
Heim >Technologie-Peripheriegeräte >KI >Um die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung
Um die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 15:41:111018Durchsuche
Aufgaben zur Textgenerierung werden normalerweise mithilfe von Lehrererzwingung trainiert. Diese Trainingsmethode ermöglicht es dem Modell, während des Trainingsprozesses nur positive Proben zu sehen. Es gibt jedoch normalerweise bestimmte Einschränkungen zwischen dem Generierungsziel und der Eingabe. Diese Einschränkungen spiegeln sich normalerweise in Schlüsselelementen im Satz wider. Beispielsweise kann „McDonalds bestellen“ nicht in „KFC bestellen“ geändert werden spielt eine Rolle. Das Schlüsselelement der Zurückhaltung sind Markenschlüsselwörter. Durch die Einführung kontrastiven Lernens und das Hinzufügen negativer Stichprobenmuster zum Generierungsprozess kann das Modell diese Einschränkungen effektiv lernen.
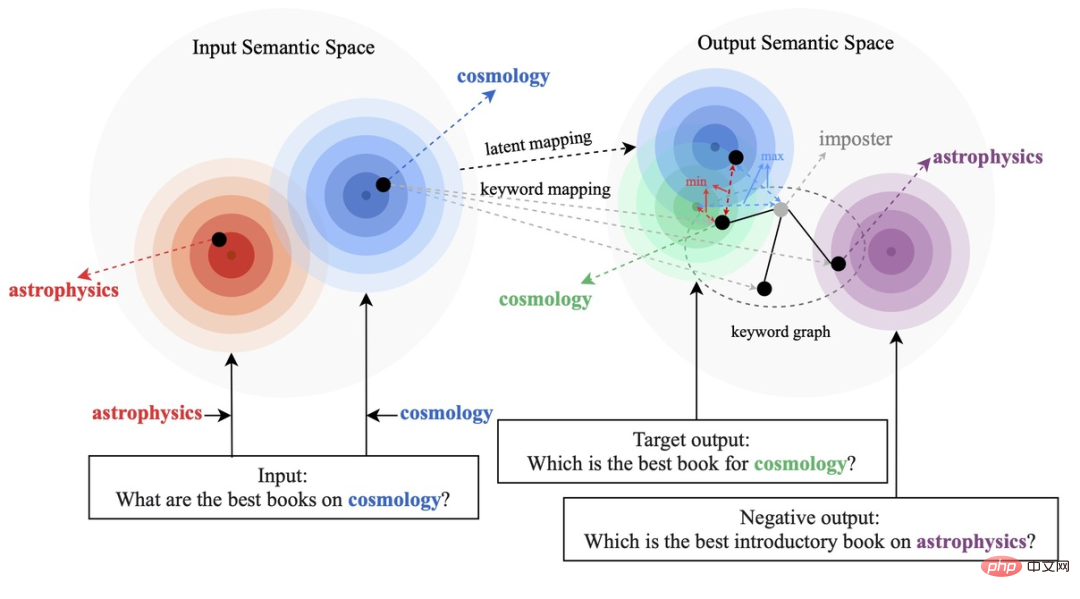
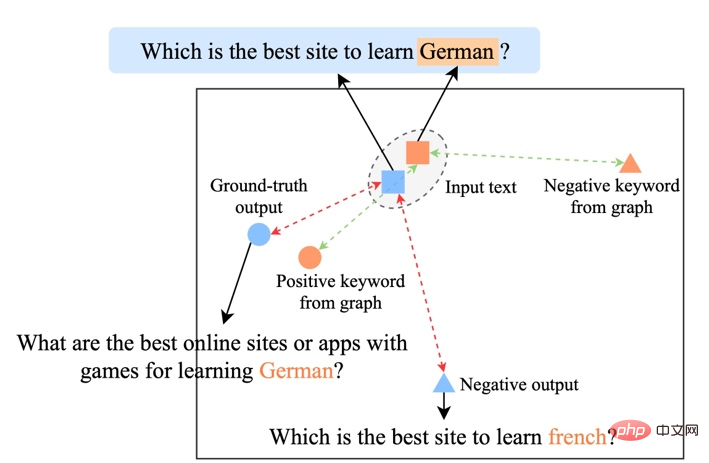
Bestehende kontrastive Lernmethoden konzentrieren sich hauptsächlich auf die gesamte Satzebene [1][2], während die Informationen wortgranularer Entitäten im Satz ignoriert werden. Das Beispiel in der folgenden Abbildung zeigt die Schlüsselwörter im Satz Die wichtige Bedeutung von Wörtern: Wenn die Schlüsselwörter eines Eingabesatzes ersetzt werden (z. B. Kosmologie -> Astrophysik), ändert sich die Bedeutung des Satzes und damit auch die Position im semantischen Raum (dargestellt durch die Verteilung). Als wichtigste Information in einem Satz entsprechen Schlüsselwörter einem Punkt in der semantischen Verteilung, der weitgehend die Position der Satzverteilung bestimmt. Gleichzeitig sind in manchen Fällen die vorhandenen kontrastiven Lernziele für das Modell zu einfach, was dazu führt, dass das Modell nicht in der Lage ist, die Schlüsselinformationen zwischen positiven und negativen Beispielen wirklich zu lernen.
Auf dieser Grundlage haben Forscher der Ant Group, der Peking-Universität und anderer Institutionen eine Methode zur Erzeugung von Kontrasten mit mehreren Granularitäten vorgeschlagen, eine hierarchische Kontraststruktur entworfen, Informationen auf verschiedenen Ebenen verbessert und das Lernen auf Satzgranularität verbessert Die Gesamtsemantik verbessert lokal wichtige Informationen auf Wortgranularität. Forschungsarbeit wurde für ACL 2022 angenommen.

Papieradresse: https://aclanthology.org/2022.acl-long.304.pdf
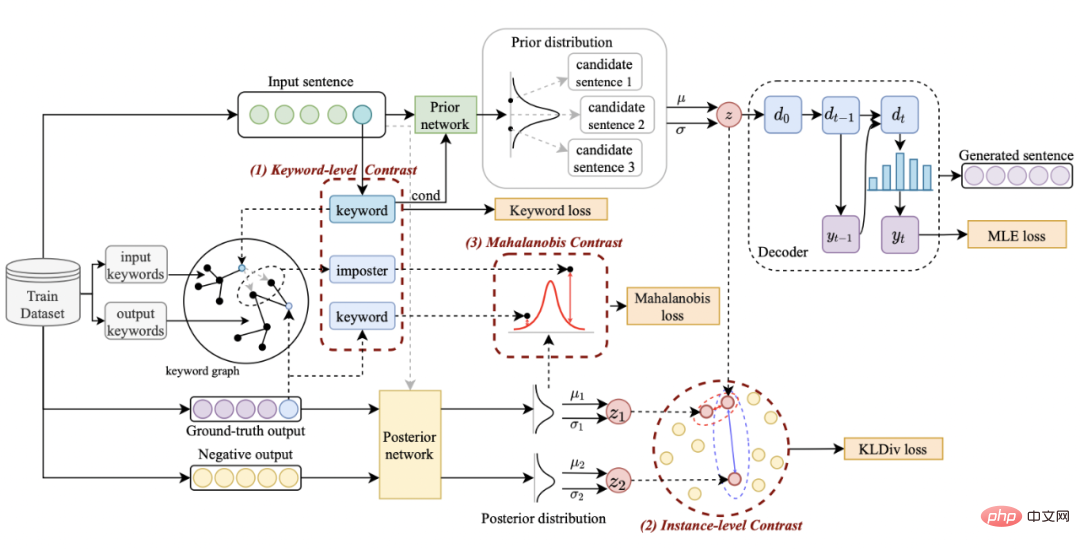
Methode
Unser Ansatz basiert auf klassisch Im CVAE-Textgenerierungsframework [3][4] kann jeder Satz einer Verteilung im Vektorraum zugeordnet werden, und die Schlüsselwörter im Satz können als aus dieser Verteilung abgetasteter Punkt betrachtet werden. Einerseits verbessern wir den Ausdruck der latenten Raumvektorverteilung durch den Vergleich der Satzgranularität. Andererseits verbessern wir den Ausdruck der Schlüsselwortpunktgranularität durch den konstruierten globalen Schlüsselwortgraphen Verteilung von Schlüsselwortpunkten und Sätzen zwischen Konstruktebenen, um den Informationsausdruck auf zwei Granularitäten zu verbessern. Die endgültige Verlustfunktion wird durch Addition dreier verschiedener kontrastiver Lernverluste erhalten.
Satzgranulares vergleichendes Lernen
Auf Instanzebene verwenden wir die ursprüngliche Eingabe x, die Zielausgabe

und die entsprechenden negativen Ausgabeproben Bilden Sie einen Satz Paargrößenvergleich
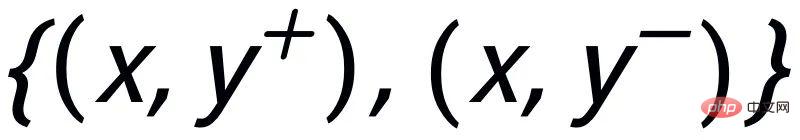
. Wir verwenden ein Prior-Netzwerk, um die Prior-Verteilung zu lernen
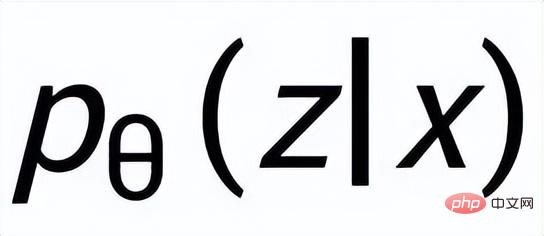
, bezeichnet als
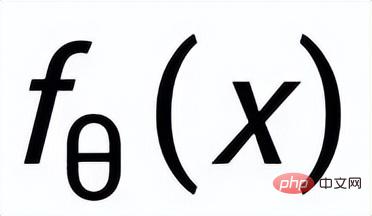
; wir verwenden ein Posterior-Netzwerk, um die ungefähre Posterior-Verteilung zu lernen
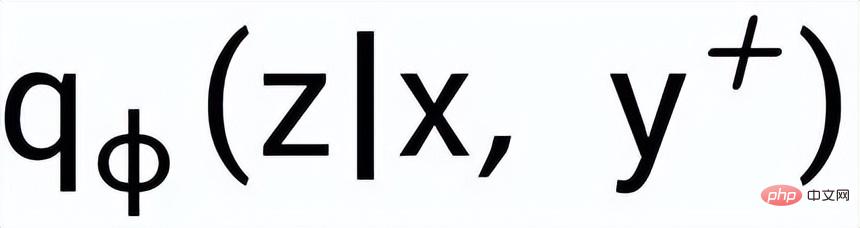
und
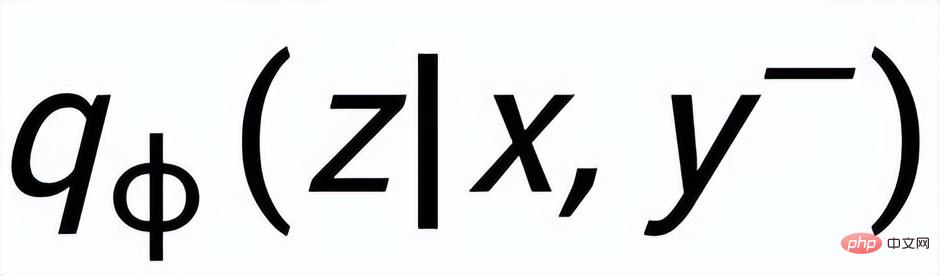
werden als
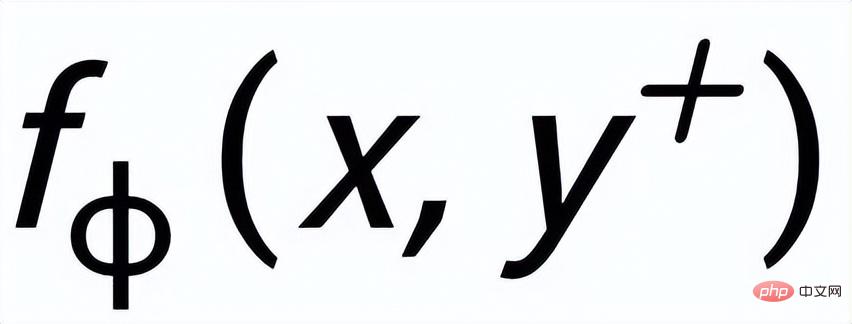
und
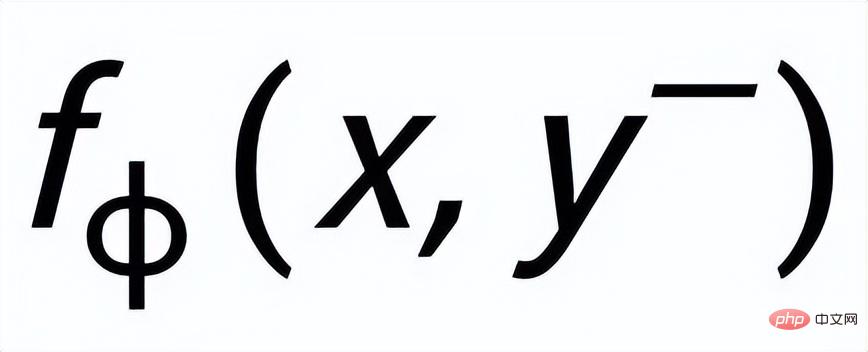
bzw. . Das Ziel des satzgranularen vergleichenden Lernens besteht darin, den Abstand zwischen der vorherigen Verteilung und der positiven hinteren Verteilung so weit wie möglich zu verringern und gleichzeitig den Abstand zwischen der vorherigen Verteilung und der negativen hinteren Verteilung zu maximieren wie folgt:
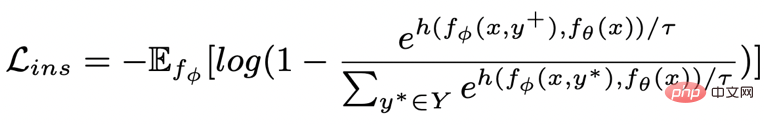
wobei eine positive Probe oder eine negative Probe ist und der Temperaturkoeffizient ist, der zur Darstellung der Abstandsmessung verwendet wird. Hier verwenden wir die KL-Divergenz (Kullback-Leibler-Divergenz) [5 ], um den direkten Abstand zwischen zwei Verteilungen zu messen.
Keyword-granulares vergleichendes Lernen
- Keyword-Netzwerk
Vergleichendes Lernen der Keyword-Granularität wird verwendet, um dem Modell mehr Aufmerksamkeit zu schenken Wörter im Satz Information Dieses Ziel erreichen wir, indem wir ein Keyword-Diagramm erstellen, das die positiven und negativen Beziehungen verwendet, die dem Eingabe- und Ausgabetext entsprechen. Konkret können wir anhand eines gegebenen Satzpaares

jeweils ein Schlüsselwort

und

bestimmen ( Für die Schlüsselwortextraktionsmethode: Ich verwende den klassischen TextRank-Algorithmus [6]).

, wobei jeder Satz

ein Paar positiver und negativer Beispielausgabesätze
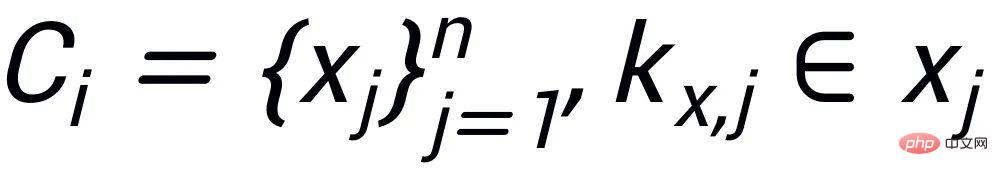
hat, sie haben Ein positives Schlüsselwort
und ausschließende Beispiel-Keywords
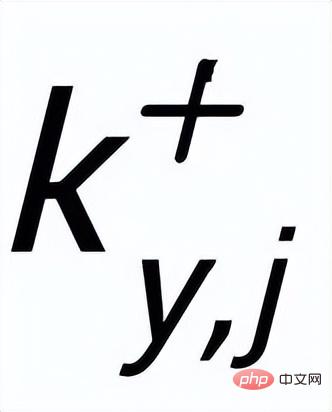
. Auf diese Weise kann in der gesamten Sammlung für jeden Ausgabesatz

das entsprechende Schlüsselwort

und jedes umgebende
 berücksichtigt werden
berücksichtigt werden
(verbunden durch positive und negative Beziehungen zwischen Sätzen)
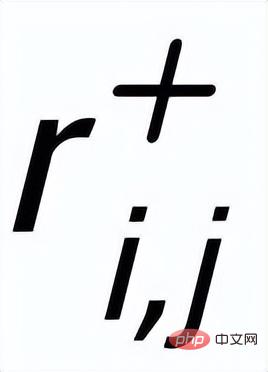
, und es gibt eine positive Kante zwischen jeder umgebenden

 . Basierend auf diesen Schlüsselwortknoten und ihren direkten Kanten können wir ein Schlüsselwortdiagramm erstellen. Wir verwenden BERT-Einbettung [7], während jeder Knoten initialisiert und verwendet wird eine MLP-Ebene, um die Darstellung jeder Kante zu lernen
. Basierend auf diesen Schlüsselwortknoten und ihren direkten Kanten können wir ein Schlüsselwortdiagramm erstellen. Wir verwenden BERT-Einbettung [7], während jeder Knoten initialisiert und verwendet wird eine MLP-Ebene, um die Darstellung jeder Kante zu lernen
 . Wir aktualisieren die Knoten und Kanten im Schlüsselwortnetzwerk iterativ über eine GAT-Schicht (Graph Attention) und eine MLP-Schicht. In jeder Iteration aktualisieren wir zunächst die Kantendarstellung auf folgende Weise:
. Wir aktualisieren die Knoten und Kanten im Schlüsselwortnetzwerk iterativ über eine GAT-Schicht (Graph Attention) und eine MLP-Schicht. In jeder Iteration aktualisieren wir zunächst die Kantendarstellung auf folgende Weise:
Hier

kann
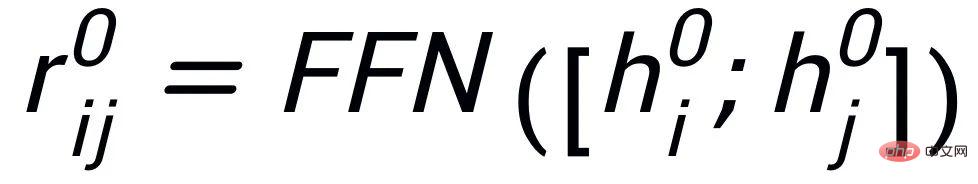
oder
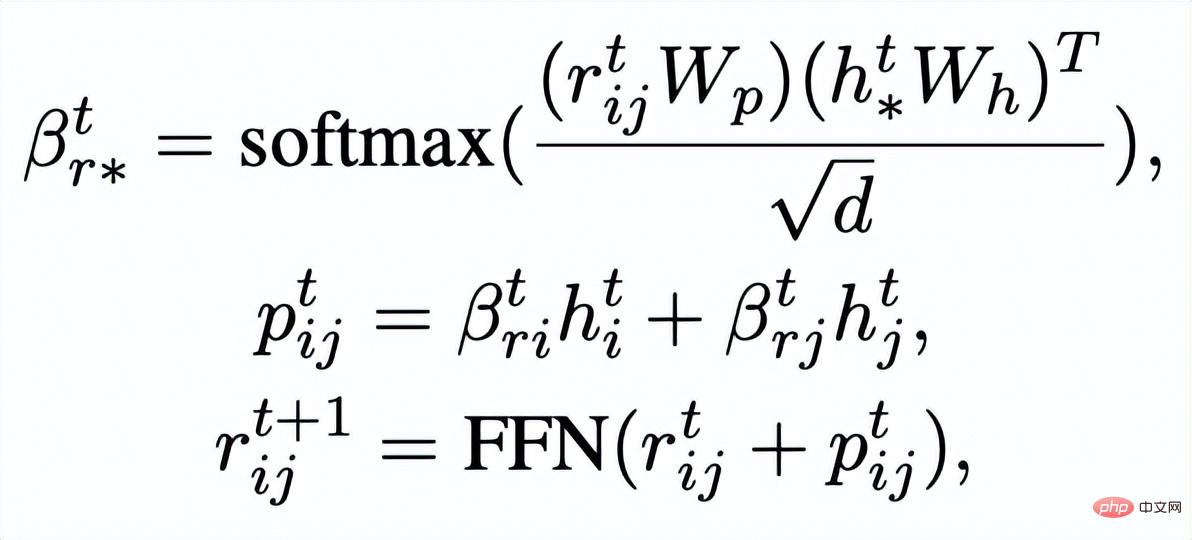
sein.

Dann basierend auf den aktualisierten Kanten
 Wir aktualisieren die Darstellung jedes Knotens über eine Diagramm-Aufmerksamkeitsschicht:
Wir aktualisieren die Darstellung jedes Knotens über eine Diagramm-Aufmerksamkeitsschicht:

ist das Aufmerksamkeitsgewicht. Um das Problem des verschwindenden Gradienten zu vermeiden, fügen wir eine Restverbindung zu
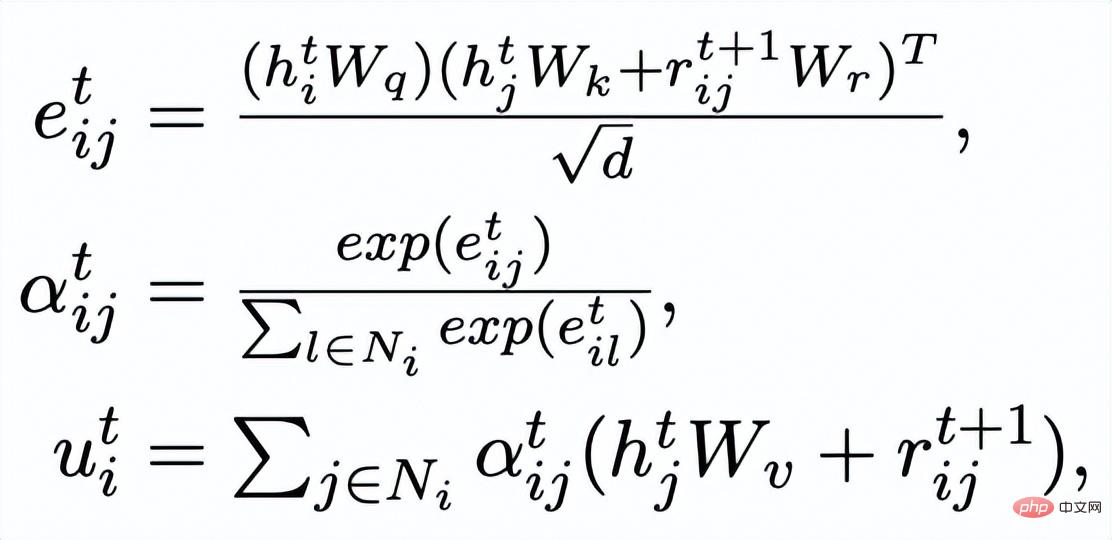
hinzu, um die Darstellung der Knoten in dieser Iteration zu erhalten
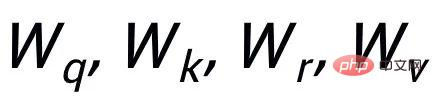
. Wir verwenden die Knotendarstellung der letzten Iteration als Darstellung des Schlüsselworts, bezeichnet als u.

Keyword-Vergleich

Der Vergleich der Keyword-Granularität erfolgt anhand der Keywords des Eingabesatzes

und ein Betrügerknoten
- . Wir zeichnen das aus der positiven Ausgabeprobe des Eingabesatzes extrahierte Schlüsselwort als
auf, und sein negativer Nachbarknoten im obigen Schlüsselwortnetzwerk wird als

aufgezeichnet, dann

, der vergleichende Lernverlust der Keyword-Granularität wird wie folgt berechnet:

hier

wird verwendet, um sich auf
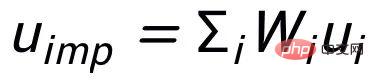
zu beziehen
oder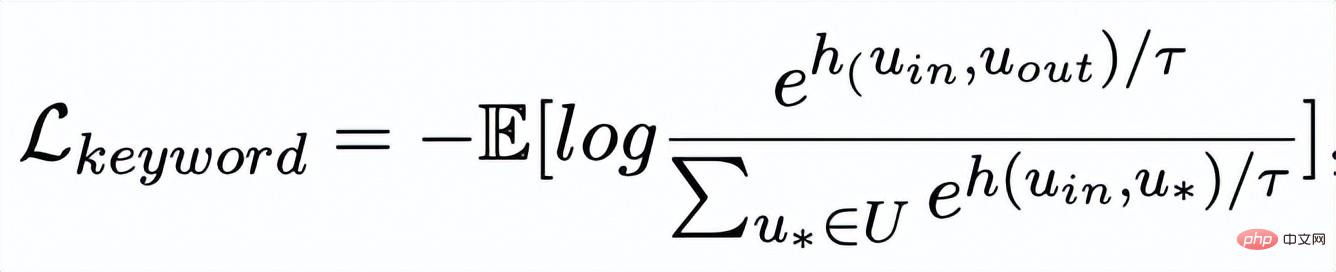
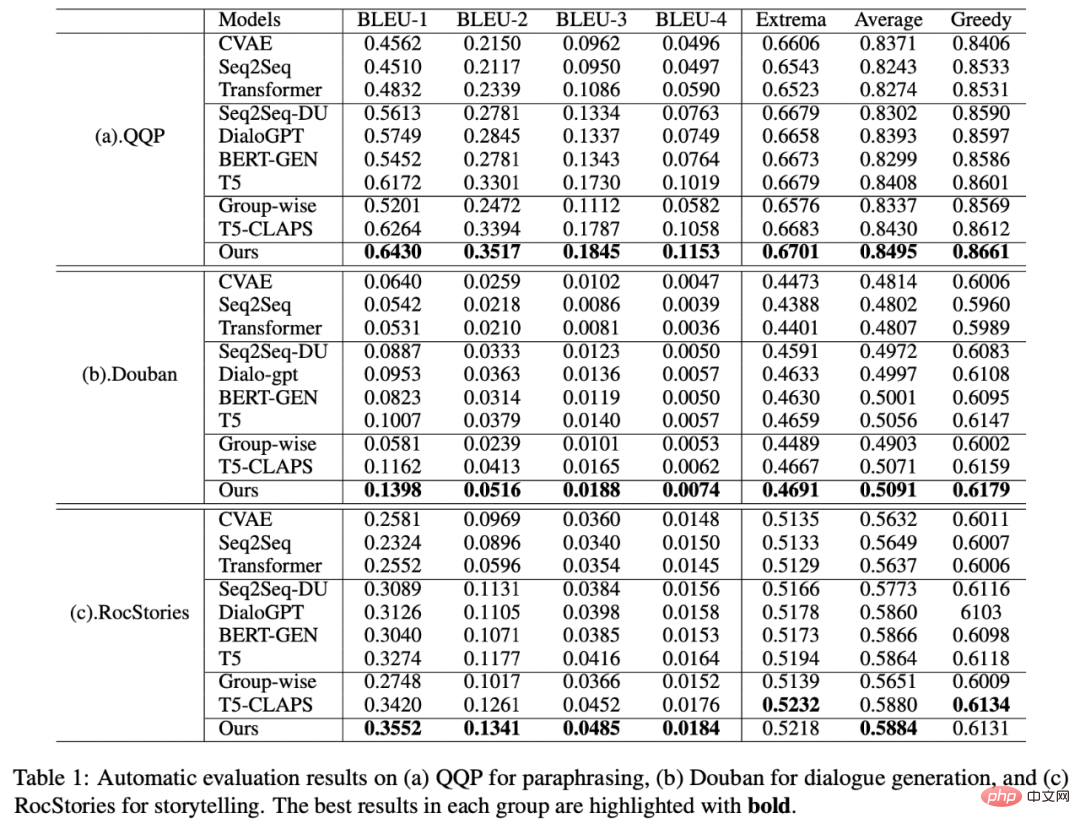
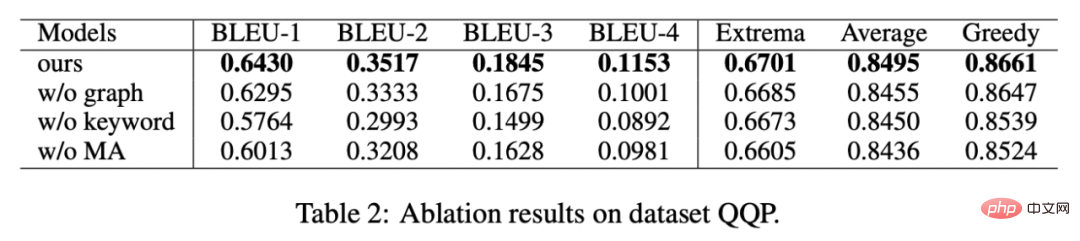
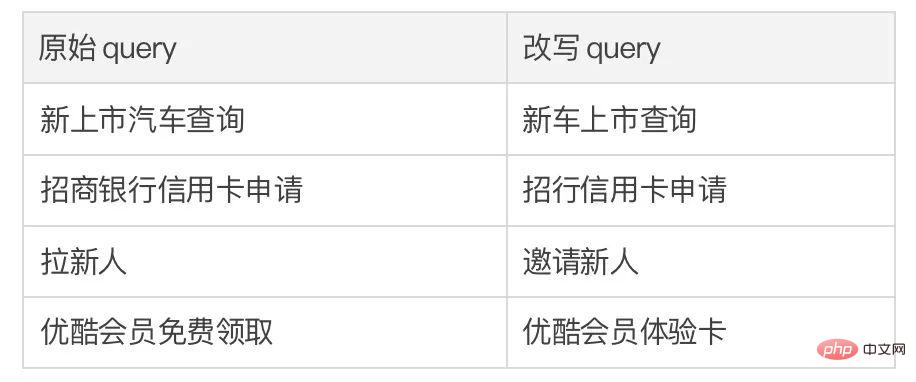
, h(·) wird verwendet, um das Abstandsmaß darzustellen. Beim vergleichenden Lernen der Schlüsselwortgranularität wählen wir die Kosinusähnlichkeit, um den Abstand zwischen zwei Punkten zu berechnen. Es ist zu beachten, dass das obige kontrastive Lernen der Satzgranularität und der Schlüsselwortgranularität jeweils an der Verteilung und am Punkt implementiert wird, so dass ein unabhängiger Vergleich der zwei Granularitäten sind möglich. Der Verstärkungseffekt wird durch kleinere Unterschiede abgeschwächt. In diesem Zusammenhang konstruieren wir eine vergleichende Assoziation zwischen verschiedenen Granularitäten basierend auf dem Mahalanobis-Abstand [8] zwischen Punkten und Verteilungen, sodass der Abstand zwischen dem Zielausgabeschlüsselwort und der Satzverteilung so gering wie möglich ist, sodass der Abstand zwischen den Imposter und die Verteilung ist so klein wie möglich. Dies gleicht den Mangel aus, dass der unabhängige Vergleich jeder Partikelgröße zum Verschwinden des Kontrasts führen kann. Insbesondere hofft das granularitätsübergreifende Mahalanobis-Distanzkontrastlernen, den Abstand zwischen der hinteren semantischen Verteilung der Sätze und so weit wie möglich zu verringern und gleichzeitig den Abstand dazwischen zu vergrößern Sie so weit wie möglich. Der Abstand zwischen ihm und ist wie folgt: hier wird auch verwendet. Siehe oder , und h(·) ist der Mahalanobis-Abstand. Wir haben an drei öffentlichen Datensätzen gearbeitet: Douban (Dialog) [9], QQP (Paraphrasierung) [10][11] und cStories-Experimente wurden am Thema (Storytelling) [12] durchgeführt und erzielten SOTA-Ergebnisse. Die von uns verglichenen Basislinien umfassen traditionelle generative Modelle (z. B. CVAE[13], Seq2Seq[14], Transformer[15]) und Methoden, die auf vorab trainierten Modellen basieren (z. B. Seq2Seq-DU[16], DialoGPT[17], BERT-GEN [7], T5[18]) und Methoden, die auf kontrastivem Lernen basieren (z. B. Group-wise[9], T5-CLAPS[19]). Wir berechnen den BLEU-Score[20] und den BOW-Einbettungsabstand (extrema/durchschnittlich/gierig)[21] zwischen Satzpaaren als automatisierte Bewertungsindikatoren. Die Ergebnisse sind in der folgenden Abbildung dargestellt: Wir Für den QQP-Datensatz werden auch drei Annotatoren verwendet: T5-CLAPS, DialoGPT, Seq2Seq-DU und die von unserem Modell generierten Ergebnisse Wir haben Ablationsanalyseexperimente durchgeführt, um herauszufinden, ob Schlüsselwörter, Schlüsselwortnetzwerke und die Mahalanobis-Distanzvergleichsverteilung verwendet werden sollen. Die Ergebnisse zeigen, dass diese drei Designs tatsächlich eine Rolle spielen Endergebnisse spielen eine wichtige Rolle. Die experimentellen Ergebnisse sind in der folgenden Abbildung dargestellt. Um die Rolle des kontrastiven Lernens auf verschiedenen Ebenen zu untersuchen, visualisierten wir die zufällig ausgewählten Fälle und führten eine Dimensionsreduktion durch t-sne[22] durch, um die zu erhalten folgendes Bild. Aus der Abbildung ist ersichtlich, dass die Darstellung des Eingabesatzes nahe an der Darstellung des extrahierten Schlüsselworts liegt, was zeigt, dass Schlüsselwörter als wichtigste Informationen im Satz normalerweise die Position der semantischen Verteilung bestimmen. Darüber hinaus können wir beim kontrastiven Lernen sehen, dass die Verteilung der Eingabesätze nach dem Training näher an positiven Stichproben und weiter von negativen Stichproben entfernt ist, was zeigt, dass kontrastives Lernen dabei helfen kann, die semantische Verteilung zu korrigieren. Abschließend untersuchen wir die Auswirkungen der Stichprobe verschiedener Schlüsselwörter. Wie in der folgenden Tabelle dargestellt, stellen wir für eine Eingabefrage Schlüsselwörter als Bedingungen bereit, um die semantische Verteilung durch TextRank-Extraktion bzw. Zufallsauswahlmethoden zu steuern und die Qualität des generierten Texts zu überprüfen. Schlüsselwörter sind die wichtigste Informationseinheit in einem Satz. Unterschiedliche Schlüsselwörter führen zu unterschiedlichen semantischen Verteilungen und führen zu unterschiedlichen Tests. Je mehr Schlüsselwörter ausgewählt werden, desto genauer sind die generierten Sätze. Mittlerweile sind auch die von anderen Modellen generierten Ergebnisse in der folgenden Tabelle aufgeführt. In diesem Artikel schlagen wir einen granularitätsübergreifenden hierarchischen kontrastiven Lernmechanismus vor, der bei der Arbeit mit mehreren textgenerierten Datensätzen mehr als wettbewerbsfähig ist. Das auf dieser Arbeit basierende Modell zum Umschreiben von Abfragen wurde erfolgreich in das tatsächliche Geschäftsszenario der Alipay-Suche implementiert und erzielte bemerkenswerte Ergebnisse. Die Dienste in der Suche von Alipay decken ein breites Spektrum an Bereichen ab und weisen erhebliche Domänenmerkmale auf. Es besteht ein großer wörtlicher Unterschied zwischen dem Suchabfrageausdruck des Benutzers und dem Dienstausdruck, was es schwierig macht, ideale Ergebnisse durch direkten Abgleich anhand von Schlüsselwörtern zu erzielen Wenn der Benutzer beispielsweise die Abfrage „Neu gestartete Autoabfrage“ eingibt, kann er sich nicht an den Dienst „Neu gestartete Autoabfrage“ erinnern. Das Ziel des Umschreibens der Abfrage besteht darin, die vom Benutzer eingegebene Abfrage so umzuschreiben, dass sie näher an der Abfrage liegt Dienstausdruck, während die Abfrageabsicht unverändert bleibt, um eine bessere Übereinstimmung mit dem Zieldienst zu erzielen. Hier sind einige Beispiele für Umformulierungen: 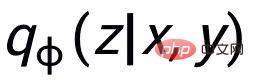


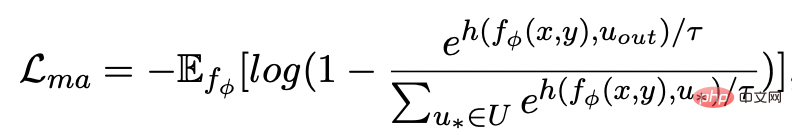



Experiment & Analyse
Experimentelle Ergebnisse
Ablationsanalyse
Visuelle Analyse
Keyword-Wichtigkeitsanalyse

Geschäftsanwendungen
Das obige ist der detaillierte Inhalt vonUm die Alipay-Sucherfahrung zu verbessern, verwenden Ant und die Peking-Universität ein hierarchisches Framework zur vergleichenden Lerntextgenerierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr