
Heim >Technologie-Peripheriegeräte >KI >Wenn Sie künstliche Intelligenz erlernen möchten, müssen Sie diesen Datensatz beherrschen. Einführung und praktische Anwendung von MNIST
Wenn Sie künstliche Intelligenz erlernen möchten, müssen Sie diesen Datensatz beherrschen. Einführung und praktische Anwendung von MNIST

- 王林nach vorne
- 2023-04-08 11:11:062148Durchsuche
Das Erlernen künstlicher Intelligenz erfordert zwangsläufig einige Datensätze. Künstliche Intelligenz zum Erkennen von Pornografie erfordert beispielsweise einige ähnliche Bilder. Künstliche Intelligenz für Spracherkennung und Korpus ist unverzichtbar. Studierende, die neu im Bereich der künstlichen Intelligenz sind, machen sich oft Sorgen um Datensätze. Heute stellen wir einen sehr einfachen, aber sehr nützlichen Datensatz vor, nämlich MNIST. Dieser Datensatz eignet sich sehr gut für das Erlernen und Üben von Algorithmen im Zusammenhang mit künstlicher Intelligenz.
Der MNIST-Datensatz ist ein sehr einfacher Datensatz, der vom National Institute of Standards and Technology (NIST) erstellt wurde. Worum geht es also in diesem Datensatz? Es handelt sich tatsächlich um einige handgeschriebene arabische Ziffern (zehn Zahlen von 0 bis 9).
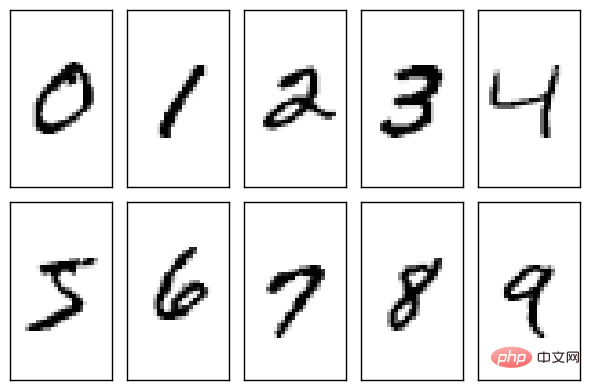
NIST ist bei der Erstellung des Datensatzes immer noch sehr ernst. Der Trainingssatz im Datensatz besteht aus handgeschriebenen Ziffern von 250 verschiedenen Personen, von denen 50 % Oberstufenschüler und 50 % Mitarbeiter des Census Bureau sind. Der Testsatz besteht ebenfalls aus dem gleichen Anteil handgeschriebener Zifferndaten.
So laden Sie den MNIST-Datensatz herunter
Der MNIST-Datensatz kann von der offiziellen Website (http://yann.lecun.com/exdb/mnist/) heruntergeladen werden langsam. Es enthält vier Teile:
- Bilder des Trainingssatzes: train-images-idx3-ubyte.gz (9,9 MB, 47 MB nach der Dekomprimierung, enthält 60.000 Beispiele)
- Beschriftungen des Trainingssatzes: train-labels-idx1-ubyte. gz (29 KB, 60 KB nach der Dekomprimierung, enthält 60.000 Tags)
- Testsatzbild: t10k-images-idx3-ubyte.gz (1,6 MB, 7,8 MB nach der Dekomprimierung, enthält 10.000 Beispiele)
- Testsatz-Tags: t10k- labels-idx1-ubyte.gz (5 KB, 10 KB nach der Dekomprimierung, enthält 10.000 Etiketten)
Das Obige enthält zwei Arten von Inhalten, eines sind Bilder, das andere sind Etiketten, Bilder und Etiketten entsprechen einer nach der anderen. Aber das Bild hier ist nicht die Bilddatei, die wir normalerweise sehen, sondern eine Binärdatei. Dieser Datensatz speichert 60.000 Bilder in einem Binärformat. Die Beschriftung ist die reelle Zahl, die dem Bild entspricht.
Wie in der Abbildung unten gezeigt, lädt dieser Artikel den Datensatz lokal herunter und dekomprimiert das Ergebnis. Zum einfacheren Vergleich sind das ursprüngliche komprimierte Paket und die dekomprimierten Dateien enthalten.
Eine kurze Analyse des Formats des Datensatzes
Jeder hat festgestellt, dass das komprimierte Paket nach der Dekomprimierung kein Bild ist, sondern jedes komprimierte Paket einem unabhängigen Problem entspricht. In dieser Datei werden Informationen über Zehntausende Bilder oder Tags gespeichert. Wie werden diese Informationen in dieser Datei gespeichert?
Tatsächlich gibt es auf der offiziellen Website von MNIST eine detaillierte Beschreibung. Am Beispiel der Bilddatei des Trainingssatzes lautet die Beschreibung des Dateiformats auf der offiziellen Website wie folgt:
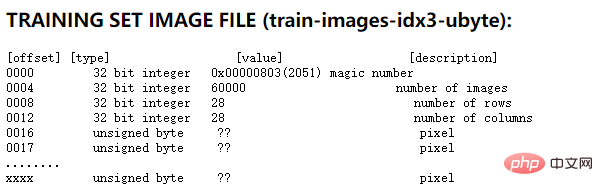
Wie aus dem Bild oben ersichtlich ist, sind die ersten vier 32-stelligen Zahlen die Beschreibungsinformationen des Trainingssatzes. Die erste ist die magische Zahl, die ein fester Wert von 0x0803 ist; die zweite ist die Anzahl der Bilder, 0xea60, also 60000; die dritte und vierte Zahl sind die Größe des Bildes, d. h. das Bild ist 28 *28 Pixel. Im Folgenden wird jedes Pixel in einem Byte beschrieben. Da in dieser Datei ein Byte zur Beschreibung eines Pixels verwendet wird, können Sie wissen, dass der Wert eines Pixels zwischen 0 und 255 liegen kann. Dabei bedeutet 0 Weiß und 255 Schwarz.

Das Format von Etikettendateien ähnelt dem von Bilddateien. Davor stehen zwei 32-stellige Zahlen, von denen die erste die magische Zahl ist, der feste Wert 0x0801 dient zur Beschreibung der Anzahl der Tags. Die nächsten Daten sind der Wert jedes Tags, dargestellt durch ein Byte. Der hier dargestellte Wertebereich ist

Die Daten, die der Etikettendatei des tatsächlichen Trainingssatzes entsprechen, lauten wie folgt. Es ist ersichtlich, dass es mit der Beschreibung des obigen Formats übereinstimmt. Darüber hinaus können wir sehen, dass entsprechend diesem Etikettensatz die in den vorherigen Bildern dargestellten Zahlen 5, 0, 4, 1 usw. sein sollten. Merken Sie es sich hier, es wird später verwendet.

Wir kennen das Dateiformat des Datensatzes, lassen Sie es uns in der Praxis umsetzen.
Visuelle Verarbeitung von Datensätzen
Nachdem wir das Speicherformat der oben genannten Daten kennen, können wir die Daten analysieren. Im folgenden Artikel wird beispielsweise ein kleines Programm implementiert, um ein Bild in der Bildersammlung zu analysieren und visuelle Ergebnisse zu erhalten. Natürlich können wir anhand des Wertes des Etikettensatzes tatsächlich wissen, um was für ein Bild es sich handelt. Dies ist nur ein Experiment. Das Endergebnis wird in einer Textdatei gespeichert, wobei das Zeichen „Y“ für die Handschrift und das Zeichen „0“ für die Hintergrundfarbe verwendet wird. Der spezifische Programmcode ist sehr einfach und wird in diesem Artikel nicht im Detail beschrieben.
# -*- coding: UTF-8 -*-
def trans_to_txt(train_file, txt_file, index):
with open(train_file, 'rb') as sf:
with open(txt_file, "w") as wf:
offset = 16 + (28*28*index)
cur_pos = offset
count = 28*28
strlen = 1
out_count = 1
while cur_pos < offset+count:
sf.seek(cur_pos)
data = sf.read(strlen)
res = int(data[0])
#虽然在数据集中像素是1-255表示颜色,这里简化为Y
if res > 0 :
wf.write(" Y ")
else:
wf.write(" 0 ")
#由于图片是28列,因此在此进行换行
if out_count % 28 == 0 :
wf.write("n")
cur_pos += strlen
out_count += 1
trans_to_txt("../data/train-images.idx3-ubyte", "image.txt", 0)Wenn wir den obigen Code ausführen, können wir eine Datei mit dem Namen image.txt erhalten. Sie können den Inhalt der Datei wie folgt sehen. Die roten Noten wurden später hinzugefügt, hauptsächlich zur besseren Sichtbarkeit. Wie Sie auf dem Bild sehen können, handelt es sich tatsächlich um eine handgeschriebene „5“.

Zuvor haben wir den Datensatz visuell über die native Python-Schnittstelle analysiert. Python verfügt über viele bereits implementierte Bibliotheksfunktionen, sodass wir die oben genannten Funktionen durch eine Bibliotheksfunktion vereinfachen können.
Parsen von Daten basierend auf Bibliotheken von Drittanbietern
Die Implementierung über die native Python-Schnittstelle ist etwas kompliziert. Wir wissen, dass Python über viele Bibliotheken von Drittanbietern verfügt, sodass wir Bibliotheken von Drittanbietern verwenden können, um den Datensatz zu analysieren und anzuzeigen. Der spezifische Code lautet wie folgt.
# -*- coding: utf-8 -*-
import os
import struct
import numpy as np
# 读取数据集,以二维数组的方式返回图片信息和标签信息
def load_mnist(path, kind='train'):
# 从指定目录加载数据集
labels_path = os.path.join(path,
'%s-labels.idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images.idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',
lbpath.read(8))
labels = np.fromfile(lbpath,
dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
#解析图片信息,存储在images中
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(len(labels), 784)
return images, labels
# 在终端打印某个图片的数据信息
def print_image(data, index):
idx = 0;
count = 0;
for item in data[index]:
if count % 28 == 0:
print("")
if item > 0:
print("33[7;31mY 33[0m", end="")
else:
print("0 ", end="")
count += 1
def main():
cur_path = os.getcwd()
cur_path = os.path.join(cur_path, "..data")
imgs, labels = load_mnist(cur_path)
print_image(imgs, 0)
if __name__ == "__main__":
main()Der obige Code ist in zwei Schritte unterteilt. Der erste Schritt besteht darin, den Datensatz in ein Array zu analysieren, und der zweite Schritt besteht darin, ein bestimmtes Bild im Array anzuzeigen. Die Anzeige erfolgt hier ebenfalls über ein Textprogramm, allerdings wird diese nicht in einer Datei gespeichert, sondern auf dem Terminal ausgedruckt. Wenn wir beispielsweise noch das erste Bild drucken, ist der Effekt wie folgt:

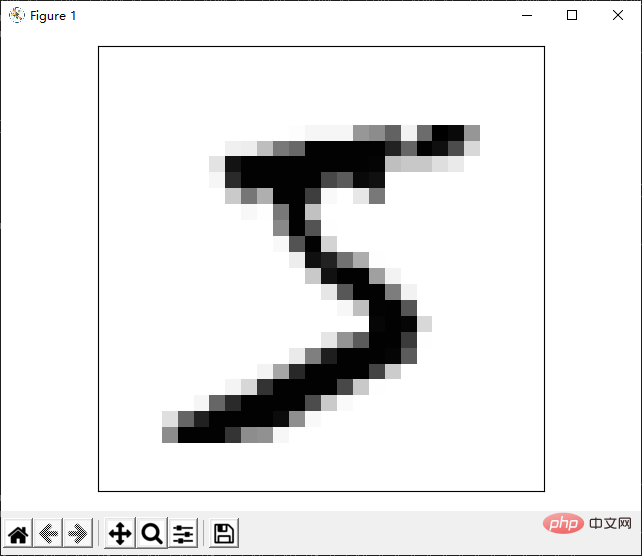
Die Darstellung der obigen Ergebnisse simuliert das Bild nur durch Zeichen. Tatsächlich können wir Bibliotheken von Drittanbietern verwenden, um eine perfektere Bildpräsentation zu erreichen. Als nächstes stellen wir vor, wie man Bilder über die Matplotlib-Bibliothek präsentiert. Diese Bibliothek ist sehr nützlich und ich werde später mit ihr in Kontakt kommen.
Wir implementieren ein
def show_image(data, index): fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True, sharey=True, ) img = data[0].reshape(28, 28) ax.imshow(img, cmap='Greys', interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) plt.tight_layout() plt.show()
Sie können derzeit sehen, dass
bei der Implementierung der oben genannten Funktionen möglicherweise einige Bibliotheken von Drittanbietern wie Matplotlib usw. fehlen. Zu diesem Zeitpunkt müssen wir es manuell installieren:
pip install matplotlib -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
Datenanalyse basierend auf TensorFlow
MNIST ist so berühmt, dass TensorFlow es bereits unterstützt. Daher können wir es über TensorFlow laden und analysieren. Nachfolgend geben wir den mit TensorFlow implementierten Code an.
# -*- coding: utf-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import pylab
def show_mnist():
# 通过TensorFlow库解析数据
mnist = input_data.read_data_sets("../data", one_hot=True)
im = mnist.train.images[0]
im = im.reshape(28 ,28)
# 进行绘图
pylab.imshow(im, cmap='Greys', interpolation='nearest')
pylab.show()
if __name__ == "__main__":
show_mnist()Der durch diesen Code erzielte Endeffekt stimmt mit dem vorherigen Beispiel überein, daher werde ich hier nicht auf Details eingehen.
Das obige ist der detaillierte Inhalt vonWenn Sie künstliche Intelligenz erlernen möchten, müssen Sie diesen Datensatz beherrschen. Einführung und praktische Anwendung von MNIST. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr