
Heim >Technologie-Peripheriegeräte >KI >Wayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage
Wayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage

- PHPznach vorne
- 2023-04-09 21:31:121331Durchsuche
Das im Juli 2022 hochgeladene arXiv-Papier „Wayformer: Motion Forecasting via Simple & Efficient Attention Networks“ ist das Werk von Google Waymo.

Bewegungsvorhersage für autonomes Fahren ist eine herausfordernde Aufgabe, da komplexe Fahrszenarien zu verschiedenen Mischformen statischer und dynamischer Eingaben führen. Es ist ein ungelöstes Problem, wie sich historische Informationen über Straßengeometrie, Fahrspurkonnektivität, zeitlich variierende Ampelzustände und dynamische Gruppen von Agenten und deren Interaktionen am besten darstellen und in effizienten Kodierungen zusammenführen lassen. Um diesen vielfältigen Satz an Eingabefunktionen zu modellieren, gibt es viele Ansätze zum Entwurf gleichermaßen komplexer Systeme mit unterschiedlichen Sätzen modalitätsspezifischer Module. Dies führt zu Systemen, die schwer zu skalieren, zu skalieren oder auf strenge Weise Qualität und Effizienz abzuwägen.
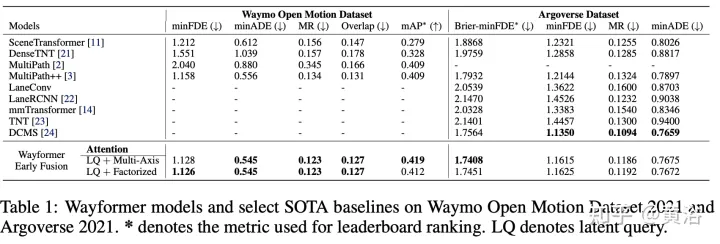
Der Wayformer in diesem Artikel ist eine Reihe einfacher und ähnlicher aufmerksamkeitsbasierter Bewegungsvorhersagearchitekturen. Wayformer bietet eine kompakte Modellbeschreibung bestehend aus aufmerksamkeitsbasierten Szenen-Encodern und -Decodern. Im Szenenencoder wird die Auswahl der Eingabemodi vor der Fusion, nach der Fusion und hierarchischen Fusion untersucht. Erkunden Sie für jeden Fusionstyp Strategien, die Effizienz und Qualität durch Zerlegungsaufmerksamkeit oder latente Abfrageaufmerksamkeit abwägen. Die Pre-Fusion-Struktur ist einfach und nicht nur modusunabhängig, sondern erzielt auch hochmoderne Ergebnisse sowohl im Waymo Open Movement Dataset (WOMD) als auch im Argoverse Leaderboard.
Fahrszenen bestehen aus multimodalen Daten wie Straßeninformationen, Ampelstatus, Agentenhistorie und Interaktionen. Für die Modalität gibt es eine Kontext4. Dimension, die den „Satz kontextueller Ziele“ für jeden modellierten Agenten darstellt (d. h. eine Darstellung anderer Verkehrsteilnehmer).
Intelligence History enthält eine Reihe vergangener Intellektzustände sowie den aktuellen Zustand. Berücksichtigen Sie für jeden Zeitschritt Merkmale, die den Zustand des Agenten definieren, wie z. B. x, y, Geschwindigkeit, Beschleunigung, Begrenzungsrahmen usw., sowie eine Kontextdimension.
Interaktionstensor repräsentiert die Beziehung zwischen Agenten. Für jeden modellierten Agenten wird eine feste Anzahl von Nächste-Nachbarn-Kontexten rund um den modellierten Agenten berücksichtigt. Diese kontextuellen Agenten stellen Agenten dar, die das Verhalten des modellierten Agenten beeinflussen.
Straßenkarte enthält Straßenmerkmale rund um den Agenten. Straßenkartensegmente werden als Polylinien dargestellt, eine Sammlung von Segmenten, die durch ihre Endpunkte angegeben und mit Typinformationen versehen sind, die der Form der Straße annähernd entsprechen. Verwenden Sie das Straßenkartensegment, das dem Modellierungsagenten am nächsten liegt. Bitte beachten Sie, dass Straßenmerkmale keine Zeitdimension haben und die Zeitdimension 1 hinzugefügt werden kann.
Für jeden Agenten enthalten die Ampelinformationen den Ampelstatus, der dem Agenten am nächsten liegt. Jeder Ampelpunkt verfügt über Merkmale, die den Standort und die Zuverlässigkeit des Signals beschreiben.
Wayformer-Modellreihe, bestehend aus zwei Hauptkomponenten: Szenen-Encoder und Decoder. Der Szenen-Encoder besteht hauptsächlich aus einem oder mehreren Aufmerksamkeits-Encodern, die zur Zusammenfassung der Fahrszene verwendet werden. Der Decoder besteht aus einem oder mehreren Standardtransformator-Cross-Attention-Modulen, die die erlernte Anfangsabfrage eingeben und dann Trajektorien mit Szenencodierung von Cross-Attention generieren.
Wie in der Abbildung gezeigt, verarbeitet das Wayformer-Modell multimodale Eingaben, um eine Szenenkodierung zu erzeugen: Diese Szenenkodierung wird als Kontext des Decoders verwendet und generiert k mögliche Trajektorien, die mehrere Modalitäten im Ausgaberaum abdecken.
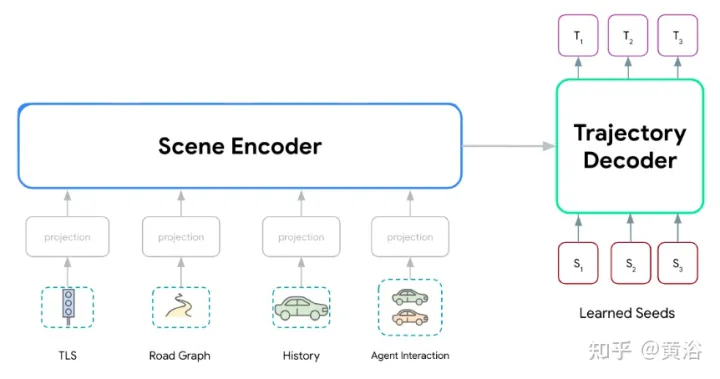
Die Vielfalt der Eingaben in den Szenenencoder macht diese Integration zu einer nicht trivialen Aufgabe. Modalitäten werden möglicherweise nicht auf derselben Abstraktionsebene oder Skala dargestellt: {Pixel vs. Zielobjekte}. Daher erfordern einige Modalitäten möglicherweise mehr Berechnungen als andere. Die rechnerische Zerlegung zwischen Modi ist anwendungsabhängig und für Ingenieure sehr wichtig. Um diesen Prozess zu vereinfachen, werden hier drei Fusionsebenen vorgeschlagen: {Post, Pre, Grade}, wie in der Abbildung gezeigt:
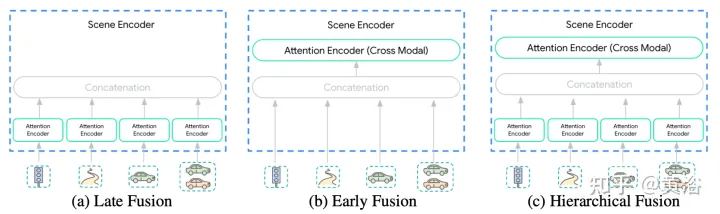
Postfusion ist die am häufigsten verwendete Methode für Bewegungsvorhersagemodelle, bei der jede Modalität ihre eigene hat eigener dedizierter Encoder. Wenn Sie die Breite dieser Encoder gleich einstellen, wird vermieden, dass zusätzliche Projektionsebenen in die Ausgabe eingefügt werden. Darüber hinaus wird der Erkundungsraum auf eine überschaubare Größe reduziert, da alle Encoder die gleiche Tiefe haben. Informationen dürfen nur in der Queraufmerksamkeitsschicht des Trajektoriendecoders über Modalitäten hinweg übertragen werden.
Pre-FusionAnstatt jeder Modalität einen Selbstaufmerksamkeits-Encoder zuzuweisen, werden die Parameter der spezifischen Modalität auf die Projektionsebene reduziert. Der Szenen-Encoder in der Abbildung besteht aus einem einzelnen Selbstaufmerksamkeits-Encoder (dem „kreuzmodalen Encoder“), der dem Netzwerk maximale Flexibilität bei der Zuweisung von Wichtigkeit über Modalitäten hinweg bei minimaler induktiver Vorspannung ermöglicht.
Hierarchische FusionAls Kompromiss zwischen den ersten beiden Extremen wird das Volumen hierarchisch zwischen modalitätsspezifischen Selbstaufmerksamkeits-Encodern und modalübergreifenden Encodern zerlegt. Wie bei der Postfusion werden Breite und Tiefe im Aufmerksamkeitsencoder und im modalübergreifenden Encoder gemeinsam genutzt. Dadurch wird die Tiefe des Szenen-Encoders effektiv zwischen modalitätsspezifischen Encodern und modalübergreifenden Encodern aufgeteilt.
Transformatornetzwerke lassen sich aufgrund der folgenden zwei Faktoren nicht gut auf große mehrdimensionale Sequenzen skalieren:
- (a) Die Selbstaufmerksamkeit ist quadratisch zur Länge der Eingabesequenz.
- (b) Positions-Feedforward-Netzwerke sind teure Subnetzwerke.
Die Beschleunigungsmethode wird im Folgenden erläutert (S ist die räumliche Dimension, T ist die Zeitbereichsdimension) und ihr Rahmen ist wie in der Abbildung dargestellt:
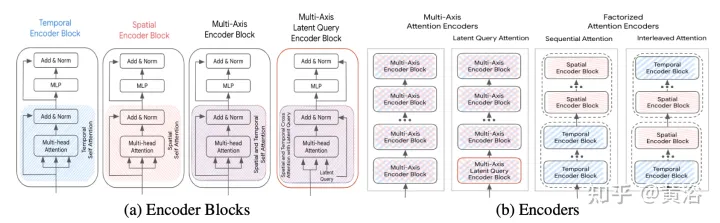
Mehrachsige Achtung: Dies bezieht sich auf Die standardmäßige Transformatoreinstellung, die Selbstaufmerksamkeit sowohl in räumlicher als auch in zeitlicher Dimension anwendet, dürfte die rechenintensivste sein. Die rechnerische Komplexität der vorderen, hinteren und hierarchischen Fusion mit mehrachsiger Aufmerksamkeit beträgt O(Sm2×T2).
Faktorisierte Aufmerksamkeit: Die rechnerische Komplexität der Selbstaufmerksamkeit ist das Quadrat der Länge der Eingabesequenz. Dies wird bei mehrdimensionalen Sequenzen noch deutlicher, da jede zusätzliche Dimension die Größe der Eingabe um einen multiplikativen Faktor erhöht. Einige Eingabemodalitäten haben beispielsweise Zeit- und Raumdimensionen, sodass der Rechenaufwand O(Sm2×T2) beträgt. Um diese Situation zu entschärfen, sollten Sie erwägen, die Aufmerksamkeit in zwei Dimensionen zu zerlegen. Diese Methode nutzt die mehrdimensionale Struktur der Eingabesequenz und reduziert die Kosten des Selbstaufmerksamkeits-Subnetzwerks von O(S2×T2) auf O(S2)+O(T2), indem Selbstaufmerksamkeit in jeder Dimension einzeln angewendet wird.
Während zerlegte Aufmerksamkeit das Potenzial hat, den Rechenaufwand im Vergleich zu mehrachsiger Aufmerksamkeit zu reduzieren, entsteht Komplexität, wenn die Selbstaufmerksamkeit auf die Reihenfolge jeder Dimension angewendet wird. Hier vergleichen wir zwei zerlegte Aufmerksamkeitsparadigmen:
- Sequentielle Aufmerksamkeit: Ein N-Schicht-Encoder besteht aus N/2 zeitlichen Encoderblöcken und einem weiteren N/2 räumlichen Encoderblock.
- Interleaved Attention: Der N-Layer-Encoder besteht aus zeitlichen und räumlichen Encoderblöcken, die sich N/2-mal abwechseln.
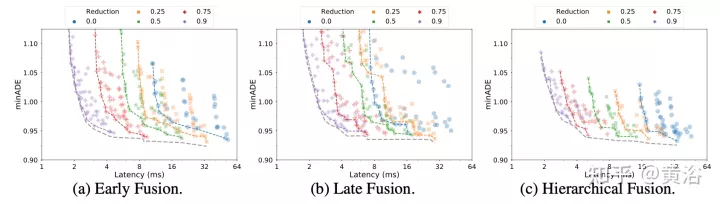
Achtung bei latenten Abfragen: Eine andere Möglichkeit, mit den Rechenkosten großer Eingabesequenzen umzugehen, besteht darin, latente Abfragen im ersten Encoderblock zu verwenden, wobei die Eingabe dem latenten Raum zugeordnet wird. Diese latenten Variablen werden von einer Reihe von Encoderblöcken weiterverarbeitet, die den latenten Raum empfangen und zurückgeben. Dies ermöglicht völlige Freiheit bei der Einstellung der Latentraumauflösung und reduziert den Rechenaufwand der Selbstaufmerksamkeitskomponente und des Positions-Feedforward-Netzwerks in jedem Block. Legen Sie den Reduzierungsbetrag (R=Lout/Lin) als Prozentsatz der Länge der Eingabesequenz fest. Bei der Postfusion und der hierarchischen Fusion bleibt der Reduktionsfaktor R für alle Aufmerksamkeitsencoder unverändert.
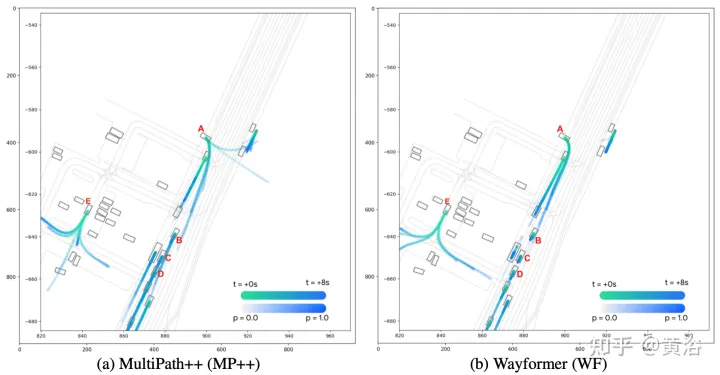
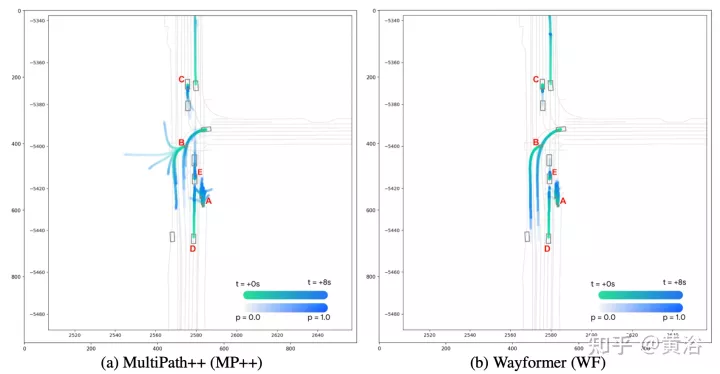
Der Wayformer-Prädiktor gibt eine Gaußsche Mischung aus, die die Flugbahn darstellt, die der Agent nehmen könnte. Um Vorhersagen zu generieren, wird ein Transformer-Decoder verwendet, der einen Satz von k gelernten Anfangsabfragen (Si) eingibt und eine Kreuzaufmerksamkeit mit den Szeneneinbettungen des Encoders durchführt, um Einbettungen für jede Komponente der Gaußschen Mischung zu generieren. Angesichts der Einbettung einer bestimmten Komponente in eine Mischung erzeugt eine lineare Projektionsebene eine nicht-kanonische Log-Wahrscheinlichkeit dieser Komponente und schätzt die gesamte Mischungswahrscheinlichkeit. Um Trajektorien zu erzeugen, wird eine weitere lineare Schichtprojektion verwendet, die 4 Zeitreihen ausgibt, die dem Mittelwert und der logarithmischen Standardabweichung der vorhergesagten Gaußschen Funktion in jedem Zeitschritt entsprechen. Während des Trainings wird der Verlust in entsprechende Klassifizierungs- und Regressionsverluste zerlegt. Unter der Annahme von k vorhergesagten Gaußschen Werten wird die Mischungswahrscheinlichkeit trainiert, um die logarithmische Wahrscheinlichkeit der wahren Flugbahn zu maximieren. Wenn der Prädiktor eine Mischung aus Gauß-Funktionen mit mehreren Modi ausgibt, ist es schwierig, Schlussfolgerungen zu ziehen, und Benchmark-Maßnahmen begrenzen häufig die Anzahl der berücksichtigten Trajektorien. Daher wird während des Bewertungsprozesses die Trajektorienaggregation angewendet, wodurch die Anzahl der berücksichtigten Modi reduziert wird und gleichzeitig die Vielfalt der ursprünglichen Ausgabemischung erhalten bleibt. Die experimentellen Ergebnisse sind wie folgt: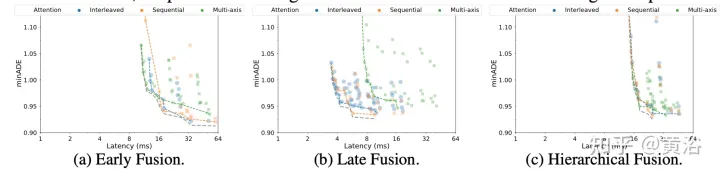
Das obige ist der detaillierte Inhalt vonWayformer: Ein einfaches und effektives Aufmerksamkeitsnetzwerk zur Bewegungsvorhersage. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr