
Heim >Technologie-Peripheriegeräte >KI >Nur 1/4 des Datenvolumens wird verwendet, um 100 % der Details realer Stimmen wiederherzustellen, und zwar mithilfe der neuesten Sprachsynthesetechnologie für übernatürliche Dialoge bei Volcano Voice!
Nur 1/4 des Datenvolumens wird verwendet, um 100 % der Details realer Stimmen wiederherzustellen, und zwar mithilfe der neuesten Sprachsynthesetechnologie für übernatürliche Dialoge bei Volcano Voice!

- PHPznach vorne
- 2023-04-08 15:21:101671Durchsuche
Tausende von Jay-Fans haben die Sterne gezählt und auf den Mond gehofft, seit 6 Jahren hat Jay Chou endlich ein neues Album veröffentlicht! Als es online ging, löste es Diskussionen im Internet aus.
Während alle in den schönen Erinnerungen an diese großartigen Jahre versunken waren, sagte der Freund, der das virale Audio gepostet hatte: Dieses Gespräch war eigentlich Sprachsynthese!
Wenn es um „Sprachsynthese“ geht, kommt Ihnen möglicherweise Folgendes in den Sinn:
• „An der Kreuzung vor Ihnen links abbiegen.“
• Beim Beantworten des Telefons , die Person auf der anderen Seite sagte ungeschickt und emotionslos „Hallo, das ist xx Credit Card Center“, der Name dieses Mannes ist Xiaoshuai“…Jetzt hat es die Stereotypen vieler Menschen bereits erreicht Derselbe perfekte und natürliche Effekt wie das Audio oben. Der Herausgeber dieses Audios –
Volcano Voice, ByteDanceAI Lab Speech & Audio Intelligent Speech and Audio Team
– hat zwei Audiostücke verwendet, um den Inhalt für die Öffentlichkeit besser zu entschlüsseln . Der Eingabetext dieser Sätze ist genau derselbe, das heißt: „Die südländische Küche bevorzugt Dip-Saucen.“ Als ich zum Beispiel zum ersten Mal in Shanghai war, habe ich gelernt, dass Gemüse beim Grillen auch mit Dip-Saucen serviert werden muss .“ Die synthetisierten Audioeffekte sind jedoch offensichtlich unterschiedlich. Das heißt, das zweite Audiostück stammt aus der neuen Sprachsynthesetechnologie für übernatürliche Dialoge, die dieses Mal vom Volcano Voice Team eingeführt wurde. Erinnern Sie sich an den Zustand der täglichen Ausdrücke der Menschen. Das Gehirn braucht Bedenkzeit, um Informationen zu verarbeiten. Wenn es um Sprache geht, zögern Menschen unwillkürlich, wenden ihre Aussprache an oder ändern sie sogar mitten im Satz, stottern und wiederholen. Sie betonen auch bewusst die Aussprache, um die wichtigsten Informationen hervorzuheben, die sie ausdrücken möchten. Dies führt zu einer Vielzahl subtiler Ausdrücke, die schwer zu beobachten sind. Diese Phänomene sind in herkömmlichen TTS schwer zu erfassen und wiederherzustellen. Die perfekte Wiedergabe dieser Feinheiten ist die Quelle des Mysteriums, das es schwierig macht, die Authentizität des Klangs zu erkennen, und ist auch das Mysterium des oben genannten Audios.
Konkret:Die neueste vom Volcano Voice Team veröffentlichte Sprachsynthesetechnologie für übernatürliche Dialoge
ist realistischer und natürlicher als herkömmliches TTS, d. h. alle Details wie Modalpartikel, Einatmungsgeräusche, Pausen während des Zögerns usw Die Ausspracheverlängerung ist vollständig integriert. Sie wird perfekt reproduziertund benötigt nur ein Viertel der Daten der herkömmlichen Klangbibliothek, um die subtilen rhythmischen Eigenschaften und Aussprachegewohnheiten echter sprechender Menschen perfekt wiederherzustellen, wodurch der Syntheseeffekt realistischer wird. Professionelle Bewertungsergebnisse zeigen, dass es grundsätzlich keinen Unterschied zwischen dieser neuen Technologie von Huoshan Voice und Aufnahmen von realen Personen gibt und es für Rezensenten schwierig ist, sie zu unterscheiden. Darüber hinaus wurde diese Technologie in vielen Szenarien wie der Videoüberspielung und dem telefonischen Kundendienst eingesetzt. Sie wird in naher Zukunft auf der offiziellen Website von Volcano Engine Voice Technology eingeführt.
Wie um alles in der Welt wird eine so leistungsstarke Technologie erreicht? Berichten zufolge werden die oben genannten Manifestationen wie Keuchen, Schlucken, unwillkürliche Verlängerung der Wortaussprache beim Denken und leises Lachen, die häufig in der tatsächlichen Kommunikation auftreten, als Parasprachphänomene (Parasprache) bezeichnet
, obwohl dies der Fall ist ist die realistischste Darstellung des Denk- und Ausdrucksprozesses des menschlichen Gehirns. Da das traditionelle Sprachsynthese-Technologie-Framework jedoch spärlich verteilte paralinguistische Phänomene nicht effektiv modellieren kann, ist die prosodische Wiederherstellungsleistung beim Sprechen begrenzt und zu „korrekt“.Basierend auf den oben genannten Schwierigkeiten macht die übernatürliche Sprachsynthese -Technologie von Huoshan Voice Durchbrüche aus zwei Ebenen: Text
undspeech -Modellierung , speziell:
•at die Textebene, Huoshan Voice übernimmt The The Das generative Stilübertragungsmodell imitiert die Art und Weise, wie echte Menschen sprechen, und führt eine kontrollierbare umgangssprachliche Transkription des Textes durch, sodass der Text die Umgangssprache besser berücksichtigt und verhindert, dass der Endeffekt zu geschrieben wird. Auf Stimmebene analysiert das Team den Durchbruch des Modells und fügt auf der Eingabeseite des TTS zusätzliche Sprachvorhersagen hinzu, um die Ausspracheeigenschaften der Person zu imitieren und so natürliche spontane Stimmeffekte zu erzielen.
Es ist erwähnenswert, dass das Team die Stabilität und Ausdruckskraft des Modells durch die Verwendung der TTS-Modellierungslösung mit unbeaufsichtigten Funktionen effektiv verbessert hat. Es kann mit nur 1/4 der Datengröße sehr natürliche und facettenreiche Klänge erzielen Herkömmliche Soundbibliotheken Der wechselnde Rhythmuseffekt ist großartig, oder?
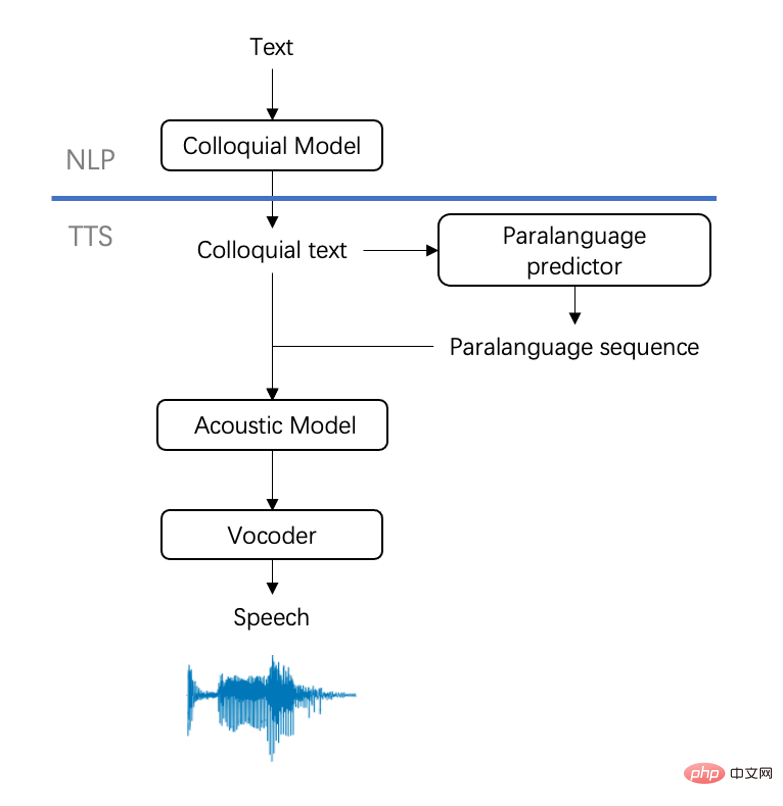
Der Text-Umgangssprache gewidmet, um den Ausdruck „realer Personen“ zum Leben zu erwecken Der erste Faktor zur Verbesserung des Syntheseeffekts. Aufgrund der tief verwurzelten Schreibgewohnheiten sind die meisten vorsynthetisierten Texte jedoch nicht natürlich genug oder erfordern viel Aufwand und kontinuierliche Anpassung, was zeitaufwändig und arbeitsintensiv ist. Um solche Probleme zu lösen, hat das Huoshan Voice-Team eine zweistufige Lösung angenommen und gute Ergebnisse erzielt:
• Phase 1: Verwendung Selbstüberwachte Methode, die Pseudodaten verwendet, um das gesprochene Sprachmodell vorab zu trainieren , Reduzierung Der Bedarf an Datenvolumen wird reduziert, gleichzeitig wird eine Zeigernetzwerkstruktur in das Modell eingeführt, um die Textsteuerbarkeit zu verbessern.
• Phase 2: Verwenden Sie eine kleine Menge hochwertiger manueller Anmerkungsdaten, um das vorab trainierte umgangssprachliche Modell zu verfeinern und schließlich kontrollierbare und natürliche umgangssprachliche Texteffekte zu erzielen.
|
| Automatisch vorhergesagter Text
|
|
| Südliche Küche Wenn ja, , zum Beispiel mein erstes Mal äh, mein erstes Mal ging nach Shanghai, und mir wurde klar, dass das Gemüse in diesem Barbecue auch so ist müssen von Dip-Saucen begleitet werden |
Wenn wir zum Beispiel auf die Straße gehen, um Kohl zu kaufen, sagen die Südländer, ich möchte einen halben Kohl, und die Nordländer sagen, ich möchte einen halben Wagen Kohl Nun, das ist ähnlich wie | wenn wir Kohl kaufen gehen|
| und dann sagen die Nordländer, ich möchte die Hälfte ein Kohl
|
Tatsächlich legt die südliche Küche mehr Wert auf den Geschmack von Gewürzen, das heißt, der Koch verwendet Gewürze, um sein Können unter Beweis zu stellen |
Ja, tatsächlich legt die südliche Küche mehr Wert über den Geschmack von Gewürzen, Mit anderen Worten: Der Koch nutzt Gewürze, um sein Können unter Beweis zu stellen |
Parasprachliche Modellierung + prosodische Vielfalt ist bemerkenswert – Der Sprachrealismus wurde vollständig verbessert wurden ebenfalls eingehend untersucht. Im Hinblick auf die parasprachliche Modellierung ermöglicht die vom Team eingeführte Synthesetechnologie dem akustischen Modell, eine Vielzahl paralinguistischer Phänomene wie Einatmen, Lachen, Zögern und Korrekturen zu modellieren, die in natürlichen Ausdrücken auftreten, und kombiniert sie mit den semantischen Informationen des Textes um automatisch paralinguistische Phänomene einzufügen . Wenn man beim Einfügevorgang sowohl „Rationalität als auch Zufälligkeit“ berücksichtigt, ist die Leistung natürlicher und realer.
|
Übernatürlich
|
|
| C.wav
|
|
| D.wav
|
|
|
Rutschkorrektur > | , ich möchte unbedingt Fleisch essen. Kopie von |
|
ParalangTest_is_000008_npy_01_new2.wav | "Bei der Erforschung der rhythmischen Vielfalt haben wir uns zusammengetan Mit der unüberwachten Repräsentationslerntechnologie haben wir unabhängig ein hoch ausdrucksstarkes akustisches Modellgerüst entwickelt. Durch die Entkopplung von Aussprache, Rhythmus und Klangfarbe wird nicht nur die erforderliche Datenmenge reduziert, sondern auch eine effiziente Modellierung extrem niederfrequenter Aussprachephänomene erreicht „Gleichzeitig werden unbeaufsichtigte Darstellungsmerkmale in Kombination mit Grundfrequenzen auf Phonemebene, Energieinformationen usw. verwendet, um natürliche Veränderungen in der Prosodie zu erreichen und eine qualitativ hochwertige Konversationsspracherzeugung zu fördern“, schlussfolgerte das Huoshan Speech Team. Huoshan Voice, das intelligente Sprach- und Audioteam von ByteDance AI Lab Speech & Audio, stellt seit langem führende KI-Sprachtechnologiefunktionen und Full-Stack-Sprachprodukte für Douyin, Jianying, Tomato Novels, Feishu und andere Unternehmenslösungen bereit Offene technische Dienstleistungen für externe Unternehmen über die Volcano Engine. |
Das obige ist der detaillierte Inhalt vonNur 1/4 des Datenvolumens wird verwendet, um 100 % der Details realer Stimmen wiederherzustellen, und zwar mithilfe der neuesten Sprachsynthesetechnologie für übernatürliche Dialoge bei Volcano Voice!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr