
Heim >Technologie-Peripheriegeräte >KI >Warum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen
Warum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen

- 王林nach vorne
- 2023-04-08 16:11:031341Durchsuche
In diesem Artikel werde ich das Papier „Warum baumbasierte Modelle immer noch Deep Learning auf Tabellendaten übertreffen“ ausführlich erläutern. Dieses Papier erklärt ein Phänomen, das von Praktikern des maschinellen Lernens auf der ganzen Welt in verschiedenen Bereichen beobachtet wurde – das Phänomen Baum -basierte Modelle sind bei der Analyse tabellarischer Daten viel besser als Deep Learning/neuronale Netze.
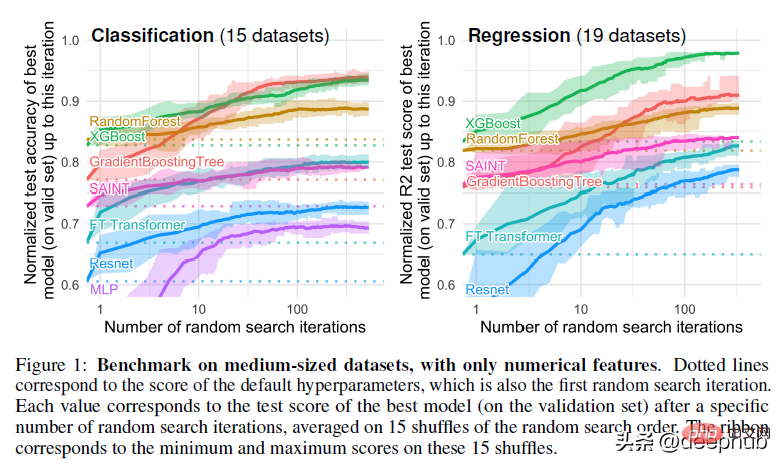
Hinweise zum Papier
Dieses Papier wurde einer umfangreichen Vorverarbeitung unterzogen. Dinge wie das Entfernen fehlender Daten können beispielsweise die Baumleistung beeinträchtigen, aber zufällige Gesamtstrukturen eignen sich hervorragend für Situationen mit fehlenden Daten, wenn Ihre Daten sehr chaotisch sind und viele Features und Dimensionen enthalten. Die Robustheit und Vorteile von RF machen es „fortschrittlicheren“ Lösungen überlegen, die anfällig für Probleme sind.

Der Großteil der restlichen Arbeit ist ziemlich normal. Ich persönlich mag es nicht, zu viele Vorverarbeitungstechniken anzuwenden, da dies dazu führen kann, dass viele Nuancen des Datensatzes verloren gehen, aber die in der Arbeit durchgeführten Schritte erzeugen im Grunde denselben Datensatz. Es ist jedoch wichtig zu beachten, dass bei der Auswertung der Endergebnisse die gleiche Verarbeitungsmethode verwendet wird.
Der Artikel verwendet auch eine Zufallssuche zur Optimierung von Hyperparametern. Dies ist ebenfalls ein Industriestandard, aber meiner Erfahrung nach eignet sich die Bayes'sche Suche besser für die Suche in einem größeren Suchraum.
Wenn wir diese verstehen, können wir uns mit unserer Hauptfrage befassen: Warum sind baumbasierte Methoden besser als Deep Learning? Die erste Ursache für Waldkonkurrenz. Kurz gesagt, neuronale Netze haben es schwer, die am besten passende Funktion zu erstellen, wenn es um nicht glatte Funktionen/Entscheidungsgrenzen geht. Zufällige Wälder eignen sich besser für seltsame/zackige/unregelmäßige Muster.
Wenn ich den Grund erraten würde, könnte es sein, dass Gradienten in neuronalen Netzen verwendet werden und Gradienten auf differenzierbaren Suchräumen basieren, die per Definition glatt sind, sodass scharfe Punkte und einige Zufallsfunktionen nicht unterschieden werden können. Ich empfehle daher, KI-Konzepte wie evolutionäre Algorithmen, traditionelle Suche und grundlegendere Konzepte zu erlernen, da diese Konzepte in verschiedenen Situationen, in denen NN versagt, zu großartigen Ergebnissen führen können. Ein konkreteres Beispiel für den Unterschied in den Entscheidungsgrenzen zwischen baumbasierten Methoden (RandomForests) und Deep-Learning-Methoden finden Sie in der Abbildung unten –
Ein konkreteres Beispiel für den Unterschied in den Entscheidungsgrenzen zwischen baumbasierten Methoden (RandomForests) und Deep-Learning-Methoden finden Sie in der Abbildung unten –
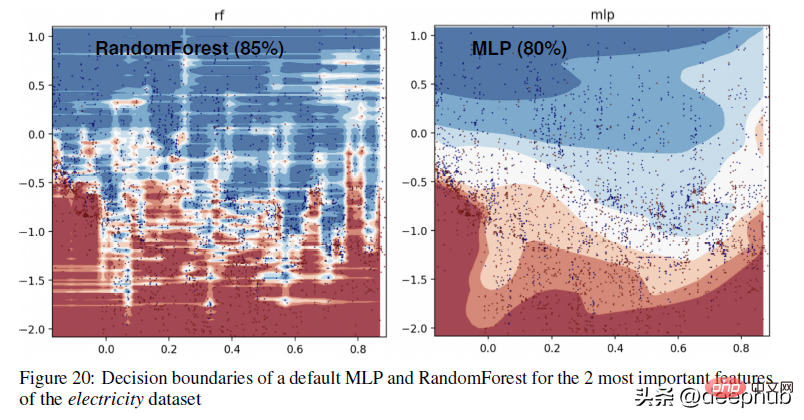 In diesem Teil können wir sehen, dass RandomForest unregelmäßige Muster auf der x-Achse (entsprechend Datumsmerkmalen) lernen kann, die MLP nicht lernen kann. Wir zeigen diesen Unterschied bei Standard-Hyperparametern, was ein typisches Verhalten neuronaler Netze ist, aber in der Praxis ist es schwierig (wenn auch nicht unmöglich), Hyperparameter zu finden, die diese Muster erfolgreich lernen.
In diesem Teil können wir sehen, dass RandomForest unregelmäßige Muster auf der x-Achse (entsprechend Datumsmerkmalen) lernen kann, die MLP nicht lernen kann. Wir zeigen diesen Unterschied bei Standard-Hyperparametern, was ein typisches Verhalten neuronaler Netze ist, aber in der Praxis ist es schwierig (wenn auch nicht unmöglich), Hyperparameter zu finden, die diese Muster erfolgreich lernen.
2. Nicht informative Eigenschaften wirken sich auf MLP-ähnliche neuronale Netze aus.
Ein weiterer wichtiger Faktor, insbesondere bei großen Datensätzen, die mehrere Beziehungen gleichzeitig kodieren. Wenn Sie einem neuronalen Netzwerk irrelevante Funktionen zuführen, sind die Ergebnisse schlecht (und Sie verschwenden mehr Ressourcen für das Training Ihres Modells). Aus diesem Grund ist es so wichtig, viel Zeit in die EDA-/Domain-Erkundung zu investieren. Dies hilft, die Funktionen zu verstehen und sicherzustellen, dass alles reibungslos funktioniert.
Die Autoren des Artikels testeten die Leistung des Modells beim Hinzufügen zufälliger und Entfernen nutzloser Funktionen. Basierend auf ihren Ergebnissen wurden zwei sehr interessante Ergebnisse gefunden:
Durch das Entfernen einer großen Anzahl von Funktionen wird der Leistungsunterschied zwischen den Modellen verringert. Dies zeigt deutlich, dass einer der Vorteile von Baummodellen darin besteht, dass sie beurteilen können, ob Merkmale nützlich sind, und den Einfluss nutzloser Merkmale vermeiden können.
Das Hinzufügen zufälliger Merkmale zum Datensatz zeigt, dass sich neuronale Netze viel stärker verschlechtern als baumbasierte Methoden. Insbesondere ResNet leidet unter diesen nutzlosen Eigenschaften. Die Verbesserung des Transformators kann darauf zurückzuführen sein, dass der darin enthaltene Aufmerksamkeitsmechanismus bis zu einem gewissen Grad hilfreich ist.
Eine mögliche Erklärung für dieses Phänomen ist die Art und Weise, wie Entscheidungsbäume entworfen werden. Jeder, der einen KI-Kurs belegt hat, kennt die Konzepte des Informationsgewinns und der Entropie in Entscheidungsbäumen. Dadurch kann der Entscheidungsbaum den besten Pfad auswählen, indem er die verbleibenden Merkmale vergleicht.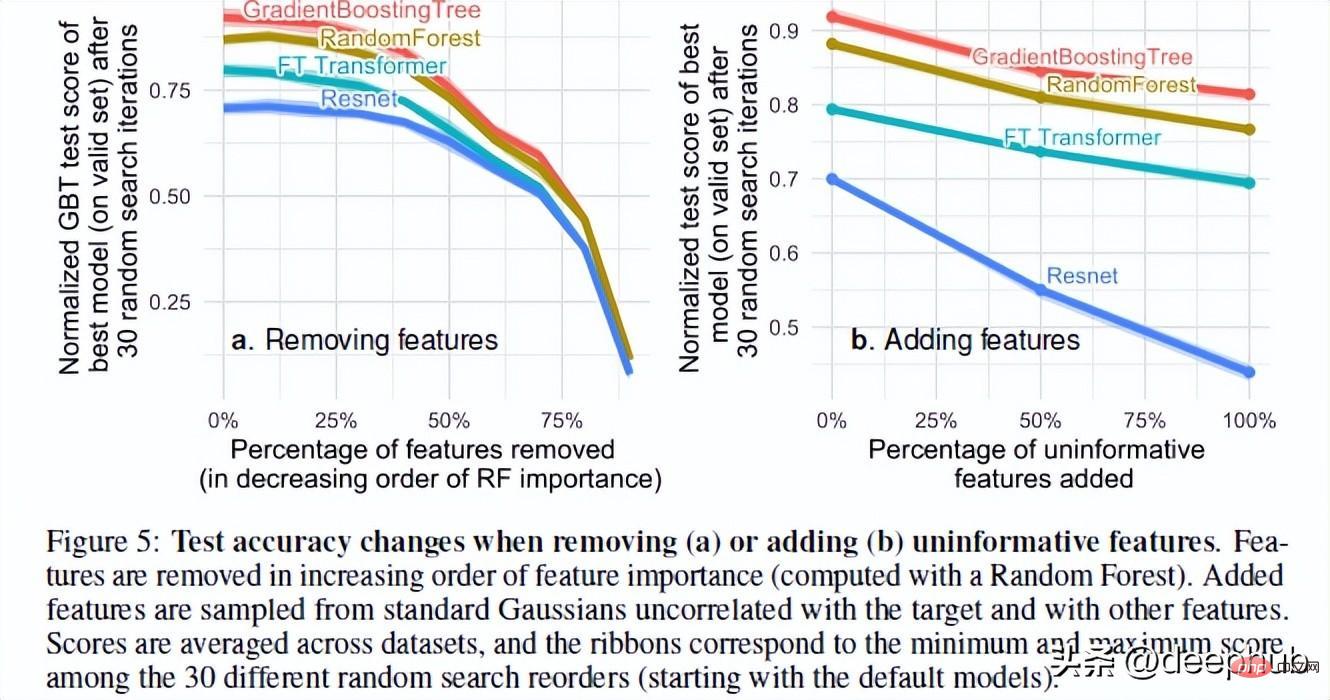 Zurück zum Thema: Es gibt noch eine letzte Sache, die RF bei tabellarischen Daten zu einer besseren Leistung als NN macht. Das ist Rotationsinvarianz.
Zurück zum Thema: Es gibt noch eine letzte Sache, die RF bei tabellarischen Daten zu einer besseren Leistung als NN macht. Das ist Rotationsinvarianz.
3. NNs sind rotationsinvariant, die tatsächlichen Daten jedoch nicht.
Neuronale Netze sind rotationsinvariant. Das bedeutet, dass sich die Leistung Ihrer Datensätze nicht ändert, wenn Sie eine Rotationsoperation durchführen. Nach der Rotation des Datensatzes änderten sich die Leistung und das Ranking der verschiedenen Modelle erheblich. Obwohl ResNets immer das schlechteste war, behielt es nach der Rotation seine ursprüngliche Leistung bei, während sich alle anderen Modelle stark veränderten.
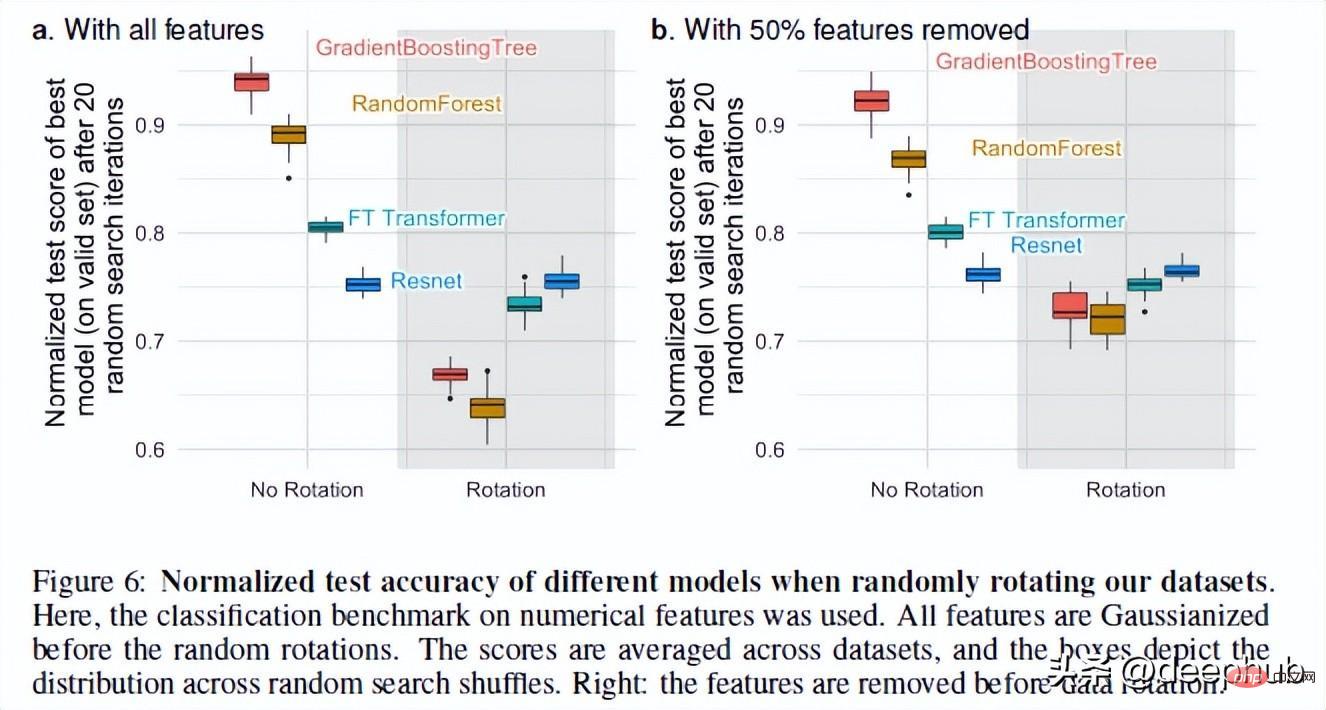
Das ist ein sehr interessantes Phänomen: Was genau bedeutet das Rotieren eines Datensatzes? Im gesamten Artikel gibt es keine detaillierten Erklärungen (ich habe den Autor kontaktiert und werde diesem Phänomen nachgehen). Wenn Sie irgendwelche Gedanken haben, teilen Sie diese bitte auch in den Kommentaren mit.
Aber diese Operation zeigt uns, warum Rotationsvarianz wichtig ist. Laut den Autoren kann die Verwendung linearer Kombinationen von Merkmalen (was ResNets invariant macht) tatsächlich dazu führen, dass Merkmale und ihre Beziehungen falsch dargestellt werden.
Das Erhalten optimaler Datenverzerrungen durch Kodierung der Originaldaten, die möglicherweise Merkmale mit sehr unterschiedlichen statistischen Eigenschaften vermischen und durch ein rotationsinvariantes Modell nicht wiederhergestellt werden können, führt zu einer besseren Leistung des Modells.
Zusammenfassung
Dies ist ein sehr interessantes Papier. Obwohl Deep Learning große Fortschritte bei Text- und Bilddatensätzen gemacht hat, hat es bei tabellarischen Daten grundsätzlich keine Vorteile. Das Papier verwendet 45 Datensätze aus verschiedenen Domänen zum Testen, und die Ergebnisse zeigen, dass baumbasierte Modelle auch ohne Berücksichtigung ihrer überlegenen Geschwindigkeit bei moderaten Daten (~10.000 Stichproben) immer noch auf dem neuesten Stand sind.
Das obige ist der detaillierte Inhalt vonWarum baumbasierte Modelle Deep Learning für Tabellendaten immer noch übertreffen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr