
Heim >Technologie-Peripheriegeräte >KI >Wang Lin von Taifan Technology: Graphdatenbank – ein neuer Weg zur kognitiven Intelligenz
Wang Lin von Taifan Technology: Graphdatenbank – ein neuer Weg zur kognitiven Intelligenz

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-11 14:37:031857Durchsuche
Gast | 🎜#organisieren|. Zhang Feng
Planung |. # 🎜🎜#Es gibt zwei relativ große Fraktionen der künstlichen Intelligenz: Rationalismus und Empirismus. Doch bei echten Industrieprodukten ergänzen sich diese beiden Fraktionen. Um mehr Kontrollierbarkeit und mehr Wissen in die Black Box dieses Modells einzuführen, ist die Anwendung von Wissensgraphen erforderlich, die symbolisches Wissen enthalten.
Vor ein paar Tagen auf der WOT Global Technology Innovation Conference, veranstaltet von 51CTO #🎜 🎜#, Dr. Wang Lin, CTO von Taifan Technology, brachte den Teilnehmern die Entwicklung des Themas „Graph Database: A New Path to Cognitive Intelligence“ näher und konzentrierte sich dabei auf die Geschichte und Entwicklung des Graphen Datenbankmodell; Eine wichtige Möglichkeit für Graphdatenbanken, kognitive Intelligenz sowie das Design von Graphdatenbanken und praktische Erfahrungen mit OpenGauss zu realisieren.
Der Vortragsinhalt ist nun wie folgt gegliedert, ich hoffe, er wird Sie inspirieren:
Der andere Typ istSymbolismus, der normalerweise den menschlichen Geist simuliert. Kognitive Prozesse sind Operationen an symbolischen Darstellungen. Daher wird es oft zum Nachdenken und Argumentieren verwendet. Eine typische repräsentative Technologie ist der Wissensgraph.
4 Möglichkeiten zur Verbesserung der KI#🎜🎜 #1 . Situative Entscheidungsfindung
Wissensgraph ist im Wesentlichen ein graphbasiertes semantisches Netzwerk, das Entitäten und Beziehungen zwischen Entitäten darstellt. Auf einer höheren Ebene ist ein Wissensgraph auch eine Sammlung miteinander verknüpften Wissens, das die reale Welt und die Beziehungen zwischen Entitäten und Dingen in einer für Menschen verständlichen Form beschreibt.
Knowledge Graph kann uns mehr Fachwissen und Kontextinformationen liefern, die uns bei der Entscheidungsfindung helfen. Aus Anwendungssicht können Wissensgraphen in drei Typen unterteilt werden:Die erste ist die 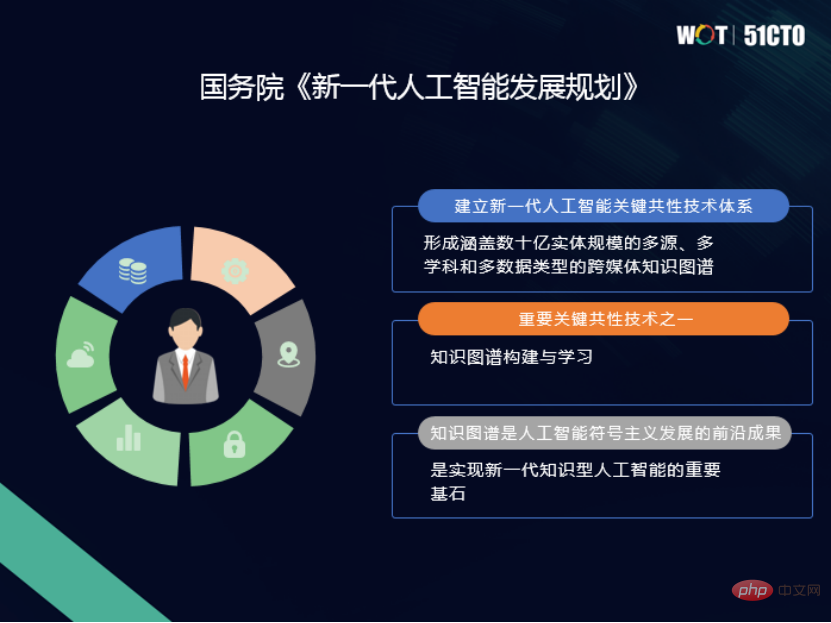 domänenbezogene Wissenslandkarte.
domänenbezogene Wissenslandkarte.
Das zweite ist
Wissensdiagramm zur externen Wahrnehmung. Aggregieren Sie externe Datenquellen und ordnen Sie sie internen relevanten Einheiten zu. Eine typische Anwendung ist die Risikoanalyse der Lieferkette. Über die Lieferkette können Sie Informationen über Lieferanten, deren vor- und nachgelagerte Lieferketten, Fabriken und andere Lieferketten einsehen, sodass Sie analysieren können, wo es Probleme gibt und ob Unterbrechungsrisiken bestehen.
Der dritte ist
Natural Language Processing Knowledge Graph. Die Verarbeitung natürlicher Sprache umfasst eine große Anzahl technischer Begriffe und sogar Schlüsselwörter in diesem Bereich, die uns bei Abfragen in natürlicher Sprache helfen können.
2. Verbessern Sie die Betriebseffizienz
Darüber hinaus müssen maschinelle Lernalgorithmen häufig auf allen Daten berechnet werden. Durch eine einfache Diagrammabfrage können Sie den Teilgraphen der erforderlichen Daten zurückgeben und so die Betriebseffizienz beschleunigen. 3. Verbessern Sie die Vorhersagegenauigkeit Diagramm erhalten.
Durch die Verknüpfung von Daten und Beziehungsdiagrammen können die Merkmale von Beziehungen direkter extrahiert werden. Doch bei traditionellen Methoden des maschinellen Lernens gehen beim Abstrahieren und Vereinfachen von Daten manchmal tatsächlich viele wichtige Informationen verloren. Daher ermöglichen uns relationale Eigenschaften eine Analyse, ohne diese Informationen zu verlieren. Darüber hinaus vereinfachen Diagrammalgorithmen den Prozess der Erkennung von Anomalien wie engen Gemeinschaften. Wir können Knoten innerhalb enger Communities bewerten und diese Informationen extrahieren, um sie beim Training von Modellen für maschinelles Lernen zu verwenden. Abschließend erfolgt die Merkmalsauswahl mithilfe von Diagrammalgorithmen, um die Anzahl der im Modell verwendeten Merkmale auf eine möglichst relevante Teilmenge zu reduzieren.
4. Erklärbarkeit
In den letzten Jahren haben wir oft von „Erklärbarkeit“ gehört, was auch der Prozess der Anwendung künstlicher Intelligenz ist. Eine besonders große Herausforderung besteht darin, dass wir verstehen müssen, wie künstliche Intelligenz zu dieser Entscheidung und diesem Ergebnis gelangt. Gleichzeitig gibt es viele Anforderungen an die Erklärbarkeit, insbesondere in einigen spezifischen Anwendungsbereichen wie Medizin, Finanzen und Justiz.
Interpretierbarkeit umfasst drei Aspekte:
(1) Interpretierbarkeit Die Daten von #🎜 🎜#. Wir müssen wissen, warum die Daten ausgewählt wurden und woher die Daten stammen. Daten müssen interpretierbar sein.
(2) Interpretierbare Vorhersage . Interpretierbare Vorhersagen bedeuten, dass wir wissen müssen, welche Merkmale verwendet werden und welche Gewichte für eine bestimmte Vorhersage verwendet werden.
(3) Interpretierbarer Algorithmus . Die aktuellen Aussichten für erklärbare Algorithmen sind sehr attraktiv, aber es gibt noch einen langen Weg, der derzeit im Forschungsbereich vorgeschlagen wird, und solche Methoden können verwendet werden, um Algorithmen eine gewisse Interpretierbarkeit zu verleihen.
Da Grafiken für die Anwendung und Entwicklung so wichtig sind der künstlichen Intelligenz, wie können wir sie also sinnvoll nutzen? Das erste, worauf Sie achten müssen, ist die Speicherverwaltung des Diagramms, bei der es sich um das Diagrammdatenmodell handelt.
Es gibt derzeit zwei gängigste Diagrammdatenmodelle: RDF-Diagramm und Attributdiagramm.
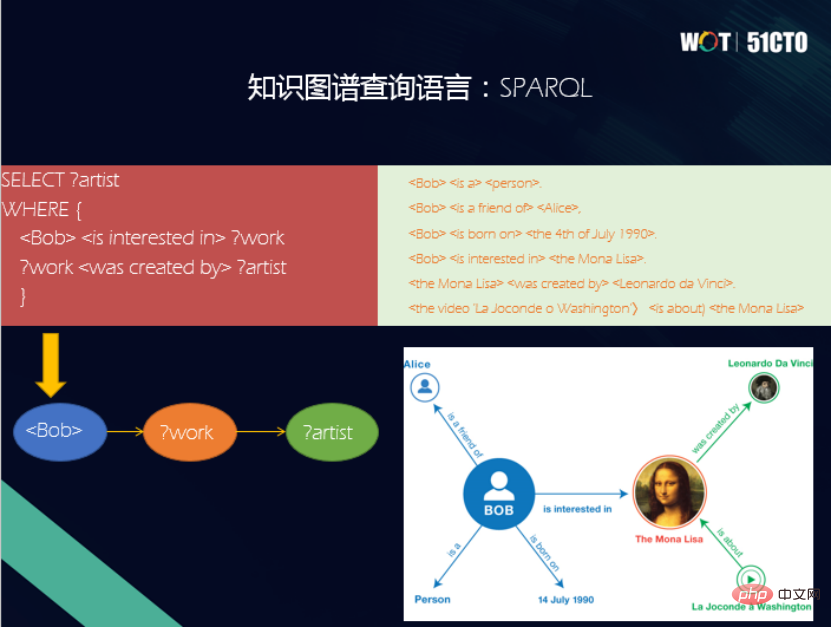
1. RDF-DiagrammRDF steht für Resource Description Framework. Es wird vom W3C formuliert und dient zur Darstellung der Austauschfähigkeiten von Maschinen im Semantic World Wide Web. Ein Standarddatenmodell zum Verständnis von Informationen. In einem RDF-Diagramm verfügt jede Ressource über eine HTTP-URL als eine ihrer eindeutigen IDs. Die RDF-Definition hat die Form eines Tripletts und stellt eine Tatsachenfeststellung dar, wobei S das Subjekt, P das Prädikat und O das Objekt darstellt. Auf dem Bild interessiert sich Bob für The MonoLisa und weist darauf hin, dass es sich um ein RDF-Diagramm handelt.

Das dem RDF-Diagramm entsprechende Datenmodell hat seine eigenen eigene Abfragesprache - SPARQL. SPARQL ist die vom W3C entwickelte Standardabfragesprache für RDF-Wissensgraphen. SPARQL lehnt sich in seiner Syntax an SQL an und ist eine deklarative Abfragesprache. Die Grundeinheit der Abfrage ist ebenfalls ein Triplettmuster.
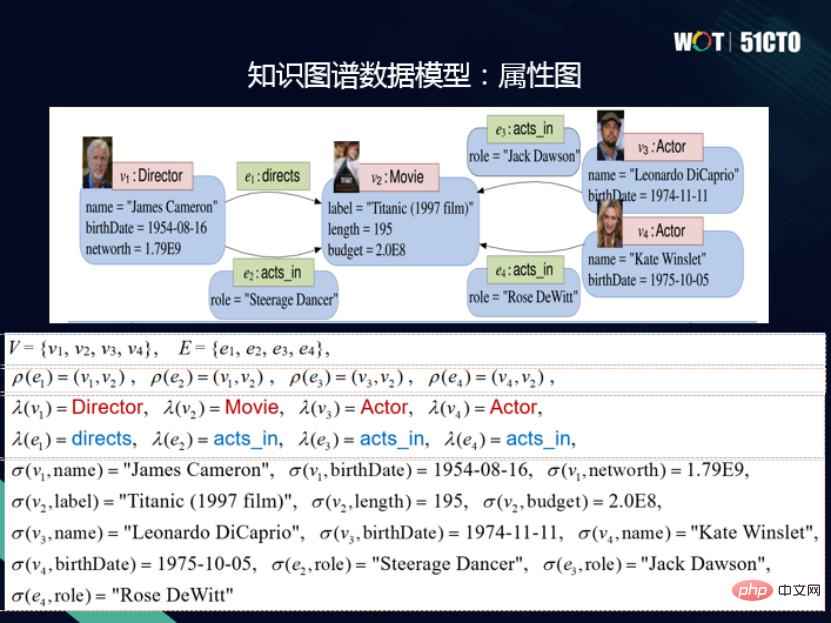
Jeder Scheitelpunkt und jede Kante im Attributdiagramm modellieren Es hat eine eindeutige ID, und die Scheitelpunkte und Kanten haben auch eine Beschriftung, die dem Ressourcentyp im RDF-Diagramm entspricht. Darüber hinaus verfügen Scheitelpunkte und Kanten über eine Reihe von Attributen, die aus Attributnamen und Attributwerten bestehen und so ein Attributdiagrammmodell bilden.
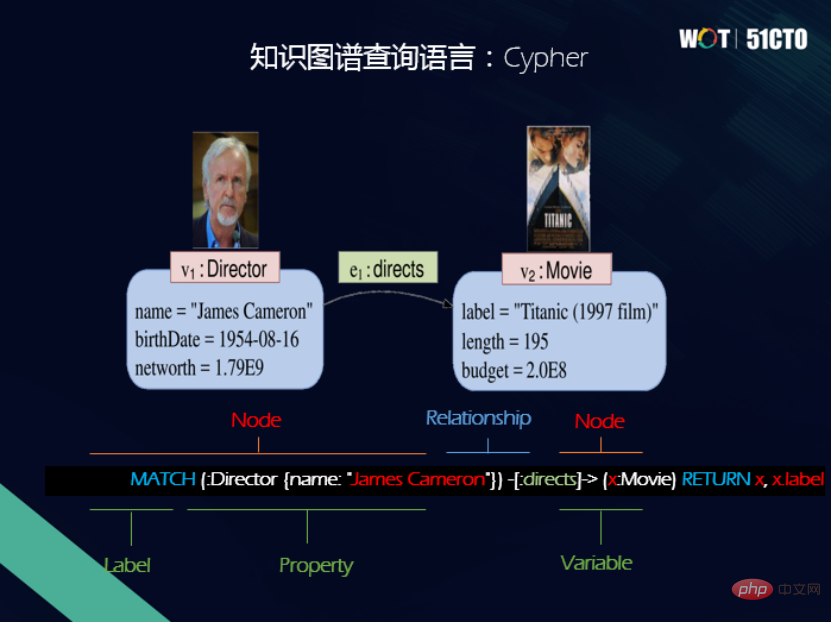
Das gleiche Attributdiagrammmodell verfügt auch über eine Abfragesprache — —Chiffre. Cypher ist ebenfalls eine deklarative Abfragesprache. Benutzer müssen nur angeben, was sie suchen möchten, und müssen nicht angeben, wie sie suchen möchten. Eines der Hauptmerkmale von Cypher ist die Verwendung der künstlerischen ASCII-Syntax, um den Diagrammmustervergleich auszudrücken.
Mit der Entwicklung künstlicher Intelligenz, kognitive Intelligenz Entwicklung und die Anwendung von Wissensgraphen nehmen zu. Daher haben Diagrammdatenbanken in den letzten Jahren immer mehr Aufmerksamkeit auf dem Markt erhalten, aber ein wichtiges Problem, mit dem Diagramme derzeit konfrontiert sind, ist die Inkonsistenz zwischen Datenmodellen und Abfragesprachen, was ein dringendes Problem ist, das gelöst werden muss # 🎜 🎜#.
Die Motivation für das Studium der OpenGauss-Graphdatenbank
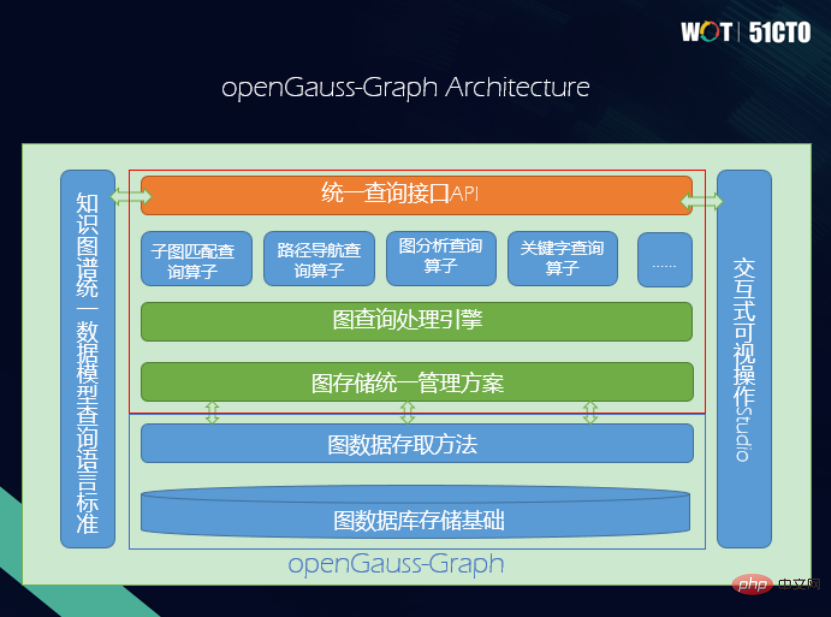
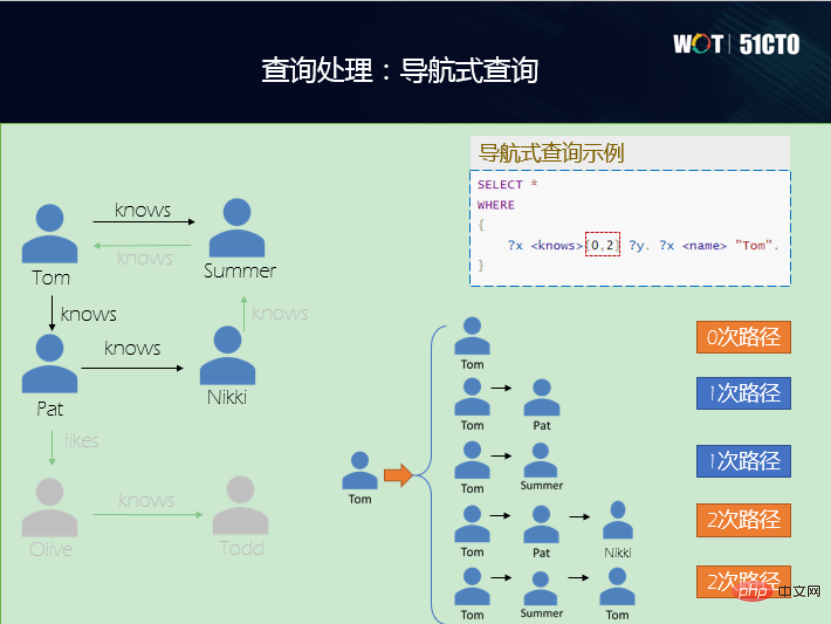
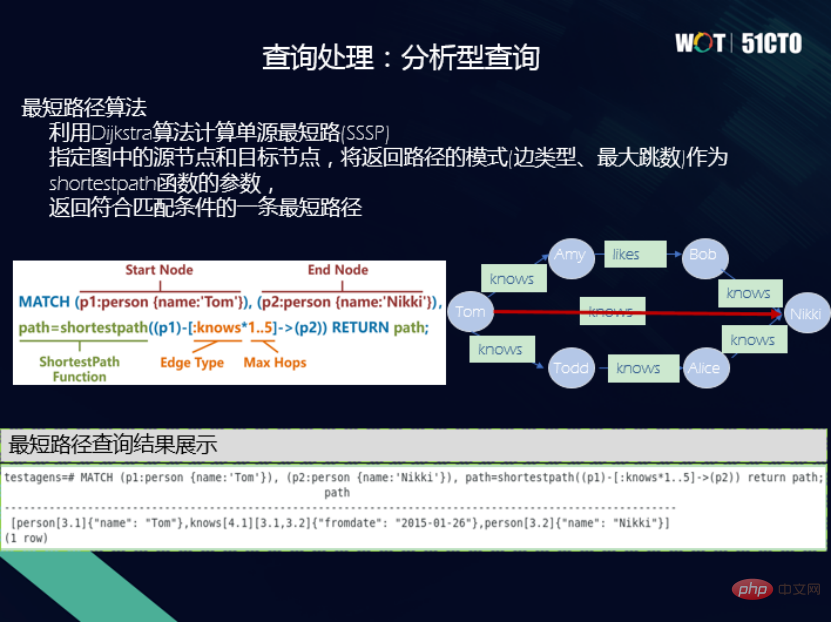
Einerseits möchte ich die Eigenschaften des Wissensgraphen selbst nutzen. Im Hinblick auf hohe Leistung, hohe Verfügbarkeit, hohe Sicherheit sowie einfache Bedienung und Wartung ist es beispielsweise für die Datenbank sehr wichtig, diese Funktionen in die Diagrammdatenbank integrieren zu können. Andererseits beginnen wir mit der Betrachtung des Diagrammdatenmodells. Derzeit gibt es zwei Datenmodelle und zwei Abfragesprachen, wenn Sie die Semantik hinter diesen beiden verschiedenen Abfragesprachen ausrichten, z. B. Projektion, Auswahl, Verknüpfung usw., wenn Sie die Semantik hinter SPARQL- und Cypher-Sprachen ausrichten zwei unterschiedliche Syntaxansichten, wodurch eine natürliche Interoperabilität erreicht wird. Das heißt, die interne Semantik kann konsistent sein, sodass Sie Cypher zum Überprüfen von RDF-Diagrammen und SPARQL auch zum Überprüfen von Attributdiagrammen verwenden können, was eine sehr gute Funktion darstellt. Die unterste Ebene verwendet OpenGauss und verwendet das relationale Modell als Diagramm zum Speichern des physischen Modells. Die Idee besteht darin, die Inkonsistenzen zwischen dem RDF-Diagramm und dem Attributdiagramm aufzulösen Speichern Sie sie physisch unten, indem Sie den größten gemeinsamen Nenner finden. Bilden Sie eine Einheit. Basierend auf dieser Idee ist die unterste Ebene der OpenGauss-Graph-Architektur die Infrastruktur, gefolgt von Zugriffsmethoden, einheitlichen Attributdiagrammen sowie RDF-Diagrammverarbeitungs- und -verwaltungsmethoden. Next ist eine einheitliche Ausführungs-Engine für die Abfrageverarbeitung, die einheitliche semantische Operatoren unterstützt, einschließlich Subgraph-Matching-Operatoren, Pfadnavigationsoperatoren, Graphanalyseoperatoren und Schlüsselwort-Abfrageoperatoren. Weiter oben befindet sich die einheitliche API-Schnittstelle, die eine SPARQL-Schnittstelle und eine Cypher-Schnittstelle bereitstellt. Darüber hinaus gibt es Sprachstandards für eine einheitliche Abfragesprache und eine visuelle Oberfläche für interaktive Abfragen. Beim Design einer Speicherlösung werden hauptsächlich die folgenden zwei Punkte berücksichtigt: (1) Es sollte nicht zu komplex sein, da die Effizienz einer Speicherlösung wichtig ist das zu komplex ist, wird nicht zu hoch sein. (2) Es muss in der Lage sein, die Datentypen von zwei verschiedenen Wissensgraphen geschickt unterzubringen. Daher gibt es eine Aufbewahrungslösung für Spitzentisch und Kantentisch. Es gibt eine gemeinsame Punkttabelle namens Eigenschaften. Für verschiedene Punkte gibt es eine Vererbung; die Kantentabelle wird auch von verschiedenen Kantentabellen geerbt. Für verschiedene Arten von Punkt- und Kantentabellen gibt es eine Kopie, wodurch eine Speicherlösung für eine Sammlung von Punkt- und Kantentabellen erhalten bleibt. Wenn es sich um ein Attributdiagramm handelt, finden Punkte mit unterschiedlichen Beschriftungen unterschiedliche Punktetabellen. Beispielsweise findet Professor die Professor-Punktetabelle. Die Attribute der Punkte werden den Attributspalten in der Punkttabelle zugeordnet. Das Gleiche gilt für die Kantentabelle. Autoren werden der Kantentabelle des Autors zugeordnet, und die Kanten werden einer Zeile in der Kantentabelle mit den IDs von zugeordnet der Startknoten und der Endknoten. Durch eine so scheinbar einfache, aber tatsächlich sehr vielseitige Methode können das RDF-Diagramm und das Attributdiagramm auf der physischen Ebene vereinheitlicht werden. In tatsächlichen Anwendungen gibt es jedoch eine große Anzahl untypisierter Entitäten. Zu diesem Zeitpunkt verwenden wir die Methode zur Klassifizierung der Semantik in der nächstgelegenen typisierten Tabelle. Neben der Speicherung ist die Abfrage das Wichtigste. Auf der semantischen Ebene haben wir Operationen angepasst und Interoperabilität zwischen zwei Abfragesprachen, SPARQL und Cypher, erreicht. In diesem Fall sind zwei Ebenen beteiligt: Grammatik und lexikalisch, und ihre Analyse kann nicht miteinander in Konflikt geraten. Wenn Sie beispielsweise SPARQL aktivieren, aktivieren Sie die Syntax von SPARQL. Wenn Sie Cypher aktivieren, aktivieren Sie die Syntax von Cypher, um Konflikte zu vermeiden. Wir haben auch viele Abfrageoperatoren implementiert. (1) Subgraph-Matching-Abfrage, die Abfrage aller Komponisten, ihrer Kompositionen und des Geburtstags des Komponisten ist ein typisches Subgraph-Matching-Problem. Es kann in Attributdiagramme und RDF-Diagramme unterteilt werden, und ihr allgemeiner Verarbeitungsablauf ist ebenfalls gleich. Beispielsweise wird der entsprechende Punkt zur Verknüpfungsliste hinzugefügt, dann wird eine Auswahloperation für die Eigenschaftenspalte hinzugefügt und dann werden Einschränkungen für die Verbindung zwischen den Punkttabellen auferlegt, die den Kopf- und Endpunktmustern entsprechen. Das RDF-Diagramm führt wichtige Operationen an den Start- und Endpunkten der Kantentabelle aus. Am Ende werden den Variablen Projektionsbeschränkungen hinzugefügt und das Endergebnis ausgegeben. Subgraph-Matching-Abfragen unterstützen auch einige integrierte Funktionen, wie z. B. die FILTER-Funktion, die Variablenformbeschränkungen, logische Operatoren, Aggregation und arithmetische Operatoren unterstützt. Natürlich kann dieser Teil auch kontinuierlich erweitert werden. (2) Navigationsabfrage, die in herkömmlichen relationalen Datenbanken nicht verfügbar ist. Die linke Seite der Abbildung unten ist ein kleines Diagramm für soziale Netzwerke. Sie können sehen, dass das Wissen, das Tom kennt, nicht stimmt. Wenn Sie in der Navigationsabfrage eine Two-Hop-Abfrage durchführen, sehen Sie, wer Tom kennt. Wenn es 0 Sprünge sind, weiß Tom es selbst. Der erste Unterschied besteht darin, dass Tom Pat kennt und Tom Summer kennt. Der zweite Sprung ist, wenn Tom zunächst Pat, dann Nikki und dann wieder Tom kennenlernt. (3) Schlüsselwortabfrage, hier sind zwei Beispiele, tsvector und tsquery. Die eine besteht darin, das Dokument in eine Liste von Begriffen umzuwandeln, die andere darin, abzufragen, ob das angegebene Wort oder die angegebene Phrase im Vektor vorhanden ist. Wenn der Text im Wissensdiagramm relativ lang ist und relativ lange Attribute aufweist, kann diese Funktion verwendet werden, um ihm eine Schlüsselwortsuchfunktion bereitzustellen, was ebenfalls sehr nützlich ist. (4) Analytische Abfragen verfügen über eigene eindeutige Abfragen für Diagrammdatenbanken, z. B. kürzester Pfad , Pagerank usw. sind alles diagrammbasierte Abfrageoperatoren, die sein können Wird verwendet in: In der Diagrammdatenbank implementiert. Um beispielsweise zu überprüfen, was der kürzeste Weg von Tom nach Nikki ist, wird der Operator für den kürzesten Weg über Cypher implementiert, und der kürzeste Weg kann ausgegeben und das Ergebnis gefunden werden. Zusätzlich zu den oben genannten Funktionen haben wir auch ein visuelles interaktives Studio implementiert, in dem Sie die Abfragesprache von Cypher und SPARQL eingeben können, um ein visuelles intuitives Diagramm zu erhalten, das oben angezeigt werden kann Für die Wartung, Verwaltung und Anwendung von Diagrammen können viele Interaktionen an Diagrammen durchgeführt werden. In Zukunft werden wir weitere Operatoren, Diagrammabfragen und Diagrammsuchen hinzufügen, um weitere Anwendungsrichtungen und -szenarien zu realisieren. Abschließend ist jeder herzlich willkommen, die OpenGauss Graph-Community zu besuchen, und auch Freunde, die sich für OpenGauss Graph interessieren, sind herzlich willkommen, der Community als neue Mitwirkende beizutreten und gemeinsam die OpenGauss Graph-Community aufzubauen. Wang Lin, Ph.D. in Ingenieurwesen, Betreuer der OpenGauss-Graphdatenbank-Community, CTO von Taifan Technology, leitender Ingenieur, stellvertretender Vorsitzender der China Computer Association YOCSEF Tianjin 21-22, Mitglied des Sonderausschusses des CCF-Informationssystems, Mitglied des Exekutivausschusses, ausgewählt in das Tianjin 131 Talent Project. OpenGauss – Diagrammarchitektur
Design einer Speicherlösung
Abfrageverarbeitungspraxis



Gastvorstellung
Das obige ist der detaillierte Inhalt vonWang Lin von Taifan Technology: Graphdatenbank – ein neuer Weg zur kognitiven Intelligenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr