
Heim >Datenbank >MySQL-Tutorial >Sprechen Sie kurz über die Join-Abfrage in MySQL
Sprechen Sie kurz über die Join-Abfrage in MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-11-03 16:49:541546Durchsuche
Dieser Artikel bringt Ihnen relevantes Wissen über MySQL, das hauptsächlich verwandte Themen zur Join-Abfrage vorstellt. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: MySQL-Video-Tutorial
Der Einfluss des Index auf die Join-Abfrage
Datenvorbereitung
Angenommen, es gibt zwei Tabellen t1 und t2, beide Tabellen haben eine Primärschlüssel-Index-ID und ein Indexfeld Es gibt keine Indizes in den Feldern a und b, und dann fügen Sie zum Experimentieren 100 Datenzeilen in die Tabelle t1 und 1000 Datenzeilen in die Tabelle t2 ein
CREATE TABLE `t2` ( `id` int NOT NULL, `a` int DEFAULT NULL, `b` int DEFAULT NULL, PRIMARY KEY (`id`), KEY `t2_a_index` (`a`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; CREATE PROCEDURE **idata**() BEGIN DECLARE i INT; SET i = 1; WHILE (i <h3 data-id="heading-3"><strong>Es gibt einen Indexabfrageprozess</strong></h3><p>Wir verwenden die Abfrage SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1. a=t2.a); Da der Join-Abfrage-MYSQL-Optimierer möglicherweise nicht gemäß unseren Wünschen ausgeführt werden kann, entscheiden wir uns für die Analyse stattdessen für die Verwendung von STRAIGHT_JOIN, um die Beobachtung intuitiver zu gestalten</p> <p><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/64b9ac3a02f2e5095eba59bdfbcd23d6-2.png" class="lazy" alt="图 1" loading="lazy"> Abbildung 1</p><p>Sie können sehen, dass wir T1 als treibende Tabelle und t2 als treibende Tabelle verwenden. Die Erklärung in der obigen Abbildung zeigt, dass diese Abfrage den Feldindex der t2-Tabelle verwendet, also die Ausführung Der Prozess dieser Anweisung sollte wie folgt ablaufen: </p>
Von t1 Lesen Sie eine Zeile mit Daten r aus der Tabelle.
Rufen Sie Feld a aus Daten r in Tabelle t2 zum Abgleichen ab t2 und bilden Sie eine Zeile mit r als Teil der Ergebnismenge.
Wiederholen Sie die Schritte 1 bis 3, bis Tabelle t1 die Daten in einer Schleife verarbeitet. Dieser Vorgang wird als Index Nested-Loop Join bezeichnet. In diesem Prozess wird die Treibertabelle t1 führt einen vollständigen Tabellenscan durch, da wir 100 Zeilen in die T1-Tabellendaten eingefügt haben, sodass die Anzahl der gescannten Zeilen dieses Mal 100 beträgt. Bei der Durchführung einer Join-Abfrage muss jede Zeile der T1-Tabelle in der T2-Tabelle durchsucht werden Die Suche wird verwendet, da die von uns erstellten Daten eine Eins-zu-Eins-Entsprechung haben, sodass bei jeder Suche nur eine Zeile gescannt wird, d. h. die T2-Tabelle scannt insgesamt 100 Zeilen und die Gesamtzahl der gescannten Zeilen Der Abfrageprozess umfasst 100+100=200 Zeilen.
- Indexloser Abfrageprozess
SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a = t2.b);
Natürlich basiert dieses Abfrageergebnis immer noch auf der Tatsache, dass die beiden von uns erstellten Tabellen klein sind. Wenn es sich um eine Tabelle in der Größenordnung von 100.000 Zeilen handelt, müssen 10 Milliarden Zeilen gescannt werden, was schrecklich ist!
2. Verstehen Sie 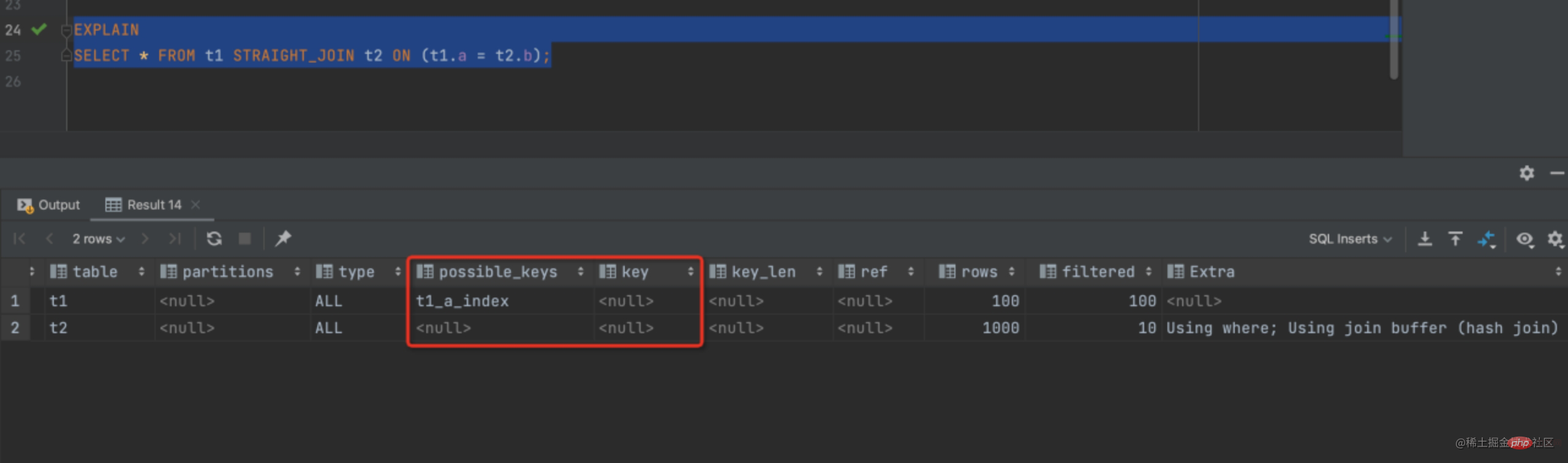 Nested-Loop-Join blockieren
Nested-Loop-Join blockieren
Nested-Loop-Join blockierenAbfrageprozessEs gibt also keinen Index für die gesteuerte Tabelle. Wie ist das alles passiert?
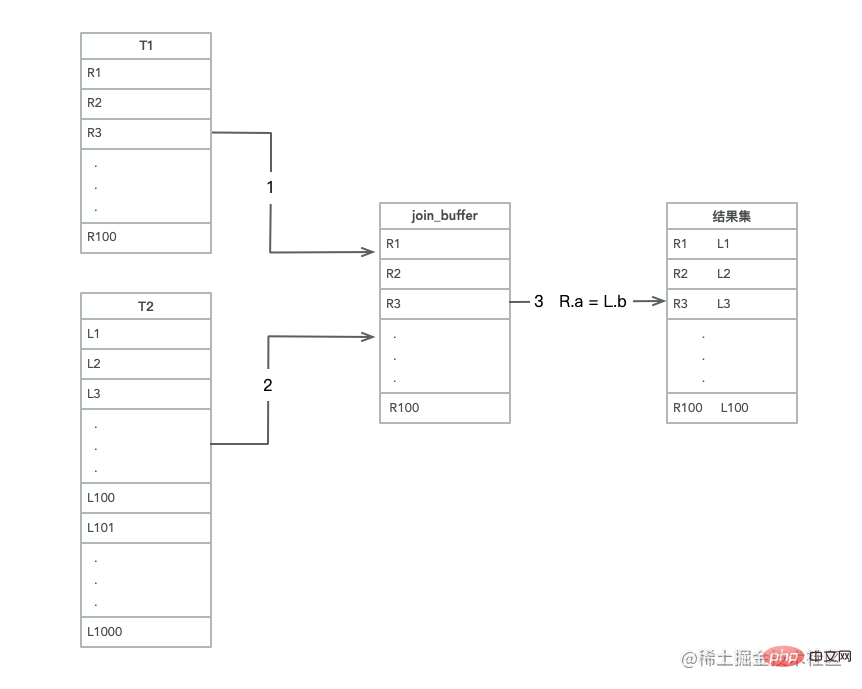
Wenn in der gesteuerten Tabelle kein Index verfügbar ist, ist der Algorithmusablauf wie folgt: Lesen Sie die Daten von t1 in den Thread-Speicher „join_buffer“. Denn was wir oben geschrieben haben, ist „select * from“. entspricht dem Einfügen der gesamten t1-Tabelle in den Speicher.
Der Vorgang des Scannens von t2 besteht darin, jede Zeile von t2 herauszunehmen und mit den Daten im Join_Buffer zu vergleichen als Teil der Ergebnismenge zurückgegeben werden.
- Diesen Hinweis können wir also anhand des Extra-Teils von Abbildung 2 mithilfe des Join-Puffers finden. Während des gesamten Prozesses wurde ein vollständiger Tabellenscan für die Tabellen t1 und t2 durchgeführt, sodass die Anzahl der gescannten Zeilen 100 betrug +1000 = 1100 Zeilen, da join_buffer in einem ungeordneten Array organisiert ist, sodass für jede Zeile in Tabelle t2 100 Urteile getroffen werden müssen. Die Gesamtzahl der Urteile, die im Speicher getroffen werden müssen, beträgt 100 * 1000 = 100.000 Mal Da diese 100.000 Mal im Speicher auftreten, ist die Geschwindigkeit viel höher und die Leistung besser. Join_buffer
 Wie Sie oben wissen, liest MySQL die Daten zur Schleifenbeurteilung in den Speicher, sodass dieser Speicher definitiv nicht unbegrenzt für Sie verfügbar ist. Zu diesem Zeitpunkt müssen wir a verwenden Parameter join_buffer_size, die Standardgröße dieses Werts beträgt 256 KB, wie unten gezeigt:
Wie Sie oben wissen, liest MySQL die Daten zur Schleifenbeurteilung in den Speicher, sodass dieser Speicher definitiv nicht unbegrenzt für Sie verfügbar ist. Zu diesem Zeitpunkt müssen wir a verwenden Parameter join_buffer_size, die Standardgröße dieses Werts beträgt 256 KB, wie unten gezeigt:
SHOW VARIABLES LIKE '%join_buffer_size%';
Abbildung 4
Wenn die abgefragten Daten zu groß sind, um auf einmal geladen zu werden, und nur ein Teil der Daten (80 Elemente) geladen werden kann, dann sieht der Abfragevorgang so aus扫描表 t1,顺序读取数据行放入 join_buffer 中,直至加载完第 80 行满了
扫描表 t2,把 t2 表中的每一行取出来跟 join_buffer 中的数据做对比,将满足条件的数据作为结果集的一部分返回
清空 join_buffer
继续扫描表 t1,顺序读取剩余的数据行放入 join_buffer 中,执行步骤 2
这个流程体现了算法名称中 Block 的由来,分块 join,可以看出虽然查询过程中 t1 被分成了两次放入 join_buffer 中,导致 t2 表被扫描了 2次,但是判断等值条件的次数还是不变的,依然是(80+20)*1000=10 万次。
所以这就是有时候 join 查询很慢,有些大佬会让你把 join_buffer_size 调大的原因。
如何正确的写出 join 查询
驱动表的选择
有索引的情况下
在这个 join 语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。
假设被驱动表的行数是 M,每次在被驱动表查询一行数据,先要走索引 a,再搜索主键索引。每次搜索一棵树近似复杂度是以 2为底的 M的对数,记为 log2M,所以在被驱动表上查询一行数据的时间复杂度是 2*log2M。
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上 匹配一次。因此整个执行过程,近似复杂度是 N + N2log2M。显然,N 对扫描行数的影响更大,因此应该让小表来做驱动表。
那没有索引的情况
上述我知道了,因为 join_buffer 因为存在限制,所以查询的过程可能存在多次加载 join_buffer,但是判断的次数都是 10 万次,这种情况下应该怎么选择?
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。这里的 K不是常数,N 越大 K就越大,因此把 K 表示为λ*N,显然λ的取值范围 是 (0,1)。
扫描的行数就变成了 N+λNM,显然内存的判断次数是不受哪个表作为驱动表而影响的,而考虑到扫描行数,在 M和 N大小确定的情况下,N 小一些,整个算是的结果会更小,所以应该让小表作为驱动表
总结:真相大白了,不管是有索引还是无索引参与 join 查询的情况下都应该是使用小表作为驱动表。
什么是小表
还是以上面表 t1 和表 t2 为例子:
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.b = t2.b WHERE t2.id <p>上面这两条 SQL 我们加上了条件 t2.id </p><p>再看另一组:</p><pre class="brush:php;toolbar:false">SELECT t1.b,t2.* FROM t1 STRAIGHT_JOIN t2 ON t1.b = t2.b WHERE t2.id <p>这个例子里,表 t1 和 t2 都是只有 100 行参加 join。 但是,这两条语句每次查询放入 join_buffer 中的数据是不一样的: 表 t1 只查字段 b,因此如果把 t1 放到 join_buffer 中,只需要放入字段 b 的值; 表 t2 需要查所有的字段,因此如果把表 t2 放到 join_buffer 中的话,就需要放入三个字 段 id、a 和 b。</p><p>这里,我们应该选择表 t1 作为驱动表。也就是说在这个例子里,”只需要一列参与 join 的 表 t1“是那个相对小的表。</p><p>结论:</p><p>在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过 滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”, 应该作为驱动表。</p><p>推荐学习:<a href="https://www.php.cn/course/list/51.html" target="_blank" textvalue="mysql视频教程">mysql视频教程</a></p>
Das obige ist der detaillierte Inhalt vonSprechen Sie kurz über die Join-Abfrage in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Zusammenfassung und Austausch von Ideen zur Optimierung langsamer MySQL-Abfragen
- Kennen Sie die Auswirkungen des MySQL-innodb-Selbstinkrementierungs-ID-Fehlers?
- Dieser Artikel vermittelt Ihnen einen schnellen Überblick über langsame Abfragen in MySQL
- Was soll ich tun, wenn Docker keine Verbindung zu MySQL herstellen kann?
- Dieser Artikel hilft Ihnen, den MySQL-Ausführungsplan schnell zu verstehen