
Heim >Technologie-Peripheriegeräte >KI >Self-Service-Maschinelles Lernen basierend auf intelligenten Datenbanken
Self-Service-Maschinelles Lernen basierend auf intelligenten Datenbanken

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 16:31:081855Durchsuche

Übersetzer |. Zhang Yi
Rezensent |. Liang Ce Sun Shujuan
1. Wie wird man ein IDO?
IDO (erkenntnisgesteuerte Organisation) bezieht sich auf eine erkenntnisgesteuerte (informationsorientierte) Organisation. Um ein IDO zu werden, benötigen Sie erstens Daten und die Tools zum Betreiben und Analysieren der Daten; zweitens einen Datenanalysten oder Datenwissenschaftler mit entsprechender Erfahrung und schließlich müssen Sie eine Technologie oder Methode finden, um eine erkenntnisbasierte Entscheidungsfindung umzusetzen; Prozesse im gesamten Unternehmen.
Maschinelles Lernen ist eine Technologie, die die Vorteile von Daten maximieren kann. Der ML-Prozess verwendet zunächst Daten, um ein Vorhersagemodell zu trainieren, und löst dann datenbezogene Probleme, nachdem das Training erfolgreich war. Unter ihnen sind künstliche neuronale Netze die effektivste Technologie, und ihr Design basiert auf unserem aktuellen Verständnis der Funktionsweise des menschlichen Gehirns. Angesichts der enormen Rechenressourcen, über die die Menschen derzeit verfügen, können unglaubliche Modelle erstellt werden, die auf riesigen Datenmengen trainiert werden.
Unternehmen können verschiedene Self-Service-Software und -Skripte verwenden, um verschiedene Aufgaben zu erledigen und so menschliches Versagen zu vermeiden. Ebenso können Sie Entscheidungen auf der Grundlage von Daten treffen, um menschliches Versagen zu vermeiden.
2. Warum setzen Unternehmen künstliche Intelligenz nur langsam ein?
Nur eine Minderheit der Unternehmen nutzt künstliche Intelligenz oder maschinelles Lernen, um Daten zu verarbeiten. Das US Census Bureau gab an, dass im Jahr 2020 weniger als 10 % der US-Unternehmen maschinelles Lernen eingeführt hatten (hauptsächlich große Unternehmen).
Zu den Hindernissen für die Einführung von ML gehören:
- KI muss noch viel Arbeit leisten, bevor sie den Menschen ersetzen kann. Erstens mangelt es vielen Unternehmen an Fachkräften und sie können sich diese auch nicht leisten. Datenwissenschaftler genießen in diesem Bereich ein hohes Ansehen, ihre Einstellung ist jedoch auch am teuersten.
- Mangel an verfügbaren Daten, Datensicherheit und zeitaufwändige Implementierung des ML-Algorithmus.
- Für Unternehmen ist es schwierig, ein Umfeld zu schaffen, in dem Daten und ihre Vorteile voll genutzt werden können. Dieses Umfeld erfordert entsprechende Tools, Prozesse und Strategien.
3. Nur automatische ML-Tools (AutoML) reichen für die Förderung des maschinellen Lernens nicht aus.
Obwohl die automatische ML-Plattform eine rosige Zukunft hat, ist ihre Abdeckung noch recht begrenzt ML kann Datenwissenschaftler bald ersetzen. Auch über die Aussage gibt es Kontroversen.
Wenn Sie Self-Service Machine Learning erfolgreich in Ihrem Unternehmen einsetzen wollen, sind AutoML-Tools zwar entscheidend, aber auch der Prozess, die Methoden und Strategien müssen beachtet werden. AutoML-Plattformen sind nur Werkzeuge, und die meisten ML-Experten glauben, dass dies nicht ausreicht.
4. Den maschinellen Lernprozess aufschlüsseln

Jeder ML-Prozess beginnt mit Daten. Es ist allgemein anerkannt, dass die Datenvorbereitung der wichtigste Teil des ML-Prozesses ist und der Modellierungsteil nur einen Teil der gesamten Datenpipeline darstellt, während er durch AutoML-Tools vereinfacht wird. Der gesamte Arbeitsablauf erfordert noch viel Arbeit, um die Daten zu transformieren und dem Modell zuzuführen. Datenvorbereitung und Datentransformation können zu den zeitaufwändigsten und unangenehmsten Teilen der Arbeit gehören.
Darüber hinaus werden auch die Geschäftsdaten, die zum Training von ML-Modellen verwendet werden, regelmäßig aktualisiert. Daher müssen Unternehmen komplexe ETL-Pipelines aufbauen, die komplexe Tools und Prozesse beherrschen. Daher ist die Sicherstellung der Kontinuität und Echtzeitfähigkeit des ML-Prozesses ebenfalls eine anspruchsvolle Aufgabe.
5. ML mit Anwendungen integrieren
Gehen wir nun davon aus, dass wir das ML-Modell erstellt haben und es dann bereitstellen müssen. Der klassische Bereitstellungsansatz behandelt es als Komponente der Anwendungsschicht, wie unten gezeigt:
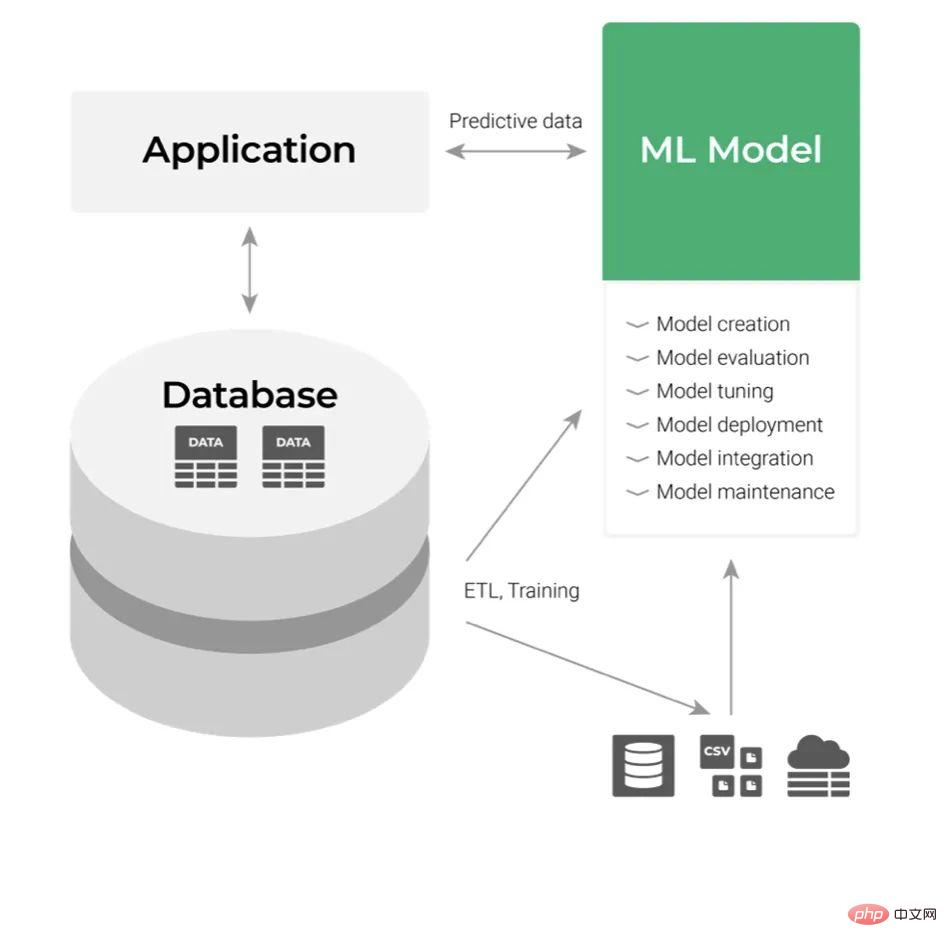
Seine Eingabe sind die Daten und die Ausgabe ist die Vorhersage, die wir erhalten. Nutzen Sie die Ausgabe von ML-Modellen, indem Sie die APIs dieser Anwendungen integrieren. Aus Entwicklersicht scheint das alles einfach zu sein, nicht jedoch, wenn man über den Prozess nachdenkt. In einer großen Organisation kann die Integration und Wartung von Geschäftsanwendungen recht umständlich sein. Auch wenn das Unternehmen technisch versiert ist, muss jede Anfrage nach Codeänderungen einen spezifischen Überprüfungs- und Testprozess über mehrere Abteilungsebenen hinweg durchlaufen. Dies wirkt sich negativ auf die Flexibilität aus und erhöht die Komplexität des gesamten Arbeitsablaufs.
Wenn beim Testen verschiedener Konzepte und Ideen genügend Flexibilität vorhanden ist, wird die ML-basierte Entscheidungsfindung viel einfacher sein und daher werden die Menschen Produkte mit Selbstbedienungsfunktionen bevorzugen.
6. Self-Service-Maschinelles Lernen/intelligente Datenbank?
Wie wir oben gesehen haben, sind Daten der Kern des ML-Prozesses, bestehende ML-Tools nehmen die Daten auf und geben Vorhersagen zurück, und diese Vorhersagen liegen ebenfalls in Form von Daten vor.
Jetzt stellt sich die Frage:
- Warum sollten wir ML als eigenständige Anwendung behandeln und eine komplexe Integration zwischen ML-Modellen, -Anwendungen und -Datenbanken implementieren?
- Warum ML nicht zu einer Kernfunktion der Datenbank machen?
- Warum nicht ML-Modelle über Standard-Datenbanksyntax wie SQL verfügbar?
Lassen Sie uns die oben genannten Probleme und ihre Herausforderungen analysieren, um ML-Lösungen zu finden.
Herausforderung Nr. 1: Komplexe Datenintegration und ETL-Pipelines
Die Aufrechterhaltung komplexer Datenintegration und ETL-Pipelines zwischen ML-Modellen und Datenbanken ist eine der größten Herausforderungen für ML-Prozesse.
SQL ist ein hervorragendes Datenmanipulationstool, daher können wir dieses Problem lösen, indem wir ML-Modelle in die Datenschicht einführen. Mit anderen Worten: Das ML-Modell lernt in der Datenbank und gibt Vorhersagen zurück.
Herausforderung Nr. 2: Integration von ML-Modellen mit Anwendungen
Die Integration von ML-Modellen mit Geschäftsanwendungen über APIs ist eine weitere Herausforderung.
Geschäftsanwendungen und BI-Tools sind eng mit Datenbanken gekoppelt. Wenn das AutoML-Tool Teil der Datenbank wird, können wir daher die Standard-SQL-Syntax verwenden, um Vorhersagen zu treffen. Darüber hinaus ist eine API-Integration zwischen ML-Modellen und Geschäftsanwendungen nicht mehr erforderlich, da sich die Modelle in der Datenbank befinden.
Lösung: Einbetten von AutoML in die Datenbank
Das Einbetten von AutoML-Tools in die Datenbank bringt viele Vorteile mit sich, wie zum Beispiel:
- Jeder, der mit Daten arbeitet und SQL versteht (Datenanalyst oder Datenwissenschaftler), kann die Vorteile des maschinellen Lernens nutzen.
- Softwareentwickler können ML effizienter in Geschäftstools und -anwendungen einbetten.
- Keine komplexe Integration zwischen Daten und Modellen sowie zwischen Modellen und Geschäftsanwendungen erforderlich.
Auf diese Weise ändert sich das obige relativ komplexe Integrationsdiagramm wie folgt:
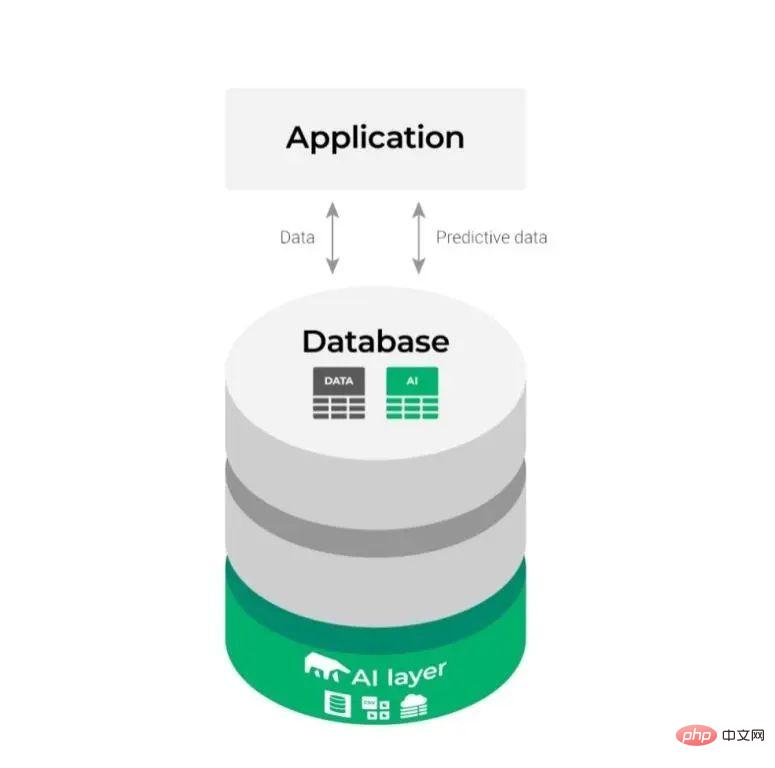
Es sieht einfacher aus und macht den ML-Prozess reibungsloser und effizienter.
7. So implementieren Sie Self-Service-ML mithilfe von Modellen als virtuelle Datenbanktabellen
Der nächste Schritt bei der Lösungsfindung ist die Implementierung.
Dafür verwenden wir eine Struktur namens AI Tables. Es bringt maschinelles Lernen in Form virtueller Tabellen auf die Datenplattform. Sie kann wie jede andere Datenbanktabelle erstellt und dann für Anwendungen, BI-Tools und DB-Clients verfügbar gemacht werden. Wir treffen Vorhersagen, indem wir einfach die Daten abfragen.
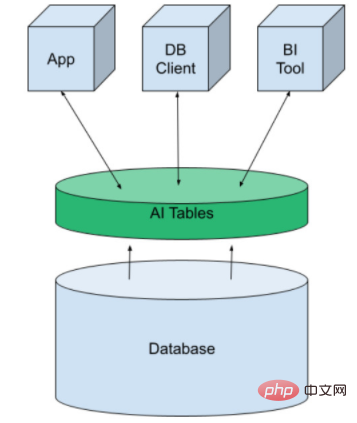
AI Tables wurde ursprünglich von MindsDB entwickelt und ist als Open Source oder Managed Cloud Service verfügbar. Sie integrieren traditionelle SQL- und NoSQL-Datenbanken wie Kafka und Redis.
8. Verwendung von AI Tables
Das Konzept von AI Tables ermöglicht es uns, den ML-Prozess in der Datenbank durchzuführen, sodass alle Schritte des ML-Prozesses (d. h. Datenvorbereitung, Modelltraining und Vorhersage) über die Datenbank durchgeführt werden können.
- KI-Tabellen trainieren
Zuerst müssen Benutzer eine KI-Tabelle entsprechend ihren eigenen Anforderungen erstellen, die einem maschinellen Lernmodell ähnelt und Funktionen enthält, die den Spalten der Quelltabelle entsprechen die AutoML-Engine selbst Modellierungsaufgaben. Beispiele werden später gegeben.
- Treffen Sie Vorhersagen
Sobald die KI-Tabelle erstellt ist, ist sie ohne weitere Bereitstellung einsatzbereit. Um Vorhersagen zu treffen, führen Sie einfach eine Standard-SQL-Abfrage für die AI-Tabelle aus.
Sie können Vorhersagen einzeln oder stapelweise treffen. AI Tables kann viele komplexe maschinelle Lernaufgaben bewältigen, wie zum Beispiel multivariate Zeitreihen, Anomalieerkennung usw.
9.Arbeitsbeispiel für KI-Tabellen
Für Einzelhändler ist es eine komplexe Aufgabe, sicherzustellen, dass Produkte zum richtigen Zeitpunkt auf Lager sind. Wenn die Nachfrage steigt, steigt das Angebot. Basierend auf diesen Daten und maschinellem Lernen können wir vorhersagen, wie viel Lagerbestand ein bestimmtes Produkt an einem bestimmten Tag haben sollte, was zu mehr Umsatz für Einzelhändler führt.
Zuerst müssen Sie die folgenden Informationen verfolgen und eine KI-Tabelle erstellen:
- Verkaufsdatum des Produkts (Verkaufsdatum)
- Geschäft des verkauften Produkts (Shop)
- Spezifisches verkauftes Produkt (Produktcode)
- Verkaufte Produktmenge (Menge)
Wie in der Abbildung unten gezeigt:
(1) KI-Tabellen trainieren
Um KI-Tabellen zu erstellen und zu trainieren, müssen Sie MindsDB zunächst den Zugriff auf die Daten erlauben. Detaillierte Anweisungen finden Sie in der MindsDB-Dokumentation.
AI-Tabellen sind wie ML-Modelle und erfordern historische Daten, um sie zu trainieren.
Im Folgenden wird ein einfacher SQL-Befehl verwendet, um eine AITable zu trainieren:

Lassen Sie uns diese Abfrage analysieren:
- Verwenden Sie die CREATE PREDICTOR-Anweisung in MindsDB.
- Definieren Sie die Quelldatenbank basierend auf historischen Daten.
- Trainieren Sie die KI-Tabelle basierend auf der historischen Datentabelle (historical_table), und die ausgewählten Spalten (Spalte_1 und Spalte_2) sind Funktionen, die für die Vorhersage verwendet werden.
- AutoML erledigt die verbleibenden Modellierungsaufgaben automatisch.
- MindsDB identifiziert den Datentyp jeder Spalte, normalisiert und codiert ihn und erstellt und trainiert das ML-Modell.
Gleichzeitig können Sie die allgemeine Genauigkeit und Zuverlässigkeit jeder Vorhersage sehen und abschätzen, welche Spalten (Merkmale) für das Ergebnis wichtiger sind.
In Datenbanken müssen wir häufig Aufgaben verarbeiten, die multivariate Zeitreihendaten mit hoher Kardinalität beinhalten. Mit herkömmlichen Methoden ist ein erheblicher Aufwand erforderlich, um solche ML-Modelle zu erstellen. Wir müssen die Daten gruppieren und basierend auf einem bestimmten Zeit-, Datums- oder Zeitstempel-Datenfeld sortieren.
Zum Beispiel prognostizieren wir die Anzahl der verkauften Hämmer in einem Baumarkt. Nun, die Daten werden nach Filiale und Produkt gruppiert und es werden Vorhersagen für jede unterschiedliche Filiale und Produktkombination erstellt. Dies bringt uns zu dem Problem, für jede Gruppe ein Zeitreihenmodell zu erstellen.
Das klingt nach einem riesigen Projekt, aber MindsDB bietet eine Methode zum Erstellen eines einzelnen ML-Modells mithilfe der GROUP BY-Anweisung, um multivariate Zeitreihendaten auf einmal zu trainieren. Sehen wir uns an, wie es mit nur einem SQL-Befehl gemacht wird:

Der stock_forecaster-Prädiktor wird erstellt, um vorherzusagen, wie viele Artikel ein bestimmtes Geschäft in Zukunft verkaufen wird . Die Daten werden nach Verkaufsdatum sortiert und nach Filiale gruppiert. So können wir den Umsatz für jedes Geschäft vorhersagen. (2) Batch-Vorhersage Erhalten Sie Stapelvorhersagen für viele Datensätze gleichzeitig.
Weitere Informationen zum Analysieren und Visualisieren von Vorhersagen in BI-Tools finden Sie in diesem Artikel. (3) Praktische Anwendung
(3) Praktische Anwendung
Der traditionelle Ansatz behandelt ML-Modelle als unabhängige Anwendungen, die die Wartung von ETL-Pipelines zur Datenbank und die API-Integration in Geschäftsanwendungen erfordern. Obwohl AutoML-Tools den Modellierungsteil einfach und unkompliziert machen, erfordert die Verwaltung des gesamten ML-Workflows immer noch erfahrene Experten. Tatsächlich ist die Datenbank bereits das bevorzugte Werkzeug für die Datenaufbereitung, daher ist es sinnvoller, ML in die Datenbank einzuführen, als Daten in ML einzuführen. Da sich AutoML-Tools in der Datenbank befinden, bietet das AI-Tables-Konstrukt von MindsDB Datenanwendern Self-Service-AutoML und optimiert Arbeitsabläufe für maschinelles Lernen.
Originallink: https://dzone.com/articles/self-service-machine-learning-with-intelligent-datEinführung des Übersetzers Zhang Yi, 51CTO-Community-Redakteur, Ingenieur mittlerer Ebene. Erforscht hauptsächlich die Implementierung von Algorithmen und Szenarioanwendungen für künstliche Intelligenz, verfügt über ein Verständnis und eine Beherrschung von Algorithmen für maschinelles Lernen und automatische Steuerungsalgorithmen und wird weiterhin auf die Entwicklungstrends der Technologie für künstliche Intelligenz im In- und Ausland achten, insbesondere auf die Anwendung künstlicher Intelligenz Intelligenztechnologie in intelligenten vernetzten Autos und Smart Homes. Spezifische Implementierung und Anwendungen in anderen Bereichen.
Das obige ist der detaillierte Inhalt vonSelf-Service-Maschinelles Lernen basierend auf intelligenten Datenbanken. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr