
Heim >Technologie-Peripheriegeräte >KI >Ein weiteres Artefakt zur Modellinterpretation für maschinelles Lernen: Shapash
Ein weiteres Artefakt zur Modellinterpretation für maschinelles Lernen: Shapash

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 15:11:111436Durchsuche

Was ist Shapash? Die Interpretierbarkeit und Verständlichkeit von Modellen stand im Mittelpunkt vieler Forschungsarbeiten und Open-Source-Projekte. Und viele Projekte sind mit Datenexperten und geschulten Fachkräften besetzt.
Shapash funktioniert mit den meisten Sklearn-, Lightgbm-, Xgboost- und Catboost-Modellen und kann für Klassifizierungs- und Regressionsaufgaben verwendet werden. Es verwendet das Shap-Backend, um den lokalen Beitrag von Features zu berechnen. Dies kann jedoch durch eine andere Strategie zur Berechnung des lokalen Beitrags ersetzt werden. Datenwissenschaftler können den Shapash-Interpreter nutzen, um ihre Modelle zu untersuchen und Fehler zu beheben, oder ihn einsetzen, um Visualisierungen jeder Schlussfolgerung bereitzustellen. Und es können auch Webanwendungen erstellt werden, die Endkunden und Unternehmern einen enormen Mehrwert bieten können. ?? Die Unterschiede zwischen globalen und lokalen Nachbarschaften können mithilfe einer Webanwendung leicht erkundet werden, um deren Modell schnell zu verstehen und zu verstehen, wie sich verschiedene Schlüsselpunkte auswirken:
 shapash-Bibliotheks-Webapp
shapash-Bibliotheks-Webapp
3. Zusammenfassung und Exporterklärung
Shapash kommt mit eine kurze und klare Erklärung. Es ermöglicht jedem Kunden, unabhängig von seinem Hintergrund, eine klare Erklärung des Hosting-Modells zu verstehen, da die Shapash-Funktionen zusammengefasst und klar erklärt werden.
4. Vollständiger Datenwissenschaftsbericht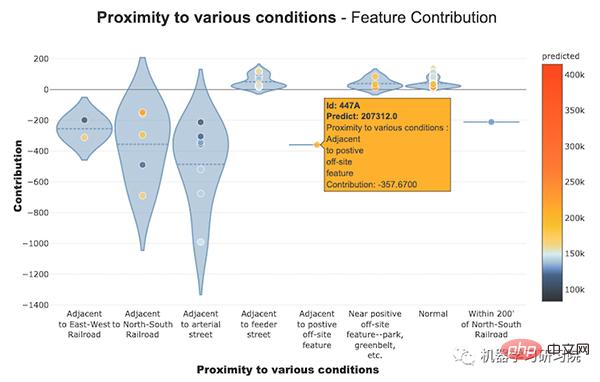 Der vollständige Datenbericht kann hier eingesehen werden: https://shapash-demo.ossbymaif.fr/
Der vollständige Datenbericht kann hier eingesehen werden: https://shapash-demo.ossbymaif.fr/
Shapash-Funktionen
Einige Funktionen von Shapash sind wie folgt:
1. Modell für maschinelles Lernen: Es eignet sich für Klassifizierungs- (Binär- oder Mehrklassenprobleme) und Regressionsprobleme. Es unterstützt mehrere Modelle wie Catboost, Xgboost, LightGBM, Sklearn Ensemble, lineare Modelle und SVM. 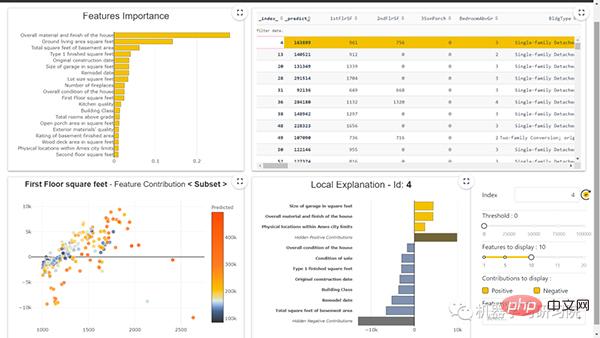
 6. Es bietet viele Optionen für Parameter, um präzise Ergebnisse zu erhalten.
6. Es bietet viele Optionen für Parameter, um präzise Ergebnisse zu erhalten.
7.Shapash ist einfach zu installieren und zu verwenden: Es bietet eine SmartExplainer-Klasse, um Ihr Modell zu verstehen und es mit einfacher Syntax zusammenzufassen und zu verdeutlichen.
8. Bereitstellung: Untersuchung und Bereitstellung (über API oder Batch-Modus) für den betrieblichen Einsatz sind wichtig. Erstellen Sie ganz einfach Webanwendungen, um von global nach lokal zu navigieren.
9. Hohe Vielseitigkeit: Um die Ergebnisse anzuzeigen, sind viele Argumente erforderlich. Doch je mehr Sie Ihre Daten bereinigen und archivieren, desto klarer werden die Ergebnisse für Ihre Endkunden sein.
So funktioniert Shapash Shapash ist eine Python-Bibliothek, die maschinelles Lernen leicht verständlich und interpretierbar macht. Datenbegeisterte können ihre Modelle leicht verstehen und teilen. Shapash verwendet Lime und Shap als Backend, um Ergebnisse in nur wenigen Codezeilen anzuzeigen. Shapash stützt sich auf verschiedene wichtige Fortschritte beim Aufbau von Modellen für maschinelles Lernen, um die Ergebnisse vernünftig zu machen. Das Bild unten zeigt den Workflow des Shapash-Pakets:So funktioniert Shapash
Wie es funktioniert
- Zuerst werden die Elemente jedes Schritts zusammengestellt, wie z. B. Datenvorbereitung, Feature-Engineering, Modellanpassung, Modellbewertung und Modellverständnis.
- Zweitens bietet es eine WebApp und Diagramme, um das Modell besser zu verstehen. Modellergebnisse können mit Kunden geteilt und besprochen werden.
- Abschließend erhalten Sie eine Zusammenfassung der Interpretierbarkeit.
Installation
Sie können Shapash mit dem folgenden Code installieren:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">shapash</span>
Für Jupyter Notebook: Wenn Sie Jupyter Notebook verwenden und Um das Inline-Diagramm anzuzeigen, müssen Sie einen anderen Befehl verwenden:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">ipywidgets</span>
Erste Schritte
Hier werden wir Shapash mithilfe des Datensatzes zur Hauspreisvorhersage untersuchen. Dies ist ein Regressionsproblem und wir müssen die Immobilienpreise vorhersagen. Zuerst analysieren wir den Datensatz, einschließlich univariater und bivariater Analysen, dann modellieren wir die Interpretierbarkeit mithilfe von Merkmalsbedeutung, Merkmalsbeitrag, lokalen Diagrammen und Vergleichsdiagrammen, dann modellieren wir die Leistung und schließlich WebApp.
Analysedatensatz
Univariate Analyse
Verwenden Sie das Bild unten, um den Namen First Floor Square Elements von zu verstehen Füße. Wir können eine Tabelle sehen, die verschiedene Statistiken für unsere Trainings- und Testdatensätze anzeigt, z. B. Mittelwert, Maximum, Minimum, Standardabweichung, Median und mehr. In der Abbildung rechts sehen Sie die Verteilungsdiagramme der Trainings- und Testdatensätze. Shapash erwähnt auch, ob unsere Funktionen kategorisch oder numerisch sind, und bietet außerdem eine Dropdown-Option, in der alle Funktionen verfügbar sind.
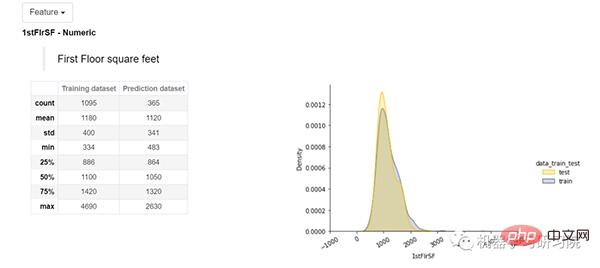
Univariate Analyse
Für kategoriale Funktionen zeigen die Trainings- und Testdatensätze nicht doppelte und fehlende Werte. Auf der rechten Seite wird ein Balkendiagramm angezeigt, das den Prozentsatz der entsprechenden Kategorie in jeder Funktion zeigt.
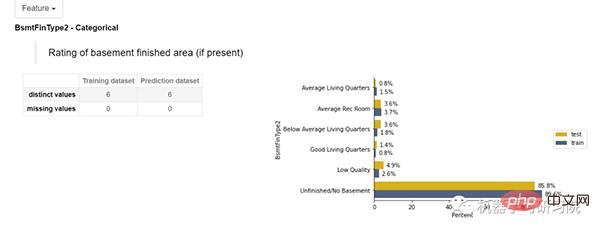
Kategorien in Funktionen
Zielanalyse
Sie können Sie auch eine detaillierte Analyse der Zielvariablen namens „Verkaufspreis“ sehen. Auf der linken Seite werden alle Statistiken wie Anzahl, Mittelwert, Standardabweichung, Minimum, Maximum, Median usw. für Trainings- und Vorhersagedatensätze angezeigt. Rechts werden die Verteilungen der Trainings- und Vorhersagedatensätze angezeigt.
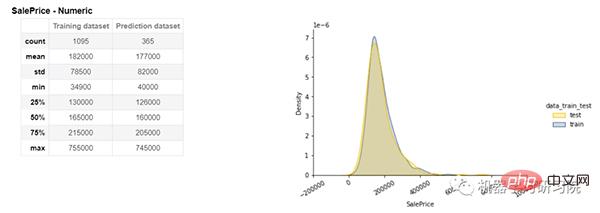
Objektive Analyse
Analyse mehrerer Variablen
oben Wir diskutieren univariate Analysen im Detail. In diesem Abschnitt werden wir uns mit der multivariaten Analyse befassen. Die folgende Abbildung zeigt die Korrelationsmatrix für die ersten 20 Features der Trainings- und Testdatensätze. Die Korrelationsskala wird auch anhand verschiedener Farben dargestellt. Auf diese Weise verwenden wir Shapash, um Beziehungen zwischen Features zu visualisieren. #? #
Durch die Verwendung dieser Bibliothek können wir die Bedeutung dieser Funktion erkennen. Die Merkmalswichtigkeit ist eine Methode zum Ermitteln der Bedeutung von Eingabemerkmalen bei der Vorhersage von Ausgabewerten. Die folgende Abbildung zeigt die Feature-Wichtigkeitskurve: 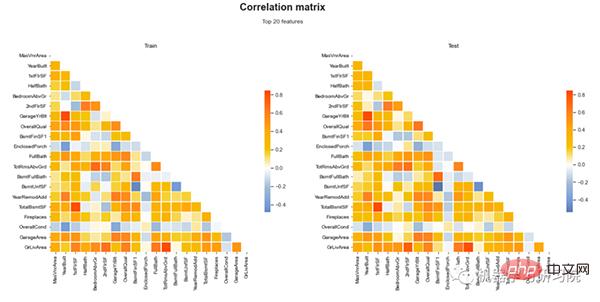
Feature-Wichtigkeitsdiagramm
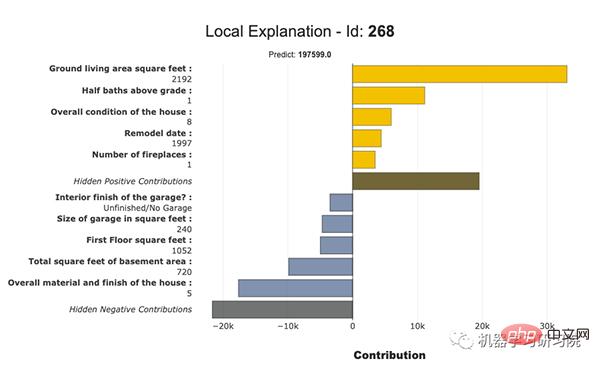
Feature-Beitragsdiagramm#🎜 🎜 #
Diese Kurven helfen uns bei der Beantwortung von Fragen, z. B. wie sich eine Funktion auf meine Vorhersagen auswirkt, ob ihr Beitrag positiv oder negativ ist usw. Dieses Diagramm verdeutlicht die Bedeutung der Interpretierbarkeit des Modells. Die Gesamtkonsistenz des Modells macht es wahrscheinlicher, die Auswirkungen von Features auf das Modell zu verstehen. Wir können die Beitragsdiagramme numerischer und kategorialer Merkmale sehen.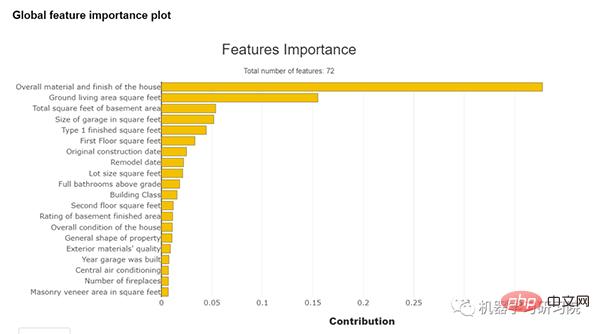
Beitragstabelle # 🎜🎜#Für Klassifizierungsmerkmale
Für Klassifizierungsmerkmale
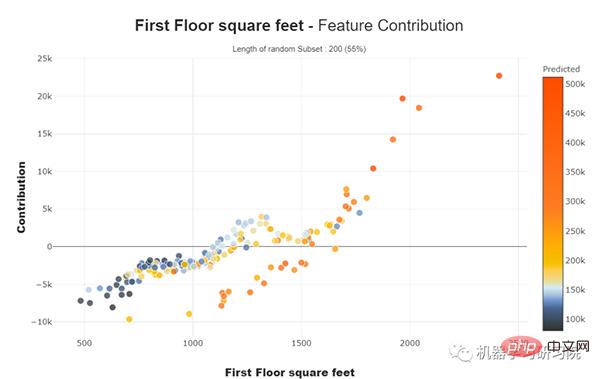
Teildiagramm
Vergleichsdiagramm
Wir können Vergleichsdiagramme zeichnen. Das Bild unten zeigt das Vergleichsdiagramm:
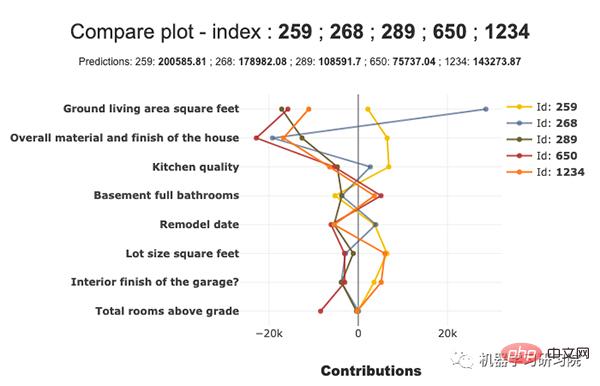
Vergleichsdiagramm
Modellleistung
Nach der Datenanalyse trainieren wir das Modell für maschinelles Lernen. Das Bild unten zeigt die Ausgabe unserer Vorhersage. Auf der linken Seite werden Statistiken wie Anzahl, Minimum, Maximum, Median, Standardabweichung usw. für die wahren und vorhergesagten Werte angezeigt. Rechts ist die Verteilung der vorhergesagten und tatsächlichen Werte dargestellt.
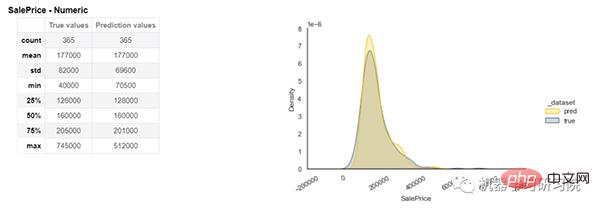
Modellleistung
WebApp
Nach dem Modelltraining können wir auch eine WebApp erstellen. Diese Web-App zeigt ein vollständiges Dashboard unserer Daten, einschließlich dessen, was wir bisher abgedeckt haben. Das Bild unten zeigt das Dashboard.
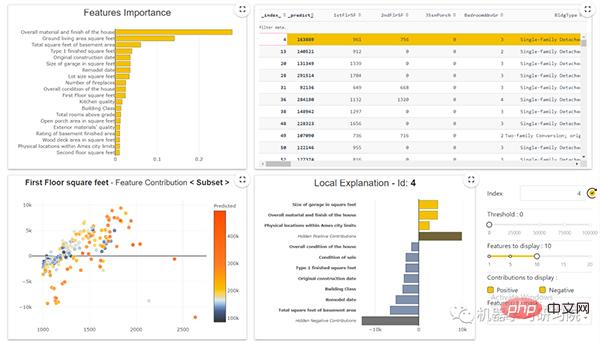
WebApp
Projektadresse: https://github.com/MAIF/shapash
Am Ende geschrieben
Dieser Artikel stellt kurz die Grundfunktionen und die Zeichenanzeige von Shapash vor Python-Bibliothek Ein gewisses Verständnis.
Das obige ist der detaillierte Inhalt vonEin weiteres Artefakt zur Modellinterpretation für maschinelles Lernen: Shapash. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr