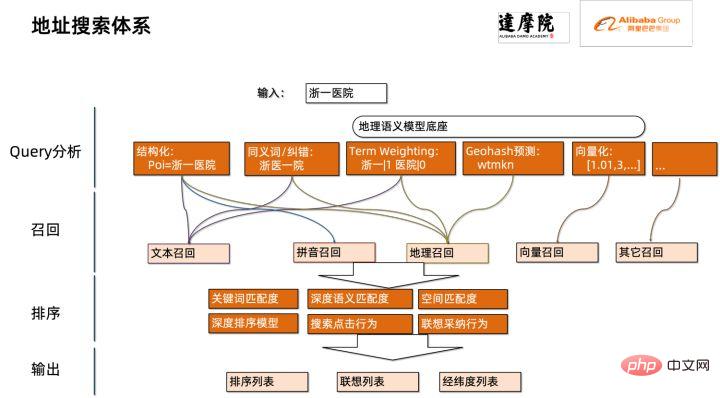
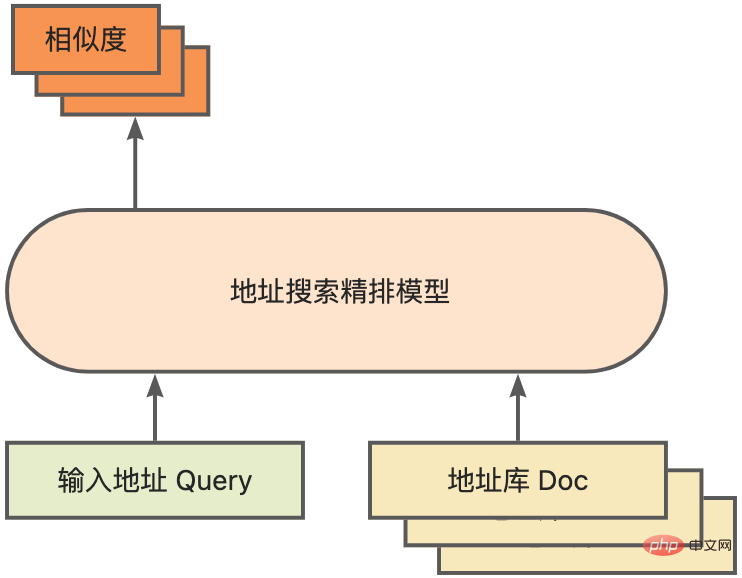
3. Lösung zur Modellinferenzoptimierung
 PAI-Blade unterstützt mehrere Eingabeformate, einschließlich Tensorflow pb, PyTorch Torchscript usw. Für das zu optimierende Modell analysiert PAI-Blade es, wendet dann verschiedene mögliche Optimierungsmethoden an und wählt aus verschiedenen Optimierungsergebnissen diejenige mit dem offensichtlichsten Beschleunigungseffekt als endgültiges Optimierungsergebnis aus.
PAI-Blade unterstützt mehrere Eingabeformate, einschließlich Tensorflow pb, PyTorch Torchscript usw. Für das zu optimierende Modell analysiert PAI-Blade es, wendet dann verschiedene mögliche Optimierungsmethoden an und wählt aus verschiedenen Optimierungsergebnissen diejenige mit dem offensichtlichsten Beschleunigungseffekt als endgültiges Optimierungsergebnis aus. 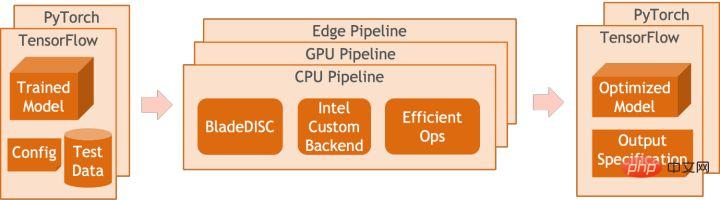
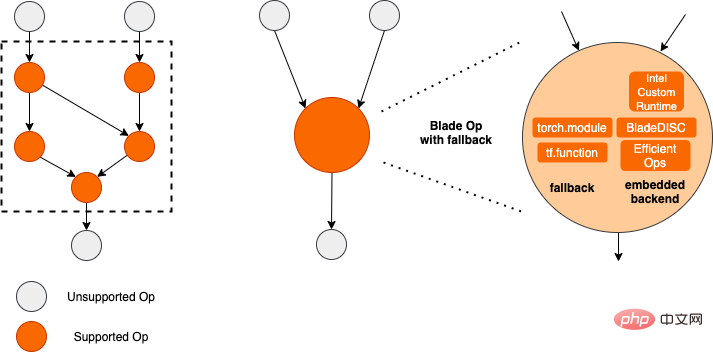
höhere Quantifizierungsgenauigkeit



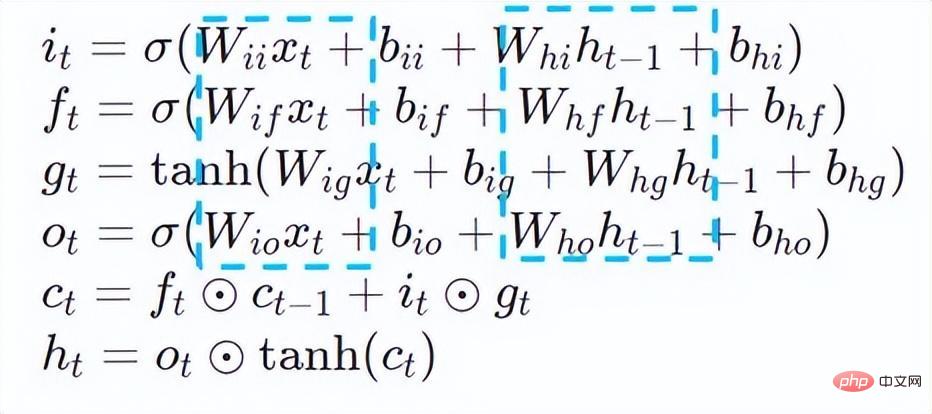
4. Gesamtleistungsanzeige
RT vor der Optimierung
Das obige ist der detaillierte Inhalt vonBefassen Sie sich mit der Praxis der AI-Deep-Learning-Modell-Inferenzoptimierung im Standardisierungsdienst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr