
Heim >Technologie-Peripheriegeräte >KI >Transformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung
Transformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-08 21:41:041252Durchsuche
arXiv-Artikel „Unifying Voxel-based Representation with Transformer for 3D Object Detection“, 22. Juni, Chinesische Universität Hongkong, Universität Hongkong, Megvii Technology (in Erinnerung an Dr. Sun Jian) und Simou Technology usw.

In diesem Artikel wird ein einheitliches multimodales 3D-Objekterkennungs-Framework namens UVTR vorgeschlagen. Diese Methode zielt darauf ab, multimodale Darstellungen des Voxelraums zu vereinheitlichen und eine genaue und robuste einmodale oder kreuzmodale 3D-Erkennung zu ermöglichen. Zu diesem Zweck werden zunächst modalitätsspezifische Räume entworfen, um verschiedene Eingaben in den Voxel-Merkmalsraum darzustellen. Behalten Sie den Voxelraum ohne Höhenkomprimierung bei, verringern Sie semantische Mehrdeutigkeiten und ermöglichen Sie räumliche Interaktion. Basierend auf diesem einheitlichen Ansatz wird eine modalübergreifende Interaktion vorgeschlagen, um die inhärenten Eigenschaften verschiedener Sensoren, einschließlich Wissenstransfer und Modalfusion, vollständig zu nutzen. Auf diese Weise können geometriebewusste Ausdrücke von Punktwolken und kontextreiche Merkmale in Bildern gut genutzt werden, was zu einer besseren Leistung und Robustheit führt.
Der Transformer-Decoder wird verwendet, um Features aus einem einheitlichen Raum mit lernbaren Standorten effizient abzutasten, was Interaktionen auf Objektebene erleichtert. Im Allgemeinen stellt UVTR einen frühen Versuch dar, unterschiedliche Modalitäten in einem einheitlichen Rahmen darzustellen. Er übertrifft frühere Arbeiten zu einzelmodalen und multimodalen Eingaben und erreicht eine führende Leistung auf dem nuScenes-Testset, Lidar, Kamera und dem NDS der multimodalen Ausgabe betragen 69,7 %, 55,1 % bzw. 71,1 %.
Code: https://github.com/dvlab-research/UVTR.
Wie in der Abbildung gezeigt:
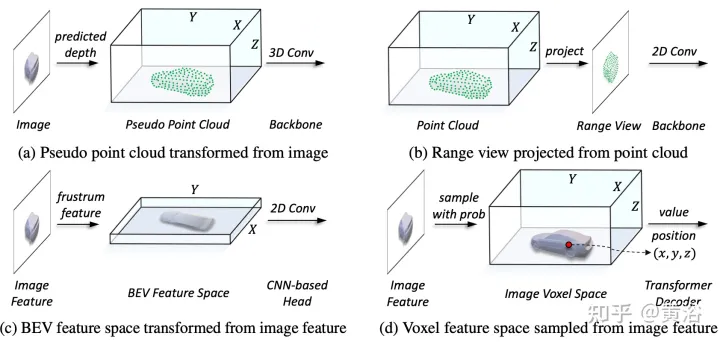
Im Darstellungsvereinheitlichungsprozess kann die Eingabe erfolgen grob unterteilt in Darstellung des Pegelflusses und charakteristischen Pegelfluss. Beim ersten Ansatz werden multimodale Daten am Anfang des Netzwerks ausgerichtet. Insbesondere wird die Pseudopunktwolke in (a) aus dem vorhergesagten tiefengestützten Bild konvertiert, während das Entfernungsansichtsbild in (b) aus der Punktwolke projiziert wird. Aufgrund von Tiefenungenauigkeiten in Pseudopunktwolken und geometrischem 3D-Zusammenbruch in Entfernungsansichtsbildern wird die räumliche Struktur der Daten zerstört, was zu schlechten Ergebnissen führt. Bei Methoden auf Merkmalsebene besteht die typische Methode darin, Bildmerkmale in Kegelstumpf umzuwandeln und sie dann in den BEV-Raum zu komprimieren, wie in Abbildung (c) dargestellt. Aufgrund seiner strahlenähnlichen Flugbahn aggregiert die Komprimierung der Höheninformationen (Höhe) an jeder Position jedoch die Merkmale verschiedener Ziele und führt so zu semantischer Mehrdeutigkeit. Gleichzeitig ist es aufgrund seines impliziten Ansatzes schwierig, explizite Merkmalsinteraktionen im 3D-Raum zu unterstützen, und schränkt den weiteren Wissenstransfer ein. Daher ist eine einheitlichere Darstellung erforderlich, um die modalen Lücken zu schließen und vielfältige Interaktionen zu erleichtern.
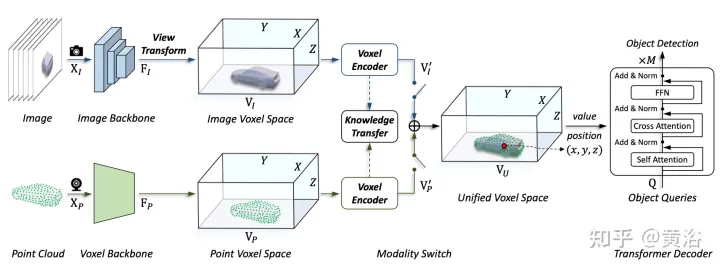
Das in diesem Artikel vorgeschlagene Framework vereinheitlicht die voxelbasierte Darstellung und den Transformator. Insbesondere Merkmalsdarstellung und Interaktion von Bildern und Punktwolken im voxelbasierten expliziten Raum. Für Bilder wird der Voxelraum durch Abtasten von Merkmalen aus der Bildebene entsprechend der vorhergesagten Tiefe und den geometrischen Einschränkungen konstruiert, wie in Abbildung (d) dargestellt. Bei Punktwolken ermöglichen genaue Standorte natürlich die Zuordnung von Merkmalen zu Voxeln. Anschließend wird ein Voxel-Encoder für die räumliche Interaktion eingeführt, um die Beziehung zwischen benachbarten Merkmalen herzustellen. Auf diese Weise verlaufen modalübergreifende Interaktionen mit Merkmalen in jedem Voxelraum auf natürliche Weise. Für Interaktionen auf Zielebene wird ein verformbarer Transformator als Decoder verwendet, um zielabfragespezifische Merkmale an jeder Position (x, y, z) im einheitlichen Voxelraum abzutasten, wie in Abbildung (d) dargestellt. Gleichzeitig wird durch die Einführung von 3D-Abfragepositionen die semantische Mehrdeutigkeit, die durch die Komprimierung von Höheninformationen (Höhe) im BEV-Raum verursacht wird, wirksam gemildert.
Wie in der Abbildung gezeigt, ist die UVTR-Architektur der multimodalen Eingabe: Bei einem Einzelbild- oder Mehrbildbild und einer Punktwolke wird es zunächst in einem einzigen Backbone verarbeitet und in modalitätsspezifische räumliche VI und VP umgewandelt. wobei die Ansichtstransformation zum Bild erfolgt. Bei Voxel-Encodern interagieren Features räumlich und der Wissenstransfer lässt sich während des Trainings leicht unterstützen. Wählen Sie je nach Einstellung über den Modalschalter monomodale oder multimodale Features aus. Schließlich werden Merkmale aus der einheitlichen räumlichen VU mit lernbaren Standorten abgetastet und mithilfe des Transformatordecoders vorhergesagt.
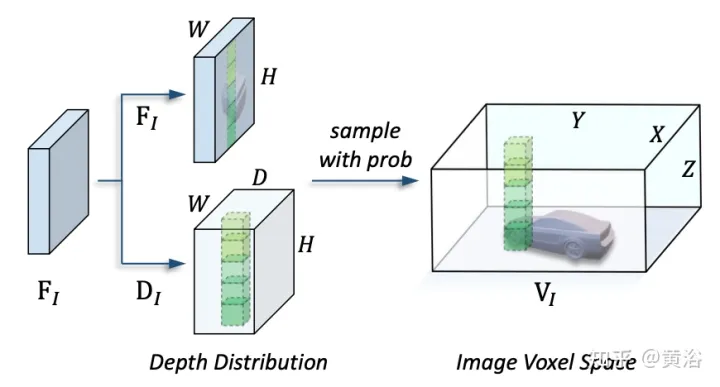
Das Bild zeigt die Details der Ansichtstransformation:
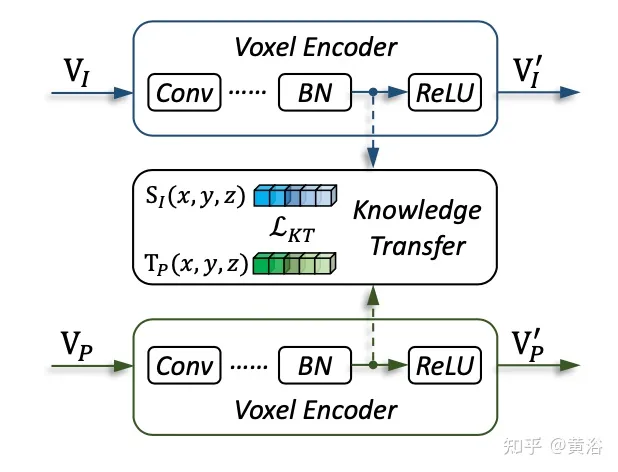
Das Bild zeigt die Details des Wissenstransfers:
Die experimentellen Ergebnisse sind wie folgt:
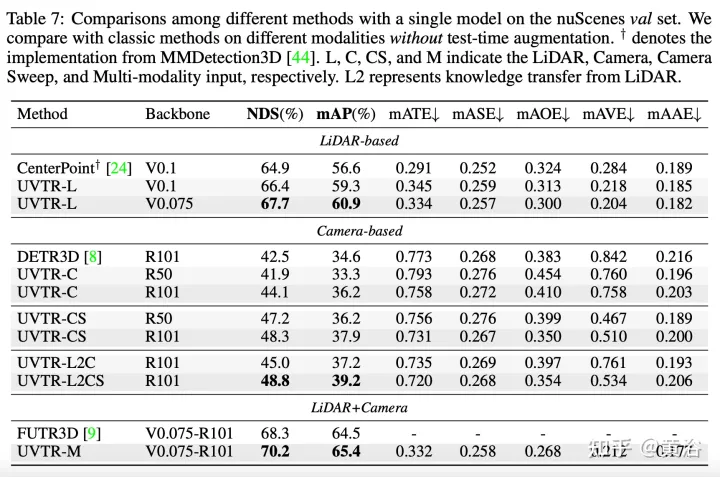
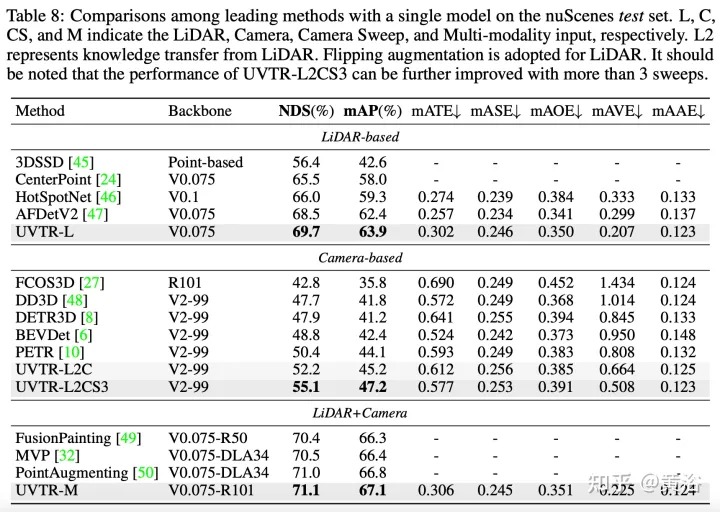
Das obige ist der detaillierte Inhalt vonTransformer vereinheitlicht voxelbasierte Darstellungen für die 3D-Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr