
Heim >Technologie-Peripheriegeräte >KI >Mithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren
Mithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren

- 王林nach vorne
- 2023-04-08 19:21:061169Durchsuche
Übersetzer |. Cui Hao
Rezensent |. Eröffnung
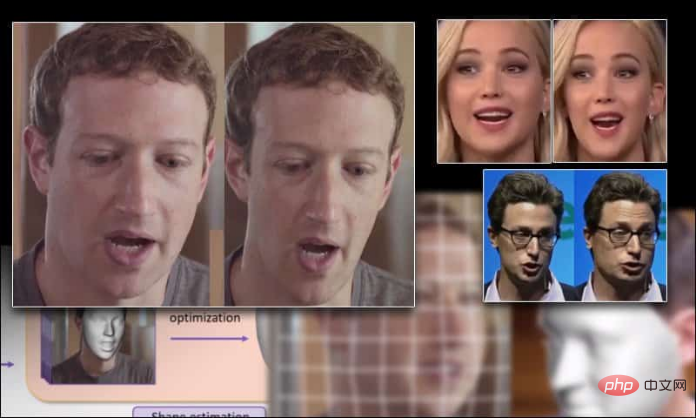 Eine gemeinsame Forschung aus China und Großbritannien hat eine neue Methode zur Umgestaltung von Gesichtern in Videos entwickelt. Diese Technologie kann die Gesichtsstruktur mit hoher Konsistenz und ohne Spuren künstlicher Beschneidung vergrößern und verkleinern.
Eine gemeinsame Forschung aus China und Großbritannien hat eine neue Methode zur Umgestaltung von Gesichtern in Videos entwickelt. Diese Technologie kann die Gesichtsstruktur mit hoher Konsistenz und ohne Spuren künstlicher Beschneidung vergrößern und verkleinern.
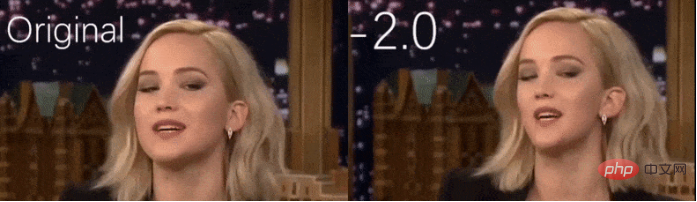 Typischerweise wird diese Transformation der Gesichtsstruktur durch traditionelle CGI-Methoden erreicht, die auf detaillierten und teuren Motion-Capping-, Rigging- und Texturierungsverfahren angewiesen sind, um das Gesicht vollständig zu rekonstruieren.
Typischerweise wird diese Transformation der Gesichtsstruktur durch traditionelle CGI-Methoden erreicht, die auf detaillierten und teuren Motion-Capping-, Rigging- und Texturierungsverfahren angewiesen sind, um das Gesicht vollständig zu rekonstruieren.
Anders als herkömmliche Methoden wird CGI in der neuen Technologie als Parameter für 3D-Gesichtsinformationen in die neuronale Pipeline integriert und dient als Grundlage für den maschinellen Lernworkflow.
 Der Autor weist darauf hin:
Der Autor weist darauf hin:
„Unser Ziel ist es, natürliche Gesichter in der realen Welt als Grundlage zu verwenden, um ihre Gesichtskonturen zu verformen und zu bearbeiten, um hochwertige Porträtrekonstruktionsvideos zu erzeugen.“ Wird für Anwendungen mit visuellen Effekten wie Gesichtsverschönerung und Gesichtsübertreibung verwendet.
Obwohl 2D-Gesichtsverzerrungstechniken seit dem Aufkommen von Photoshop für Verbraucher verfügbar sind (und eine Subkultur von Gesichtsverzerrungen und Körperdysmorphien für Videos ohne Verwendung hervorgebracht haben). CGI ist immer noch eine schwierige Technologie
 Mark Zuckerbergs Gesichtsgröße hat sich aufgrund neuer Technologien vergrößert und verkleinert
Mark Zuckerbergs Gesichtsgröße hat sich aufgrund neuer Technologien vergrößert und verkleinert
Derzeit ist die Körperumformung computergestützt ein heißes Thema im Sehbereich, vor allem wegen seines Potenzials in der Mode E-Commerce, wie zum Beispiel Menschen größer und mit vielfältigeren Knochen aussehen zu lassen, aber es gibt immer noch einige Herausforderungen
Auch hier war die Veränderung der Gesichtsform in Videos der Kern der Arbeit der Forscher Die Implementierung der Technologie wurde durch menschliche Verarbeitung und andere Einschränkungen behindert. Das neue Produkt migriert daher zuvor untersuchte Funktionen von statischen Erweiterungen auf dynamische Videoausgabe.
Das neue System wird auf einem Desktop-PC trainiert, der mit AMD Ryzen 9 3950X und 32 GB Speicher ausgestattet ist und verwendet den optischen Flussalgorithmus von OpenCV, um Bewegungskarten zu generieren und diese über das StructureFlow-Framework (FAN) zur Merkmalsschätzung zu glätten. Wird auch im beliebten Deepfakes-Komponentenpaket zur Lösung von Gesichtsoptimierungsproblemen verwendet
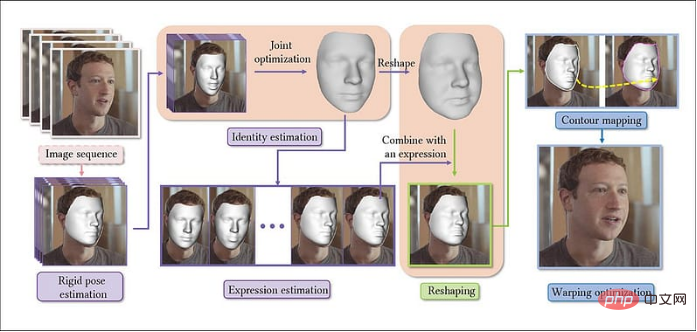
Beispiel für die Verwendung des neuen Systems zur Vergrößerung von Gesichtern Der Titel dieses Artikels lautet „Parametrische Umformung von Porträts in Videos“ und sein Autor ist „Über Gesichter“. Im neuen System werden Videos in Bildsequenzen extrahiert, wobei zunächst ein Basismodell für das Gesicht erstellt und dann repräsentative Folgebilder verkettet werden, wodurch konsistente Persönlichkeitsparameter entlang der gesamten Bildlaufrichtung (d. h. der Richtung des Videobilds) erstellt werden.
Der Titel dieses Artikels lautet „Parametrische Umformung von Porträts in Videos“ und sein Autor ist „Über Gesichter“. Im neuen System werden Videos in Bildsequenzen extrahiert, wobei zunächst ein Basismodell für das Gesicht erstellt und dann repräsentative Folgebilder verkettet werden, wodurch konsistente Persönlichkeitsparameter entlang der gesamten Bildlaufrichtung (d. h. der Richtung des Videobilds) erstellt werden.
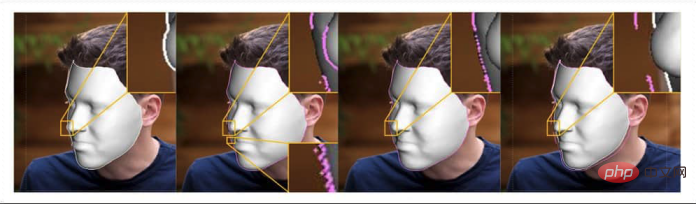
Der Arbeitsablauf des neuen Systems berücksichtigt Verdeckungssituationen, etwa wenn sich ein Objekt aus der Sicht entfernt. Dies ist auch eine der größten Herausforderungen für Deepfake-Software, da FAN-Markierungen diese Situationen kaum berücksichtigen können und ihre Übersetzungsqualität dazu neigt, sich zu verschlechtern, wenn Gesichter vermieden oder verdeckt werden.
Das neue System vermeidet die oben genannten Probleme, indem es „Konturenergie“ definiert, die den Grenzen von 3D-Gesichtern (3DMM) und 2D-Gesichtern (definiert durch FAN-Landmarken) entspricht.
Optimierung
Das Anwendungsszenario dieses Systems ist die Echtzeitverformung, beispielsweise die Gesichtsformtransformation in Echtzeit durch Filter im Video-Chat. Derzeit können Frameworks dies nicht erreichen, sodass die Bereitstellung der notwendigen Rechenressourcen, um eine „Echtzeit“-Verformung zu ermöglichen, eine erhebliche Herausforderung darstellt.
Nach der Hypothese des Papiers beträgt die Latenz jedes Bildvorgangs von 24-fps-Videos in der Pipeline im Verhältnis zum Material pro Sekunde 16,344 Sekunden. Gleichzeitig ist dies bei der Merkmalsschätzung und 3D-Gesichtsverformung der Fall ein Treffer (321 Millisekunden bzw. 160 Millisekunden) Millisekunde).
Dadurch hat die Optimierung wichtige Fortschritte bei der Reduzierung der Latenz gemacht. Da eine gemeinsame Optimierung über alle Frames den Systemaufwand erheblich erhöhen würde und die Optimierung des Initialisierungsstils (unter der Annahme durchgehend konsistenter Sprechereigenschaften) zu Anomalien führen könnte, haben die Autoren einen Sparse-Modus übernommen, um Koeffizienten in realistischen Intervallen abgetasteter Frames zu berechnen.
Dann wird eine gemeinsame Optimierung dieser Teilmenge von Frames durchgeführt, was zu einem schlankeren Rekonstruktionsprozess führt.
Facial Surfaces
Die in diesem Projekt verwendete Morphing-Technologie ist eine Adaption des Werks Deep Shapely Portraits (DSP) des Autors aus dem Jahr 2020.
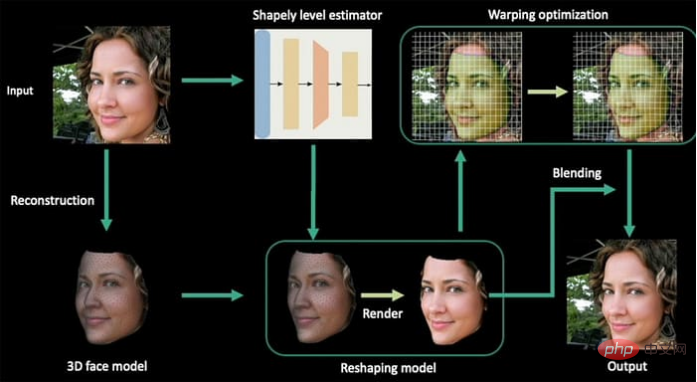
Deep Shapely Portraits, 2020 Einreichung bei ACM Multimedia. Das Papier wurde von Forschern des Joint Laboratory der Zhejiang University-Tencent Game and Intelligent Graphics Innovation Technology geleitet. Die Autoren stellten fest, dass „wir diese Methode von der Umformung eines einzelnen Bildes auf die Umformung einer gesamten Bildsequenz ausgeweitet haben.“ Das Papier stellt fest, dass es keine vergleichbaren historischen Daten zur Bewertung des neuen Ansatzes gibt. Daher verglichen die Autoren ihre gekrümmten Videoausgaberahmen mit der statischen DSP-Ausgabe.
Testen des neuen Systems anhand statischer Bilder von Deep Shapely Portraits Die Autoren weisen darauf hin, dass die DSP-Methode aufgrund der Verwendung von Sparse Mapping Spuren künstlicher Modifikation aufweist – das neue Framework löst dieses Problem durch Dense Mapping. Darüber hinaus argumentiert das Papier, dass es den von DSP produzierten Videos an Glätte und visueller Kohärenz mangele. Der Autor weist darauf hin:
Der Autor weist darauf hin:
„Die Ergebnisse zeigen, dass unsere Methode stabil und kohärent umgeformte Porträtvideos erzeugen kann, während bildbasierte Methoden leicht zu offensichtlichen Flackerartefakten (künstliche Änderungsspuren) führen können.“
Übersetzte Einführung des Autors
Cui Hao, 51CTO-Community-Redakteur, leitender Architekt, verfügt über 18 Jahre Erfahrung in Softwareentwicklung und -architektur sowie 10 Jahre Erfahrung in verteilter Architektur. Ehemals technischer Experte bei HP. Er ist bereit zu teilen und hat viele beliebte Fachartikel geschrieben, die mehr als 600.000 Mal gelesen wurden. Autor von „Distributed Architecture Principles and Practice“.
Originaltitel:
Restructuring Faces in Videos With Machine Learning
Das obige ist der detaillierte Inhalt vonMithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr