
Heim >Datenbank >MySQL-Tutorial >Detailliertes Verständnis der Funktionsweise des MySQL-Indexoptimierers
Detailliertes Verständnis der Funktionsweise des MySQL-Indexoptimierers

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-11-09 14:05:241544Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über MySQL und stellt hauptsächlich relevante Inhalte zum Funktionsprinzip des Indexoptimierers vor, einschließlich der Zusammensetzung von MySQL Server, dem Prinzip der Indexauswahl durch den MySQL-Optimierer und der SQL-Kostenanalyse Fassen Sie den gesamten Abfrageprozess durch eine ausgewählte Abfrage zusammen. Ich hoffe, dass er für alle hilfreich ist.

Empfohlenes Lernen: MySQL-Video-Tutorial
1. Wie der MySQL-Optimierer Indizes auswählt
Schauen wir uns diese Tabelle an. Das Feld SUB_ODR_ID erstellt zwei verwandte Indizes. Was wir zuvor gesagt haben Wir haben gelernt, dass wir einen PRIMÄRSCHLÜSSEL (ID)自增主键索引,(LOG_ID, SUB_ODR_ID) erstellen und ihn als gemeinsamen Index und eindeutigen Index festlegen und zwei Indizes zu zwei Zeitpunkten festlegen: CREATE_TIME und UPDATE_TIME.
CREATE TABLE `***` ( `ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `LOG_ID` varchar(32) NOT NULL COMMENT '交易流水号', `ODR_ID` varchar(32) NOT NULL COMMENT '父单号', `SUB_ODR_ID` varchar(32) NOT NULL COMMENT '子单号', `CREATE_TIME` datetime(0) NOT NULL COMMENT '创建时间', `CREATE_BY` varchar(32) NOT NULL COMMENT ' 创建人', `UPDATE_TIME` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间', `UPDATE_BY` varchar(32) NOT NULL COMMENT '更新人', PRIMARY KEY (`ID`) USING BTREE, UNIQUE INDEX `UNQ_LOG_SUBODR_ID`(`LOG_ID`, `SUB_ODR_ID`) USING BTREE, INDEX `IDX_ODR_ID`(`ODR_ID`) USING BTREE, INDEX `IDX_SUB_ID`(`SUB_ODR_ID`) USING BTREE, INDEX `IDX_CREATE_TIME`(`CREATE_TIME`) USING BTREE, INDEX `IDX_UPDATE_TIME`(`UPDATE_TIME`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 SET = utf8 COLLATE = utf8_general_ci COMMENT = '分摊业务明细表' ROW_FORMAT = Dynamic;
Im Abfragefeld SUB_ODR_ID können theoretisch drei verwandte Indizes verwendet werden: UNQ_LOG_SUBODR_ID, IDX_SUB_ID. Wie wählt der MySQL-Optimierer aus diesen drei Indizes aus?
In einer relationalen Datenbank ist der B+-Baum lediglich eine Datenstruktur, die zur Speicherung verwendet wird.
Wie man es verwendet, hängt vom Optimierer der Datenbank ab. Der Optimierer bestimmt die Auswahl eines bestimmten Index, den sogenannten Ausführungsplan. Die Auswahl des Optimierers basiert auf den Kosten. Je niedriger die Kosten, desto höher der Präferenzindex.
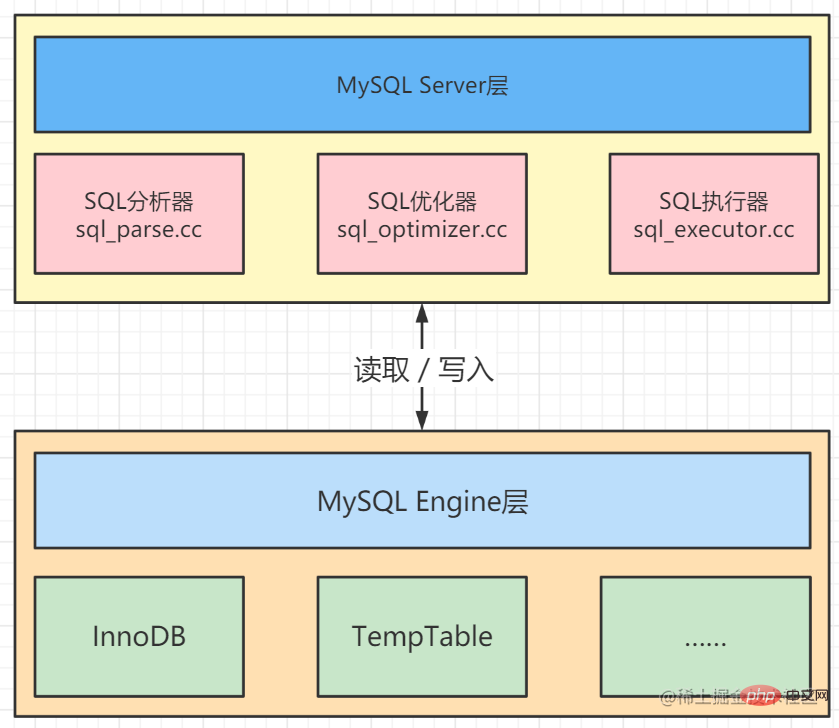
1. Zusammensetzung der MySQL-Datenbank
Die MySQL-Datenbank besteht aus der Serverschicht (Server) und der Engineschicht (Engine).
Die Serve-Schicht verfügt über einen SQL-Analysator, einen SQL-Optimierer und einen SQL-Executor, die für den spezifischen Ausführungsprozess von SQL-Anweisungen verantwortlich sind.
Die Engine-Schicht ist für die Speicherung spezifischer Daten verantwortlich, z. B. der am häufigsten verwendeten InnoDB-Speicher-Engine und der TempTable-Engine, die zum Speichern temporärer Ergebnissätze im Speicher verwendet wird.
Der SQL-Optimierer analysiert alle möglichen Ausführungspläne und wählt die Ausführung mit den niedrigsten Kosten aus. Dieser Optimierer wird CBO (kostenbasierter Optimierer) genannt.
2. Berechnung der MySQL-Datenbankkosten
In MySQL sind die Berechnungskosten eines SQL leicht zu verstehen, nämlich den Zugriff auf die Datenbank (Datenbankseite, Festplatte) + die Verarbeitung von Daten.
CPU-Kosten, die den Rechenaufwand darstellen, z. B. Vergleich von Indexschlüsselwerten, Vergleich von Datensatzwerten und Sortieren von Ergebnismengen. Diese Vorgänge werden auf der Serverebene ausgeführt. Die IO-Kosten stellen die Kosten für E/A auf Engine-Ebene dar. MySQL 8.0 kann die Kosten für das Lesen von Speicher-E/A und Festplatten-E/A separat berechnen, indem es unterscheidet, ob sich die Tabellendaten im Speicher befinden.
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
Der MySQL-Optimierer geht davon aus, dass, wenn ein Teil von SQL eine festplattenbasierte temporäre Tabelle erstellen muss, die Kosten zu diesem Zeitpunkt am größten sind und 20-mal so hoch sind wie die einer speicherbasierten temporären Tabelle. Die Kosten für den Vergleich von Indexschlüsselwerten und Datensätzen sind sehr gering. Wenn jedoch viele Datensätze verglichen werden müssen, können die Kosten sehr hoch sein.
Der MySQL-Optimierer geht davon aus, dass die Kosten für das Lesen von der Festplatte viermal so hoch sind wie die Speicherkosten (die Kosten sind nicht statisch und variieren je nach Hardware). 2. Kosten für MySQL-Abfragen
read_cost bedeutet von Die Kosten für das Lesen durch die InnoDB-Speicher-Engine; eval_cost stellt die CPU-Kosten der Serverschicht dar;
EXPLAIN FORMAT=json
select * from test.fork_business_detail f where f.sub_odr_id = ''
3. SELECT-Ausführungsprozess
Wie kann die MySQL-Abfrageleistung verbessert werden? Zunächst müssen Sie den gesamten Prozess der SQL-Verarbeitung durch den Abfrageoptimierer verstehen. Als Beispiel wird der Ausführungsprozess von SELECT SQL verwendet, wie in der folgenden Abbildung dargestellt:
Der Client sendet eine SELECT-Abfrage an den Server. Der Server überprüft zunächst den Abfragecache. Wenn der Cache erreicht wird, werden die im Cache gespeicherten Ergebnisse sofort zurückgegeben. Andernfalls gelangen Sie zur nächsten Stufe.
Der Server führt die SQL-Analyse und -Vorverarbeitung durch und der Abfrageoptimierer generiert den entsprechenden Ausführungsplan Das Ergebnis wird an den Client zurückgegeben und auch im Abfragecache abgelegt.
Empfohlenes Lernen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonDetailliertes Verständnis der Funktionsweise des MySQL-Indexoptimierers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Grundlegende MySQL-Fallfreigabe für mehrere Tabellenabfragen
- Lassen Sie uns über die vier Möglichkeiten sprechen, das Passwort in MySQL zu ändern (siehe es für Anfänger).
- Sprechen Sie kurz über die Join-Abfrage in MySQL
- Keine Panik, wenn etwas passiert, zeichnen Sie es zuerst auf: MySQL in langsamer Abfrageoptimierung
- Wie man MySQL Distinct verwendet