
Heim >Technologie-Peripheriegeräte >KI >Princeton Chen Danqi: Wie man „große Modelle' kleiner macht
Princeton Chen Danqi: Wie man „große Modelle' kleiner macht

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-08 16:01:031431Durchsuche
„Große Modelle kleiner machen“Dies ist das akademische Ziel vieler Sprachmodellforscher. Angesichts der teuren Umgebung und der Schulungskosten großer Modelle hielt Chen Danqi beim Qingyuan Academic Annual eine Rede mit dem Titel „Making“. Konferenz der Intelligent Source Conference „Große Modelle kleiner“ Gastvortrag. Der Bericht konzentrierte sich auf den TRIME-Algorithmus, der auf Speicherverbesserung basiert, und den CofiPruning-Algorithmus, der auf grob- und feinkörnigem gemeinsamem Beschneiden und schichtweiser Destillation basiert. Ersteres kann die Vorteile der Sprachmodell-Perplexität und der Abrufgeschwindigkeit berücksichtigen, ohne die Modellstruktur zu ändern, während letzteres eine schnellere Verarbeitungsgeschwindigkeit und eine kleinere Modellstruktur erreichen und gleichzeitig die Genauigkeit nachgelagerter Aufgaben gewährleisten kann.

Chen Danqi Assistenzprofessor für Informatik an der Princeton University
Chen Danqi schloss 2012 die Yao-Klasse der Tsinghua University ab und erhielt 2018 einen Doktortitel in Informatik von der Stanford University. Er studierte Linguistik und Informatik am Stanford University Science Professor Christopher Manning.
1 Hintergrundeinführung
In den letzten Jahren wird der Bereich der Verarbeitung natürlicher Sprache schnell von großen Sprachmodellen dominiert. Seit der Einführung von GPT 3 ist die Größe der Sprachmodelle exponentiell gewachsen. Große Technologieunternehmen veröffentlichen weiterhin immer größere Sprachmodelle. Vor kurzem hat Meta AI das OPT-Sprachmodell (ein großes Sprachmodell mit 175 Milliarden Parametern) veröffentlicht und den Quellcode und die Modellparameter der Öffentlichkeit zugänglich gemacht.

Der Grund, warum Forscher große Sprachmodelle so sehr bewundern, liegt in ihren hervorragenden Lernfähigkeiten und Leistungen, aber die Menschen wissen immer noch sehr wenig über den Black-Box-Charakter großer Sprachmodelle. Durch die Eingabe einer Frage in das Sprachmodell und die schrittweise Argumentation durch das Sprachmodell können sehr komplexe Argumentationsprobleme gelöst werden, beispielsweise das Ableiten von Antworten auf Rechenprobleme. Gleichzeitig bergen groß angelegte Sprachmodelle jedoch Risiken, insbesondere ihre ökologischen und wirtschaftlichen Kosten. Beispielsweise sind der Energieverbrauch und die CO2-Emissionen groß angelegter Sprachmodelle wie GPT-3 atemberaubend.  Angesichts der Probleme des teuren Trainings großer Sprachmodelle und einer großen Anzahl von Parametern hofft das Team von Chen Dan, durch akademische Forschung den Rechenaufwand für vorab trainierte Modelle zu reduzieren und Sprachmodelle für Anwendungen auf niedrigeren Ebenen effizienter zu machen. Zu diesem Zweck werden zwei Arbeiten des Teams hervorgehoben: Eine davon ist eine neue Trainingsmethode für Sprachmodelle namens TRIME und die andere ist eine effektive Modellbereinigungsmethode namens CofiPruning.
Angesichts der Probleme des teuren Trainings großer Sprachmodelle und einer großen Anzahl von Parametern hofft das Team von Chen Dan, durch akademische Forschung den Rechenaufwand für vorab trainierte Modelle zu reduzieren und Sprachmodelle für Anwendungen auf niedrigeren Ebenen effizienter zu machen. Zu diesem Zweck werden zwei Arbeiten des Teams hervorgehoben: Eine davon ist eine neue Trainingsmethode für Sprachmodelle namens TRIME und die andere ist eine effektive Modellbereinigungsmethode namens CofiPruning.
2 Dokument, geben Sie es in den Transformer-Encoder ein, um die versteckten Vektoren zu erhalten, und transportieren Sie diese versteckten Vektoren dann zur Softmax-Ebene. Die Ausgabe dieser Ebene ist eine Matrix, die aus V-Worteinbettungsvektoren besteht, wobei V die Größe von darstellt Das Vokabular kann schließlich verwendet werden. Der Ausgabevektor sagt den Originaltext voraus und vergleicht ihn mit der Standardantwort des gegebenen Dokuments, um den Gradienten zu berechnen und die Backpropagation des Gradienten zu implementieren. Ein solches Trainingsparadigma bringt jedoch die folgenden Probleme mit sich: (1) Ein riesiger Transformer-Encoder bringt hohe Trainingskosten mit sich. (2) Die Eingabelänge des Sprachmodells ist fest und der Berechnungsaufwand des Transformers erhöht sich deutlich Aufgrund der Änderung der Sequenzlänge ist es für Transformer schwierig, mit langen Texten umzugehen. (3) Das heutige Trainingsparadigma besteht darin, den Text in einen Vektorraum mit fester Länge zu projizieren ein Engpass des Sprachmodells.

Zu diesem Zweck schlug das Team von Chen Danqi ein neues Trainingsparadigma vor – TRIME, das hauptsächlich Batch-Speicher für das Training verwendet, und schlug darauf basierend drei Sprachmodelle vor, die dieselbe Trainingszielfunktion haben, nämlich TrimeLM, TrimeLMlong und TrimeLMext. TrimeLM kann als Alternative zu Standard-Sprachmodellen angesehen werden; TrimeLMlong ist für Text mit großer Reichweite konzipiert, ähnlich wie Transformer-XL, kombiniert einen großen Datenspeicher, ähnlich wie kNN-LM. Unter dem oben erwähnten Trainingsparadigma definiert TRIME zunächst den Eingabetext als  , und überträgt dann die Eingabe an den Transformer-Encoder
, und überträgt dann die Eingabe an den Transformer-Encoder  , um den versteckten Vektor
, um den versteckten Vektor  zu erhalten, und nach dem Passieren der Softmax-Ebene
zu erhalten, und nach dem Passieren der Softmax-Ebene  Die erforderliche Vorhersage wird erhalten. Das nächste Wort
Die erforderliche Vorhersage wird erhalten. Das nächste Wort  , die trainierbaren Parameter im gesamten Trainingsparadigma sind
, die trainierbaren Parameter im gesamten Trainingsparadigma sind  und E. Die Arbeit von Chen Danqis Team wurde von den folgenden zwei Arbeiten inspiriert: (1) Der von Grave et al. im Jahr 2017 vorgeschlagene Continuous-Cache-Algorithmus. Dieser Algorithmus trainiert während des Trainingsprozesses ein gemeinsames Sprachmodell
und E. Die Arbeit von Chen Danqis Team wurde von den folgenden zwei Arbeiten inspiriert: (1) Der von Grave et al. im Jahr 2017 vorgeschlagene Continuous-Cache-Algorithmus. Dieser Algorithmus trainiert während des Trainingsprozesses ein gemeinsames Sprachmodell  . Während des Inferenzprozesses zählt er anhand des Eingabetexts
. Während des Inferenzprozesses zählt er anhand des Eingabetexts  zunächst alle Wörter auf, die zuvor im angegebenen Text aufgetreten sind, und alle, die dem entsprechen Das nächste Wort, das vorhergesagt werden muss, markiert die Position und verwendet dann die Ähnlichkeit zwischen latenten Variablen und Temperaturparametern, um die Cache-Verteilung zu berechnen. In der Testphase können durch lineare Interpolation der Sprachmodellverteilung und der Cache-Verteilung bessere experimentelle Ergebnisse erzielt werden.
zunächst alle Wörter auf, die zuvor im angegebenen Text aufgetreten sind, und alle, die dem entsprechen Das nächste Wort, das vorhergesagt werden muss, markiert die Position und verwendet dann die Ähnlichkeit zwischen latenten Variablen und Temperaturparametern, um die Cache-Verteilung zu berechnen. In der Testphase können durch lineare Interpolation der Sprachmodellverteilung und der Cache-Verteilung bessere experimentelle Ergebnisse erzielt werden.

(2) Das von Khandelwal et al. vorgeschlagene k-Nearest-Neighbor-Language-Modell (kNN-LM). Diese Methode ähnelt dem kontinuierlichen Caching-Algorithmus dass kNN-LM ein Datenspeicherbereich ist, der auf den Trainingsbeispielen basiert. In der Testphase wird eine Suche nach k nächsten Nachbarn für die Daten im Datenspeicherbereich durchgeführt, um die besten Top-k-Daten auszuwählen. 
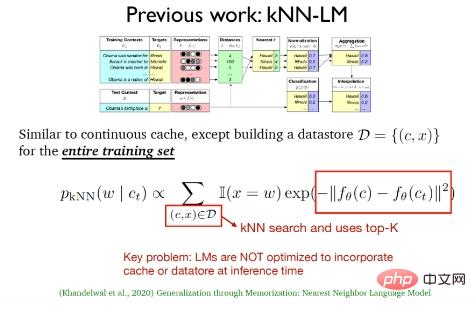
Die beiden oben genannten Arbeiten verwendeten in der Testphase tatsächlich nur die Cache-Verteilung und die K-Nearest-Neighbor-Verteilung. In der Inferenzphase wurde lediglich das traditionelle Sprachmodell fortgesetzt Optimieren Sie den Cache und die Daten nicht.
Darüber hinaus gibt es einige Sprachmodellwerke für sehr lange Texte, die Aufmerksamkeit verdienen, wie zum Beispiel den 2019 vorgeschlagenen Transformer-XL, der den Aufmerksamkeitswiederholungsmechanismus und das 2020 vorgeschlagene speicherbasierte Modell Compressive Transformers der Speicherkomprimierung kombiniert , usw.
Basierend auf mehreren zuvor vorgestellten Arbeiten entwickelte das Team von Chen Danqi eine auf Batch-Speicher basierende Sprachmodell-Trainingsmethode. Die Hauptidee besteht darin, ein Arbeitsgedächtnis für denselben Trainingsbatch aufzubauen. Für die Aufgabe, das nächste Wort aus einem bestimmten Text vorherzusagen, ist die Idee von TRIME dem kontrastiven Lernen sehr ähnlich. Es berücksichtigt nicht nur die Aufgabe, die Wahrscheinlichkeit des nächsten Wortes mithilfe der Softmax-Worteinbettungsmatrix vorherzusagen, sondern auch Fügt ein neues Modul hinzu, in dem alle anderen Texte berücksichtigt werden, die im Trainingsgedächtnis erscheinen und das gleiche Wort wie der angegebene Text enthalten, der vorhergesagt werden muss.

Daher umfasst die Trainingszielfunktion des gesamten TRIME zwei Teile:
(1) Vorhersageaufgabe basierend auf der Ausgabewort-Einbettungsmatrix.
(2) Teilen Sie die Ähnlichkeit des vorherzusagenden Worttextes im Trainingsspeicher (Trainingsspeicher), wobei die zu messende Vektordarstellung die Eingabe durch die letzte Feedforward-Schicht und das skalierte Skalarprodukt ist wird verwendet, um die Vektorähnlichkeit zu messen.
Der Algorithmus hofft, dass das endgültig trainierte Netzwerk das endgültig vorhergesagte Wort so genau wie möglich erreichen kann und gleichzeitig die Texte, die dasselbe vorherzusagende Wort im selben Trainingsstapel teilen, so ähnlich wie möglich sind dass alle Textspeicherdarstellungen während des Trainingsprozesses übergeben werden. Backpropagation ermöglicht ein durchgängiges Lernen neuronaler Netze. Die Implementierungsidee des Algorithmus ist weitgehend von dem im Jahr 2020 vorgeschlagenen dichten Abruf inspiriert. Der dichte Abruf richtet Abfragen und positiv verwandte Dokumente in der Trainingsphase aus, verwendet Dokumente im selben Stapel wie negative Proben und extrahiert Daten aus großen Datenmengen in der Inferenzphase. Relevante Dokumente aus dem Speicherbereich abrufen.

Die Inferenzphase von TRIME ist fast die gleiche wie der Trainingsprozess. Der einzige Unterschied besteht darin, dass verschiedene Testspeicher verwendet werden können, einschließlich lokaler Speicher, Langzeitspeicher und externer Speicher. Das lokale Gedächtnis bezieht sich auf alle Wörter, die im aktuellen Segment vorkommen und durch den Aufmerksamkeitsmechanismus vektorisiert wurden. Das Langzeitgedächtnis bezieht sich auf Textdarstellungen, die aufgrund von Einschränkungen der Eingabelänge nicht direkt abgerufen werden können, sondern aus demselben Dokument stammen wie der zu erstellende Text Der verarbeitete externe Speicher bezieht sich auf den großen Datenspeicherbereich, in dem alle Trainingsbeispiele oder zusätzliche Korpora gespeichert werden. 
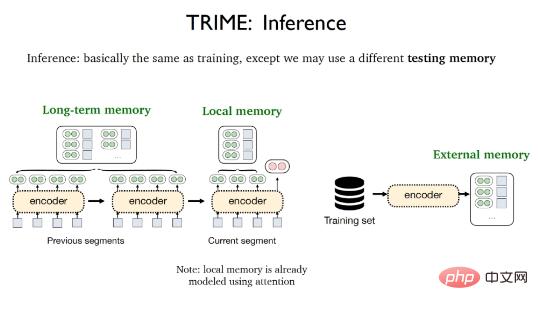
Um die Inkonsistenz zwischen den Trainings- und Testphasen zu minimieren, müssen bestimmte Datenverarbeitungsstrategien übernommen werden, um das Trainingsgedächtnis besser aufzubauen. Der lokale Speicher bezieht sich auf vorherige Token im selben Datenfragment und ist äußerst kostengünstig zu verwenden. Die Stapelverarbeitung mit Zufallsstichproben kann verwendet werden, um den lokalen Speicher sowohl in der Trainingsphase als auch in der Testphase direkt zu nutzen. Dies führt zu einer Basisversion des TrimeLM-Modells, die auf dem lokalen Speicher basiert.

Das Langzeitgedächtnis bezieht sich auf Tags in vorherigen Fragmenten desselben Dokuments und muss sich auf frühere Fragmente desselben Dokuments verlassen. Zu diesem Zweck werden aufeinanderfolgende Segmente (konsekutive Segmente) im selben Dokument in denselben Trainingsstapel gelegt, wodurch das TrimeLMlong-Modell des kollektiven Langzeitgedächtnisses entsteht.

Externer Speicher muss zum Abrufen mit großen Datenspeichern kombiniert werden. Zu diesem Zweck kann BM25 verwendet werden, um ähnliche Segmente in den Trainingsdaten in denselben Trainingsstapel zu packen, was zum TrimeLMext-Modell in Kombination mit externem Speicher führt.

Zusammenfassend lässt sich sagen, dass das traditionelle Sprachmodell in der Trainingsphase keinen Speicher verwendet und die kontinuierliche Caching-Methode in der Testphase nur den lokalen Speicher oder das Langzeitgedächtnis verwendet Speicher in der Testphase; und für die drei Sprachmodelle des TRIME-Algorithmus wird die Speichererweiterung sowohl in der Trainings- als auch in der Testphase verwendet. TrimeLMlong fügt aufeinanderfolgende Fragmente desselben Dokuments ein Beim gleichen Batch-Training werden während der Testphase lokaler Speicher und Langzeitspeicher kombiniert. TrimeLMext fügt während der Trainingsphase ähnliche Dokumente zum Training in denselben Stapel ein und kombiniert während der Testphase lokalen Speicher, Langzeitspeicher und externen Speicher.

In der experimentellen Phase können beim Testen des Modellparameters 247M und der Slice-Länge 3072 im WikiText-103-Datensatz die drei Versionen des auf dem TRIME-Algorithmus basierenden Sprachmodells eine bessere Verwirrung erzielen als die herkömmlichen Der Transformer Perplexity-Effekt, unter dem das auf der tatsächlichen Entfernung basierende TrimeLMext-Modell die besten experimentellen Ergebnisse erzielen kann. Gleichzeitig können TrimeLM und TrimeLMlong auch eine Abrufgeschwindigkeit beibehalten, die der des herkömmlichen Transformators nahe kommt, und bieten gleichzeitig die Vorteile von Ratlosigkeit und Abrufgeschwindigkeit.

Wenn Sie den Modellparameter 150M und die Slice-Länge 150 im WikiText-103-Datensatz testen, können Sie sehen, dass TrimeLMlong in der Trainingsphase aufeinanderfolgende Segmente desselben Dokuments in denselben Trainingsstapel einfügt. Sie werden in der Testphase kombiniert. Es nutzt den lokalen Speicher und das Langzeitgedächtnis. Obwohl die Scheibenlänge nur 150 beträgt, können die tatsächlich in der Testphase verfügbaren Daten 15.000 erreichen und die experimentellen Ergebnisse sind weitaus besser als bei anderen Basismodellen.

Bei der Konstruktion von Sprachmodellen auf Zeichenebene erzielte das auf dem TRIME-Algorithmus basierende Sprachmodell auch die besten experimentellen Ergebnisse für den enwik8-Datensatz. Gleichzeitig wurde bei der Anwendungsaufgabe der maschinellen Übersetzung auch TrimeMT_ext verwendet besser erreicht als die experimentellen Basisergebnisse des Modells.

Zusammenfassend lässt sich sagen, dass das auf dem TRIME-Algorithmus basierende Sprachmodell drei Methoden der Speicherkonstruktion anwendet und relevante Daten im selben Stapel vollständig nutzt, um eine Speichererweiterung zu erreichen. Es führt Speicher ein, ohne viele Berechnungen durchzuführen Ohne Kosten und ohne Änderung der Gesamtstruktur des Modells werden bessere experimentelle Ergebnisse erzielt als mit anderen Basismodellen.
Chen Danqi hob auch das abrufbasierte Sprachmodell hervor. Tatsächlich kann TrimeLMext als eine bessere Version des k-Nearest-Neighbor-Sprachmodells angesehen werden, aber während des Inferenzprozesses sind diese beiden Algorithmen schneller als andere Basismodelle . Es ist fast 10 bis 60 Mal langsamer, was offensichtlich inakzeptabel ist. Chen Danqi wies auf eine der möglichen zukünftigen Entwicklungsrichtungen abrufbasierter Sprachmodelle hin: Ist es möglich, einen kleineren Abruf-Encoder und einen größeren Datenspeicherbereich zu verwenden, um den Rechenaufwand für die Suche nach nächsten Nachbarn zu reduzieren?
Im Vergleich zu herkömmlichen Sprachmodellen haben abrufbasierte Sprachmodelle erhebliche Vorteile. Beispielsweise können abrufbasierte Sprachmodelle besser aktualisiert und gewartet werden, während herkömmliche Sprachmodelle nicht mithilfe von Vorkenntnissen trainiert werden können Gleichzeitig können abrufbasierte Sprachmodelle auch in datenschutzrelevanten Bereichen besser eingesetzt werden. Was die bessere Nutzung abrufbasierter Sprachmodelle anbelangt, glaubt Lehrer Chen Danqi, dass Feinabstimmung, Aufforderung oder kontextbezogenes Lernen zur Lösungsfindung beitragen können. 

Papieradresse: https://arxiv.org/abs/2204.00408
Modellkomprimierungstechnologie wird häufig in großen Sprachmodellen verwendet, sodass kleinere Modelle schneller an nachgelagerte Anwendungen angepasst werden können. Die herkömmlichen gängigen Modellkomprimierungsmethoden sind Destillation und Bereinigung. Für die Destillation ist es häufig erforderlich, ein festes Schülermodell vorab zu definieren. Dieses Schülermodell wird normalerweise zufällig initialisiert und dann wird das Wissen vom Lehrermodell auf das Schülermodell übertragen, um eine Wissensdestillation zu erreichen.
Ausgehend von der Originalversion von BERT können Sie beispielsweise nach der allgemeinen Destillation, also nach dem Training an einer großen Anzahl unbeschrifteter Korpora, die Basisversion von TinyBERT4 erhalten Verwenden Sie auch die aufgabengesteuerte Destillationsmethode. Durch den Erhalt des fein abgestimmten TinyBERT4 kann das endgültige Modell kleiner und schneller als das ursprüngliche BERT-Modell sein, allerdings auf Kosten einer geringen Genauigkeit. Diese auf Destillation basierende Methode weist jedoch auch bestimmte Mängel auf. Beispielsweise ist die Modellarchitektur für verschiedene nachgelagerte Aufgaben häufig gleichzeitig festgelegt und muss mithilfe unbeschrifteter Daten von Grund auf trainiert werden.

Beim Beschneiden ist es oft notwendig, von einem Lehrermodell auszugehen und dann kontinuierlich irrelevante Teile vom Originalmodell zu entfernen. Mit der im Jahr 2019 vorgeschlagenen unstrukturierten Beschneidung können kleinere Modelle erhalten werden, die Laufgeschwindigkeit wird jedoch nur geringfügig verbessert, während die strukturierte Beschneidung in praktischen Anwendungen Geschwindigkeitsverbesserungen durch die Entfernung von Parametergruppen wie Feedforward-Schichten erzielt, wie z. B. im Jahr 2021. Die vorgeschlagene Blockbeschneidung kann eine zwei- bis dreifache Geschwindigkeit erreichen Verbesserung.


Um die Grenzen traditioneller Destillations- und Beschneidungsmethoden zu überwinden, schlug das Team von Chen Danqi einen Algorithmus namens CofiPruning vor, Beschnitt sowohl grobkörnige als auch feinkörnige Einheiten und entwarf A Schicht für Schicht Die Destillationszielfunktion überträgt Wissen vom ungekürzten Modell auf das beschnittene Modell und kann letztendlich eine Geschwindigkeitssteigerung um mehr als das Zehnfache bei gleichzeitiger Beibehaltung einer Genauigkeit von mehr als 90 % im Vergleich zur herkömmlichen Destillationsmethode erzielen.
Der Vorschlag von CofiPruning basiert auf zwei wichtigen Grundarbeiten:
(1) Durch das Beschneiden der gesamten Schicht kann die Geschwindigkeit verbessert werden, aber etwa 50 % der Schichten des neuronalen Netzwerks können beschnitten werden Ein grobkörniger Schnitt hat einen größeren Einfluss auf die Genauigkeit.
(2) besteht darin, kleinere Einheiten wie Köpfe zu beschneiden, um eine bessere Flexibilität zu erreichen. Diese Methode stellt jedoch ein schwierigeres Optimierungsproblem bei der Implementierung dar und hat keine allzu großen Auswirkungen auf die Geschwindigkeit.
Aus diesem Grund hofft das Team von Chen Danqi, sowohl grobkörnige als auch feinkörnige Einheiten gleichzeitig beschneiden zu können und so beide Granularitäten zu nutzen. Um das Problem der Datenübertragung vom ursprünglichen Modell zum beschnittenen Modell zu lösen, verwendet CofiPruning außerdem eine schichtweise Ausrichtungsmethode, um Wissen während des Bereinigungsprozesses zu übertragen. Die endgültige Zielfunktion umfasst Destillationsverlust und Sparsitätsbasis Verzögerung. Langer Tagverlust.

In der experimentellen Phase kann am GLUE-Datensatz für Satzklassifizierungsaufgaben und am SQuAD1.1-Datensatz für Frage- und Antwortaufgaben festgestellt werden, dass CofiPruning alle Destillationen übertrifft und die beschnittene Basislinienmethode eine bessere Leistung erbringt.

Wenn bei TinyBERT keine universelle Destillation verwendet wird, wird der experimentelle Effekt stark reduziert. Wenn jedoch eine universelle Destillation verwendet wird, kann der experimentelle Effekt zwar verbessert werden, die Trainingszeit ist jedoch sehr teuer. Der CofiPruning-Algorithmus kann nicht nur fast den gleichen Effekt wie das Basismodell erzielen, sondern auch die Laufzeit und die Rechenkosten erheblich verbessern und eine schnellere Verarbeitungsgeschwindigkeit bei geringeren Rechenkosten erzielen. Experimente zeigen, dass bei grobkörnigen Einheiten die erste und letzte Feed-Forward-Schicht am stärksten erhalten bleibt, während bei feinkörnigen Einheiten die mittlere Schicht mit größerer Wahrscheinlichkeit beschnitten wird; Netzwerk Wahrscheinlicher, dass es beschnitten wird.

Zusammenfassend lässt sich sagen, dass CofiPruning ein sehr einfacher und effektiver Modellkomprimierungsalgorithmus ist, der grobkörnige und feinkörnige Einheiten gemeinsam beschneidet und mit der objektiven Funktion der schichtweisen Destillation kombiniert Connect Structure Pruning und Knowledge Destillation nutzen beide Algorithmen, was zu einer schnelleren Verarbeitung und kleineren Modellstrukturen führt. In Bezug auf den zukünftigen Trend der Modellkomprimierung konzentrierte sich Chen Danqi auch darauf, ob große Sprachmodelle wie GPT-3 beschnitten werden können und ob vorgelagerte Aufgaben beschnitten werden können. Dies sind Forschungsideen, auf die man sich in Zukunft konzentrieren kann.
3 Zusammenfassung und Ausblick
Groß angelegte Sprachmodelle haben jedoch aufgrund hoher Umwelt- und Wirtschaftskosten, Datenschutz- und Fairness-Bedenken sowie Schwierigkeiten bei Echtzeitaktualisierungen einen sehr erfreulichen praktischen Anwendungswert erreicht Sprachmodelle lassen noch viel zu wünschen übrig. Chen Danqi glaubt, dass zukünftige Sprachmodelle als umfangreiche Wissensdatenbanken verwendet werden können. Gleichzeitig muss der Umfang der Sprachmodelle in Zukunft erheblich reduziert werden, oder es können spärliche Sprachmodelle verwendet werden Ersetzen Sie die dichte Retrieval- und Modellkomprimierungsarbeit. Forscher müssen sich ebenfalls darauf konzentrieren.
Das obige ist der detaillierte Inhalt vonPrinceton Chen Danqi: Wie man „große Modelle' kleiner macht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr