
Heim >Technologie-Peripheriegeräte >KI >Eine Anleitung zur Implementierung des Random-Forest-Algorithmus beim maschinellen Lernen
Eine Anleitung zur Implementierung des Random-Forest-Algorithmus beim maschinellen Lernen

- 王林nach vorne
- 2023-04-08 18:01:08861Durchsuche
Da Modelle des maschinellen Lernens für die Vorhersage und Analyse von Daten immer beliebter werden, gewinnt der Einsatz von Random-Forest-Algorithmen zunehmend an Bedeutung. Random Forest ist ein überwachter Lernalgorithmus, der für Regressions- und Klassifizierungsaufgaben im Bereich des maschinellen Lernens verwendet wird. Es funktioniert, indem es zur Trainingszeit eine große Anzahl von Entscheidungsbäumen erstellt und Klassen ausgibt, entweder den Modus der Klasse (Klassifizierung) oder die durchschnittliche Vorhersage eines einzelnen Baums (Regression).
In diesem Artikel besprechen wir, wie der Random Forest-Algorithmus mithilfe realer Online-Datensätze implementiert wird. Wir bieten außerdem detaillierte Codeerklärungen und Beschreibungen der einzelnen Schritte sowie eine Bewertung der Modellleistung und -visualisierung.
Der Datensatz, den wir verwenden werden, ist der „Breast Cancer Wisconsin (Diagnostic) Dataset“, der öffentlich verfügbar ist und über das UCI Machine Learning Repository abgerufen werden kann. Der Datensatz umfasst 569 Fälle mit 30 Attributen und zwei Kategorien – bösartig und gutartig. Unser Ziel ist es, diese Fälle anhand von 30 Merkmalen zu klassifizieren und festzustellen, ob sie gutartig oder bösartig sind. Sie können den Datensatz unter https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data herunterladen.
Zuerst importieren wir die notwendigen Bibliotheken:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Als nächstes laden wir den Datensatz:
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
Ausgabe:
Bevor wir das Modell erstellen, müssen wir die Daten vorverarbeiten. Da die Spalten „id“ und „Unbenannt: 32“ für unser Modell keinen Nutzen haben, werden wir sie löschen:
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
Ausgabe:
Als nächstes werden wir „ „Diagnose“-Spalte, die unserer Zielvariablen zugewiesen und aus unseren Funktionen entfernt wurde:
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)
Wir werden unseren Datensatz nun in Trainings- und Testsätze aufteilen. Wir werden 70 % der Daten für das Training und 30 % für Tests verwenden:
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
Nachdem unsere Daten vorverarbeitet und in Trainings- und Testsätze aufgeteilt wurden, können wir jetzt unser Random-Forest-Modell erstellen:
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
Hier setzen wir die Anzahl der Entscheidungsbäume im Wald auf 100 und legen den Zufallszustand fest, um die Wiederholbarkeit der Ergebnisse sicherzustellen.
Jetzt können wir die Leistung des Modells bewerten. Wir verwenden den Genauigkeitswert, die Verwirrungsmatrix und den Klassifizierungsbericht zur Bewertung:
y_pred = rf.predict(X_test)
# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:n", class_report)
Ausgabe:
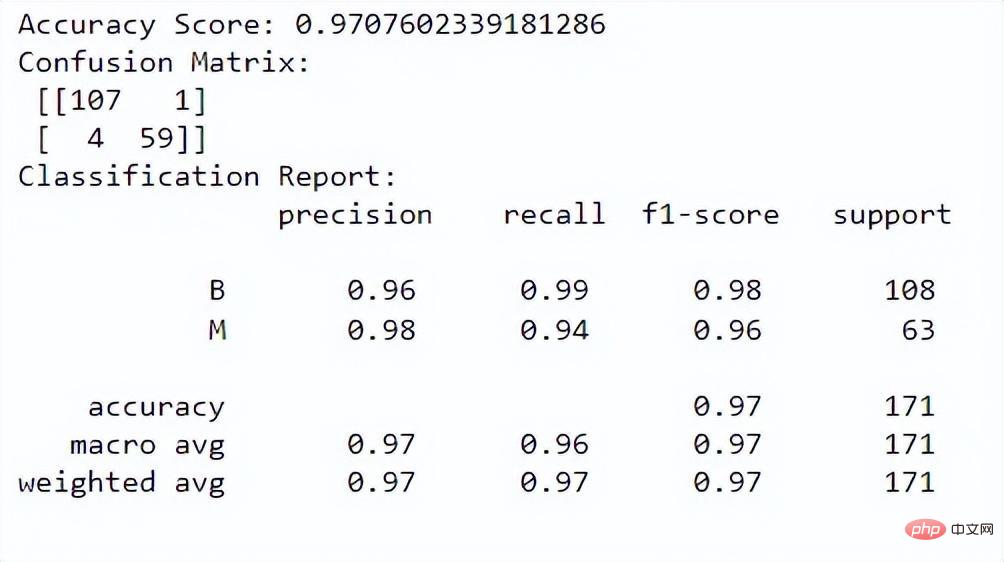
Der Genauigkeitswert sagt uns, wie gut das Modell bei der korrekten Klassifizierung von Instanzen funktioniert. Die Verwirrungsmatrix gibt uns ein besseres Verständnis der Klassifizierungsleistung unseres Modells. Der Klassifizierungsbericht liefert uns Präzisions-, Rückruf-, F1-Score- und Unterstützungswerte für beide Klassen.
Endlich können wir die Bedeutung jedes Merkmals im Modell visualisieren. Wir können dies tun, indem wir ein Balkendiagramm erstellen, das die Wichtigkeitswerte der Merkmale anzeigt:
importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
plt.show()
Ausgabe:
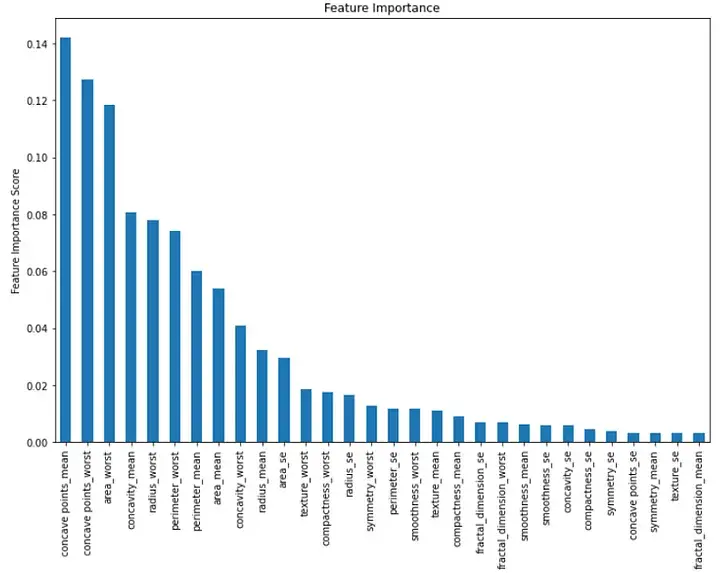
Dieses Balkendiagramm zeigt die Wichtigkeit jedes Merkmals in absteigender Reihenfolge des Geschlechts. Wir können sehen, dass die ersten drei wichtigen Merkmale „mittlere Konkavität“, „schlechteste Konkavität“ und „schlechteste Region“ sind.
Zusammenfassend ist die Implementierung des Random-Forest-Algorithmus beim maschinellen Lernen ein leistungsstarkes Werkzeug für Klassifizierungsaufgaben. Damit können wir Instanzen anhand mehrerer Merkmale klassifizieren und die Leistung unseres Modells bewerten. In diesem Artikel verwenden wir einen Online-Datensatz aus der realen Welt und stellen detaillierte Codeerklärungen und Beschreibungen jedes Schritts sowie eine Bewertung der Modellleistung und -visualisierung bereit.
Das obige ist der detaillierte Inhalt vonEine Anleitung zur Implementierung des Random-Forest-Algorithmus beim maschinellen Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr