
Heim >Technologie-Peripheriegeräte >KI >„Location Embedding': Das Geheimnis hinter Transformer
„Location Embedding': Das Geheimnis hinter Transformer

- 王林nach vorne
- 2023-04-10 10:01:031094Durchsuche
#🎜🎜 ## 🎜🎜#Übersetzer
|#🎜🎜 ## 🎜🎜 ## 🎜🎜#Inhaltstabelle### 🎜🎜 ## 🎜🎜 ## 🎜🎜#Einführung### Einbettung in NLP-Konzept
Erfordert verschiedene Arten von anfänglichen Versuch-und-Irrtum-Experimenten für die positionelle Einbettung in Transformers
🎜🎜#- Frequenzbasierter Standort. Einbettung
- Zusammenfassung # 🎜🎜#
- # 🎜🎜#Referenz
- Einführung
- Die Einführung des Transformers Architektur im Bereich Deep Learning hat zweifellos den Weg für eine stille Revolution geebnet. Straßen sind für Zweige des NLP besonders wichtig. Der unverzichtbarste Teil der Transformer-Architektur ist die „positionelle Einbettung“, die dem neuronalen Netzwerk die Fähigkeit verleiht, die Reihenfolge von Wörtern in langen Sätzen und die Abhängigkeiten zwischen ihnen zu verstehen. Wir wissen, dass RNN und LSTM vor Transformer eingeführt wurden und die Reihenfolge von Wörtern auch ohne Positionseinbettung verstehen können. Dann stellt sich natürlich die Frage, warum dieses Konzept in Transformer eingeführt wurde und die Vorteile dieses Konzepts so hervorgehoben werden. In diesem Artikel erläutern wir Ihnen diese Ursachen und Folgen.
- Einbettungskonzept in NLP
- Einbettung ist ein Prozess in der Verarbeitung natürlicher Sprache, der verwendet wird, um Rohtext in mathematische Vektoren umzuwandeln. Dies liegt daran, dass das Modell des maschinellen Lernens nicht in der Lage ist, das Textformat direkt zu verarbeiten und für verschiedene interne Rechenprozesse zu verwenden.
- Der Einbettungsprozess für Algorithmen wie Word2vec und Glove wird Worteinbettung oder statische Einbettung genannt.
Auf diese Weise kann ein Textkorpus mit einer großen Anzahl von Wörtern zum Training an das Modell übergeben werden. Das Modell weist jedem Wort einen entsprechenden mathematischen Wert zu und geht davon aus, dass die häufiger vorkommenden Wörter ähnlich sind. Nach diesem Vorgang werden die resultierenden mathematischen Werte für weitere Berechnungen verwendet.
Angenommen, unser Textkorpus besteht aus drei Sätzen, wie folgt:
#🎜 🎜 #Die britische Regierung zahlt jedes Jahr große Subventionen an den König und die Königin von Palermo und behauptet, eine gewisse Kontrolle über die Verwaltungsführung zu haben.
Zu den Mitgliedern der königlichen Familie gehören neben dem König und der Königin auch ihre Tochter Marie-Theresa Charlotte (Madame Royale), die Schwester des Königs, Lady Elizabeth, Footman Cleary und andere.
Dies wurde durch die Nachricht von Mordreds Verrat unterbrochen, Lancelot nahm nicht an dem letzten tödlichen Konflikt teil und überlebte sowohl den König als auch die Königin und so weiter war der Niedergang des Runden Tisches.
Hier können wir sehen, dass die beiden Wörter „König“ und „Königin“ häufig vorkommen. Daher geht das Modell davon aus, dass zwischen diesen Wörtern möglicherweise eine gewisse Ähnlichkeit besteht. Wenn diese Wörter
in mathematische Werte umgewandelt werden, werden sie bei der Darstellung in einem mehrdimensionalen Raum in geringem Abstand platziert.
- Bildquelle: Illustrationen des Autors
- Davon ausgegangen Ist ein weiteres A-Wort „Straße“, dann wird es in diesem großen Textkorpus logischerweise nicht so häufig vorkommen wie „König“ und „Königin“. Daher wäre das Wort weit entfernt von „König“ und „Königin“ und weit entfernt an einem anderen Ort im Weltraum platziert.
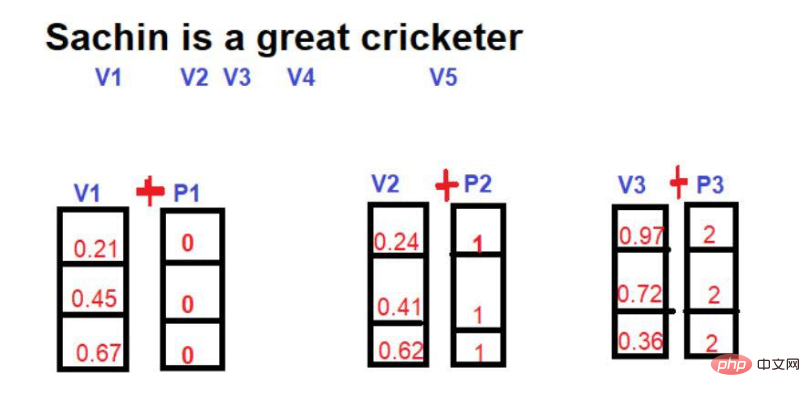
- Bildquelle: Illustrationen des Autors In der Mathematik wird ein Vektor durch eine Reihe von Zahlen dargestellt Die Zahl gibt die Größe des Wortes entlang einer bestimmten Dimension an. Zum Beispiel: Wir setzen hier
Daher wird „König“ im dreidimensionalen Raum in der Form [0,21, 0,45, 0,67] ausgedrückt. Das Wort „Königin“ kann als [0,24,0,41,0,62] ausgedrückt werden. Das Wort „Straße“ kann als [0,97,0,72,0,36] ausgedrückt werden.
Notwendigkeit einer Positionseinbettung in Transformer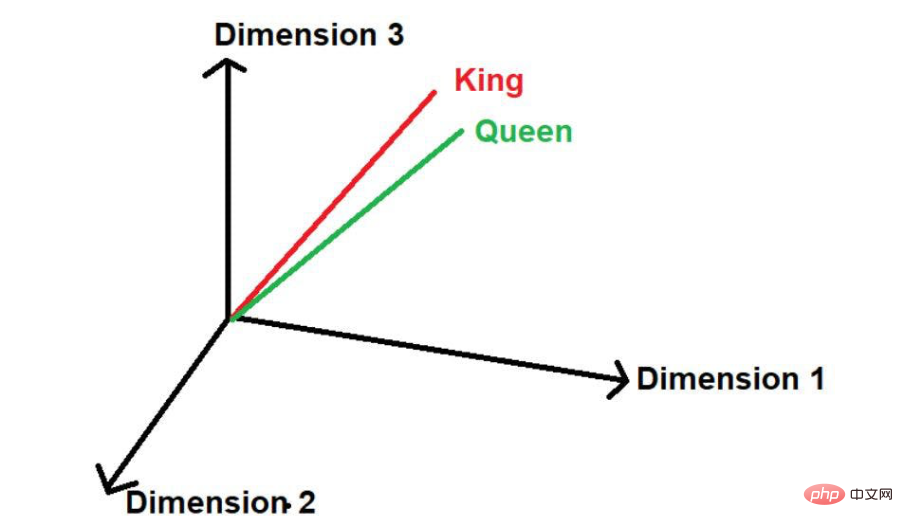
Betrachten wir zum Beispiel die folgenden Sätze:
Satz 1 – „Obwohl Sachin Tendulkar heute nicht 100 Runs erzielte, führte er das Team zum Sieg.“ Satz 2 – „Obwohl Sachin Tendulkar heute 100 Runs erzielte, gelang es ihm nicht, das Team zum Sieg zu führen.“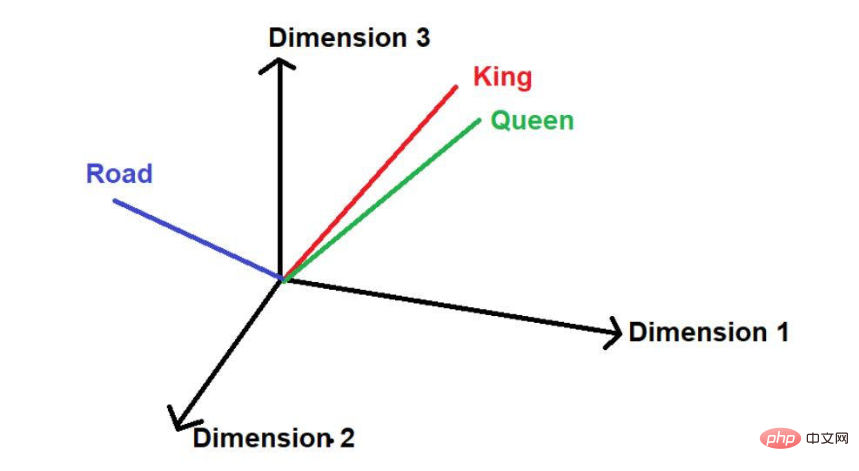 Diese beiden Sätze sehen ähnlich aus, weil sie die meisten Wörter gemeinsam haben, aber ihre zugrunde liegende Bedeutung ist sehr unterschiedlich. Die Reihenfolge und Platzierung von Wörtern wie „不“ haben den Kontext der übermittelten Nachricht verändert
Diese beiden Sätze sehen ähnlich aus, weil sie die meisten Wörter gemeinsam haben, aber ihre zugrunde liegende Bedeutung ist sehr unterschiedlich. Die Reihenfolge und Platzierung von Wörtern wie „不“ haben den Kontext der übermittelten Nachricht verändert
Daher ist es bei NLP-Projekten sehr wichtig, Standortinformationen zu verstehen. Wenn ein Modell einfach Zahlen in einem mehrdimensionalen Raum verwendet und den Kontext falsch versteht, kann dies insbesondere in Vorhersagemodellen schwerwiegende Folgen haben.
Um diese Herausforderung zu meistern, wurden neuronale Netzwerkarchitekturen wie RNN (Recurrent Neural Network) und LSTM (Long Term Short Term Memory) eingeführt. Bis zu einem gewissen Grad sind diese Architekturen beim Verstehen von Standortinformationen sehr erfolgreich. Das Hauptgeheimnis ihres Erfolgs besteht darin, lange Sätze zu lernen, indem sie die Reihenfolge der Wörter beibehalten. Darüber hinaus verfügen sie auch über Informationen zu Wörtern, die dem „interessanten Wort“ nahe kommen, und zu Wörtern, die weit vom „interessanten Wort“ entfernt sind.
Betrachten Sie zum Beispiel den folgenden Satz:
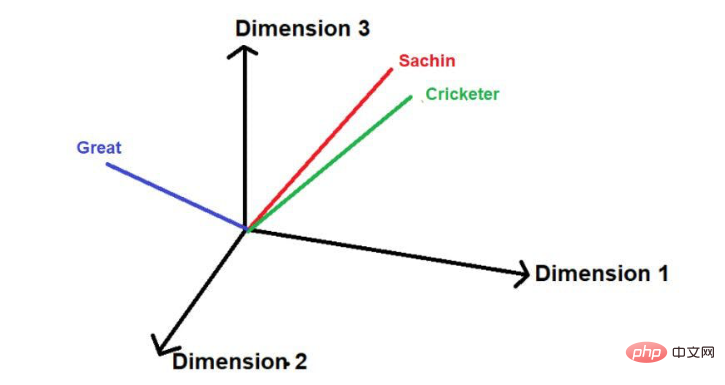
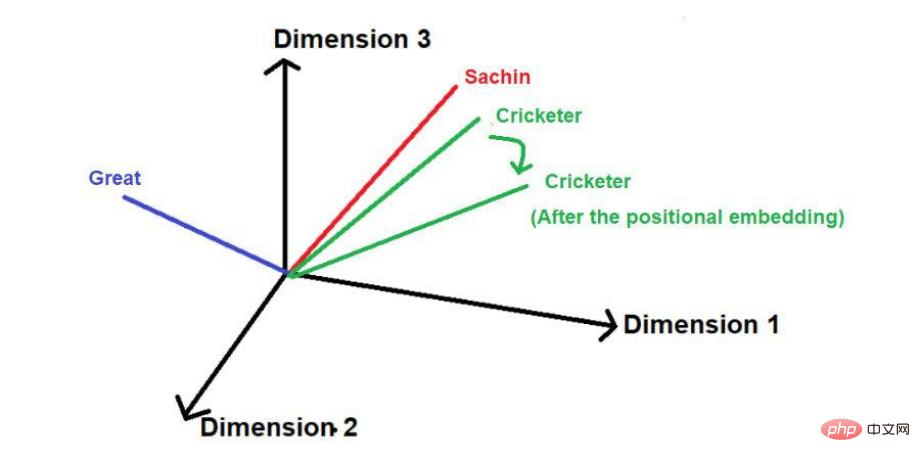
„Sachin ist der größte Cricketspieler aller Zeiten“.

Bildquelle: Illustrationen des Autors
Die rot unterstrichenen Wörter sind diese. Hier können Sie sehen, dass die „interessanten Wörter“ in der Reihenfolge des Originaltextes durchlaufen werden.
Darüber hinaus können sie auch Standortinformationen in großen Textkorpora verstehen, indem sie sich merken

Bildquelle: Illustrationen des Autors
Durch diese Techniken kann RNN/LSTM jedoch die Standortinformationen in großen Textkorpora verstehen. Das eigentliche Problem besteht jedoch darin, eine sequentielle Durchquerung von Wörtern in einem großen Textkorpus durchzuführen. Stellen Sie sich vor, wir haben einen sehr großen Textkorpus mit 1 Million Wörtern und es würde sehr lange dauern, jedes Wort der Reihe nach durchzugehen. Manchmal ist es nicht möglich, so viel Rechenzeit für das Training eines Modells aufzuwenden.
Um diese Herausforderung zu meistern, wird eine neue fortschrittliche Architektur – „Transformer“ – eingeführt.
Ein wichtiges Merkmal der Transformer-Architektur ist, dass ein Textkorpus durch die parallele Verarbeitung aller Wörter erlernt werden kann. Ob der Textkorpus 10 Wörter oder 1 Million Wörter enthält, ist der Transformer-Architektur egal.

Bildquelle: Illustration vom Autor bereitgestellt

Bildquelle: Illustration vom Autor bereitgestellt
Jetzt müssen wir uns der Herausforderung stellen, Wörter parallel zu verarbeiten. Da auf alle Wörter gleichzeitig zugegriffen wird, gehen Informationen über Abhängigkeiten zwischen Wörtern verloren. Daher kann sich das Modell die zugehörigen Informationen zu einem bestimmten Wort nicht merken und diese nicht genau speichern. Diese Frage führt uns erneut zur ursprünglichen Herausforderung, Kontextabhängigkeiten beizubehalten, obwohl die Modellberechnungs-/Trainingszeit erheblich verkürzt wird.
Wie kann man also die oben genannten Probleme lösen? Die Lösung ist
kontinuierliches Ausprobieren
Als dieses Konzept eingeführt wurde, waren die Forscher zunächst sehr daran interessiert, eine optimierte Methode zu entwickeln, mit der Positionsinformationen in der Transformer-Struktur erhalten bleiben könnten. Im Rahmen eines Trial-and-Error-Experiments wurde als erstes die Methode ausprobiert:
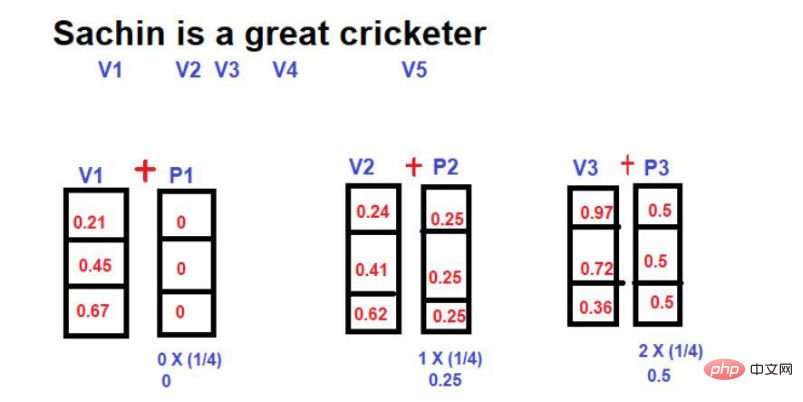
Hier besteht die Idee darin, unter Verwendung von Wortvektoren einen neuen mathematischen Vektor einzuführen, der den Index des Wortes enthält.
Bildquelle: Illustrationen des Autors
Angenommen, das folgende Bild ist die Darstellung von Wörtern in einem mehrdimensionalen Raum
Bildquelle: Illustrationen des Autors
Nach dem Hinzufügen der Position Vektor, seine Größe und Richtung können die Position jedes Wortes ändern, wie unten gezeigt.
Bildquelle: Illustrationen des Autors
Der Nachteil dieser Technik besteht darin, dass bei besonders langen Sätzen der Positionsvektor proportional zunimmt. Nehmen wir an, ein Satz besteht aus 25 Wörtern, dann wird dem ersten Wort ein Positionsvektor mit der Größe 0 hinzugefügt, und dem letzten Wort wird ein Positionsvektor mit der Größe 24 hinzugefügt. Diese enorme Unsicherheit kann zu Problemen führen, wenn wir diese Werte in höhere Dimensionen projizieren.
Eine weitere Technik zur Reduzierung von Positionsvektoren ist
Hier wird der Bruchwert jedes Wortes relativ zur Satzlänge als Größe des Positionsvektors berechnet.
Die Berechnungsformel für den Score-Wert lautet
Wert=1/N-1
wobei „N“ die Position eines bestimmten Wortes ist.
Betrachten wir zum Beispiel das folgende Beispiel –
Bildquelle: Abbildung vom Autor bereitgestellt
Bei dieser Technik kann die maximale Größe des Positionsvektors unabhängig von der Länge des Satzes auf 1 begrenzt werden. Allerdings gibt es eine große Lücke. Wenn Sie zwei Sätze unterschiedlicher Länge vergleichen, ist der Einbettungswert eines Wortes an einer bestimmten Position unterschiedlich. Ein bestimmtes Wort oder seine entsprechende Position sollte im gesamten Textkorpus den gleichen Einbettungswert haben, um das Verständnis seines Kontexts zu erleichtern. Wenn dasselbe Wort in verschiedenen Sätzen unterschiedliche Einbettungswerte hat, wird die Darstellung der Informationen eines Textkorpus in einem mehrdimensionalen Raum zu einer sehr komplexen Aufgabe. Selbst wenn ein solch komplexer Raum implementiert wird, ist es sehr wahrscheinlich, dass das Modell irgendwann aufgrund übermäßiger Informationsverzerrung zusammenbricht. Daher wurde diese Technik von der Entwicklung der positionellen Einbettung von Transformern ausgeschlossen.
Schließlich schlugen die Forscher eine Transformer-Architektur vor und erwähnten in dem berühmten Whitepaper: „Aufmerksamkeit ist alles, was Sie brauchen“. ... " ist die Position oder der Indexwert eines bestimmten Wortes in einem Satz.
„d“ ist die maximale Länge/Dimension des Vektors, der ein bestimmtes Wort im Satz darstellt.
„i“ stellt den Index der Einbettungsdimension jeder Position dar. Es bedeutet auch Häufigkeit. Wenn i=0 ist, wird davon ausgegangen, dass es sich um die höchste Häufigkeit handelt, für nachfolgende Werte wird davon ausgegangen, dass die Häufigkeit abnimmt.
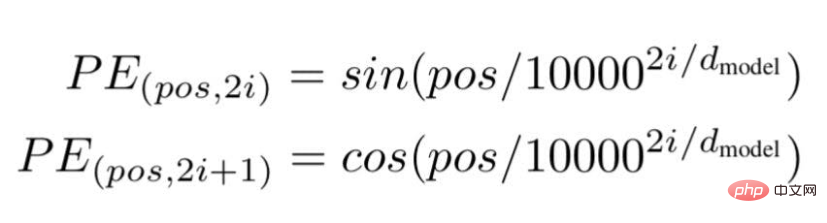
Bildquelle: Illustration vom Autor bereitgestellt
Bildquelle: Illustration vom Autor bereitgestellt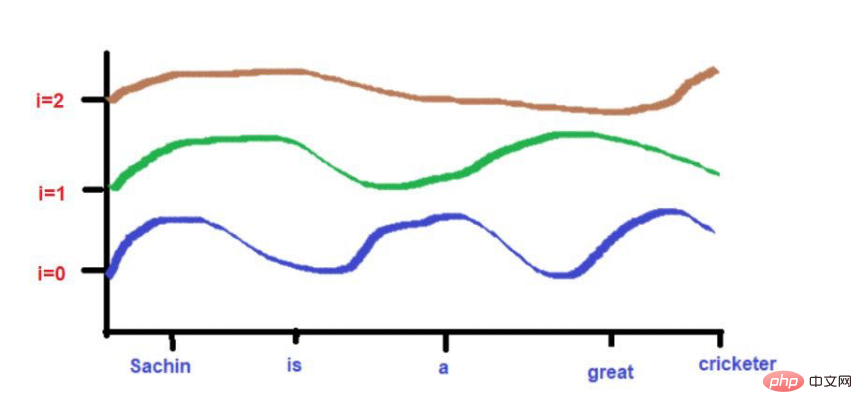
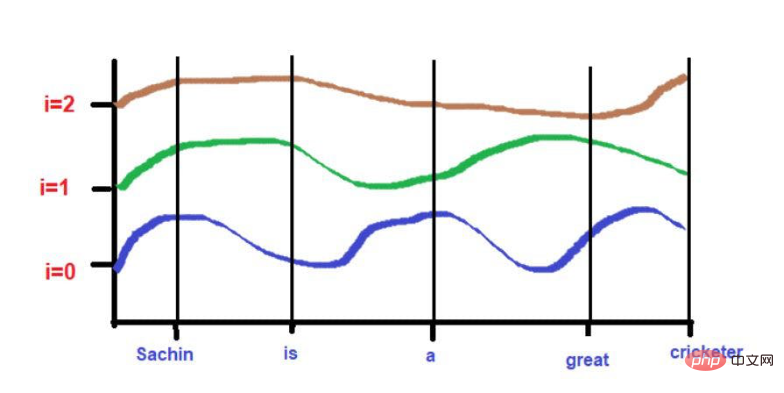 Basierend auf unserem Beispieltext – „Sachin ist ein großartiger Cricketspieler“.
Basierend auf unserem Beispieltext – „Sachin ist ein großartiger Cricketspieler“.
Für
pos = 0 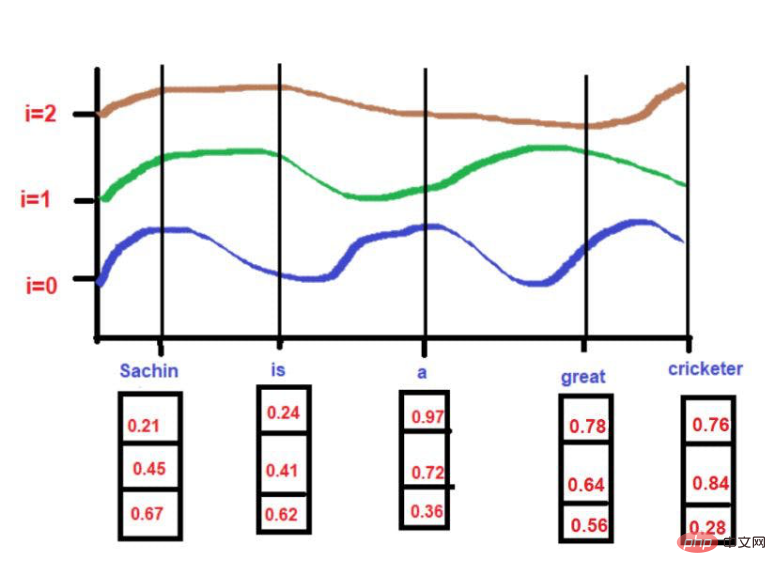
Bildquelle: Illustrationen vom Autor bereitgestellt
Wenn i =0,
PE(0,0) = sin(0/10000^2(0)/3)
PE(0,0) = sin(0)
PE(0,0) = 0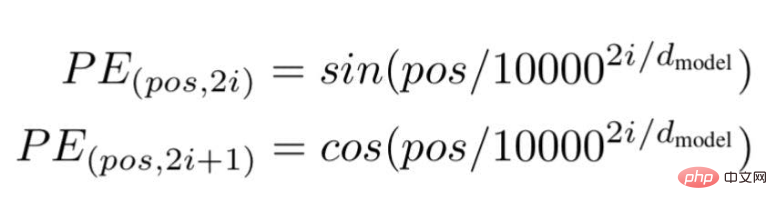
Bildquelle: Illustrationen vom Autor bereitgestellt
Wenn i =0,
PE(3,0) = sin(3/10000^2(0)/3)
PE(3,0) = sin(3/1)
PE(3,0) = 0,05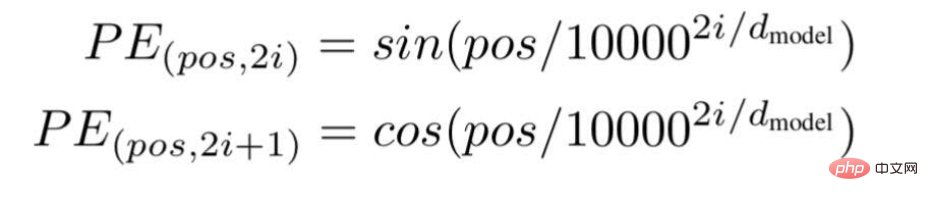
PE(3,2) = sin(3/1,4)PE(3,2) = 0,03
Bildquelle: Illustration des Autors
Hier wird der Maximalwert auf 1 begrenzt (weil wir die Sin/Cos-Funktion verwenden). Daher gibt es bei früheren Techniken keine Probleme mit Positionsvektoren großer Größe.
Darüber hinaus können Wörter, die sehr nahe beieinander liegen, bei niedrigeren Frequenzen auf ähnliche Höhen fallen, während ihre Höhen bei höheren Frequenzen etwas anders ausfallen.
Wenn der Abstand zwischen Wörtern sehr gering ist, sind ihre Höhen auch bei niedrigeren Frequenzen sehr unterschiedlich und ihre Höhenunterschiede nehmen mit der Häufigkeit zu.
Denken Sie zum Beispiel an diesen Satz: „Der König und die Königin gingen auf der Straße.“
Die Wörter „King“ und „Road“ sind weiter entfernt platziert.
Wenn man bedenkt, dass die beiden Wörter nach Anwendung der Wellenfrequenzformel ungefähr die gleiche Höhe haben. Wenn wir zu höheren Frequenzen kommen (z. B. 0), werden ihre Höhen unterschiedlicher.
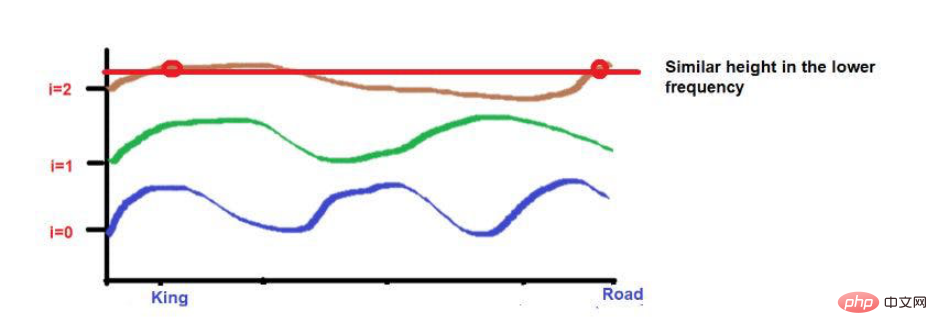
Illustrationen vom Autor bereitgestellt Illustrationen vom Autor bereitgestellt
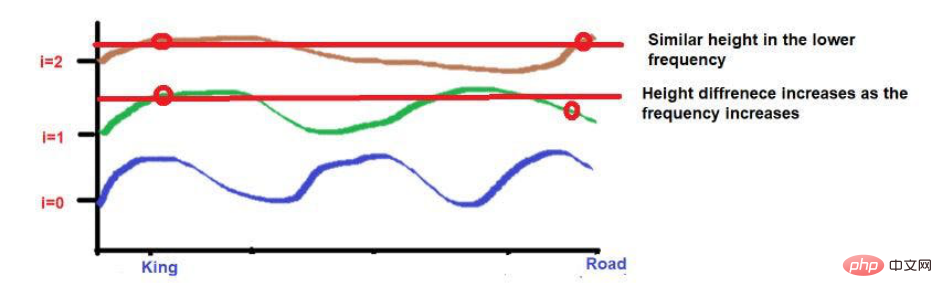
Bildquelle: Illustrationen des Autors
Und die beiden Wörter „König“ und „Königin“ sind näher beieinander platziert. 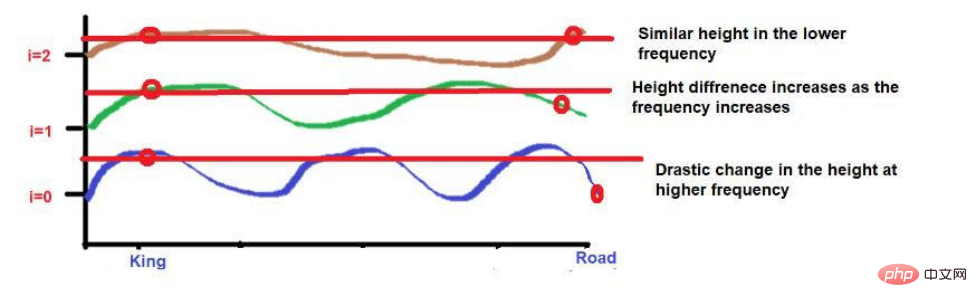
Bildquelle: Illustrationen des Autors
Aber worauf wir achten müssen, ist, dass wenn die Nähe von Diese Wörter sind niedrig, wenn man sich zu hohen Frequenzen bewegt, werden ihre Höhen sehr unterschiedlich sein. Wenn die Wörter sehr nahe beieinander liegen, gibt es nur einen kleinen Höhenunterschied, wenn Sie sich zu höheren Frequenzen bewegen. 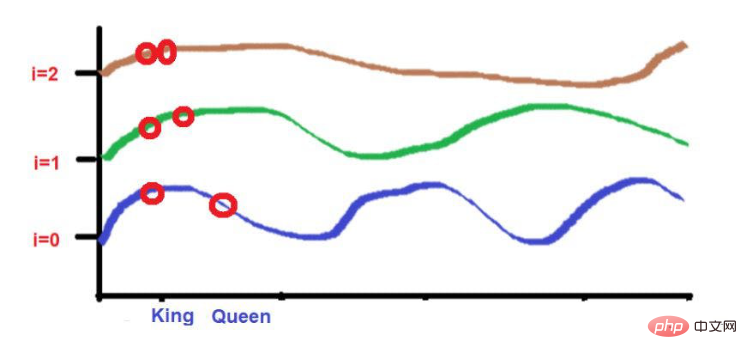
Positionale Einbettung: Das Geheimnis hinter der Genauigkeit von Transformer Neural Networks, Autor: Sanjay Kumar
Das obige ist der detaillierte Inhalt von„Location Embedding': Das Geheimnis hinter Transformer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr