
Heim >Web-Frontend >js-Tutorial >So verwenden Sie Node zur Bildkomprimierung
So verwenden Sie Node zur Bildkomprimierung

- 青灯夜游nach vorne
- 2023-03-20 18:22:482370Durchsuche
Wie verwende ich Node für die Bildkomprimierung? Im folgenden Artikel werden PNG-Bilder als Beispiel verwendet, um die Komprimierung von Bildern vorzustellen. Ich hoffe, er ist hilfreich für Sie!

Kürzlich möchte ich Bildverarbeitungsdienste anbieten, darunter die Implementierung der Bildkomprimierungsfunktion. Früher konnte ich bei der Entwicklung des Front-Ends einfach die vorgefertigte API von Canvas verwenden, um es zu verarbeiten. Das Back-End verfügt möglicherweise auch über eine vorgefertigte API, aber ich weiß es nicht. Wenn ich sorgfältig darüber nachdenke, habe ich das Prinzip der Bildkomprimierung nie im Detail verstanden. Deshalb habe ich diese Gelegenheit einfach genutzt, um etwas zu recherchieren und zu studieren, und diesen Artikel geschrieben, um es aufzuzeichnen. Wie immer gilt: Wenn etwas nicht stimmt, DDDD (nimm deinen Bruder mit).
Wir laden zunächst das Bild ins Backend hoch und schauen, welche Parameter das Backend erhält. Ich verwende hier Node.js (Nest) als Backend und verwende PNG-Bilder als Beispiel.
Die Schnittstelle und die Parameter werden wie folgt gedruckt:
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> <br/> return {<br/> file<br/> }<br/>}<br/>
Um die Komprimierung durchzuführen, müssen wir die Bilddaten abrufen. Wie Sie sehen, ist das Einzige, was Bilddaten verbergen kann, diese Pufferfolge. Was beschreibt diese Pufferfolge? Sie müssen zunächst herausfinden, was PNG ist. [Empfohlene verwandte Tutorials: nodejs-Video-Tutorial, Programmierunterricht]
PNG
Hier ist die WIKI-Adresse von PNG.
Nachdem ich es gelesen hatte, erfuhr ich, dass PNG aus einem 8-Byte-Dateiheader und mehreren Blöcken besteht. Das schematische Diagramm sieht wie folgt aus:
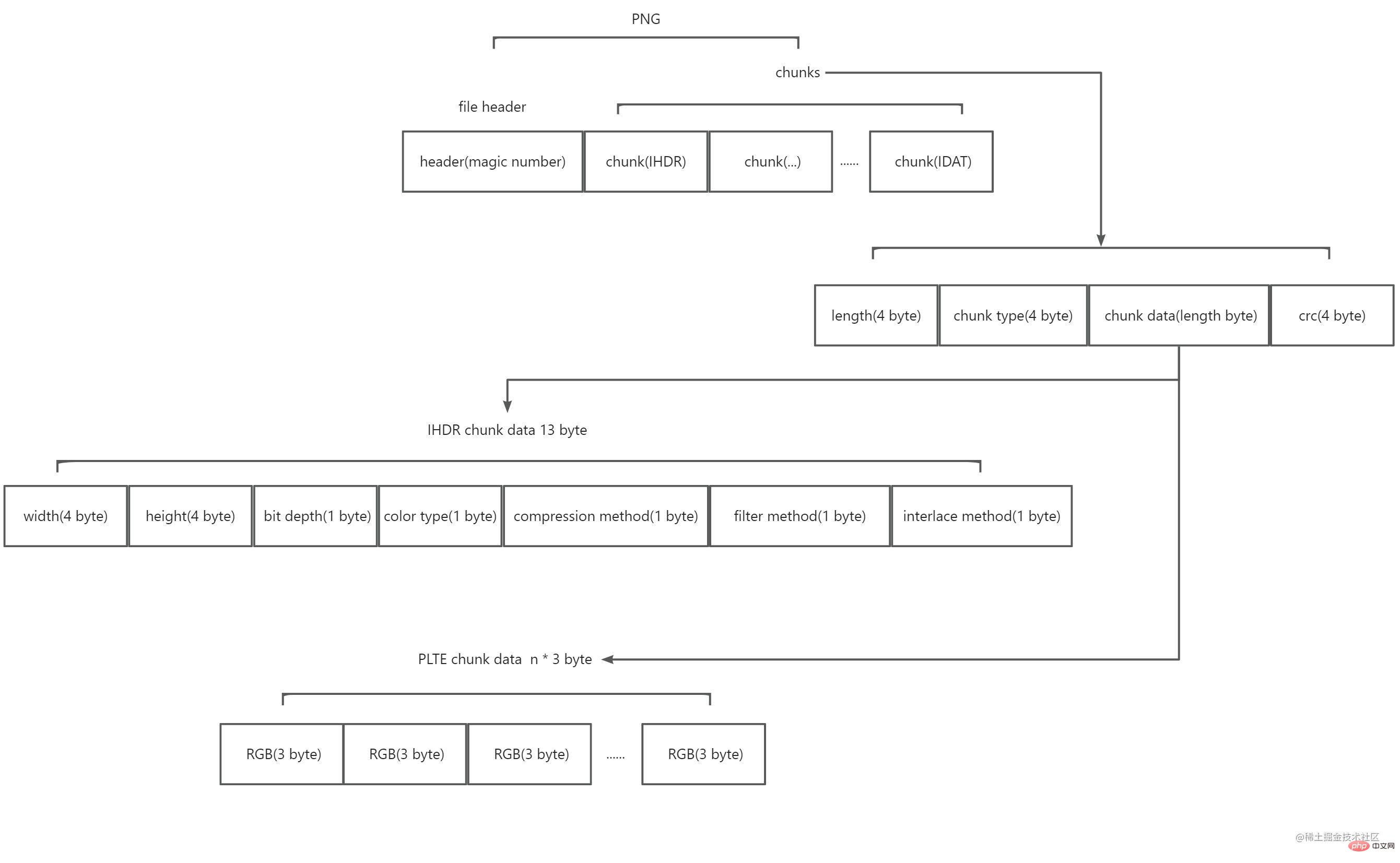
Darunter:
Der Dateikopf besteht aus einer sogenannten magischen Zahl. Der Wert ist 89 50 4e 47 0d 0a 1a 0a (hexadezimal). Es markiert diese Datenzeichenfolge als PNG-Format.
Blöcke werden in zwei Typen unterteilt, einer wird als „kritische Blöcke“ (kritische Blöcke) und der andere als „Hilfsblöcke“ (Hilfsblöcke) bezeichnet. Der Schlüsselblock ist unerlässlich. Ohne den Schlüsselblock kann der Decoder das Bild nicht korrekt identifizieren und anzeigen. Der Hilfsblock ist optional und einige Softwareprogramme tragen den Hilfsblock möglicherweise nach der Bildverarbeitung. Jeder Block besteht aus vier Teilen: 4 Byte beschreiben, wie lang der Inhalt dieses Blocks ist, 4 Byte beschreiben den Typ dieses Blocks und n Byte beschreiben den Inhalt des Blocks (n ist die Größe des vorherigen 4-Byte-Werts, Das heißt, die maximale Länge eines Blocks beträgt 28 * 4. Die 4-Byte-CRC-Prüfung überprüft die Daten des Blocks und markiert das Ende eines Blocks. Darunter ist der Wert von 4 Bytes des Blocktyps 4 ACSII-Codes. Der erste Buchstabe in Großbuchstaben bedeutet, dass es sich um einen Schlüsselblock handelt, und in Kleinbuchstaben bedeutet, dass es sich um einen Hilfsblock handelt Großbuchstaben bedeuten, dass es öffentlich ist , und in Kleinbuchstaben bedeutet, dass es öffentlich ist ; der dritte Buchstabe muss für die spätere Erweiterung von PNG verwendet werden; Wird es nicht erkannt, bedeutet Großbuchstabe, dass es nur dann sicher kopiert werden kann, wenn der Schlüsselblock nicht geändert wurde, und Kleinbuchstabe bedeutet, dass beides sicher kopiert werden kann. PNG bietet offiziell viele definierte Blocktypen. Hier müssen Sie nur die wichtigsten Blocktypen kennen, nämlich IHDR, PLTE, IDAT und IEND. IHDRPNG-Anforderung
Der erste Block muss IHDR sein. Der Blockinhalt von IHDR ist auf 13 Bytes festgelegt und enthält die folgenden Informationen des Bildes: Breite (4 Byte) und Höhe (4 Byte)
Bittiefe (1 Byte, Werte sind 1, 2, 4, 8 oder 16) & Farbtyp Farbtyp (1 Byte, Wert ist 0, 2, 3, 4 oder 6) Komprimierungsmethode Komprimierungsmethode (1 Byte, Wert ist 0) & Filtermethode Filtermethode (1 Byte, Wert ist 0) 0)
Interlace-Methode (1 Byte, Wert ist 0 oder 1)
Breite und Höhe sind leicht zu verstehen, die übrigen scheinen unbekannt, ich werde sie als nächstes erklären.
Bevor wir die Bittiefe erklären, schauen wir uns zunächst den Farbtyp an:
0 bedeutet, dass es nur einen Kanal gibt. Die Werte der drei Farbkanäle sind gleich, sodass nicht mehr als zwei Kanäle zur Darstellung erforderlich sind.
- 2 stellt die echte Farbe (RGB) dar, die drei Kanäle hat, nämlich R (Rot), G (Grün), B (Blau).
3 stellt den Farbindex dar (indiziert). Es gibt auch nur einen Kanal, der den Indexwert der Farbe darstellt. Dieser Typ ist häufig mit einer Reihe von Farblisten ausgestattet, und die spezifische Farbe wird basierend auf dem Indexwert und der Farblistenabfrage ermittelt.
4 steht für Graustufen und Alpha. Zusätzlich zum Graustufenkanal gibt es einen zusätzlichen Alphakanal zur Steuerung der Transparenz.
6 bedeutet echte Farbe und Alpha mit vier Kanälen.
Der Grund, warum wir vom Kanal sprechen, ist, dass er hier mit der Bittiefe zusammenhängt. Der Bittiefenwert definiert die Anzahl der von jedem Kanal belegten Bits. Durch die Kombination von Bittiefe und Farbtyp können Sie den Farbformattyp des Bildes und die von jedem Pixel belegte Speichergröße ermitteln. Die von PNG offiziell unterstützten Kombinationen sind wie folgt:
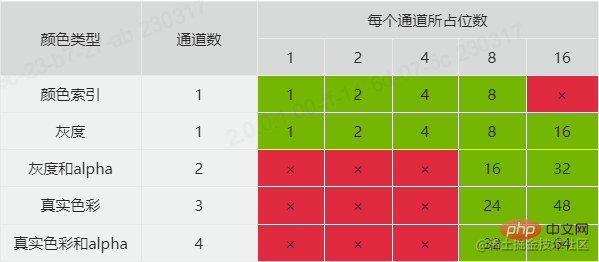
Filterung und Komprimierung sind darauf zurückzuführen, dass PNG nicht die Originaldaten des Bildes, sondern die verarbeiteten Daten speichert, weshalb PNG-Bilder weniger Speicher belegen. PNG verwendet zwei Schritte zum Komprimieren und Konvertieren von Bilddaten.
Der erste Schritt ist das Filtern. Der Zweck der Filterung besteht darin, den Originalbilddaten nach Durchlaufen der Regeln eine höhere Komprimierungsrate zu ermöglichen. Wenn es beispielsweise ein Farbverlaufsbild gibt, sind die Farben von links nach rechts [#000000, #000001, #000002, ..., #ffffff], dann können wir uns auf eine Regel einigen, dass die Pixel auf der rechten Seite sind immer und vergleiche es mit dem vorherigen linken Pixel, dann werden die verarbeiteten Daten zu [1, 1, 1, ..., 1]. Ermöglicht dies eine bessere Komprimierung? PNG verfügt derzeit nur über eine Filtermethode, die auf benachbarten Pixeln als vorhergesagten Werten basiert und die vorhergesagten Werte vom aktuellen Pixel subtrahiert. Es gibt fünf Arten der Filterung. (Derzeit weiß ich nicht, wo dieser Werttyp gespeichert ist. Er befindet sich möglicherweise in IDAT. Wenn Sie ihn finden, löschen Sie das in dieser Klammer. Es wurde festgestellt, dass dieser Werttyp wird in den IDAT-Daten gespeichert. ) Wie in der Tabelle dargestellt:
| Typbyte | Filtername | Vorhergesagter Wert |
|---|---|---|
| 0 | Keine | Keine Verarbeitung |
| 1 | Sub | Benachbarte Pixel auf der linken Seite |
| 2 | Oben | Benachbarte Pixel oben |
| 3 | Durchschnittlich | Math.floor((benachbarte Pixel auf der linken Seite benachbarte Pixel oben) / 2) |
| 4 | Paeth | Nimm den Wert, der am nächsten kommt |
第二步,压缩。PNG也只有一种压缩算法,使用的是DEFLATE算法。这里不细说,具体看下面的章节。
交错方式,有两种值。0表示不处理,1表示使用Adam7 算法进行处理。我没有去详细了解该算法,简单来说,当值为0时,图片需要所有数据都加载完毕时,图片才会显示。而值为1时,Adam7会把图片划分多个区域,每个区域逐级加载,显示效果会有所优化,但通常会降低压缩效率。加载过程可以看下面这张gif图。

PLTE
PLTE的块内容为一组颜色列表,当颜色类型为颜色索引时需要配置。值得注意的是,颜色列表中的颜色一定是每个通道8bit,每个像素24bit的真实色彩列表。列表的长度,可以比位深约定的少,但不能多。比如位深是2,那么22,最多4种颜色,列表长度可以为3,但不能为5。
IDAT
IDAT的块内容是图片原始数据经过PNG压缩转换后的数据,它可能有多个重复的块,但必须是连续的,并且只有当上一个块填充满时,才会有下一个块。
IEND
IEND的块内容为0 byte,它表示图片的结束。
阅读到这里,我们把上面的接口改造一下,解析这串buffer。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> return result;<br/>}<br/>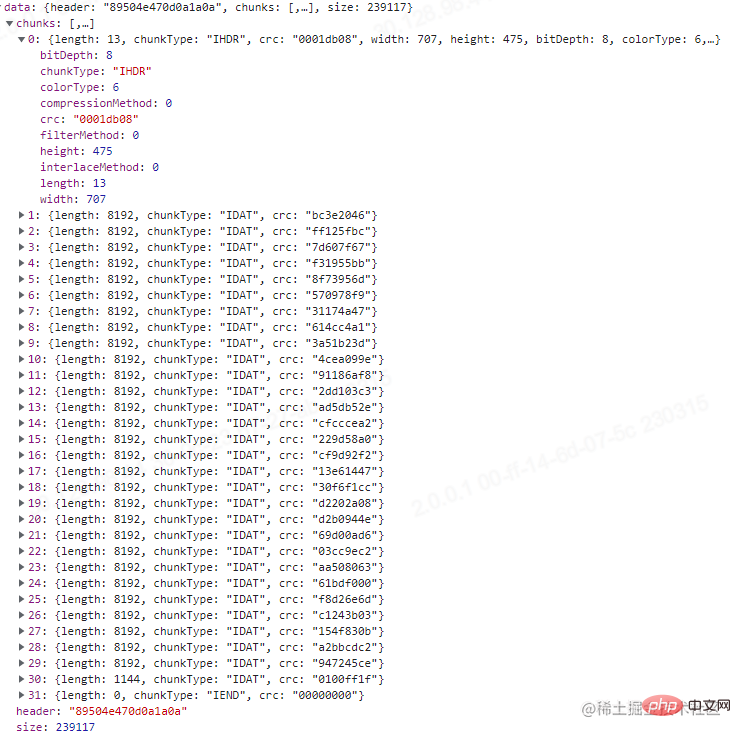
这里我测试用的图没有PLTE,刚好我去TinyPNG压缩我那张测试图之后进行上传,发现有PLTE块,可以看一下,结果如下图。
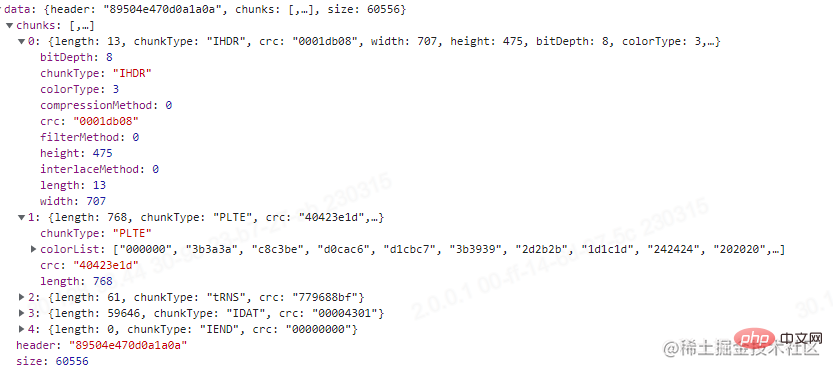
通过比对这两张图,压缩图片的方式我们也能窥探一二。
PNG的压缩
前面说过,PNG使用的是一种叫DEFLATE的无损压缩算法,它是Huffman Coding跟LZ77的结合。除了PNG,我们经常使用的压缩文件,.zip,.gzip也是使用的这种算法(7zip算法有更高的压缩比,也可以了解下)。要了解DEFLATE,我们首先要了解Huffman Coding和LZ77。
Huffman Coding
哈夫曼编码忘记在大学的哪门课接触过了,它是一种根据字符出现频率,用最少的字符替换出现频率最高的字符,最终降低平均字符长度的算法。
举个例子,有字符串"ABCBCABABADA",如果按照正常空间存储,所占内存大小为12 * 8bit = 96bit,现对它进行哈夫曼编码。
1.统计每个字符出现的频率,得到A 5次 B 4次 C 2次 D 1次
2.对字符按照频率从小到大排序,将得到一个队列D1,C2,B4,A5
3.按顺序构造哈夫曼树,先构造一个空节点,最小频率的字符分给该节点的左侧,倒数第二频率的字符分给右侧,然后将频率相加的值赋值给该节点。接着用赋值后节点的值和倒数第三频率的字符进行比较,较小的值总是分配在左侧,较大的值总是分配在右侧,依次类推,直到队列结束,最后把最大频率和前面的所有值相加赋值给根节点,得到一棵完整的哈夫曼树。
4.对每条路径进行赋值,左侧路径赋值为0,右侧路径赋值为1。从根节点到叶子节点,进行遍历,遍历的结果就是该字符编码后的二进制表示,得到:A(0)B(11)C(101)D(100)。
完整的哈夫曼树如下(忽略箭头,没找到连线- -!):
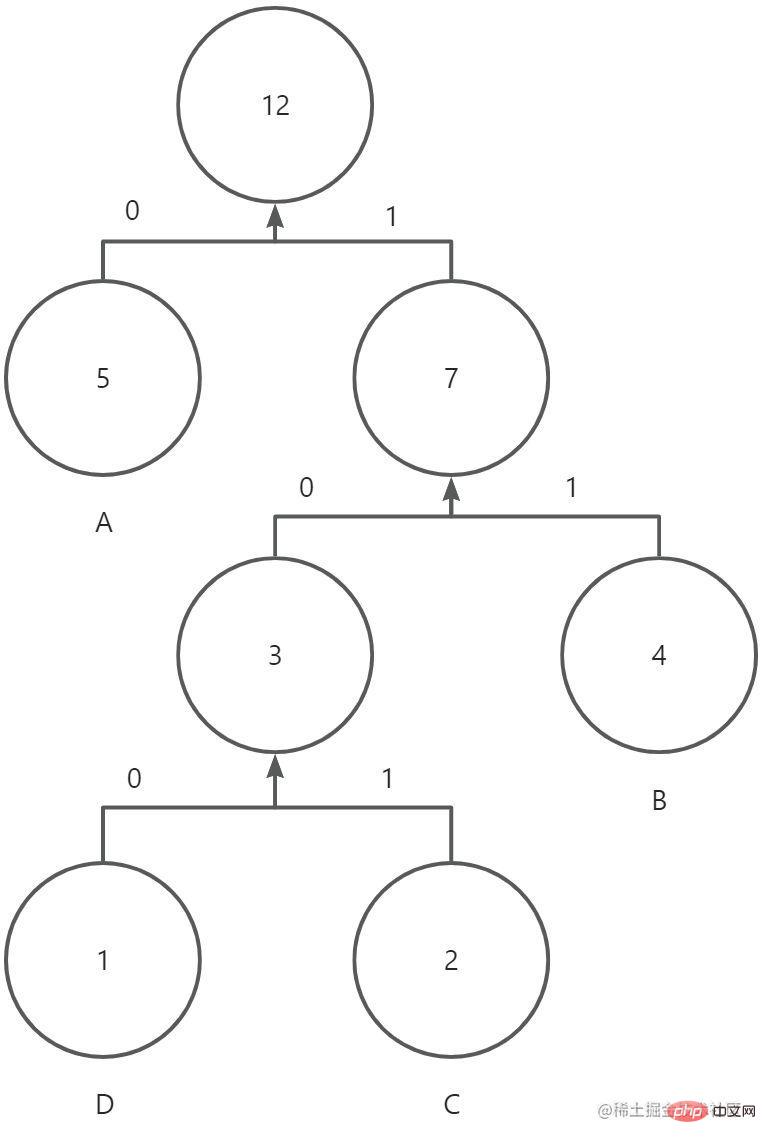
压缩后的字符串,所占内存大小为5 * 1bit + 4 * 2bit + 2 * 3bit + 1 * 3bit = 22bit。当然在实际传输过程中,还需要把编码表的信息(原始字符和出现频率)带上。因此最终占比大小为 4 * 8bit + 4 * 3bit(频率最大值为5,3bit可以表示)+ 22bit = 66bit(理想状态),小于原有的96bit。
LZ77
LZ77算法还是第一次知道,查了一下是一种基于字典和滑动窗的无所压缩算法。(题外话:因为Lempel和Ziv在1977年提出的算法,所以叫LZ77,哈哈哈?)
我们还是以上面这个字符串"ABCBCABABADA"为例,现假设有一个4 byte的动态窗口和一个2byte的预读缓冲区,然后对它进行LZ77算法压缩,过程顺序从上往下,示意图如下:

总结下来,就是预读缓冲区在动态窗口中找到最长相同项,然后用长度较短的标记来替代这个相同项,从而实现压缩。从上图也可以看出,压缩比跟动态窗口的大小,预读缓冲区的大小和被压缩数据的重复度有关。
DEFLATE
DEFLATE【RFC 1951】是先使用LZ77编码,对编码后的结果在进行哈夫曼编码。我们这里不去讨论具体的实现方法,直接使用其推荐库Zlib,刚好Node.js内置了对Zlib的支持。接下来我们继续改造上面那个接口,如下:
import * as zlib from 'zlib';<br/><br/>@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> // 因为可能有多个IDAT的块 需要个数组缓存最后拼接起来<br/> const fileChunkDatas = [];<br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> case 'IDAT':<br/> fileChunkDatas.push(buffer.subarray(pointer + 8, pointer + 8 + length));<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> const originFileData = zlib.unzipSync(Buffer.concat(fileChunkDatas));<br/><br/> // 这里原图片数据太长了 我就只打印了长度<br/> return {<br/> ...result,<br/> originFileData: originFileData.length,<br/> };<br/>}<br/>
最终打印的结果,我们需要注意红框的那几个部分。可以看到上图,位深和颜色类型决定了每个像素由4 byte组成,然后由于过滤方式的存在,会在每行的第一个字节进行标记。因此该图的原始数据所占大小为:707 * 475 * 4 byte + 475 * 1 byte = 1343775 byte。正好是我们打印的结果。
我们也可以试试之前TinyPNG压缩后的图,如下:
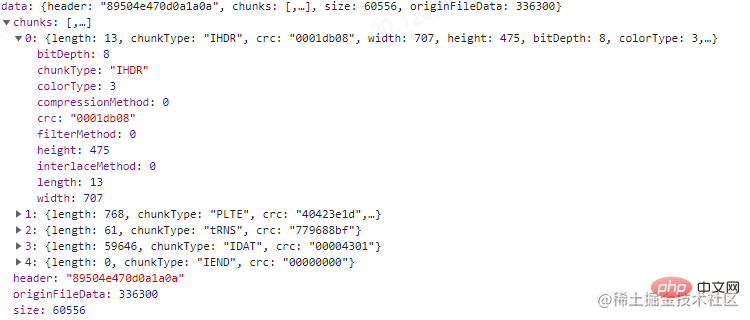
可以看到位深为8,索引颜色类型的图每像素占1 byte。计算得到:707 * 475 * 1 byte + 475 * 1 byte = 336300 byte。结果也正确。
总结
现在再看如何进行图片压缩,你可能很容易得到下面几个结论:
1.减少不必要的辅助块信息,因为辅助块对PNG图片而言并不是必须的。
2.减少IDAT的块数,因为每多一个IDAT的块,就多余了12 byte。
3.降低每个像素所占的内存大小,比如当前是4通道8位深的图片,可以统计整个图片色域,得到色阶表,设置索引颜色类型,降低通道从而降低每个像素的内存大小。
4.等等....
至于JPEG,WEBP等等格式图片,有机会再看。溜了溜了~(还是使用现成的库处理压缩吧)。
好久没写文章,写完才发现语雀不能免费共享,发在这里吧。
更多node相关知识,请访问:nodejs 教程!
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Node zur Bildkomprimierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie konfiguriere ich die Node-Umgebung in IDEA? Kurze Analyse der Methoden
- Was ist EventLoop? So testen Sie die Leistung eines Knotens oder einer Seite
- Was ist Cache? Wie implementiert man es mit Node?
- Wie aktualisiere ich die Knotenversion? Detailliertes Tutorial-Sharing
- Eine kurze Analyse, wie das http-Modul in Node Datei-Uploads verarbeitet
- Vertiefendes Verständnis des Node-Event-Loop-Mechanismus (EventLoop).