
Heim >Technologie-Peripheriegeräte >KI >Virtuell-reale Domänenanpassungsmethode zur autonomen Fahrspurerkennung und -klassifizierung
Virtuell-reale Domänenanpassungsmethode zur autonomen Fahrspurerkennung und -klassifizierung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-08 14:31:121920Durchsuche
arXiv-Artikel „Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving“, Mai 2022, Arbeit an der University of Waterloo, Kanada.

Obwohl das überwachte Erkennungs- und Klassifizierungs-Framework für autonomes Fahren große annotierte Datensätze erfordert, ist die Unüberwachte Domänenanpassung (UDA, Unsupervised Domain Adaptation)-Methode, die auf synthetischen Daten basiert, die durch Beleuchtung realer Simulationsumgebungen generiert werden, kostengünstig. Weniger zeitaufwändige Lösung. In diesem Artikel wird ein UDA-Schema kontradiktorischer diskriminierender und generativer Methoden für Anwendungen zur Spurlinienerkennung und -klassifizierung beim autonomen Fahren vorgeschlagen.
Stellt außerdem den Simulanes-Datensatzgenerator vor, der die riesigen Verkehrsszenen und Wetterbedingungen von CARLA nutzt, um einen natürlichen synthetischen Datensatz zu erstellen. Das vorgeschlagene UDA-Framework verwendet den beschrifteten synthetischen Datensatz als Quelldomäne, während die Zieldomäne die unbeschrifteten realen Daten sind. Verwenden Sie die gegnerische Generierung und den Feature-Diskriminator, um das Lernmodell zu debuggen und die Spurposition und -kategorie der Zieldomäne vorherzusagen. Die Auswertung erfolgt mit realen und synthetischen Datensätzen.
Das Open-Source-UDA-Framework finden Sie unter githubcom/anita-hu/sim2real-lane-detection und den Datensatzgenerator unter github.com/anita-hu/simulanes.
Das Fahren in der realen Welt ist vielfältig, mit unterschiedlichen Verkehrsbedingungen, Wetterbedingungen und Umgebungen. Daher ist die Vielfalt der Simulationsszenarien entscheidend für die gute Anpassbarkeit des Modells in der realen Welt. Es gibt viele Open-Source-Simulatoren für autonomes Fahren, nämlich CARLA und LGSVL. In diesem Artikel wird CARLA zum Generieren des Simulationsdatensatzes ausgewählt. Zusätzlich zur flexiblen Python-API enthält CARLA auch umfangreiche vorgezeichnete Karteninhalte, die städtische, ländliche und Autobahnszenen abdecken.
Der Simulationsdatengenerator Simulanes generiert eine Vielzahl von Simulationsszenarien in städtischen, ländlichen und Autobahnumgebungen, darunter 15 Fahrspurkategorien und dynamisches Wetter. Die Abbildung zeigt Beispiele aus dem synthetischen Datensatz. Fußgänger- und Fahrzeugteilnehmer werden zufällig generiert und auf der Karte platziert, was die Schwierigkeit des Datensatzes durch Verdeckung erhöht. Gemäß den TuSimple- und CULane-Datensätzen ist die maximale Anzahl von Fahrspuren in der Nähe des Fahrzeugs auf 4 begrenzt und Reihenanker werden als Beschriftungen verwendet.

Da der CARLA-Simulator keine Spurpositionsbeschriftungen direkt bereitstellt, wird das Wegpunktsystem von CARLA zur Generierung von Beschriftungen verwendet. Ein CARLA-Wegpunkt ist eine vordefinierte Position in der Mitte der Fahrspur, der der Autopilot des Fahrzeugs folgen soll. Um die Spurpositionsbezeichnung zu erhalten, wird der Wegpunkt der aktuellen Spur um W/2 nach links und rechts verschoben, wobei W die vom Simulator vorgegebene Spurbreite ist. Diese verschobenen Wegpunkte werden dann in das Kamerakoordinatensystem projiziert und mit einer Spline-Kurve versehen, um Beschriftungen entlang vorgegebener Zeilenankerpunkte zu generieren. Die Klassenbezeichnung wird vom Simulator vergeben und ist eine von 15 Klassen.
Um einen Datensatz mit N Frames zu generieren, teilen Sie N gleichmäßig auf alle verfügbaren Karten auf. Auf der standardmäßigen CARLA-Karte wurden die Städte 1, 3, 4, 5, 7 und 10 verwendet, während die Städte 2 und 6 aufgrund von Unterschieden zwischen den extrahierten Spurpositionsbeschriftungen und den Spurpositionen des Bildes nicht verwendet wurden. Für jede Karte erscheinen Fahrzeugteilnehmer an zufälligen Orten und bewegen sich zufällig. Dynamisches Wetter wird dadurch erreicht, dass sich der Sonnenstand als sinusförmige Funktion der Zeit sanft ändert und gelegentlich Stürme entstehen, die das Erscheinungsbild der Umgebung durch Variablen wie Wolkenbedeckung, Wassermenge und stehendes Wasser beeinflussen. Um zu vermeiden, dass mehrere Frames am selben Ort gespeichert werden, prüfen Sie, ob sich das Fahrzeug vom Standort des vorherigen Frames entfernt hat, und generieren Sie ein neues Fahrzeug neu, wenn es zu lange stillsteht.
Wenn der Sim-to-Real-Algorithmus auf die Spurerkennung angewendet wird, wird ein End-to-End-Ansatz gewählt und das Ultra-Fast-Lane-Detection (UFLD)-Modell als Basisnetzwerk verwendet. Die Wahl fiel auf UFLD, weil seine leichte Architektur bei gleicher Eingangsauflösung 300 Bilder/Sekunde erreichen kann und gleichzeitig eine mit modernsten Methoden vergleichbare Leistung erzielt. UFLD formuliert die Fahrspurerkennungsaufgabe als zeilenbasierte Auswahlmethode, bei der jede Fahrspur durch eine Reihe horizontaler Positionen vordefinierter Zeilen, d. h. Zeilenanker, dargestellt wird. Für jeden Zeilenanker wird die Position in w Rasterzellen unterteilt. Für den Anker der i-ten Spur und der j-ten Reihe wird die Standortvorhersage zu einem Klassifizierungsproblem, bei dem das Modell die Wahrscheinlichkeit Pi,j für die Auswahl der (w+1)-Gitterzelle ausgibt. Die zusätzliche Dimension in der Ausgabe sind keine Spuren.
UFLD schlägt einen zusätzlichen Segmentierungszweig vor, um Features in mehreren Maßstäben zu aggregieren, um lokale Features zu modellieren. Dieser wird nur während des Trainings verwendet. Bei der UFLD-Methode wird der Kreuzentropieverlust für den Segmentierungsverlust Lseg verwendet. Für die Spurklassifizierung wird ein kleiner Zweig der vollständig verbundenen (FC) Schicht hinzugefügt, um dieselben Funktionen wie die FC-Schicht für die Spurpositionsvorhersage zu erhalten. Der Spurklassifizierungsverlust Lcls verwendet auch Kreuzentropieverlust.
Um das Domain-Drift-Problem der UDA-Einstellungen zu lindern, UNIT(“Unsupervised Image-to-Image Translation Networks“, NIPS, 2017) & MUNIT(“Multimodale unüberwachte Bild-zu-Bild-Übersetzung, ” ECCV 2018) kontradiktorische Generierungsmethode und kontradiktorische Diskriminanzmethode unter Verwendung eines Merkmalsdiskriminators. Wie in der Abbildung gezeigt: Es werden eine gegnerische Generierungsmethode (A) und eine gegnerische Diskriminierungsmethode (B) vorgeschlagen. UNIT und MUNIT werden in (A) dargestellt, das die Generatoreingabe für die Bildübersetzung zeigt. Zusätzliche Stileingaben für MUNIT werden mit blauen gestrichelten Linien angezeigt. Der Einfachheit halber wird der Encoderausgang im MUNIT-Stil weggelassen, da er nicht für die Bildübersetzung verwendet wird.

Die experimentellen Ergebnisse sind wie folgt:
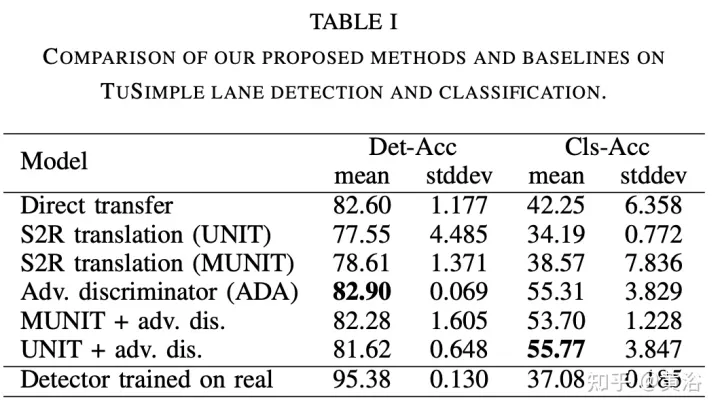

Links: Direktübertragungsmethode, rechts: Adversarial Identification (ADA)-Methode
Das obige ist der detaillierte Inhalt vonVirtuell-reale Domänenanpassungsmethode zur autonomen Fahrspurerkennung und -klassifizierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr