
Heim >Technologie-Peripheriegeräte >KI >Praktische Übung zum Entscheidungsbaum für maschinelles Lernen
Praktische Übung zum Entscheidungsbaum für maschinelles Lernen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-11 19:16:011111Durchsuche
Übersetzer |. Zhu Xianzhong
Rezensent |. Sun Shujuan
Entscheidungsfindung im maschinellen Lernen Baum
Moderne Algorithmen für maschinelles Lernen verändern unser tägliches Leben. Große Sprachmodelle wie BERT unterstützen beispielsweise die Google-Suche und GPT-3 unterstützt viele Hochsprachenanwendungen.
Andererseits ist die Erstellung komplexer Algorithmen für maschinelles Lernen heute viel einfacher als je zuvor. Unabhängig davon, wie komplex ein Algorithmus für maschinelles Lernen auch sein mag, fallen sie alle in eine der folgenden Lernkategorien: Unüberwachtes Lernen
- Tatsächlich Entscheidung Tree ist einer der ältesten überwachten Algorithmen für maschinelles Lernen und kann eine Vielzahl realer Probleme lösen. Untersuchungen zeigen, dass die früheste Erfindung des Entscheidungsbaumalgorithmus auf das Jahr 1963 zurückgeht.
- Lassen Sie uns als Nächstes in die Details dieses Algorithmus eintauchen und sehen, warum dieser Algorithmustyp auch heute noch so beliebt ist.
- Was ist ein Entscheidungsbaum? Der Entscheidungsbaumalgorithmus ist ein beliebter überwachter Algorithmus für maschinelles Lernen, da er eine relativ einfache Möglichkeit bietet, mit komplexen Datensätzen umzugehen. Entscheidungsbäume haben ihren Namen aufgrund ihrer Ähnlichkeit mit der Struktur eines Baumes; eine Baumstruktur besteht aus mehreren Komponenten wie Wurzeln, Zweigen und Blättern in Form von Knoten und Kanten. Sie werden für die Entscheidungsanalyse verwendet, ähnlich wie ein Wenn-Sonst-basiertes Entscheidungsflussdiagramm, in dem Entscheidungen zu den gewünschten Vorhersagen führen. Entscheidungsbäume können diese If-Else-Entscheidungsregeln lernen, um den Datensatz aufzuteilen und schließlich ein baumartiges Datenmodell zu generieren.
- Entscheidungsbäume wurden bei der Vorhersage diskreter Ergebnisse für Klassifizierungsprobleme und der Vorhersage kontinuierlicher numerischer Ergebnisse für Regressionsprobleme angewendet. Im Laufe der Jahre haben Wissenschaftler viele verschiedene Algorithmen wie CART, C4.5 und Ensemble-Algorithmen wie Random Forests und Gradient Boosted Trees entwickelt.
Analyse der verschiedenen Komponenten des Entscheidungsbaums
Das Ziel der Entscheidung Der Baumalgorithmus ist die Vorhersage der Ergebnisse des Eingabedatensatzes. Der Baumdatensatz ist in drei Formen unterteilt: Attribute, Attributwerte und vorherzusagende Typen. Wie bei jedem überwachten Lernalgorithmus ist der Datensatz in zwei Typen unterteilt: Trainingssatz und Testsatz. Unter anderem definiert der Trainingssatz die Entscheidungsregeln, die der Algorithmus lernt und auf den Testsatz anwendet.Bevor wir die Schritte des Entscheidungsbaumalgorithmus zusammenfassen, wollen wir zunächst die Komponenten des Entscheidungsbaums verstehen:
Wurzelknoten: Es ist der Startknoten oben im Entscheidungsbaum und enthält alle Attributwerte. Der Wurzelknoten wird basierend auf den vom Algorithmus gelernten Entscheidungsregeln in Entscheidungsknoten unterteilt.
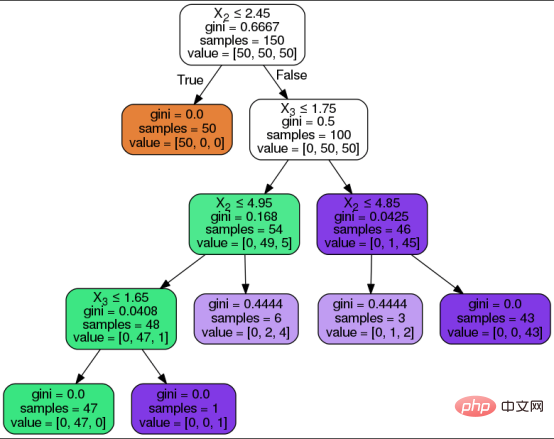
Entscheidungsknoten/Interner Knoten: Der interne Knoten ist der Entscheidungsknoten zwischen dem Wurzelknoten und dem Blattknoten, entsprechend der Entscheidungsregel und ihrem Antwortpfad. Knoten stellen Fragen dar und Zweige zeigen Pfade zu relevanten Antworten auf der Grundlage dieser Fragen.
Blattknoten: Blattknoten ist der Endknoten, der die Zielvorhersage darstellt. Diese Knoten werden nicht weiter aufgeteilt.
- Das Folgende ist eine visuelle Darstellung eines Entscheidungsbaums und seiner oben genannten Komponenten. Der Entscheidungsbaumalgorithmus durchläuft die folgenden Schritte, um die gewünschte Vorhersage zu erzielen: # 🎜🎜#
- Der Algorithmus beginnt am Wurzelknoten mit allen Attributwerten.
- Der Wurzelknoten ist basierend auf den Entscheidungsregeln, die der Algorithmus aus dem Trainingssatz gelernt hat, in Entscheidungsknoten unterteilt.
- Leiten Sie interne Entscheidungsknoten basierend auf der Frage und ihrem Antwortpfad durch Zweige/Kanten.
Fahren Sie mit den vorherigen Schritten fort, bis Sie einen Blattknoten erreichen oder alle Attribute verwendet werden.
- Um das beste Attribut auf jedem Knoten auszuwählen, basiert die Aufteilung auf einer der folgenden beiden Attributauswahlmetriken: # 🎜🎜#
- GINI-KOEFFIZIENT (Gini-Index) misst die Gini-Verunreinigung (Gini-Verunreinigung), um die Wahrscheinlichkeit anzuzeigen, dass ein Algorithmus eine zufällige Klassenbezeichnung falsch klassifiziert.
- InformationsgewinnMisst die Verbesserung der Entropie nach der Segmentierung, um die Vorhersage von Klassen zu vermeiden 50/50 geteilt. Entropie ist ein mathematisches Maß für die Verunreinigung in einer bestimmten Datenprobe. Chaoszustand im Entscheidungsbaum liegt nahe bei 50/50 durch 🎜#divide#🎜 🎜# bedeutet. Blumenklassifizierungsfall mit EntscheidungsbaumalgorithmusNachdem wir die oben genannten Grundkenntnisse verstanden haben, beginnen wir mit der Implementierung. Ein Anwendungsfall. In diesem Artikel implementieren wir mithilfe der Scikit Learning-Bibliothek ein Entscheidungsbaumklassifizierungsmodell in Python.
Der Datensatz für dieses Tutorial ist ein Irisblütendatensatz. Dieser Datensatz ist bereits in die Scikit-Open-Source-Bibliothek integriert, sodass Entwickler ihn nicht extern laden müssen. Dieser Datensatz umfasst insgesamt vier Irisattribute und entsprechende Attributwerte, die in das Modell eingegeben werden, um eine von drei Arten von Irisblüten vorherzusagen.
Attribute/Merkmale im Datensatz: Kelchblattlänge, Kelchblattbreite, Blütenblattlänge, Blütenblattbreite.Vorhergesagte Tags/Blumentypen im Datensatz: Setosis, Versicolor, Virginica.
- Als nächstes wird eine schrittweise Codebeschreibung des Entscheidungsbaumklassifikators basierend auf der Python-Sprache gegeben.
- Bibliothek importieren
Importieren Sie zunächst die Bibliotheken, die zum Implementieren des Entscheidungsbaums erforderlich sind, über den folgenden Codeabschnitt.
import pandas as pd import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier
Laden des Iris-DatensatzesDer folgende Code zeigt die Verwendung der Funktion „load_iris“ zum Laden des in der Variablen „data_set“ gespeicherten sklearn.datasets Iris-Datensatz in der Bibliothek. Die nächsten beiden Codezeilen drucken den Iristyp und die charakteristischen Informationen.
data_set = load_iris() print('Iris plant classes to predict: ', data_set.target_names) print('Four features of iris plant: ', data_set.feature_names)Attribute und Tags trennen
Die folgenden Codezeilen implementieren die Blume Separate Attribut- und Typinformationen und speichern sie in entsprechenden Variablen. Unter diesen ist die Funktion „Shape[0]“ dafür verantwortlich, die Anzahl der in der Variablen X_att gespeicherten Attribute zu bestimmen. Die Gesamtzahl der Attributwerte im Datensatz beträgt 150.
#提取花的特性和类型信息 X_att = data_set.data y_label = data_set.target print('数据集中总的样本数:', X_att.shape[0])Tatsächlich können wir auch eine visuelle Tabelle erstellen, um einen Teil der Attributwerte im Datensatz anzuzeigen, indem wir den Wert in der Variablen X_att hinzufügen zum DataFrame in der Panda-Bibliothek Nur in der Funktion.
data_view=pd.DataFrame({ 'sepal length':X_att[:,0], 'sepal width':X_att[:,1], 'petal length':X_att[:,2], 'petal width':X_att[:,3], 'species':y_label }) data_view.head()Datensatz aufteilenDer folgende Code zeigt die Verwendung der Funktion train_test_split, um den Datensatz in zwei Teile aufzuteilen: einen Trainingssatz und ein Testset. Unter anderem wird der Parameter random_state in dieser Funktion verwendet, um einen zufälligen Startwert für die Funktion bereitzustellen, um bei jeder Ausführung die gleichen Ergebnisse für den angegebenen Datensatz bereitzustellen. test_size gibt die Größe des Testsatzes an macht nach der Aufteilung 25 % aus. Trainingsdaten machen 75 % aus.
#数据集拆分为训练集和测试集两部分 X_att_train, X_att_test, y_label_train, y_label_test = train_test_split(X_att, y_label, random_state = 42, test_size = 0.25)
Wenden Sie die Entscheidungsbaumklassifizierungsfunktion an. DecisionTreeClassifier-Funktion #
Klassifizierungsmodellum 一
Entscheidungsbaum zu realisieren,
#🎜🎜 # KategorieDie Standardeinstellung ist „Entropie“ Weg . Der Standard ermöglicht , die Attributauswahlmetrik auf (Informationsgewinn) festzulegen. Der Code ordnet dann das Modell unserem Trainingssatz aus Attributen und Beschriftungen zu.
#应用决策树分类器 clf_dt = DecisionTreeClassifier(criterion = 'entropy') clf_dt.fit(X_att_train, y_label_train)
计算模型精度
下面的代码负责计算并打印决策树分类模型在训练集和测试集上的准确性。为了计算准确度分数,我们使用了predict函数。测试结果是:训练集和测试集的准确率分别为100%和94.7%。
print('Training data accuracy: ', accuracy_score(y_true=y_label_train, y_pred=clf_dt.predict(X_att_train))) print('Test data accuracy: ', accuracy_score(y_true=y_label_test, y_pred=clf_dt.predict(X_att_test)))真实世界中的决策树应用程序
当今社会,机器学习决策树在许多行业的决策过程中都得到广泛应用。其中,决策树的最常见应用首先是在金融和营销部门,例如可用于如下一些子领域:
- 贷款批准
- 支出管理
- 客户流失预测
- 新产品的可行性分析,等等。
如何改进决策树?
作为本文决策树主题讨论的总结,我们有充分的理由安全地假设:决策树的可解释性仍然很受欢迎。决策树之所以容易理解,是因为它们可以被人类以可视化方式展现并便于解释。因此,它们是解决机器学习问题的直观方法,同时也能够确保结果是可解释的。机器学习中的可解释性是我们过去讨论过的一个小话题,它也与即将到来的人工智能伦理主题存在密切联系。
与任何其他机器学习算法一样,决策树自然也可以加以改进,以避免过度拟合和出现过于偏向于优势预测类别。剪枝和ensembling技术是克服决策树算法缺点方案最常采用的方法。决策树尽管存在这些缺点,但仍然是决策分析算法的基础,并将在机器学习领域始终保持重要位置。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:An Introduction to Decision Trees for Machine Learning,作者:Stylianos Kampakis
Das obige ist der detaillierte Inhalt vonPraktische Übung zum Entscheidungsbaum für maschinelles Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr