
Heim >Technologie-Peripheriegeräte >KI >Meituan belegt den ersten Platz in der kleinen Beispiel-Lernliste FewCLUE! Schnelles Lernen + Selbsttrainingspraxis
Meituan belegt den ersten Platz in der kleinen Beispiel-Lernliste FewCLUE! Schnelles Lernen + Selbsttrainingspraxis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 17:41:101358Durchsuche
Autor: Luo Ying, 🎜🎜#)
[1]ist eine maßgebliche Bewertungsliste für das Verständnis der chinesischen Sprache. Sie umfasst viele semantische Analyse- und semantische Verständnis-Unteraufgaben wie Textklassifizierung, Beziehungen zwischen Sätzen und Leseverständnis von großer Bedeutung sowohl für die Wissenschaft als auch für die Industrie.
Abbildung 1 FewCLUE-Liste (Stand 18.04.2022)
# 🎜🎜#FewCLUE [2,3]
[2,3]
2 Methodeneinführung
Obwohl das groß angelegte Pre-Training-Modell bei verschiedenen Hauptaufgaben sehr gute Ergebnisse erzielt hat, kann es nicht verwendet werden Bei bestimmten Aufgaben sind immer noch viele annotierte Daten erforderlich. Die verschiedenen Unternehmen von Meituan verfügen über eine Fülle von NLP-Szenarien, die häufig hohe manuelle Kennzeichnungskosten erfordern. In den frühen Phasen der Geschäftsentwicklung oder wenn neue Geschäftsanforderungen schnell eingeführt werden müssen, sind häufig nicht genügend kommentierte Beispiele vorhanden. Verwenden Sie traditionelles Pretrain (pretraining) + Fine-Tuning ( Fine -tuning#🎜 🎜#) Deep-Learning-Trainingsmethoden erfüllen oft nicht die idealen Indexanforderungen, daher ist es sehr notwendig, das Modelltrainingsproblem in kleinen Beispielszenarien zu untersuchen.
Dieser Artikel schlägt eine Reihe von gemeinsamen Trainingsplänen für große Modelle und kleine Proben FSL++ vor, die Modellstrukturoptimierung, groß angelegtes Vortraining, Probenverbesserung und Ensemble-Lernen kombinieren und automatisches Training und andere Modelloptimierungsstrategien erzielten schließlich hervorragende Ergebnisse auf der FewCLUE-Liste unter dem maßgeblichen Bewertungsmaßstab für das Verständnis der chinesischen Sprache, und die Leistung übertraf bei einigen Aufgaben das menschliche Niveau, und bei einigen Aufgaben (wie CLUEWSC #🎜 🎜#) Es gibt noch Raum für Verbesserungen. Nach der Veröffentlichung von FewCLUE nutzte NetEase Fuxi das selbst entwickelte EET-Modell [4]
und verbesserte das semantische Verständnis des Modells durch sekundäres Training. Fügen Sie dann Vorlagen für das Erlangshen-Modell des IDEA Research Institute hinzu.[5] Feinabstimmung der nachgelagerten Aufgaben im Prozess. Als Hilfsaufgabe wird das Masked Language Model (MLM) mit dynamischer Maskenstrategie verwendet. Diese Methoden verwenden alle Prompt Learning als grundlegende Aufgabenstruktur. Im Vergleich zu diesen selbst entwickelten großen Modellen fügt unsere Methode hauptsächlich Modelloptimierungsstrategien wie Stichprobenverbesserung, Ensemble-Lernen und Selbstlernen hinzu, was eine erhebliche Verbesserung darstellt Verbessern Sie die Aufgabenleistung und Robustheit des Modells. Gleichzeitig kann diese Methode auf verschiedene Modelle vor dem Training angewendet werden, wodurch sie flexibler und bequemer wird.
Die Gesamtmodellstruktur von FSL++ ist in Abbildung 2 unten dargestellt. Der FewCLUE-Datensatz bietet 160 beschriftete Daten und fast 20.000 unbeschriftete Daten für jede Aufgabe. In dieser FewCLUE-Praxis haben wir zunächst in der Feinabstimmungsphase Prompt Learning mit mehreren Vorlagen erstellt und Verbesserungsstrategien wie kontradiktorisches Training, kontrastives Lernen und Mixup für gekennzeichnete Daten verwendet. Da diese Datenverbesserungsstrategien unterschiedliche Verbesserungsprinzipien verwenden, kann davon ausgegangen werden, dass die Unterschiede zwischen diesen Modellen relativ groß sind und nach integriertem Lernen bessere Ergebnisse erzielt werden. Nachdem wir die Datenverbesserungsstrategie für das Training verwendet haben, verfügen wir daher über mehrere schwach überwachte Modelle und verwenden diese schwach überwachten Modelle, um unbeschriftete Daten vorherzusagen und die Pseudo-Label-Verteilung unbeschrifteter Daten zu erhalten. Danach integrieren wir mehrere Pseudo-Label-Verteilungen unbeschrifteter Daten, die von verschiedenen Datenverbesserungsmodellen vorhergesagt wurden, um eine vollständige Pseudo-Label-Verteilung unbeschrifteter Daten zu erhalten. Anschließend rekonstruieren wir das Prompt Learning mit mehreren Vorlagen und verwenden die Daten erneut. Erweitern Sie die Strategie und wählen Sie die aus optimale Strategie. Derzeit führt unser Experiment nur eine Iteration durch, und wir können auch mehrere Iterationen ausprobieren. Mit zunehmender Anzahl der Iterationen wird die Verbesserung jedoch nicht mehr offensichtlich sein.Abbildung 2 FSL++-Modellrahmen Das vorab trainierte Sprachmodell wird auf einem riesigen, unbeschrifteten Korpus trainiert. RoBERTa[6] ist beispielsweise auf mehr als 160 GB Text trainiert, darunter Enzyklopädien, Nachrichtenartikel, literarische Werke und Webinhalte. Die von diesen Modellen erlernten Darstellungen erzielen eine hervorragende Leistung bei Aufgaben mit Datensätzen unterschiedlicher Größe aus mehreren Quellen. Das FSL++-Modell verwendet das RoBERTa-Large-Modell als Grundmodell und übernimmt die domänenadaptive Vortrainingsmethode (DAPT)[7]Vortrainingsmethode und das aufgabenadaptive Vortraining (TAPT), die Domänenwissen integrieren )[7]. DAPT zielt darauf ab, eine große Menge unbeschrifteten Textes in das Feld einzufügen, um das Sprachmodell basierend auf dem vorab trainierten Modell weiter zu trainieren und es dann anhand des Datensatzes der angegebenen Aufgabe zu optimieren. Die Fortsetzung des Vortrainings auf der Zieltextdomäne kann die Leistung des Sprachmodells verbessern, insbesondere bei nachgelagerten Aufgaben im Zusammenhang mit der Zieltextdomäne. Darüber hinaus ist die Verbesserung umso größer, je höher die Korrelation zwischen dem Text vor dem Training und dem Aufgabenbereich ist. In dieser Übung haben wir schließlich das RoBERTa Large-Modell verwendet, das auf CLUE Vocab[8] vorab trainiert wurde und einen 100-G-Korpus an Unterhaltungsprogrammen, Sport, Gesundheit, internationalen Angelegenheiten, Filmen, Prominenten und anderen Bereichen enthält. TAPT bezieht sich auf das Hinzufügen einer kleinen Menge unbeschrifteten Korpus, der direkt mit der Aufgabe zusammenhängt, auf der Grundlage des vorab trainierten Modells für das Vortraining. Für die TAPT-Aufgabe sind die von uns ausgewählten Vortrainingsdaten die unbeschrifteten Daten, die von der FewCLUE-Liste für jede Aufgabe bereitgestellt werden. Darüber hinaus verwenden wir in der Praxis von Aufgaben zur Beziehung zwischen Sätzen, wie z. B. der Inferenzaufgabe für natürliche Sprache in Chinesisch (OCNLI) und der Kurztext-Matching-Aufgabe für den chinesischen Dialog BUSTM, andere Aufgaben für Beziehungen zwischen Sätzen, wie zum Beispiel den Inferenzdatensatz für natürliche Sprache in Chinesisch Als Anfangsparameter werden die auf CMNLI und dem chinesischen Kurztext-Ähnlichkeitsdatensatz LCQMC vorab trainierten Modellparameter verwendet. Im Vergleich zur direkten Verwendung des Originalmodells zur Erledigung der Aufgabe kann dies auch den Effekt bis zu einem gewissen Grad verbessern. FewCLUE enthält eine Vielzahl von Aufgabenformen, und wir haben für jede Aufgabe eine geeignete Modellstruktur ausgewählt. Die Kategoriewörter von Textklassifizierungsaufgaben und Aufgaben zum maschinellen Leseverständnis (MRC) enthalten selbst Informationen, sodass sie besser für die Modellierung in Form eines maskierten Sprachmodells (MLM) geeignet sind, während die Aufgabe zur Beziehung zwischen Sätzen bestimmt die Korrelation zwischen zwei Sätzen, ähnlicher der Aufgabenform Next Sentence Prediction (NSP)[9]. Daher wählen wir das PET[10]-Modell für Klassifizierungsaufgaben und Leseverständnisaufgaben und das EFL[11]-Modell für Inter-Satz-Beziehungsaufgaben. Die EFL-Methode kann negative Stichproben durch globale Stichproben erstellen und robuster lernen Klassifizierungsgerät. Das Hauptziel von Prompt Learning besteht darin, die Lücke zwischen dem Ziel vor dem Training und dem Ziel der nachgelagerten Feinabstimmung zu minimieren. Normalerweise umfassen vorhandene Vortrainingsaufgaben MLM-Verlustfunktionen, nachgelagerte Aufgaben verwenden jedoch kein MLM, sondern führen neue Klassifikatoren ein, was zu Inkonsistenzen zwischen Vortrainingsaufgaben und nachgelagerten Aufgaben führt. Prompt Learning führt keine zusätzlichen Klassifizierer oder andere Parameter ein, sondern wandelt die Aufgabe in eine MLM-Form um, indem es Vorlagen (Template, das Sprachfragmente für Eingabedaten zusammenfügt ) und Etikettenwortzuordnungen (Verbalizer, das für jedes Etikett dient) zusammenfügt entsprechende Wörter im Vokabular, um das Vorhersageziel für die MLM-Aufgabe festzulegen), sodass das Modell in nachgelagerten Aufgaben mit einer kleinen Anzahl von Stichproben verwendet werden kann. Nehmen Sie als Beispiel die in Abbildung 3 gezeigte E-Commerce-Bewertungs-Stimmungsanalyseaufgabe EPRSTMT. Angesichts des Textes „Dieser Film ist wirklich gut, es lohnt sich, ihn ein zweites Mal anzusehen!“ besteht die traditionelle Textklassifizierung darin, den Klassifikator mit der Einbettung im CLS-Teil zu verbinden und ihn der 0-1-Klassifizierung (0: negativ) zuzuordnen , 1: Positiv ). Diese Methode erfordert das Training eines neuen Klassifikators in kleinen Stichprobenszenarien und es ist schwierig, gute Ergebnisse zu erzielen. Die auf Prompt Learning basierende Methode besteht darin, eine Vorlage „Dies ist ein [MASK]-Kommentar“ zu erstellen und diese dann mit dem Originaltext zu verbinden. Während des Trainings sagt das Sprachmodell das Wort an der [MASK]-Position voraus und ordnet es dann zu Ordnen Sie es der entsprechenden Kategorie zu (gut: positiv, schlecht: negativ). Aufgrund des Mangels an ausreichenden Daten ist es manchmal schwierig, die leistungsstärksten Vorlagen und Tag-Wortzuordnungen zu ermitteln. Daher kann auch das Design der Wortzuordnung mit mehreren Vorlagen und mehreren Etiketten übernommen werden. Durch das Entwerfen mehrerer Vorlagen übernimmt das Endergebnis die Integration der Ergebnisse mehrerer Vorlagen oder das Entwerfen einer Eins-zu-Viele-Tag-Wortzuordnung, sodass ein Tag mehreren Wörtern entspricht. Ähnlich wie im obigen Beispiel kann die folgende Vorlagenkombination entworfen werden (links: mehrere Vorlagen für denselben Satz, rechts: Multi-Label-Mapping). Abbildung 4 PET-Multi-Template- und Multi-Label-Mapping Aufgabenbeispiel Tabelle 1 PET-Vorlagenkonstruktion im FewCLUE-Datensatz. EFL-Modell fügt zwei Sätze zusammen, indem es Einbettung an der [CLS]-Position der Ausgabeschicht verwendet, gefolgt von einem Klassifikator, um die Vorhersage zu vervollständigen. Während des Trainingsprozesses von EFL werden zusätzlich zu den Stichproben im Trainingssatz auch negative Stichproben erstellt. Während des Trainingsprozesses werden Sätze in anderen Daten zufällig als negative Stichproben in jedem Stapel ausgewählt und die Datenverbesserung wird durch die Konstruktion negativer Stichproben durchgeführt Proben. Obwohl das EFL-Modell einen neuen Klassifikator trainieren muss, gibt es derzeit viele öffentliche Textimplikations-/Inter-Satz-Beziehungsdatensätze wie CMNLI, LCQMC usw., die anhand dieser Beispiele kontinuierlich gelernt werden können (continue-train) Anschließend werden die gelernten Parameter auf das kleine Beispielszenario übertragen und mithilfe des Aufgabendatensatzes von FewCLUE weiter verfeinert. ?? Im Bereich NLP besteht der Zweck der Datenerweiterung darin, Textdaten zu erweitern, ohne die Semantik zu ändern. Zu den Hauptmethoden gehören einfache Textersetzung, die Verwendung von Sprachmodellen zum Generieren ähnlicher Sätze usw. Wir haben Methoden wie EDA ausprobiert, um Textdaten zu erweitern, aber eine Änderung in einem Wort kann dazu führen, dass sich die Bedeutung des gesamten Satzes ändert und der Satz ersetzt wird Text enthält viel Rauschen. Daher ist es schwierig, mit einfachen Regelbeispieländerungen genügend erweiterte Daten zu generieren. Die Einbettungsverbesserung wirkt sich jedoch nicht mehr auf die Eingabe aus, sondern auf der Einbettungsebene. Die Robustheit des Modells kann durch Hinzufügen von Störungen oder Interpolation zur Einbettung verbessert werden. Daher führen wir in dieser Praxis hauptsächlich Embedding-Enhancement durch. Zu den von uns verwendeten Datenverbesserungsstrategien gehören Mixup[12], Manifold-Mixup[13] Adversarial Training, AT und kontrastives Lernen R-Drop Mixup kann die Generalisierungsfähigkeit des Modells verbessern, indem eine einfache lineare Transformation der Eingabedaten durchgeführt wird, um neue kombinierte Stichproben und kombinierte Beschriftungen zu erstellen. Bei verschiedenen überwachten oder halbüberwachten Aufgaben kann die Verwendung von Mixup die Generalisierungsfähigkeit des Modells erheblich verbessern. Die Mixup-Methode kann als Regularisierungsoperation betrachtet werden, die erfordert, dass die vom Modell auf Merkmalsebene erzeugten kombinierten Merkmale lineare Einschränkungen erfüllen, und diese Einschränkung zur Regularisierung des Modells verwendet. Wenn die Eingabe des Modells eine lineare Kombination der beiden anderen Eingaben ist, ist seine Ausgabe intuitiv auch eine lineare Kombination der Ausgabe, die erhalten wird, nachdem die beiden Daten separat in das Modell eingegeben wurden. Tatsächlich muss das Modell ungefähr sein ein lineares System. Manifold Mixup verallgemeinert den oben genannten Mixup-Vorgang auf Funktionen. Da Features über semantische Informationen höherer Ordnung verfügen, kann die Interpolation über ihre Dimensionen zu aussagekräftigeren Stichproben führen. In Modellen ähnlich BERT[9] und RoBERTa[6] wird die Anzahl der Schichten k zufällig ausgewählt und eine Mixup-Interpolation wird für die Merkmalsdarstellung dieser Schicht durchgeführt. Die Interpolation von gewöhnlichem Mixup erfolgt im Einbettungsteil der Ausgabeebene, und Manifold Mixup entspricht dem Hinzufügen dieser Reihe von Interpolationsoperationen zu einer zufälligen Ebene der Transformers-Struktur innerhalb des Sprachmodells. Gegnerisches Training verbessert den Modellverlust erheblich, indem es den Eingabeproben kleine Störungen hinzufügt. Beim gegnerischen Training geht es darum, ein Modell zu trainieren, das Originalproben und gegnerische Proben effektiv identifizieren kann. Das Grundprinzip besteht darin, einige gegnerische Stichproben durch Hinzufügen von Störungen zu konstruieren und sie dem Modell zum Trainieren zu geben, wodurch die Robustheit des Modells bei der Begegnung mit gegnerischen Stichproben verbessert und gleichzeitig die Leistung und Generalisierungsfähigkeiten des Modells verbessert werden. Kontradiktorische Beispiele müssen zwei Merkmale aufweisen: R-Drop führt Dropout zweimal für denselben Satz aus und erzwingt, dass die Ausgabewahrscheinlichkeiten verschiedener von Dropout generierter Untermodelle konsistent sind. Obwohl die Einführung von Dropout gut funktioniert, führt sie zu Inkonsistenzproblemen im Trainings- und Inferenzprozess. Um die Inkonsistenz dieses Trainingsinferenzprozesses zu mildern, reguliert R-Drop Dropout, fügt Einschränkungen für die Ausgabedatenverteilung in der von den beiden Untermodellen generierten Ausgabe hinzu und führt den KL-Divergenzverlust des Datenverteilungsmaßes ein innerhalb der Charge Die beiden von derselben Stichprobe generierten Datenverteilungen sollten so ähnlich wie möglich sein und eine Verteilungskonsistenz aufweisen. Insbesondere minimiert R-Drop für jede Trainingsstichprobe die KL-Divergenz zwischen den Ausgabewahrscheinlichkeiten von Untermodellen, die von verschiedenen Dropouts generiert wurden. Als Trainingsidee kann R-Drop in den meisten überwachten oder halbüberwachten Trainings eingesetzt werden und ist äußerst vielseitig. Die drei Datenverbesserungsstrategien, die wir verwenden: Mixup besteht darin, lineare Änderungen zwischen zwei Stichproben in der Ausgabeschicht vorzunehmen. Das Einbetten des Sprachmodells und der Ausgabeschicht einer zufälligen Schicht von Transformern innerhalb des Sprachmodells und das gegnerische Training dienen dazu Erhöhen Sie die Anzahl der Stichproben. Winzige Störungen, während kontrastives Lernen darin besteht, zwei Dropouts für denselben Satz durchzuführen, um ein positives Stichprobenpaar zu bilden, und dann die KL-Divergenz zu verwenden, um die Konsistenz der beiden Untermodelle zu begrenzen. Alle drei Strategien verbessern die Verallgemeinerung des Modells, indem sie einige Operationen beim Einbetten durchführen. Die durch verschiedene Strategien erhaltenen Modelle haben unterschiedliche Präferenzen, was Bedingungen für den nächsten Schritt des Ensemble-Lernens schafft. Ensemble-Lernen kann mehrere schwach überwachte Modelle kombinieren, um ein besseres und umfassenderes stark überwachtes Modell zu erhalten. Die Grundidee des Ensemble-Lernens besteht darin, dass selbst wenn ein schwacher Klassifikator eine falsche Vorhersage macht, andere schwache Klassifikatoren den Fehler korrigieren können. Wenn die Unterschiede zwischen den zu kombinierenden Modellen erheblich sind, führt Ensemble-Lernen in der Regel zu einem besseren Ergebnis. Selbsttraining verwendet eine kleine Menge beschrifteter Daten und eine große Menge unbeschrifteter Daten, um das Modell gemeinsam zu trainieren. Zuerst wird der trainierte Klassifikator verwendet, um die Beschriftungen aller unbeschrifteten Daten vorherzusagen, und dann werden Beschriftungen mit höherer Konfidenz als Pseudobezeichnungen ausgewählt Labels Daten, pseudo-beschriftete Daten werden mit vom Menschen beschrifteten Trainingsdaten kombiniert, um den Klassifikator neu zu trainieren. Ensemble-Lernen + Selbsttraining ist eine Lösung, die mehrere Modelle und unbeschriftete Daten nutzen kann. Zu den allgemeinen Schritten des Ensemble-Lernens gehören unter anderem: Trainieren Sie mehrere verschiedene schwach überwachte Modelle, verwenden Sie jedes Modell, um die Etikettenwahrscheinlichkeitsverteilung unbeschrifteter Daten vorherzusagen, berechnen Sie die gewichtete Summe der Etikettenwahrscheinlichkeitsverteilung und erhalten Sie die Pseudoetikettenwahrscheinlichkeitsverteilung unbeschrifteter Daten Daten. Selbsttraining bezieht sich auf das Training eines Modells, um andere Modelle zu kombinieren. Die allgemeinen Schritte sind: Trainieren mehrerer Lehrermodelle, das Schülermodell lernt die Soft Prediction von Stichproben mit hoher Konfidenz in der Pseudo-Label-Wahrscheinlichkeitsverteilung und das Schülermodell dient als letzter starker Lerner. In dieser FewCLUE-Praxis konstruieren wir zunächst Multi-Template-Prompt-Learning in der Feinabstimmungsphase und verwenden Verbesserungsstrategien wie kontradiktorisches Training, kontrastives Lernen und Mixup für gekennzeichnete Daten. Da diese Datenverbesserungsstrategien unterschiedliche Verbesserungsprinzipien verwenden, kann davon ausgegangen werden, dass die Unterschiede zwischen diesen Modellen relativ groß sind und nach integriertem Lernen bessere Ergebnisse erzielt werden. Nachdem wir die Datenverbesserungsstrategie für das Training verwendet haben, verfügen wir über mehrere schwach überwachte Modelle und verwenden diese schwach überwachten Modelle, um unbeschriftete Daten vorherzusagen und unbeschriftete Daten zu erhalten -Label-Verteilung von gelabelten Daten. Anschließend integrieren wir mehrere Pseudo-Label-Verteilungen unbeschrifteter Daten, die von verschiedenen Datenerweiterungsmodellen vorhergesagt wurden, um eine vollständige Pseudo-Label-Verteilung unbeschrifteter Daten zu erhalten. Beim Screening von Pseudo-Label-Daten wählen wir nicht unbedingt die Stichprobe mit der höchsten Konfidenz aus, denn wenn die Konfidenz jedes Datenerweiterungsmodells sehr hoch ist, bedeutet dies, dass es sich bei dieser Stichprobe möglicherweise um eine leicht zu erlernende Stichprobe handelt und hat nicht unbedingt einen großen Wert. Wir kombinieren das durch mehrere Datenverbesserungsmodelle gegebene Vertrauen und versuchen, Stichproben mit höherem Vertrauen auszuwählen, die jedoch nicht leicht zu erlernen sind (wie viele Die Vorhersagen von die beiden Modelle sind nicht alle konsistent ). Anschließend wird das Multi-Template-Prompt-Lernen unter Verwendung des Satzes beschrifteter Daten und pseudobeschrifteter Daten rekonstruiert, die Datenerweiterungsstrategie erneut verwendet und die beste Strategie ausgewählt. Derzeit führt unser Experiment nur eine Iteration durch und wir können auch mehrere Iterationen ausprobieren. Mit zunehmender Anzahl der Iterationen nimmt die Verbesserung jedoch ab und ist nicht mehr signifikant. FewCLUE-Liste enthält 9 Aufgaben, darunter jeweils Dort sind 4 Aufgaben zur Textklassifizierung, 2 Aufgaben zur Beziehung zwischen Sätzen und 3 Aufgaben zum Leseverständnis. Zu den Textklassifizierungsaufgaben gehören die Sentimentanalyse der E-Commerce-Bewertung, die Klassifizierung wissenschaftlicher Dokumente, die Nachrichtenklassifizierung und Themenklassifizierungsaufgaben für App-Anwendungsbeschreibungen. Es wird hauptsächlich in zwei Klassifikationen von Kurztexten eingeteilt: Mehrfachklassifizierung von Kurztexten und Mehrfachklassifizierung von Langtexten. Einige der Aufgaben haben viele Kategorien, mehr als 100 Kategorien, und es besteht ein Problem mit dem Ungleichgewicht der Kategorien. Zu den Aufgaben zur Beziehung zwischen Sätzen gehören das logische Denken in natürlicher Sprache und Aufgaben zur Zuordnung kurzer Texte. Zu den Leseverständnisaufgaben gehören das Leseverständnis von Redewendungen, das selektive Ausfüllen von Lücken, die zusammenfassende Beurteilung, die Identifizierung von Schlüsselwörtern und Aufgaben zur Disambiguierung von Pronomen. Jede Aufgabe stellt etwa 160 beschriftete Daten und etwa 20.000 unbeschriftete Daten bereit. Da die Langtextklassifizierungsaufgabe viele Kategorien hat und zu schwierig ist, liefert sie auch mehr beschriftete Daten. Die detaillierten Aufgabendaten sind in Tabelle 4 aufgeführt: Tabelle 4 FewCLUE-Datensatz-Aufgabeneinführung # 🎜🎜#3.2 Experimenteller Vergleich Tabelle 5 Vergleich der experimentellen Ergebnisse verschiedener Modelle und Parametermengen (fette rote Schrift zeigt das beste Ergebnis an) Tabelle 6 zeigt die experimentellen Ergebnisse der Datenverbesserung und des Ensemble-Lernens am PET/EFL-Modell Es kann festgestellt werden, dass selbst wenn die Datenverbesserungsstrategie für ein großes Modell verwendet wird, das Modell eine Verbesserung von 0,8 bis 9 PP bringen kann und nach weiterem integrierten Lernen und Selbsttraining die Modellleistung weiterhin um 0,4 bis 4 PP verbessert wird. Tabelle 6 Basismodell + Datenverbesserung + Ensemble-Lernversuchsergebnisse (fette rote Schrift zeigt das beste Ergebnis an) Im Schritt Ensemble-Lernen + Selbsttraining haben wir verschiedene Screening-Strategien ausprobiert: In verschiedenen Unternehmen von Meituan gibt es umfangreiche NLP-Szenarien. Einige Aufgaben können wie oben erwähnt als Textklassifizierungsaufgaben und Aufgaben für die Beziehung zwischen Sätzen klassifiziert werden Die Beispiel-Lernstrategie wurde auf verschiedene Meituan-Dianping-Szenarien angewendet und soll bei knappen Datenressourcen bessere Modelle trainieren. Darüber hinaus wurde die kleine Beispiel-Lernstrategie in verschiedenen NLP-Algorithmusfunktionen der internen Plattform zur Verarbeitung natürlicher Sprache (NLP) verwendet. Sie wurde in vielen Geschäftsszenarien implementiert und konnte den internen Ingenieuren von Meituan erhebliche Vorteile bringen um die Möglichkeiten des NLP-Zentrums kennenzulernen. Textklassifizierungsaufgabe Kategorie medizinischer Schönheitsthemen: Hinweise zu Meituan und Dianping sind nach Themen in 8 Kategorien unterteilt: Neugierde, Ladenerkundung, Bewertung, Fälle aus dem wirklichen Leben, Behandlungsprozess, und Vermeidung von Fallstricken, Wirkungsvergleich, wissenschaftliche Popularisierung. Wenn der Benutzer auf ein bestimmtes Thema klickt, wird der entsprechende Notizinhalt zurückgegeben und der Erfahrungsaustausch auf der Enzyklopädieseite und der Planseite des Medical Beauty-Kanals der Meituan- und Dianping-App geteilt. Die Genauigkeit des Lernens kleiner Stichproben anhand von 2.989 Trainingsdaten stieg um 1,8 PP und erreichte 89,24 %. Strategieidentifikation: Gewinnung von Reisestrategien aus UGC und Notizen, Bereitstellung von Inhalten für Reisestrategien, Anwendung auf das Strategiemodul unter der Suche nach malerischen Orten, der abgerufene Inhalt sind Notizen, die Reisestrategien beschreiben, kleine Beispiele für das Lernen und die Nutzung von 384 Elemente Die Genauigkeit der Trainingsdaten stieg um 2PP und erreichte 87 %. Xuecheng-Textklassifizierung Das Beispiellernen verbessert die Modellgenauigkeit um 2,5 PP gegenüber dem vorhandenen Modell und erreicht 84 %. Projekt-Screening: Die aktuelle gemischte Anordnung von Bewertungen auf der Bewertungslistenseite von LE Life Services/Beauty und anderen Unternehmen ist für Benutzer unpraktisch, um Entscheidungsinformationen schnell zu finden, daher sind strukturiertere Klassifizierungs-Tags erforderlich, um den Benutzeranforderungen gerecht zu werden , Lernen kleiner Stichproben In diesen beiden Unternehmen hat die Genauigkeitsrate bei der Verwendung von 300–500 Datenteilen 95 %+ erreicht (Mehrere Datensätze sind jeweils um 1,5–4 PP gestiegen). Aufgabe zur Beziehung zwischen Sätzen Markierung der medizinischen Schönheitswirksamkeit: Erinnern Sie sich an den Notengehalt von Meituan und Dianping nach Wirksamkeit. Die Arten der Wirksamkeit sind: feuchtigkeitsspendend, aufhellend, Gesichtsstraffung, Faltenentfernung usw . Online auf der Seite des Medical Beauty-Kanals gibt es 110 Arten von Wirksamkeit, die beim Lernen kleiner Stichproben nur 2909 Trainingsdaten verwendet werden, um eine Genauigkeit von 91,88 % zu erreichen (erhöht um 2,8PP). Medical Beauty Brand Marking: Marken-Upstream-Unternehmen haben Anforderungen an die Markenförderung und Vermarktung ihrer Produkte, und Content-Marketing ist eine der derzeit gängigen und effektiven Marketingmethoden. Bei der Markenkennzeichnung werden die Hinweise zur Marke jeder Marke wie „Yifuquan“ und „Shuweike“ in Erinnerung gerufen. Insgesamt sind 103 Marken in der Medical Beauty Brand Hall online. Für eine kleine Auswahl werden nur 1.676 Schulungsartikel benötigt Lernen. Die Datengenauigkeitsrate erreichte 88,59 % (erhöht um 2,9PP). In dieser Listeneinreichung haben wir ein semantisches Verständnismodell basierend auf RoBERTa erstellt und die Leistung des verbessert Modell. Dieses Modell kann die Textklassifizierung, Aufgaben zum Denken zwischen Sätzen und verschiedene Leseverständnisaufgaben erledigen. Durch die Teilnahme an dieser Evaluierungsaufgabe verfügen wir über ein tieferes Verständnis von Algorithmen und Forschung im Bereich des Verstehens natürlicher Sprache in kleinen Beispielszenarien. Wir haben dies auch genutzt, um die Implementierungsfähigkeiten der chinesischen Sprache gründlich zu testen. Edge-Algorithmen legen den Grundstein für die weitere Entwicklung in der Zukunft. Darüber hinaus sind die Aufgabenszenarien in diesem Datensatz den Geschäftsszenarien der Meituan Search- und NLP-Abteilung sehr ähnlich. Viele Strategien dieses Modells werden auch direkt im tatsächlichen Geschäft angewendet und stärken das Unternehmen direkt. Luo Ying, Xu Jun, Xie Rui und Wu Wei stammen alle von Meituan Search und der NLP-Abteilung/NLP-Zentrum. 2.1 Erweitertes Vortraining
2.2 Modellstruktur
2.2.1 Prompt Learning
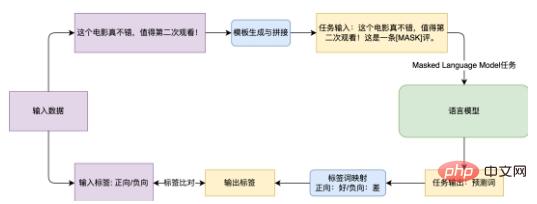
 Abbildung 3 Flussdiagramm der Prompt-Learning-Methode zum Abschließen der Stimmungsanalyseaufgabe
Abbildung 3 Flussdiagramm der Prompt-Learning-Methode zum Abschließen der Stimmungsanalyseaufgabe

2.2.2 EFL Das
 )
)  [15].
[15].  Tabelle 3 Kurze Beschreibung der Datenverbesserungsstrategie
Tabelle 3 Kurze Beschreibung der Datenverbesserungsstrategie
2.4 Ensemble-Lernen und Selbsttraining
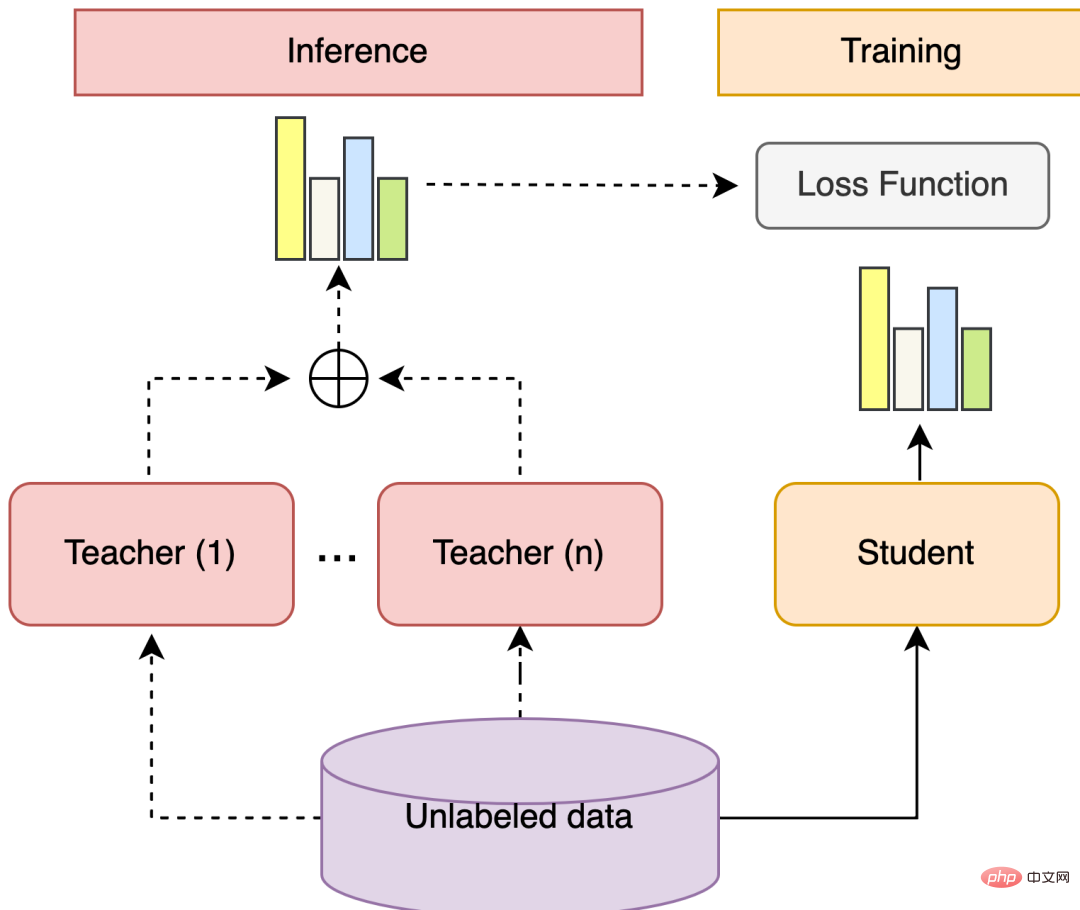
 Abbildung 5 Integrierte Lern- und Selbsttrainingsstruktur
Abbildung 5 Integrierte Lern- und Selbsttrainingsstruktur 


4 Anwendung kleiner Beispiellernstrategien in Meituan-Szenarien
5 Zusammenfassung
6 Die Autoren dieses Artikels
Das obige ist der detaillierte Inhalt vonMeituan belegt den ersten Platz in der kleinen Beispiel-Lernliste FewCLUE! Schnelles Lernen + Selbsttrainingspraxis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr