
Heim >Technologie-Peripheriegeräte >KI >Neue Perspektive auf die Bilderzeugung: Diskussion NeRF-basierter Generalisierungsmethoden
Neue Perspektive auf die Bilderzeugung: Diskussion NeRF-basierter Generalisierungsmethoden

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 17:31:072076Durchsuche
Neue perspektivische Bilderzeugung (NVS) ist ein Anwendungsgebiet der Computer Vision. Im SuperBowl-Spiel von 1998 demonstrierte die RI NVS mit Multikamera-Stereovision (MVS). Damals wurde diese Technologie auf ein Sportunternehmen übertragen US-amerikanischer Fernsehsender, der jedoch letztendlich nicht kommerzialisiert wurde; die britische BBC Broadcasting Company investierte in Forschung und Entwicklung dafür, wurde jedoch nicht wirklich kommerzialisiert.
Im Bereich des bildbasierten Renderings (IBR) gibt es für NVS-Anwendungen einen Zweig, nämlich das Tiefenbild-basierte Rendering (DBIR). Darüber hinaus musste das 3D-Fernsehen, das im Jahr 2010 sehr beliebt war, auch binokulare stereoskopische Effekte aus monokularen Videos erzielen, doch aufgrund der Unausgereiftheit der Technologie wurde es letztendlich nicht populär. Zu diesem Zeitpunkt wurde bereits begonnen, Methoden zu erforschen, die auf maschinellem Lernen basieren. Beispielsweise nutzte Youtube Bildsuchmethoden, um Tiefenkarten zu synthetisieren.
Ich habe vor einigen Jahren die Anwendung von Deep Learning in NVS eingeführt: Neue Methode zur Erzeugung perspektivischer Bilder basierend auf Deep Learning
Vor kurzem sind Neural Radiation Fields (NeRF) zu einer realistischen Möglichkeit geworden, Szenen darzustellen und zu synthetisieren Fotos Ein wirkungsvolles Beispiel für ein Bild, dessen direkteste Anwendung NVS ist. Eine große Einschränkung des herkömmlichen NeRF besteht darin, dass es oft nicht in der Lage ist, qualitativ hochwertige Renderings aus neuen Blickwinkeln zu erzeugen, die sich deutlich vom Trainingsblickpunkt unterscheiden. Das Folgende ist eine Diskussion der Verallgemeinerungsmethode von NeRF. Die grundlegende Einführung der NeRF-Prinzipien wird hier ignoriert. Wenn Sie interessiert sind, lesen Sie bitte das Rezensionspapier:
- Ein Überblick über den Fortschritt des neuronalen Renderings
-
Neuronales Volumenrendering: NeRF und andere Methoden
Das Papier [2] schlägt vor: Wir schlagen ein allgemeines tiefes neuronales Netzwerk, MVSNeRF, vor, das über Szenen hinweg verallgemeinert und Strahlungsfelder ableitet, die aus nur drei nahegelegenen Eingabeansichten rekonstruiert werden. Die Methode nutzt ebene gescannte Volumina (weit verbreitet in der Stereovision mit mehreren Ansichten) für geometriebewusste Szenenbeurteilungen und kombiniert sie mit physikalisch basiertem Volumenrendering für die Rekonstruktion neuronaler Strahlungsfelder.
Diese Methode nutzt den Erfolg von Deep MVS, um 3D-Faltungen auf Kostenvolumina anzuwenden, um verallgemeinerbare neuronale Netze für 3D-Rekonstruktionsaufgaben zu trainieren. Im Gegensatz zur MVS-Methode, die nur eine Tiefeninferenz für eine solche Kosteneinheit durchführt, führt dieses Netzwerk eine Inferenz über die Geometrie und das Erscheinungsbild der Szene durch und gibt neuronale Strahlungsfelder aus, wodurch eine Ansichtssynthese ermöglicht wird. Insbesondere wird unter Verwendung eines 3D-CNN ein neuronales Szenenkodierungsvolumen (aus dem Originalvolumen) rekonstruiert, das aus voxelweisen neuronalen Merkmalen besteht, die lokale Szenengeometrie und Erscheinungsinformationen kodieren. Anschließend dekodiert ein mehrschichtiges Perzeptron (MLP) die Volumendichte und Strahldichte an beliebigen aufeinanderfolgenden Stellen innerhalb des kodierten Volumens unter Verwendung trilinear interpolierter neuronaler Merkmale. Im Wesentlichen ist das Codierungsvolumen eine lokale neuronale Darstellung des Strahlungsfelds; sobald es geschätzt ist, kann es direkt (unter Vernachlässigung des 3D-CNN) für differenzierbares Ray-Marching für die endgültige Darstellung verwendet werden.
Im Vergleich zu bestehenden MVS-Methoden ermöglicht MVSNeRF differenzierbares neuronales Rendering, trainiert ohne 3D-Überwachung und optimiert die Inferenzzeit, um die Qualität weiter zu verbessern. Im Vergleich zu bestehenden neuronalen Rendering-Methoden sind MVS-ähnliche Architekturen von Natur aus in der Lage, ansichtsübergreifende Korrespondenzschlussfolgerungen durchzuführen, was bei der Verallgemeinerung auf unsichtbare Testszenen hilft und zu einer besseren Rekonstruktion und Rendering neuronaler Szenen führt.
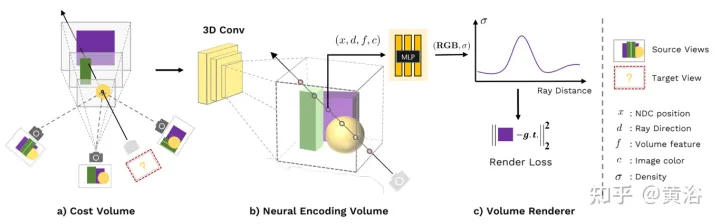
Abbildung 1 ist eine Übersicht über MVSNeRF: (a) Verzerren (Homographietransformation) Sie zunächst die 2D-Bildmerkmale auf einen Ebenen-Sweep (Ebenen-Sweep), um diese varianzbasierte Kostenontologie-Kodierung zu erstellen die Änderungen im Bildaussehen zwischen verschiedenen Eingabeansichten unter Berücksichtigung der durch Szenengeometrie und ansichtsbezogenen Hell-Dunkel-Effekte verursachten 3D-CNN-Volumen CNN ist ein 3D-UNet, das Informationen zum Erscheinungsbild von Szenen effektiv ableiten und weitergeben kann, um aussagekräftige Szenencodierungsvolumina zu erzeugen. Hinweis: Dieses Codierungsvolumen wird mithilfe des Volumenrenderings im End-to-End-Training unbeaufsichtigt vorhergesagt und abgeleitet Bildpixel werden in der nächsten Volumenregressionsstufe zusammengeführt, sodass die durch Downsampling verlorenen hohen Frequenzen wiederhergestellt werden können. (c) Mithilfe von MLP können durch Kodierung der Eigenschaften der Volumeninterpolation die Volumendichte und die RGB-Strahlung an jeder Position zurückgeführt werden. Diese Volumenattribute können bestimmt werden, indem der differenzielle Strahlverlauf das endgültige Rendering durchführt.
Das Papier [3] schlägt Stereo Radiation Field (SRF) vor, eine durchgängig trainierte neuronale Ansichtssynthesemethode, die auf neue Szenen verallgemeinert werden kann und beim Testen nur spärliche Ansichten erfordert. Die Kernidee ist eine neuronale Architektur, die von der klassischen Multi-View-Stereo-Methode (MVS) inspiriert ist, um Oberflächenpunkte durch das Finden ähnlicher Bildbereiche in Stereobildern abzuschätzen. Geben Sie 10 Ansichten in das Encoder-Netzwerk ein und extrahieren Sie Multiskalen-Features. Multilayer Perceptrons (MLPs) ersetzen den klassischen Bild-Patch- oder Feature-Matching und geben ein Ensemble von Ähnlichkeitswerten aus. Bei SRF erhält jeder 3D-Punkt eine Kodierung seines stereoskopischen Gegenstücks im Eingabebild und seine Farbe und Dichte werden im Voraus vorhergesagt. Diese Kodierung wird implizit durch das Ensemble paarweiser Ähnlichkeiten erlernt – eine Simulation des klassischen Stereosehens.
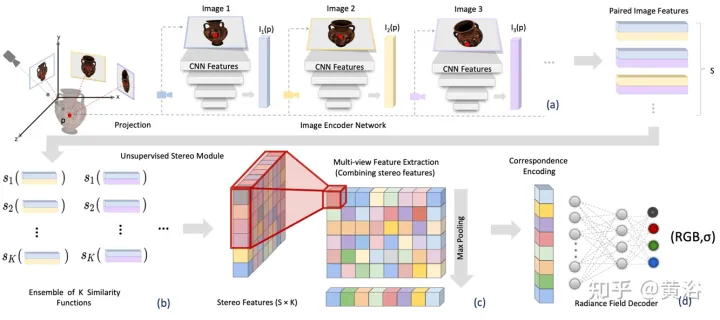
Mit bekannten Kameraparametern und einem Satz von N Referenzbildern sagt SRF die Farbe und Dichte von 3D-Punkten voraus. Konstruieren Sie das SRF-Modell f, ähnlich der klassischen Multi-View-Stereovisionsmethode: (1) Um die Position eines Punkts zu kodieren, projizieren Sie ihn in jede Referenzansicht und erstellen Sie einen lokalen Feature-Deskriptor (2 ) ) Wenn auf einer Oberfläche und den Fotos konsistent sind, sollten die Merkmalsdeskriptoren einander entsprechen; der Merkmalsabgleich wird mit einer erlernten Funktion simuliert, die die Merkmale aller Referenzansichten kodiert. (3) Die Kodierung wird von einem erlernten Decoder dekodiert eine NeRF-Darstellung. Abbildung 2 gibt einen Überblick über SRF: (a) Bildmerkmale extrahieren; (b) den Prozess der Fotokonsistenz durch eine erlernte Ähnlichkeitsfunktion simulieren und eine dreidimensionale Merkmalsmatrix (SFM) erhalten; Multi-View-Feature-Matrix (MFM); (d) Durch maximales Pooling erhält man eine kompakte Kodierung von Korrespondenz und Farbe, die dekodiert wird, um Farbe und Volumendichte zu erhalten.
Das Papier [4] schlägt DietNeRF vor, eine 3D-Darstellung neuronaler Szenen, die aus mehreren Bildern geschätzt wird. Es führt einen zusätzlichen semantischen Konsistenzverlust ein, der die realistische Darstellung neuer Posen fördert.
Wenn in NeRF nur wenige Ansichten verfügbar sind, ist das Rendering-Problem uneingeschränkt; sofern es nicht streng reguliert wird, leidet NeRF häufig unter degenerierten Lösungen. Wie in Abbildung 3 dargestellt: (A) Wenn 100 Beobachtungen eines Objekts aus einheitlich abgetasteten Posen vorgenommen werden, schätzt NeRF eine detaillierte und genaue Darstellung und ermöglicht so eine qualitativ hochwertige Ansichtssynthese allein aus der Konsistenz mehrerer Ansichten 8 Ansichten, bei denen das Ziel im Nahfeld der Trainingskamera platziert wird, führt die gleiche NeRF-Überanpassung zu einer Fehlausrichtung des Ziels und einer Verschlechterung der Pose in der Nähe der Trainingskamera (C). Bei der Regularisierung, Vereinfachung, bei manueller Anpassung und Neuinitialisierung; NeRF kann konvergieren, erfasst aber keine feinen Details mehr. (D) Ohne Vorkenntnisse über ähnliche Objekte kann die Synthese einzelner Szenenansichten unbeobachtete Regionen nicht angemessen vervollständigen.

Abbildung 4 ist ein schematisches Diagramm der Arbeit von DietNeRF: Basierend auf dem Prinzip „Aus jedem Blickwinkel ist ein Objekt dieses Objekt“, DietNeRF überwacht jedes Strahlungsfeld (DietNeRF-Kamera); der semantische Konsistenzverlust wird im Merkmalsraum berechnet, der Szenenattribute auf hoher Ebene erfasst, sodass der visuelle Transformer CLIP zum Extrahieren der semantischen Darstellung des Renderings verwendet wird. und dann den Vergleich mit der Grundwahrheitsansicht der Ähnlichkeit der Darstellungen maximieren.
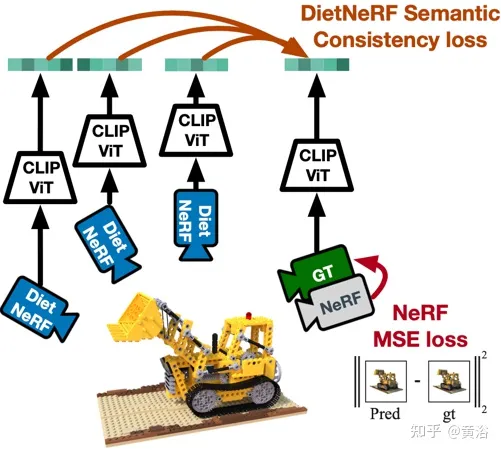
Tatsächlich kann das vom Einzelansicht-2D-Bildencoder erlernte semantische Vorwissen der Szene eine 3D-Darstellung einschränken. DietNeRF wird anhand von Hunderten Millionen Einzelansichten von 2D-Fotosets trainiert, die aus dem Internet unter Aufsicht in natürlicher Sprache abgerufen wurden: (1) Bei gegebener Eingabeansicht aus derselben Pose korrekt gerendert, (2) Semantik auf hoher Ebene über verschiedene zufällige Posen hinweg abgeglichen Eigentum. Die semantische Verlustfunktion kann das DietNeRF-Modell aus beliebigen Posen überwachen.
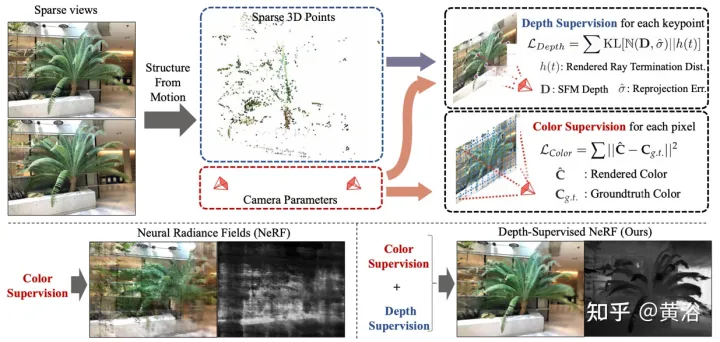
Das Papier [5] schlägt DS-NeRF vor, das einen lernenden Strahlungsfeldverlust verwendet und eine vorgefertigte Tiefenkartenüberwachung verwendet, wie in Abbildung 5 dargestellt. Tatsache ist, dass aktuelle NeRF-Pipelines Bilder mit bekannten Kamerapositionen erfordern, die typischerweise über Structure from Motion (SFM) geschätzt werden. Entscheidend ist, dass SFM auch spärliche 3D-Punkte erzeugt, die während des Trainings als „freie“ Tiefenüberwachung verwendet werden: Es wird ein Verlust hinzugefügt, der dazu führt, dass die Endtiefenverteilung eines Strahls mit einem bestimmten 3D-Schlüsselpunkt übereinstimmt, einschließlich der Tiefenunsicherheit.
Paper [6] schlägt pixelNeRF vor, ein Lernframework zur Vorhersage kontinuierlicher neuronaler Szenendarstellungen basierend auf einem oder mehreren Eingabebildern. Es führt eine vollständig Faltungsmethode ein, um die NeRF-Architektur an die Bildeingabe anzupassen und es dem Netzwerk zu ermöglichen, über mehrere Szenen hinweg zu trainieren, um das Vorwissen einer Szene zu erlernen, sodass es von einem spärlichen Satz von Ansichten (mindestens einer) ausgehen kann eine Feed-Forward-Methode. Durch die Nutzung der Volumenrendering-Methode von NeRF kann pixelNeRF ohne zusätzliche 3D-Überwachung direkt aus Bildern trainiert werden.
Konkret berechnet pixelNeRF zunächst ein vollständig gefaltetes Bildmerkmalsraster (Feature Grid) aus dem Eingabebild und passt NeRF an das Eingabebild an. Anschließend werden für jeden interessierenden 3D-Abfrageraumpunkt x und jede interessierende Blickrichtung d im Blickkoordinatensystem die entsprechenden Bildmerkmale mittels Projektion und bilinearer Interpolation abgetastet. Die Abfragespezifikation wird zusammen mit den Bildmerkmalen an das NeRF-Netzwerk gesendet, das Dichte und Farbe ausgibt, wo die räumlichen Bildmerkmale als Rest in jede Schicht eingespeist werden. Wenn mehrere Bilder verfügbar sind, wird die Eingabe zunächst in eine latente Darstellung jedes Kamerakoordinatensystems codiert, die in einer Zwischenschicht zusammengeführt wird, bevor Farbe und Dichte vorhergesagt werden. Das Modelltraining basiert auf dem Rekonstruktionsverlust zwischen einem Ground-Truth-Bild und einer volumengerenderten Ansicht. Das
pixelNeRF-Framework ist in Abbildung 6 dargestellt: Für einen 3D-Abfragepunkt x entlang der Blickrichtung d, einem Zielkamerastrahl, wird das entsprechende Bildmerkmal aus dem Merkmalsvolumen W durch Projektion und Interpolation extrahiert Die Funktion wird mit kombiniert. Die räumlichen Koordinaten werden gemeinsam an das NeRF-Netzwerk übergeben. Die ausgegebenen RGB- und Dichtewerte werden für das Volumenrendering verwendet und mit den Zielpixelwerten in der Kamera verglichen Koordinatensystem der Eingabeansicht.
Es ist ersichtlich, dass PixelNeRF und SRF lokale CNN-Merkmale verwenden, die aus dem Eingabebild extrahiert wurden, während MVSNeRF durch Bildverzerrung einen 3D-Körper erhält, der dann von einem 3D-CNN verarbeitet wird. Diese Methoden erfordern ein Vortraining an vielen Multi-View-Bilddatensätzen verschiedener Szenen, deren Beschaffung kostspielig sein kann. Darüber hinaus erfordern die meisten Methoden trotz der langen Vortrainingsphase eine Feinabstimmung der Netzwerkgewichte zum Testzeitpunkt, und die Qualität neuer Ansichten kann sich leicht verschlechtern, wenn sich die Testdomäne ändert.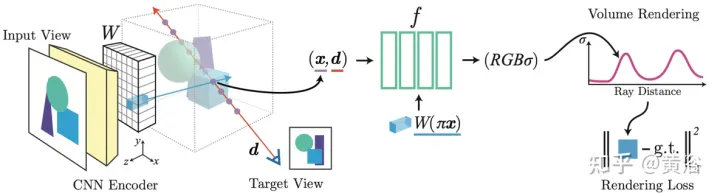 Natürlich bietet DS-NeRF eine zusätzliche Tiefenüberwachung, um die Rekonstruktionsgenauigkeit zu verbessern. Diet-NeRF vergleicht CLIP mit unsichtbaren Einbettungen von Standpunkten, die bei niedrigen Auflösungen gerendert wurden. Dieser semantische Konsistenzverlust kann nur Informationen auf hoher Ebene bereitstellen und die Szenengeometrie spärlicher Eingaben nicht verbessern.
Natürlich bietet DS-NeRF eine zusätzliche Tiefenüberwachung, um die Rekonstruktionsgenauigkeit zu verbessern. Diet-NeRF vergleicht CLIP mit unsichtbaren Einbettungen von Standpunkten, die bei niedrigen Auflösungen gerendert wurden. Dieser semantische Konsistenzverlust kann nur Informationen auf hoher Ebene bereitstellen und die Szenengeometrie spärlicher Eingaben nicht verbessern.
Das im Artikel [7] vorgeschlagene IBRNet, dessen Kern MLP und Lichttransformator (klassische Transformer-Architektur: Positionskodierung und Selbstaufmerksamkeit) umfasst, wird zur Schätzung der Strahldichte und Volumendichte kontinuierlicher 5D-Positionen (3D-Raumposition und 2D) verwendet (Blickrichtung) und rendern Darstellungsinformationen in Echtzeit aus mehreren Quellansichten.
Beim Rendern geht dieser Ansatz auf die klassische Arbeit des
Bildbasierten Renderings(
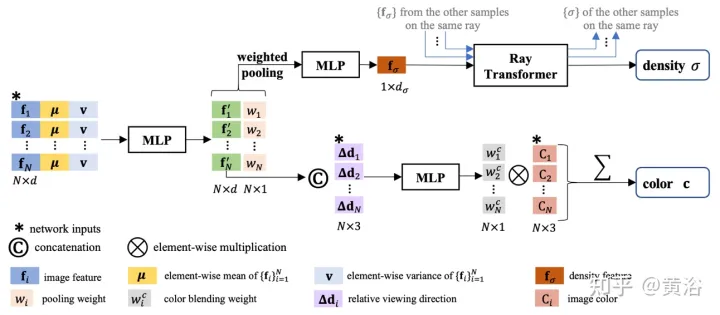
IBR) zurück. Im Gegensatz zu neuronalen Szenendarstellungen, die jede Szenenfunktion für das Rendern optimieren, lernt IBRNet eine allgemeine Ansichtsinterpolationsfunktion, die auf neue Szenen verallgemeinert. Es verwendet immer noch das klassische Volumenrendering zur Synthese von Bildern, ist jedoch vollständig differenzierbar und wird mit Posenbildern mit mehreren Ansichten als Überwachung trainiert. Der Strahltransformator berücksichtigt diese Dichtemerkmale entlang des gesamten Strahls, um den skalaren Dichtewert jeder Probe zu berechnen, was Sichtbarkeitsbeurteilungen auf größeren räumlichen Maßstäben ermöglicht. Separat leitet ein Farbmischungsmodul die ansichtsabhängige Farbe jeder Probe mithilfe der 2D-Merkmale und des Sichtvektors der Quellansicht ab. Schließlich berechnet das Volumenrendering den endgültigen Farbwert für jeden Strahl. Abbildung 7 zeigt einen Überblick über IBRNet: 1) Um die Zielansicht (mit „?“ gekennzeichnetes Bild) zu rendern, identifizieren Sie zunächst einen Satz benachbarter Quellansichten (z. B. mit A und B gekennzeichnete Ansichten) und extrahieren Sie Bildmerkmale 2) Anschließend wird für jeden Strahl in der Zielansicht IBRNet (gelb schattierter Bereich) verwendet, um eine Reihe von Musterfarben und -dichten entlang des Strahls zu berechnen. Für jede Probe werden daraus die entsprechenden Informationen (Bildfarbe) aggregiert (Ansicht, Merkmale und Blickrichtung der angrenzenden Quelle), generieren Sie die Farb- und Dichtemerkmale und wenden Sie dann den Strahltransformator auf die Dichtemerkmale aller Proben auf dem Licht an, um den Dichtewert vorherzusagen. 3) Verwenden Sie abschließend das Volumenrendering, um Farbe und Dichte entlang des Strahls zu akkumulieren. Anhand der rekonstruierten Bildfarbe kann ein End-to-End-L2-Verlusttraining durchgeführt werden.
Wie in Abbildung 8 dargestellt, ist die Farb- und Volumendichte-Vorhersagearbeit von IBRNet für kontinuierliche 5D-Positionen dargestellt: Zunächst werden die aus allen Quellansichten extrahierten 2D-Bildmerkmale in ein PointNet-ähnliches MLP eingegeben, und lokale und globale Informationen werden eingegeben aggregiert, um Wahrnehmungsmerkmale mit mehreren Ansichten zu generieren und Gewichte zu bündeln, Gewichte zum Konzentrieren von Merkmalen zu verwenden, Sichtbarkeitsbeurteilungen für mehrere Ansichten durchzuführen und Dichtemerkmale zu erhalten, anstatt die Dichte σ einer einzelnen 5D-Probe direkt vorherzusagen Aggregation aller Probeninformationen entlang des Strahls; Das Strahltransformatormodul ermittelt Dichtemerkmale für alle Proben auf dem Strahl und ermöglicht eine geometrische Schlussfolgerung über größere Entfernungen und verbessert die Dichtevorhersage für Farbvorhersage- und Wahrnehmungsmerkmale; werden relativ zum Abfragestrahl verwendet. Verbinden Sie die Eingabe basierend auf der Blickrichtung der Quellansicht mit einem kleinen Netzwerk, um einen Satz harmonischer Gewichte vorherzusagen, und die Ausgabefarbe c ist der gewichtete Durchschnitt der Bildfarbe der Quellansicht.
Hier muss noch etwas hinzugefügt werden: Im Gegensatz zu NeRF, das die absolute Blickrichtung verwendet, berücksichtigt IBRNet die Blickrichtung relativ zur Quellansicht, d. h. # 🎜🎜#d#🎜 Der Unterschied zwischen 🎜# und di, Δd=d−di. Δd ist kleiner, was normalerweise bedeutet, dass die Farbe der Zielansicht eher der entsprechenden Farbe der Quellansicht ähnelt und umgekehrt. Das in der Arbeit [8] vorgeschlagene General Radiation Field (GRF) repräsentiert und rendert 3D-Ziele und -Szenen nur aus 2D-Beobachtungen. Das Netzwerk modelliert die 3D-Geometrie als universelles Strahlungsfeld, nimmt einen Satz von 2D-Bildern, extrinsischen Kamerapositionen und intrinsischen Parametern als Eingabe, erstellt eine interne Darstellung für jeden Punkt im 3D-Raum und rendert dann das entsprechende Erscheinungsbild und die entsprechende Geometrie, die von jedem Punkt aus betrachtet werden Position. Der Schlüssel besteht darin, die lokalen Merkmale jedes Pixels eines 2D-Bildes zu lernen und diese Merkmale dann auf 3D-Punkte zu projizieren, um so eine vielseitige und reichhaltige Punktdarstellung zu erzeugen. Darüber hinaus ist ein Aufmerksamkeitsmechanismus integriert, um Pixelmerkmale mehrerer 2D-Ansichten zu aggregieren und so visuelle Okklusionsprobleme implizit zu berücksichtigen. Abbildung 9 ist ein schematisches Diagramm von GRF: GRF projiziert jeden 3D-Punkt
pauf jedes der
MEingabebilder aus Features von Jedes Pixel wird für jede Ansicht gesammelt, aggregiert und dem MLP zugeführt, der die Farb- und Volumendichte von p ableitet.
GRF besteht aus vier Teilen: 1) einem Feature-Extraktor für jedes 2D-Pixel, einem CNN-basierten Encoder-Decoder; 2) 2D-Reprojektion von Features in den 3D-Raum; 3) Aufmerksamkeitsbasierter Aggregator zum Erhalten universeller Merkmale von 3D-Punkten 4) Neuronaler Renderer NeRF.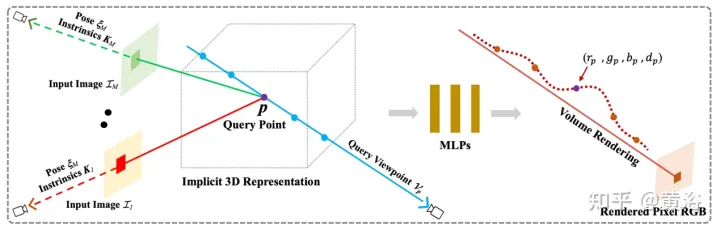 Da dem RGB-Bild kein Tiefenwert zugeordnet ist, gibt es keine Möglichkeit zu bestimmen, zu welchem spezifischen 3D-Oberflächenpunkt das Pixelmerkmal gehört. Im Reprojektionsmodul werden Pixelmerkmale als Darstellungen jeder Position entlang des Strahls im 3D-Raum betrachtet. Formal können bei einem gegebenen 3D-Punkt, einer beobachtenden 2D-Ansicht sowie der Kameraposition und intrinsischen Parametern die entsprechenden 2D-Pixelmerkmale durch einen Neuprojektionsvorgang abgerufen werden.
Da dem RGB-Bild kein Tiefenwert zugeordnet ist, gibt es keine Möglichkeit zu bestimmen, zu welchem spezifischen 3D-Oberflächenpunkt das Pixelmerkmal gehört. Im Reprojektionsmodul werden Pixelmerkmale als Darstellungen jeder Position entlang des Strahls im 3D-Raum betrachtet. Formal können bei einem gegebenen 3D-Punkt, einer beobachtenden 2D-Ansicht sowie der Kameraposition und intrinsischen Parametern die entsprechenden 2D-Pixelmerkmale durch einen Neuprojektionsvorgang abgerufen werden.
In einem Feature-Aggregator lernt der Aufmerksamkeitsmechanismus eindeutige Gewichtungen für alle Eingabe-Features und aggregiert sie dann. Durch ein MLP kann auf die Farbe und Volumendichte von 3D-Punkten geschlossen werden.
Das Papier [9] schlägt RegNeRF vor, um die Geometrie und das Erscheinungsbild von Bildfeldern zu regulieren, die aus unbeobachteten Blickwinkeln gerendert werden, und den Lichtabtastraum während des Trainings zu tempern. Zusätzlich wird ein normalisiertes Strömungsmodell verwendet, um die Farben unbeobachteter Standpunkte zu regulieren.
Abbildung 10 ist eine Übersicht über das RegNeRF-Modell: Bei einem Satz Eingabebilder (blaue Kamera) optimiert NeRF den Rekonstruktionsverlust; bei spärlichen Eingaben führt dies jedoch zu einer degenerierten Lösung; Nehmen Sie unbeobachtete Ansichten (rote Kamera) auf und regulieren Sie die Geometrie und das Erscheinungsbild der aus diesen Ansichten gerenderten Bildfelder, genauer gesagt: Werfen Sie für ein bestimmtes Strahlungsfeld einen Strahl durch die Szene und rendern Sie die vorhergesagten RGB-Bildfelder werden dann durch das trainierte normalisierte Strömungsmodell geleitet und die vorhergesagte Log-Likelihood wird maximiert, wodurch ein Glätteverlust auf die gerenderten Tiefenfelder zugefügt wird. Dieser Ansatz führt zu konsistenten 3D-Darstellungen, selbst für spärliche Eingaben, die gerendert werden realistische neue Ansichten.
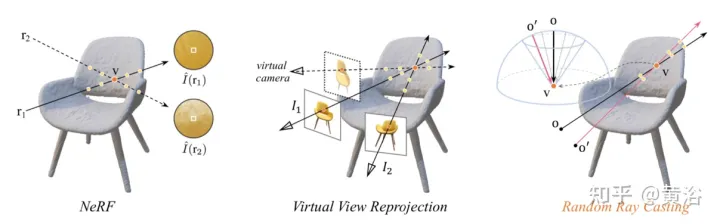
Der Artikel [10] untersucht eine Methode zur Extrapolation neuer Ansichten anstelle der Bildsynthese mit wenigen Aufnahmen, d. h. (1) das Trainingsbild kann sehr gut sein (2) Es gibt einen signifikanten Unterschied zwischen der Verteilung der Trainings- und Teststandpunkte, der als RapNeRF (RAy Priors NeRF) bezeichnet wird.Die Erkenntnis aus Papier [10] ist, dass das inhärente Erscheinungsbild jeder sichtbaren Projektion einer 3D-Oberfläche konsistent sein sollte. Daher wird eine zufällige Raycasting-Strategie vorgeschlagen, die es ermöglicht, unsichtbare Ansichten mit sichtbaren Ansichten zu trainieren. Darüber hinaus kann die Wiedergabequalität der extrapolierten Ansicht basierend auf einem vorberechneten Strahlenatlas entlang der Sichtlinie des Beobachtungsstrahls weiter verbessert werden. Eine wesentliche Einschränkung besteht darin, dass RapNeRF die Konsistenz mehrerer Ansichten nutzt, um den Effekt einer starken Korrelation zwischen Ansichten zu eliminieren.
Die intuitive Erklärung der zufälligen Ray-Casting-Strategie ist in Abbildung 11 dargestellt: Im linken Bild beobachten zwei Strahlen den 3D-Punkt v, r1 befindet sich im Trainingsraum und r2 ist weit vom Trainingsstrahl entfernt; In Anbetracht der Verteilungsdrift und Kartierungsfunktion von NeRF Fc:(r,f)→c wird ein Teil seiner Probenstrahlung entlang r2 ungenau sein; Pixelfarbe, entlang r2 Der Strahldichteakkumulationsvorgang liefert eher eine inverse Farbschätzung von v; das mittlere Bild ist eine einfache virtuelle Ansichtsreprojektion, die der NeRF-Formel folgt, um die beteiligten Pixelstrahlen zu berechnen und den virtuellen Strahl zu finden, der auf dasselbe 3D trifft Punkt aus dem Trainingsstrahlenpool Der entsprechende Strahl ist in der Praxis sehr unpraktisch; im Bild rechts ist für einen bestimmten Trainingsstrahl (projiziert von o und durch v) Random Ray Casting (RRC) #🎜🎜 # Strategie ist innerhalb eines Kegels zufällig. Erzeugen Sie einen unsichtbaren virtuellen Strahl (projiziert von o′ und durch v) und geben Sie dann online eine Pseudobezeichnung basierend auf dem Trainingsstrahl an. RRC unterstützt das Training unsichtbarer Strahlen mit sichtbaren Strahlen.
I die Beobachtungsrichtung d und der Kameraursprung o in seinem Weltkoordinatensystem #🎜 angegeben 🎜# und Tiefenwert tz und Licht r=o+td. Hier wird das vorab trainierte NeRF-Paar tz vorberechnet und gespeichert. Sei
v=o+tzd der nächstgelegene 3D-Oberflächenpunkt, der von r getroffen wird. Während der Trainingsphase wird v als neuer Ursprung betrachtet und ein Strahl wird zufällig von v innerhalb des Kegels geworfen, wobei die Mittellinie der Vektor #🎜 ist 🎜##🎜 🎜#vo¯=−tzd. Dies kann leicht erreicht werden, indem man vo¯ in einen sphärischen Raum umwandelt und einige zufällige Störungen Δφ und Δθ in φ und θ einführt. Hier sind φ und θ die Azimut- und Elevationswinkel von vo¯. Δφ und Δθ werden gleichmäßig aus dem vordefinierten Intervall [−η, η] abgetastet. Daraus erhalten wir θ′=θ+Δθ und φ′=φ+Δφ. Daher kann ein virtueller Strahl von einem zufälligen Ursprung o' geworfen werden, der auch durch v geht. Auf diese Weise kann der wahre Wert der Farbintensität I(r) als Pseudo-Token von I~(r′) betrachtet werden. Basic NeRF nutzt „gerichtete Einbettung“, um die Lichteffekte der Szene zu kodieren. Durch den Szenenanpassungsprozess ist die trainierte Farbvorhersage MLP stark von der Blickrichtung abhängig. Für die Interpolation neuer Ansichten ist dies kein Problem. Aufgrund einiger Unterschiede zwischen Trainings- und Testlichtverteilungen ist dies jedoch möglicherweise nicht für die Extrapolation einer neuen Ansicht geeignet. Eine naive Idee wäre, einfach die gerichtete Einbettung (bezeichnet als „NeRF w/o dir“) zu entfernen. Dies führt jedoch häufig zu Bildartefakten wie unerwarteten Wellen und ungleichmäßigen Farben. Dies bedeutet, dass die Blickrichtung des Lichts möglicherweise auch mit der Oberflächenglätte zusammenhängt. Der Artikel [10] berechnet einen Strahlenatlas und zeigt, dass er die Wiedergabequalität extrapolierter Ansichten weiter verbessern kann, ohne das Problem interpolierter Ansichten mit sich zu bringen. Ein Strahlenatlas ähnelt einem Texturatlas, speichert jedoch die globale Strahlrichtung für jeden 3D-Scheitelpunkt.
Insbesondere wird für jedes Bild (z. B. Bild
I) die Blickrichtung seines Strahls für alle räumlichen Standorte erfasst und dadurch eine Strahlkarte generiert. Extrahieren Sie ein grobes 3D-Netz (R3DM) aus vorab trainiertem NeRF und ordnen Sie Strahlrichtungen 3D-Scheitelpunkten zu. Am Beispiel des Scheitelpunkts V=(x,y,z) sollte seine globale Lichtrichtung
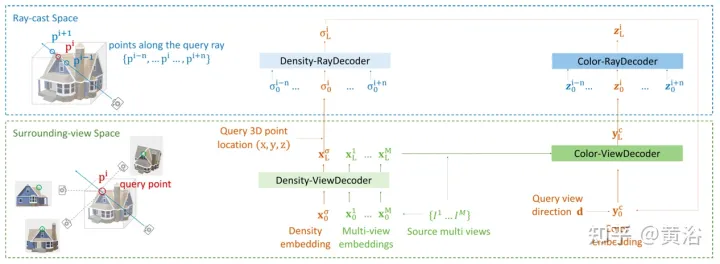
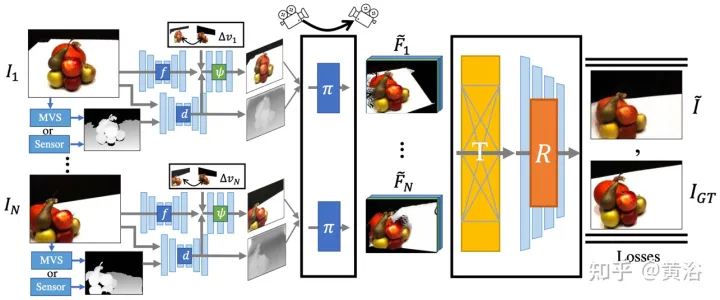
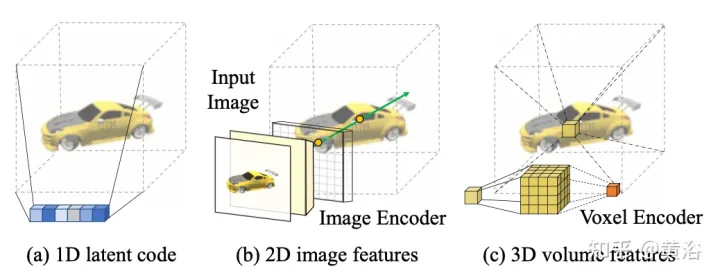
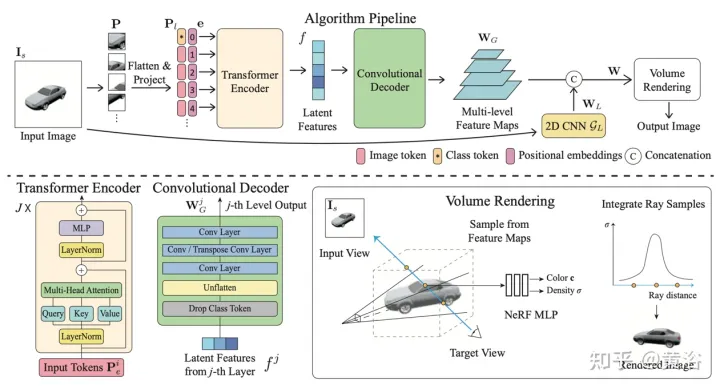
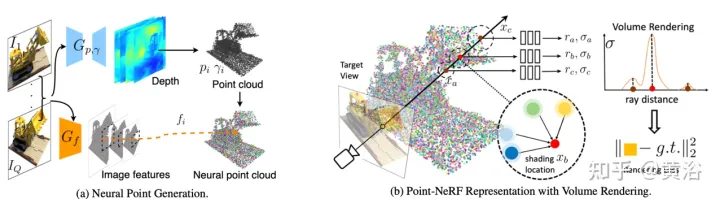
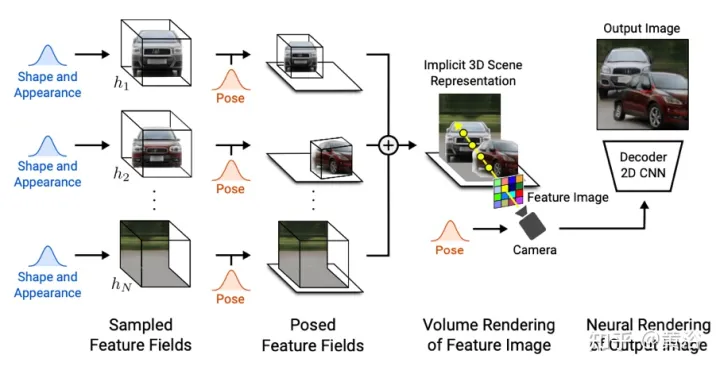
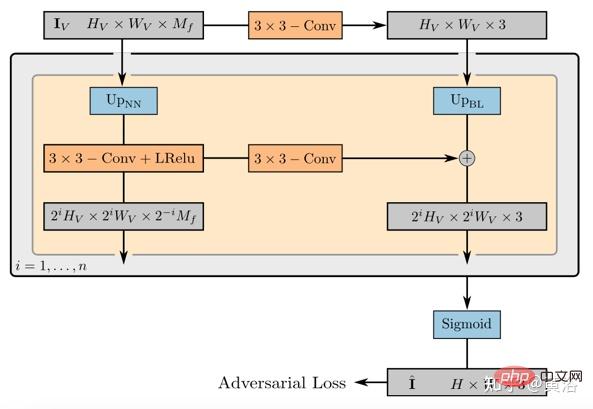
d¯V ausgedrückt werden als #🎜🎜 # wobei K der interne Kameraparameter ist, Γw2c(Ii) die Kamera-Welt-Koordinatensystem-Transformationsmatrix des Bildes Ii, Vuv(Ii) die 2D-Projektion des Scheitelpunkts V auf dem Bild ist Ii-Position, L ist die Anzahl der Trainingsbilder bei der Vertex-V-Rekonstruktion. Für jedes Pixel einer beliebigen Kameraposition erhält man durch die Projektion eines 3D-Netzes mit einer Ray-Map-Textur (R3DM) in 2D einen globalen Ray-Prior d¯. Abbildung 12 ist ein schematisches Diagramm des Lichtatlas: Das heißt, es wird ein Lichtatlas vom Trainingslicht erfasst und zum Hinzufügen von Textur zum groben 3D-Netz (R3DM) des Stuhls verwendet. R(Ii) ist das Trainingsbild Strahlendiagramm von II. Wenn Sie RapNeRF trainieren, verwenden Sie das d¯ des interessierenden Pixels I(r), um dessen d in Fc für die Farbvorhersage zu ersetzen. Die Wahrscheinlichkeit, dass dieser alternative Mechanismus auftritt, beträgt 0,5. Während der Testphase beträgt die Strahldichte c der Probe x ungefähr: wobei die Abbildungsfunktion Fσ(x):x→(σ,f) ist. Original NeRF optimiert jede Szenendarstellung unabhängig, ohne dass gemeinsame Informationen zwischen Szenen untersucht werden müssen, und ist zeitaufwändig. Um dieses Problem zu lösen, haben Forscher Modelle wie PixelNeRF und MVSNeRF vorgeschlagen, die mehrere Beobachteransichten als bedingte Eingabe empfangen und ein universelles neuronales Strahlungsfeld lernen. Dem Divide-and-Conquer-Designprinzip folgend besteht es aus zwei unabhängigen Komponenten: einem CNN-Feature-Extraktor für ein einzelnes Bild und einem MLP als NeRF-Netzwerk. Für die Einzelansicht-Stereovision ordnet das CNN in diesen Modellen das Bild einem Merkmalsgitter zu und das MLP ordnet die abgefragten 5D-Koordinaten und ihre entsprechenden CNN-Merkmale einer einzelnen Volumendichte und einer ansichtsabhängigen RGB-Farbe zu. Da CNN und MLP bei der Stereovision mit mehreren Ansichten keine beliebige Anzahl von Eingabeansichten verarbeiten können, werden die Koordinaten und entsprechenden Merkmale im Koordinatensystem jeder Ansicht zunächst unabhängig verarbeitet und es werden bildbedingte Zwischendarstellungen jeder Ansicht erhalten. Als nächstes wird ein zusätzliches Pooling-basiertes Modell verwendet, um die Ansichtszwischendarstellungen innerhalb dieser NeRF-Netzwerke zu aggregieren. Bei 3D-Verständnisaufgaben liefern mehrere Ansichten zusätzliche Informationen über die Szene. Der Artikel [11] schlägt ein Encoder-Decoder-Transformer-Framework TransNeRF vor, um die Szene des neuronalen Strahlungsfeldes zu charakterisieren. TransNeRF kann tiefe Beziehungen zwischen mehreren Ansichten untersuchen und Multi-View-Informationen über einen einzigen Transformer-basierten NeRF-Aufmerksamkeitsmechanismus zu koordinatenbasierten Szenendarstellungen zusammenfassen. Darüber hinaus berücksichtigt TransNeRF die entsprechenden Informationen des Raycast-Raums und des peripheren Sichtraums, um die lokale geometrische Konsistenz von Form und Aussehen in der Szene zu lernen. Wie in Abbildung 13 dargestellt, rendert TransNeRF den abgefragten 3D-Punkt in einem Zielbetrachtungsstrahl. TransNeRF umfasst: 1) Im peripheren Raum den Dichteansicht-Decoder (Density-ViewDecoder) und den Farbansicht-Decoder (Color-ViewDecoder). ViewDecoder) integriert die Quellansichts- und Abfragerauminformationen ((x,y,z),d) in die latente Dichte und Farbdarstellung des 3D-Abfragepunkts 2) Verwenden Sie im Ray Casting-Raum den Dichte-Ray-Decoder (Density). -RayDecoder) und Farbstrahldecoder (Color-RayDecoder) berücksichtigen benachbarte Punkte entlang des Zielsichtstrahls, um die Abfragedichte und Farbdarstellung zu verbessern. Schließlich werden die Volumendichte und die Richtungsfarbe des abgefragten 3D-Punkts auf der Zielsichtlinie von TransNeRF erhalten. Der Artikel [12] schlägt eine verallgemeinerbare NVS-Methode mit spärlicher Eingabe namens FWD vor, die eine qualitativ hochwertige Bildsynthese in Echtzeit ermöglicht. Mit expliziter Tiefe und differenziellem Rendering erreicht FWD eine 130- bis 1000-fache Geschwindigkeit und eine bessere wahrgenommene Qualität. Wenn die Sensortiefe während des Trainings oder der Inferenz nahtlos integriert wird, kann die Bildqualität verbessert und gleichzeitig die Echtzeitgeschwindigkeit beibehalten werden. Die wichtigste Erkenntnis besteht darin, dass die explizite Charakterisierung der Tiefe jedes Eingabepixels die Anwendung einer Vorwärtsverzerrung auf jede Eingabeansicht mit einem differenzierbaren Punktwolken-Renderer ermöglicht. Dadurch wird die teure Volumenmessung bei NeRF-ähnlichen Methoden vermieden und eine Echtzeitgeschwindigkeit bei gleichzeitig hoher Bildqualität erreicht. SynSin [1] verwendet einen differenzierbaren Punktwolken-Renderer für die Einzelbild-New-View-Synthese (NVS). Paper [12] erweitert SynSin auf mehrere Eingaben und untersucht effektive Methoden zum Zusammenführen von Multi-View-Informationen. FWD schätzt die Tiefe jeder Eingabeansicht, erstellt eine Punktwolke latenter Merkmale und synthetisiert dann die neue Ansicht über einen Punktwolken-Renderer. Um das Inkonsistenzproblem zwischen Beobachtungen aus verschiedenen Blickwinkeln zu lindern, wird das Blickpunkt-bezogene Merkmal MLP in die Punktwolke eingeführt, um Blickpunkt-bezogene Ergebnisse zu modellieren. Ein weiteres Transformer-basiertes Fusionsmodul kombiniert effektiv Funktionen aus mehreren Eingaben. Ein Verfeinerungsmodul, das fehlende Bereiche nachmalen und die Kompositionsqualität weiter verbessern kann. Das gesamte Modell wird durchgängig trainiert, wodurch photometrische und wahrnehmungsbezogene Verluste minimiert, Tiefe erlernt und Funktionen zur Optimierung der Synthesequalität genutzt werden. Abbildung 14 ist eine Übersicht über FWD: Verwenden Sie bei einem gegebenen Satz spärlicher Bilder das Feature-Netzwerk f (basierend auf der BigGAN-Architektur), das ansichtsbezogene Feature-MLP ψ und das tiefe Netzwerk d für jedes Bild Ii Konstruiert eine Punktwolke (einschließlich geometrischer und semantischer Informationen der Ansicht) Pi; Zusätzlich zu Bildern verwendet d als Eingabe die von MVS geschätzte Tiefe (basierend auf PatchmatchNet) oder die Sensortiefe und führt eine Regression durch verfeinerte Tiefe; basierend auf Bildmerkmalen Fi und der relativen Ansichtsänderung Δv (basierend auf den normalisierten Ansichtsrichtungen vi und vt, d. h. vom Punkt zur Mitte der Eingabeansicht i). und Zielansicht t), durch f und ψ Pixel-für-Pixel-Regressionsfunktionen Fi′; verwenden Sie einen differenzierbaren Punktwolkenrenderer π (Splatting), um den Punkt zu projizieren und zu rendern Wolke zur Zielansicht, d. h. F~i; Rendering Anstatt Ansichtspunktwolken direkt zu aggregieren, fusioniert der Transformer T die Rendering-Ergebnisse aus einer beliebigen Anzahl von Eingaben und wendet das Verfeinerungsmodul R an, um die zu dekodieren Das endgültige Bildergebnis repariert semantisch und geometrisch Bereiche, die durch die ungenaue Tiefe verursacht werden, und verbessert die Wahrnehmungsqualität basierend auf der in Feature-Maps enthaltenen Semantik. Das Training nutzt photometrischen Verlust und Inhaltsverlust. Bestehende Methoden zur Rekonstruktion von 3D-Objekten mithilfe lokaler Bildmerkmale projizieren eingegebene Bildmerkmale auf Abfrage-3D-Punkte, um Farbe und Dichte vorherzusagen und daraus auf die 3D-Form und das Erscheinungsbild zu schließen. Diese bildbedingten Modelle eignen sich gut zum Rendern von Zielperspektivenkarten, die nahe an der Eingabeperspektive liegen. Wenn sich die Zielperspektive jedoch zu stark verschiebt, führt diese Methode zu einer erheblichen Verdeckung der Eingabeansicht, einem starken Rückgang der Renderqualität und unscharfen Vorhersagen. Um das oben genannte Problem zu lösen, schlägt Papier [13] eine Methode vor, um globale und lokale Merkmale zu verwenden, um eine komprimierte 3D-Darstellung zu erstellen. Globale Features werden von einem visuellen Transformer gelernt, während lokale Features aus einem 2D-Faltungsnetzwerk extrahiert werden. Um eine neue Ansicht zu synthetisieren, wird ein MLP-Netzwerk darauf trainiert, ein Volumenrendering basierend auf der erlernten 3D-Darstellung zu erreichen. Diese Darstellung ermöglicht die Rekonstruktion unsichtbarer Regionen, ohne dass erzwungene Einschränkungen wie Symmetrie oder kanonische Koordinatensysteme erforderlich sind. Angenommen, ein einzelnes Bild befindet sich bei Kamera s, besteht die Aufgabe darin, eine neue Ansicht bei Kamera t zu synthetisieren. Wenn ein 3D-Punkt x im Quellbild sichtbar ist, kann seine Farbe Is(π(x)) direkt verwendet werden, wobei π die Projektion in der Quellansicht darstellt und anzeigt, dass der Punkt in einer neuen Ansicht sichtbar ist. Wenn x verdeckt ist, greifen Sie auf andere Informationen als die projizierte π(x)-Farbe zurück. Wie in Abbildung 15 dargestellt, gibt es drei mögliche Lösungen, um diese Art von Informationen zu erhalten: (a) Allgemein ist NeRF eine auf einem 1D-Latentcode basierende Methode, die 3D-Zielinformationen in 1D-Vektoren codiert Die induktive Verzerrung ist eingeschränkt. (b) 2D-bildbasierte Methoden rekonstruieren jeden 3D-Punkt aus Pixel-für-Pixel-Bildmerkmalen. Solche Darstellungen fördern eine bessere Rendering-Qualität in sichtbaren Bereichen und sind recheneffizienter, aber das Rendering wird für unsichtbare Bereiche unscharf. c) ) Die 3D-Voxel-basierte Methode behandelt das 3D-Ziel als eine Sammlung von Voxeln und wendet eine 3D-Faltung an, um die Farbe RGB und den Dichtevektor σ zu erzeugen, was schneller rendert und die 3D-Priors zum Rendern voll ausnutzt unsichtbare Geometrie, begrenzt jedoch die Rendering-Auflösung aufgrund der Voxelgröße und des begrenzten Empfangsfelds. Abbildung 6 ist eine Übersicht über die global-lokale Hybrid-Rendering-Methode [13]: Zunächst wird das Eingabebild in N=8×8 Bildblöcke unterteilt P; jeder Bildblock wird abgeflacht und linearisiert Projiziert auf das Bild-Token (Token) P1; der Transformator-Encoder nimmt das Bild-Token und die lernbare Position, die e einbettet, und extrahiert globale Informationen als einen Satz latenter Merkmale f; dann werden die latenten Merkmale in mehrere Ebenen dekodiert mit einer Faltungsdecoder-Feature-Map WG; Zusätzlich zu den globalen Features wird ein weiteres 2D-CNN-Modell verwendet, um lokale Bildfeatures zu erhalten. Schließlich wird das NeRF MLP-Modell zum Abtasten der Features des Volumenrenderings verwendet. Das Papier [14] schlägt Point-NeRF vor, das die Vorteile von NeRF und MVS kombiniert und neuronale 3D-Punktwolken und verwandte neuronale Merkmale zur Modellierung des Strahlungsfelds verwendet. Point-NeRF kann effektiv gerendert werden, indem neuronale Punktmerkmale in der Nähe der Szenenoberfläche in einer auf Ray Marching basierenden Rendering-Pipeline zusammengefasst werden. Darüber hinaus wird Point-NeRF durch direkte Inferenz aus einem vorab trainierten tiefen Netzwerk initialisiert, um eine neuronale Punktwolke zu erzeugen. Die Punktwolke kann so optimiert werden, dass sie die visuelle Qualität von NeRF übertrifft und 30-mal schneller trainiert. Point-NeRF wird mit anderen 3D-Rekonstruktionsmethoden kombiniert und verwendet einen Wachstums- und Beschneidungsmechanismus, d. h. das Wachstum in Bereichen mit hoher Volumendichte und das Beschneiden in Bereichen mit geringer Volumendichte, um die rekonstruierten Punktwolkendaten zu optimieren. Eine Übersicht über Point-NeRF ist in Abbildung 17 dargestellt: (a) Aus Bildern mit mehreren Ansichten generiert Point-NeRF mithilfe eines kostenvolumenbasierten 3D-CNN Tiefe für jede Ansicht und extrahiert 2D-Merkmale aus dem Eingabebild durch a 2D CNN; Nach der Aggregation der Tiefenkarte wird ein punktbasiertes Strahlungsfeld erhalten, in dem jeder Punkt eine räumliche Position, Konfidenz und nicht projizierte Bildmerkmale aufweist. (b) Um eine neue Ansicht zu synthetisieren, wird eine differenzierbare Strahlenreise durchgeführt Die neuronale Punktwolke berechnet hell und dunkel in der Nähe. An jeder hellen und dunklen Position aggregiert Point-NeRF die Merkmale seiner K neuronalen Punktnachbarn, berechnet die Strahlungsdichte und die Körperdichte und verwendet dann die Körperdichteakkumulation, um die Strahlungsdichte zu summieren. Der gesamte Prozess ist durchgängig trainierbar und punktuelle Strahlungsfelder können durch Rendering-Verluste optimiert werden. GRAF (Generative Radiance Field)[18] ist ein Strahlungsfeld-Generierungsmodell, das die Synthese hochauflösender 3D-fähiger Bilder und das Training des Modells durch die Einführung eines Diskriminators basierend auf mehrskaligen Patches erreicht Es sind nur 2D-Bilder erforderlich, die von Kameras mit unbekannter Pose aufgenommen wurden. Das Ziel besteht darin, ein Modell zum Synthetisieren neuer Szenen durch Training an unverarbeiteten Bildern zu erlernen. Genauer gesagt wird ein kontradiktorisches Framework verwendet, um ein generatives Modell von Strahlungsfeldern (GRAF) zu trainieren. Abbildung 18 zeigt einen Überblick über das GRAF-Modell: Der Generator nimmt die Kameramatrix K, die Kameraposition ξ, den 2D-Abtastmodus ν und den Form-/Erscheinungscode als Eingabe und sagt einen Bildfleck voraus P′; Der Diskriminator vergleicht den synthetischen Patch P′ mit dem Patch P, der zum Zeitpunkt der Inferenz extrahiert wurde, und sagt eine Farbe für jeden Bildpixelwert voraus ; Allerdings ist dieser Vorgang zur Trainingszeit zu teuer, daher wird ein fester Bereich mit der Größe K×KPixel vorhergesagt, der zufällig skaliert und gedreht wird, um den Gradienten für das gesamte Strahlungsfeld bereitzustellen. x und der Blickrichtung d auf RGB-Farbwerte c abbilden und Volumendichte σ: zs, der die Zielform bestimmt, und ein Erscheinungscode za, der die bestimmt Aussehen. Hier wird gθ als bedingtes Strahlungsfeld bezeichnet und seine Struktur ist in Abbildung 19 dargestellt: Zunächst wird der Formcode h basierend auf dem Positionscode und dem Formcode von x berechnet Dichtekopf σθ kodiert dies. Um die Farbe c an der 3D-Position x vorherzusagen, verketten Sie die Positionskodierung von h mit d Code za, Und übergeben Sie den resultierenden Vektor an den Farbkopf cθ; berechnen Sie σ unabhängig vom Blickwinkel d und fördern Sie so die Konsistenz bei mehreren Ansichten und die Trennung von Form und Aussehen Das Netzwerk verwendet zwei latente Codes, um Form und Aussehen zu trennen. Sie werden modelliert und können während der Inferenz separat behandelt werden. Der Diskriminator ist als Faltungs-Neuronales Netzwerk implementiert und vergleicht den vorhergesagten Patch P′ mit dem Patch P, der aus der Datenverteilung pD-Realbild I extrahiert wurde. Um einen K×K-Patch aus einem echten Bild I zu extrahieren, extrahieren Sie zunächst v=(u,s) aus derselben Verteilung pv, die zum Extrahieren des obigen Generator-Patches verwendet wurde, und führen Sie dann eine bilineare Interpolationsabfrage durch I an der 2D-Bildkoordinate P(u,s) und probieren Sie den echten Patch P aus. Verwenden Sie Γ(I,v), um diesen bilinearen Abtastvorgang darzustellen. Experimente ergaben, dass ein einzelner Diskriminator mit gemeinsamen Gewichten für alle Patches ausreicht, selbst wenn die Patches an zufälligen Orten in unterschiedlichen Maßstäben abgetastet werden. Hinweis: Die Skala bestimmt das Empfangsfeld des Patches. Um das Training zu erleichtern, beginnen Sie daher mit einem größeren Empfangsfeld-Patch, um den globalen Kontext zu erfassen. Anschließend werden nach und nach Patches mit kleineren Empfangsfeldern abgetastet, um lokale Details zu verfeinern. GIRAFFE[19] wird verwendet, um beim Training an unstrukturierten Rohbildern Szenen auf kontrollierbare und realistische Weise zu generieren. Die Hauptbeiträge liegen in zwei Aspekten: 1) Die kombinierte 3D-Szenendarstellung wird direkt in das generative Modell integriert, um eine besser kontrollierbare Bildsynthese zu erreichen. 2) Kombinieren Sie diese explizite 3D-Darstellung mit einer neuronalen Rendering-Pipeline, um schnellere Schlussfolgerungen und realistischere Bilder zu ermöglichen. Zu diesem Zweck ist die Szenendarstellung eine Kombination aus generierten neuronalen Merkmalsfeldern, wie in Abbildung 20 dargestellt: Für eine zufällig ausgewählte Kamera wird ein Merkmalsbild der Szene basierend auf einem separaten 2D-Neuralfeld volumengerendert Das Rendering-Netzwerk wandelt das Merkmalsbild in RGB-Bilder um. Während des Trainings werden nur Originalbilder verwendet, und der Bilderzeugungsprozess kann während des Tests gesteuert werden, einschließlich der Kameraposition, der Zielposition sowie der Form und des Erscheinungsbilds des Modells Erweitert über den Bereich der Trainingsdaten hinaus und kann beispielsweise Bilder mit Verhältnissen und Szenen mit mehr Objekten in Trainingsbildern synthetisieren. Rendern Sie das Szenenvolumen in ein Feature-Bild mit relativ niedriger Auflösung, was Zeit und Rechenaufwand spart. Der neuronale Renderer verarbeitet diese Merkmalsbilder und gibt das endgültige Rendering aus. Auf diese Weise kann die Methode qualitativ hochwertige Bilder erhalten und auf reale Szenen skaliert werden. Wenn diese Methode an einer Sammlung unstrukturierter Rohbilder trainiert wird, ermöglicht sie eine steuerbare Bildsynthese von Einzel- und Mehrobjektszenen. Beim Kombinieren von Szenen sind zwei Situationen zu berücksichtigen: N fest und N wechselnd (die letzte ist der Hintergrund). In der Praxis wird der Hintergrund mit derselben Darstellung wie das Ziel dargestellt, mit der Ausnahme, dass die Skalierungs- und Übersetzungsparameter über die gesamte Szene hinweg festgelegt sind und um den Ursprung des Szenenraums herum zentriert sind. Das Gewicht des 2D-Rendering-Operators ordnet das Feature-Bild dem endgültigen synthetischen Bild zu, das als 2D-CNN mit Leaky-ReLU-Aktivierung parametrisiert und mit 3x3-Faltung und Next-Neighbor-Upsampling kombiniert werden kann, um die räumliche Auflösung zu erhöhen. Die letzte Ebene wendet die Sigmoidoperation an, um die endgültige Bildvorhersage zu erhalten. Das schematische Diagramm ist in Abbildung 21 dargestellt. Der Diskriminator ist auch ein CNN mit Leaky ReLU-Aktivierung. 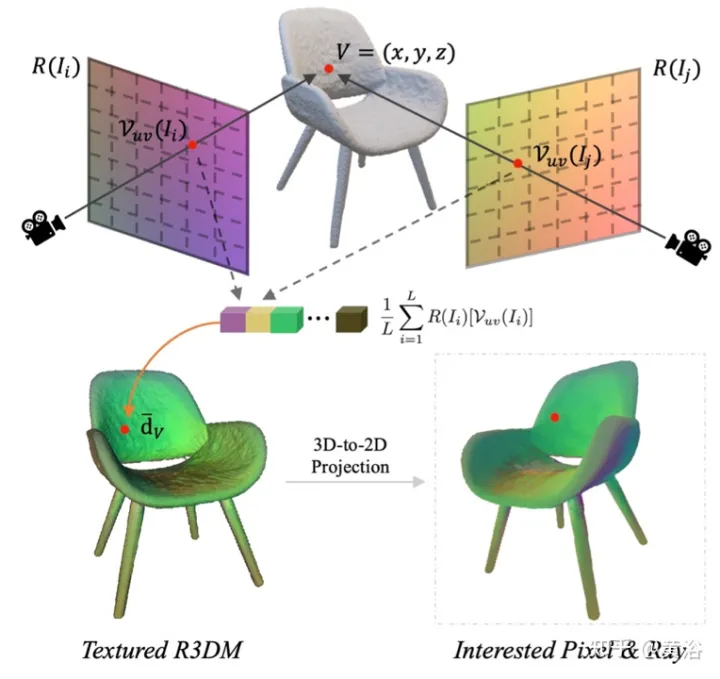
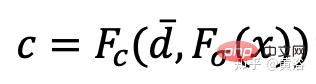
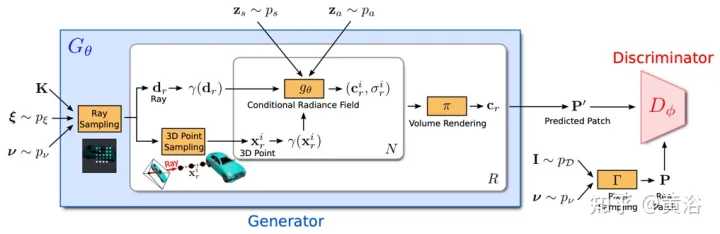 Das Strahlungsfeld wird durch ein tiefes, vollständig verbundenes neuronales Netzwerk dargestellt, wobei die Parameter θ die Positionskodierung der 3D-Position
Das Strahlungsfeld wird durch ein tiefes, vollständig verbundenes neuronales Netzwerk dargestellt, wobei die Parameter θ die Positionskodierung der 3D-Position 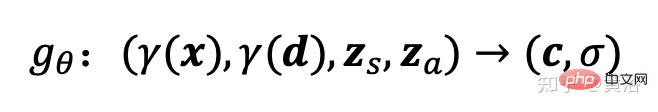 gθ von zwei zusätzlichen latenten Codes ab: Einer ist der Formcode
gθ von zwei zusätzlichen latenten Codes ab: Einer ist der Formcode 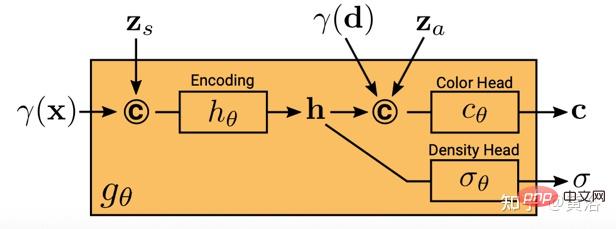
Das obige ist der detaillierte Inhalt vonNeue Perspektive auf die Bilderzeugung: Diskussion NeRF-basierter Generalisierungsmethoden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr