
Detaillierte Erläuterung des Aufbaus und der Verwendung des Redis-Sharding-Clusters

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-07-21 17:46:592688Durchsuche

Empfohlenes Lernen: Redis-Video-Tutorial
Vorwort
Man kann sagen, dass Redis in der tatsächlichen Projektentwicklung sehr häufig verwendet wird. Wir haben über mehrere Clusterlösungen gesprochen, die häufig von Redis verwendet werden. Verschiedene Cluster entsprechen unterschiedlichen Szenarien, und die Vor- und Nachteile verschiedener Cluster werden ausführlich erläutert. In diesem Artikel wird der Redis-Sharded-Cluster als Einstiegspunkt verwendet, beginnend mit der Konstruktion des Redis-Sharded-Clusters, und die technischen Punkte werden ausführlich erläutert im Zusammenhang mit dem Redis-Sharding-Cluster;
- Einzelner Schreibfehler (hoher gleichzeitiger Schreibaufwand);
- Automatische Cluster-Skalierung; offline und übertragen;
- Erstellen Sie ein Cluster-Architekturdiagramm
- Vorbereitung
2. Laden Sie das Redis-Installationspaket herunter.
 Erstellen Sie 6 Verzeichnisdateien, um die Daten zu speichern von jedem Redis-Beispiel
Erstellen Sie 6 Verzeichnisdateien, um die Daten zu speichern von jedem Redis-Beispiel
mkdir 7001 7002 7003 8001 8002 8003
2. Erstellen Sie eine redis.conf-Datei mit dem folgenden Inhalt
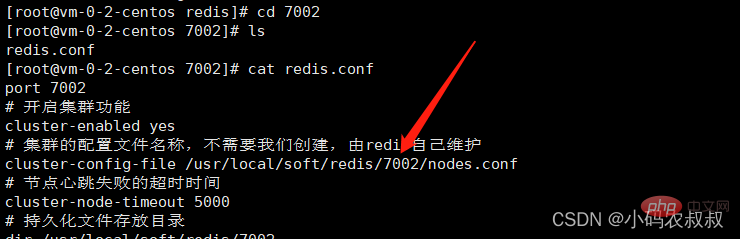
port 6379 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /usr/local/soft/redis/6379/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /usr/local/soft/redis/6379 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 本机公网IP # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /usr/local/soft/redis/6379/run.log
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
 Nachdem die Ausführung abgeschlossen ist, können Sie sehen, dass 6 Redis-Instanzen geöffnet wurden
Nachdem die Ausführung abgeschlossen ist, können Sie sehen, dass 6 Redis-Instanzen geöffnet wurden
Cluster erstellen
Durch die obigen Schritte wurden 6 Redis-Instanzen geöffnet, aber kein Cluster Als nächstes müssen Sie die entsprechenden Schritte ausführen. Befehl, um sie zu einem Cluster zu bilden. 
1 Verwenden Sie den folgenden Befehl, um den Cluster zu erstellen (Befehle nach 5.0).
 redis-cli --cluster oder ./redis-trib .rb: stellt den Cluster-Operationsbefehl dar;
redis-cli --cluster oder ./redis-trib .rb: stellt den Cluster-Operationsbefehl dar;
create: stellt das Erstellen eines Clusters dar;
–replicas 1 oder –cluster-replicas 1: gibt die Anzahl der Replikate an jedes Masters im Cluster auf 1 und die Gesamtzahl der Knoten ÷ (Replikate + 1). Sie erhalten die Anzahl der Master. Daher sind die ersten n Knoten in der Knotenliste Master und die anderen Knoten sind Slave-Knoten, die zufällig verschiedenen Mastern zugewiesen werden.
 Sie können Cluster-Befehle auch über den Hilfebefehl redis-cli --cluster anzeigen Wenn Sie den Befehl ausführen, werden Sie von der Konsole gefragt, welches Beispiel als Master und welches als Slave verwendet wird. Nachdem Sie weiterhin „Ja“ eingegeben haben, wird ein Cluster gemäß der oben genannten Strategie erstellt Ich kann wahrscheinlich die folgenden Informationen aus dem Ausgabeprotokoll entnehmen:
Sie können Cluster-Befehle auch über den Hilfebefehl redis-cli --cluster anzeigen Wenn Sie den Befehl ausführen, werden Sie von der Konsole gefragt, welches Beispiel als Master und welches als Slave verwendet wird. Nachdem Sie weiterhin „Ja“ eingegeben haben, wird ein Cluster gemäß der oben genannten Strategie erstellt Ich kann wahrscheinlich die folgenden Informationen aus dem Ausgabeprotokoll entnehmen:
Der Master-Knoten hat die Portnummern 7001, 7002 und 7003 nacheinander;
Der Slave-Knoten hat nacheinander die Portnummern 8001, 8002 und 8003; Der Master Der Knoten hat nacheinander die Portnummern 7001, 7002 und 7003. Jedem Knoten ist eine bestimmte Anzahl von Steckplätzen zugewiesen: [0-5460], [5461-10922], [10923-16383], also insgesamt 16384 Slots sind zugewiesen;
2. Überprüfen Sie den Clusterstatus
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf通过这个命令,可以清楚的看到集群中各个实例节点的主从状态,实例ID(唯一身份标识),槽位区间等信息
Redis散列插槽说明
其实对redis分片集群稍有了解的同学应该知道,redis分片集群在逻辑上将集群中的所有节点构成了一块完整的内存空间,数据写入进来后,具体存放到哪个节点呢?所以集群引入了一个逻辑尚的插槽概念,即将集群划分为16384个槽位,集群中的每个节点占据一部分槽位数(这个日志中可以看出来);
那么当某个具体的key写入的时候,集群将会通过一定的算法,将要写入的数据路由到指定的插槽上去;
这里有个点需要注意,数据key不是与节点绑定,而是与插槽绑定。
redis集群会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分;
- key中不包含“{}”,整个key都是有效部分;
举例来说:key是num,那么就根据num计算,如果是{应用名称}num,则根据“应用名称”计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值
下面不妨看下效果
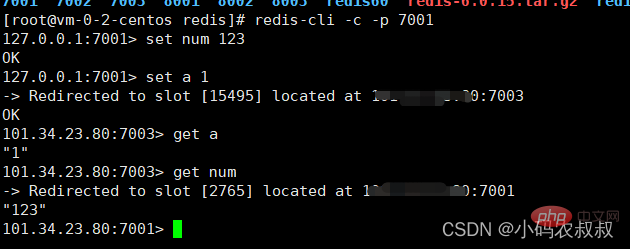
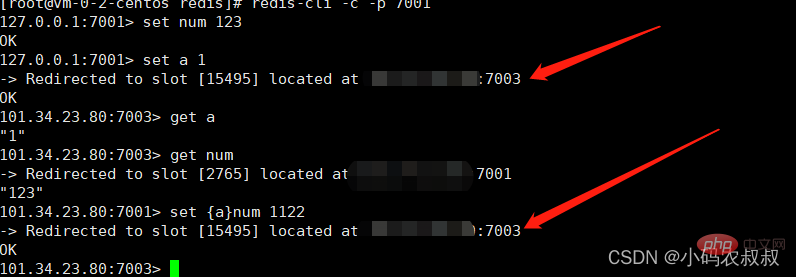
通过上面的演示可以发现,经过集群计算的key将会分配到不同的插槽上,也就是说,key是与插槽绑定,而不是与某个节点绑定,想想为什么会这样呢?
思考下面这个需求
如何将同一类数据固定的保存在同一个Redis实例?
简单来说,如果key的分配完全没有规则的话,当涉及到某个业务类的数据对应的key随机分配到不同的节点上面时,取值的时候就会出现像上面的重定向跨节点的问题,一定程度上提升性能;
解决办法
这一类数据使用相同的有效部分,例如key都以{业务ID}为前缀
集群伸缩(添加节点)
reids的cluster模式下,有一个比较强的功能就是集群的伸缩能力,即在现有的集群基础上,可以根据实际的业务需求,进行集群的伸缩,下面来演示下给上面的集群添加一个新节点的步骤;
1、在当前目录下拷贝一个目录

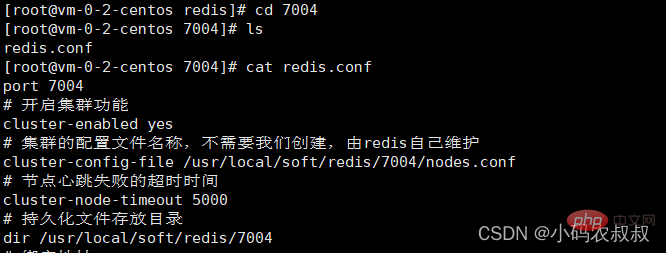
2、修改配置文件的端口
sed -i s/6379/7004/g 7004/redis.conf
3、启动这个实例
/usr/local/soft/redis/redis60/src/redis-server /usr/local/soft/redis/7004/redis.conf

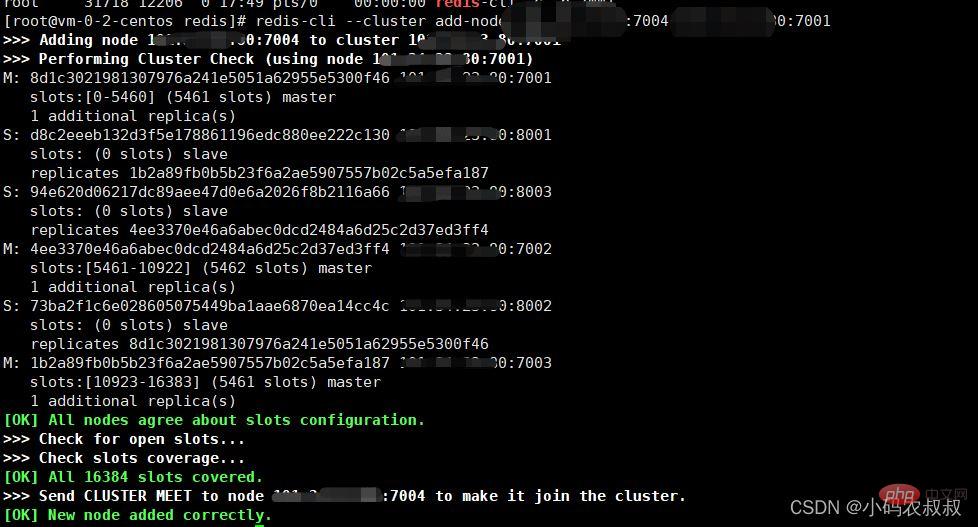
4、使用下面的命令将7004实例假如集群
redis-cli --cluster add-node IP:7004 IP:7001
5、再次查看集群状态
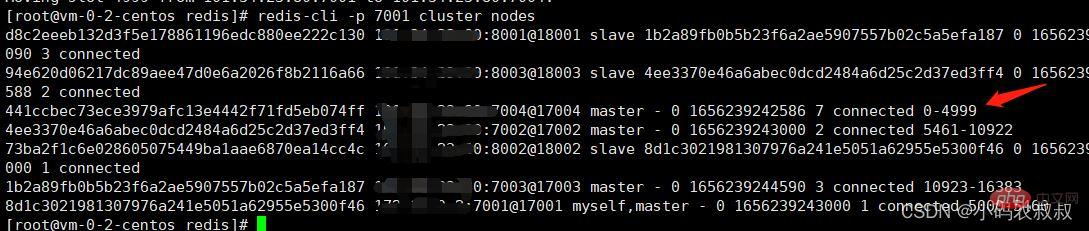
redis-cli -p 7001 cluster nodes
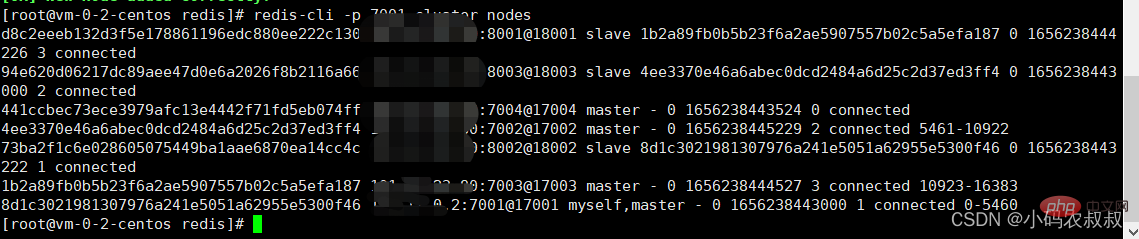
通过上面的状态信息发现,7004这个节点虽然加入了集群,并成了master,但是集群并没有给它分配任何的插槽
6、分配插槽
分配插槽的基本思路是,从现有的某个节点上迁移部分插槽到新的节点即可,执行下面的命令进行插槽分配
redis-cli --cluster reshard 101.34.23.80:7001
执行命令后将出现下面的提示,这里输入你要转移的插槽数量
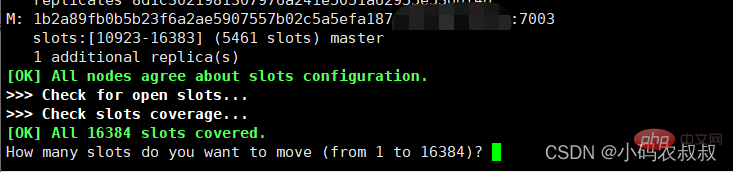
将7004对应的实例ID输入即可
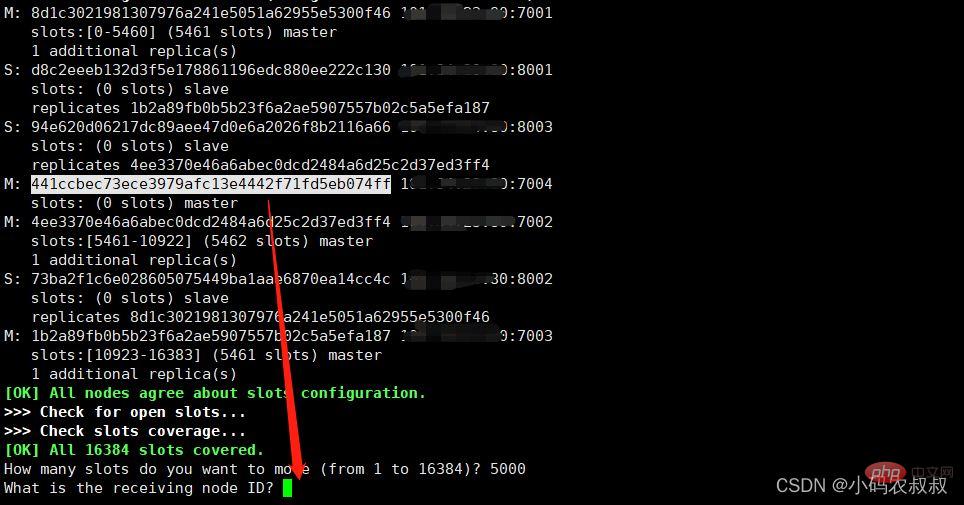
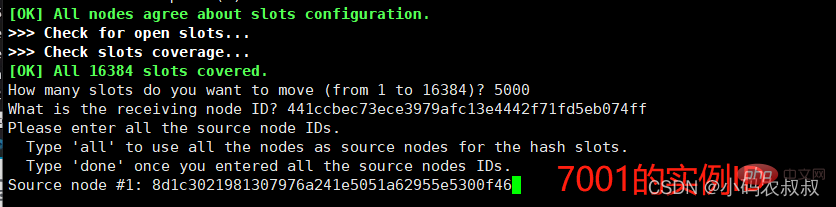
输入yes后开始移动插槽
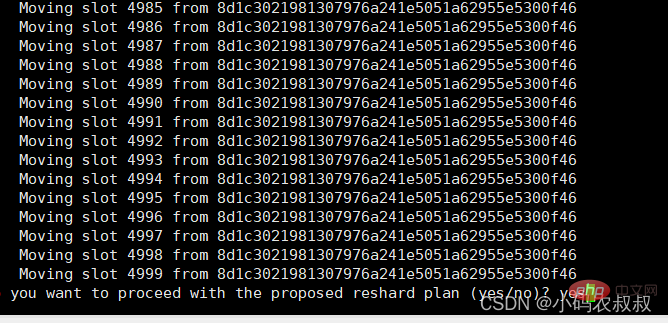
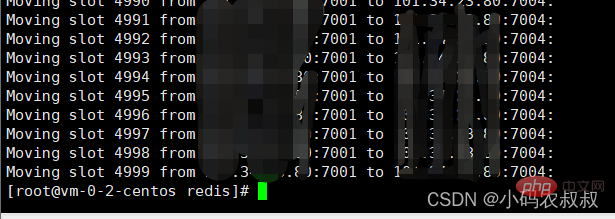
移动完成后,再次查看集群状态,这时候7004对应的节点就分配到了从0 ~ 500的数量的插槽
故障转移
redis的cluster模式的集群,还具备一定的故障转移能力,比如在上面的架构模式下,当集群中的某个master节点宕机之后,会出现什么情况呢?下面我们来模拟下这个过程,看看效果如何
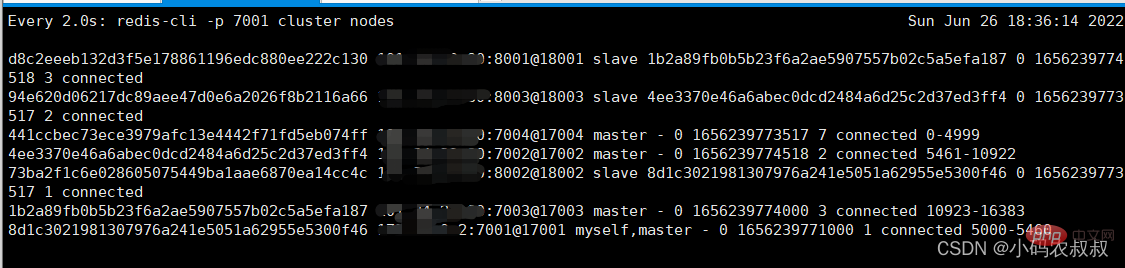
1、使用watch命令监控下集群的状态
通过这个命令可以实时查看集群的动态日志变化
watch redis-cli -p 7001 cluster nodes
2、手动将7002实例的master宕机
redis-cli -p 7002 shutdown
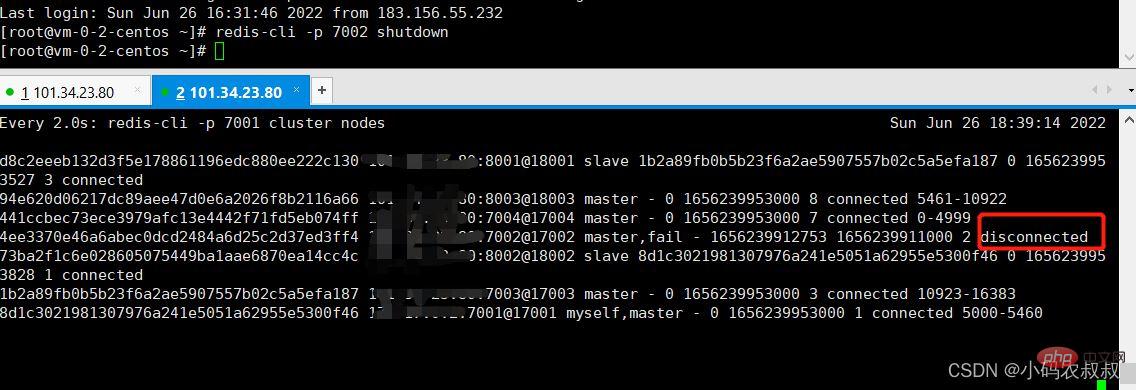
从上面的监控日志不难发现,当7002挂掉后,过了一会儿与集群以及它的从节点8003失去了联系,然后8003这个节点升级为master节点;
3、手动将7002实例启动起来
/usr/local/soft/redis/redis60/src/redis-server /usr/local/soft/redis/7002/redis.conf
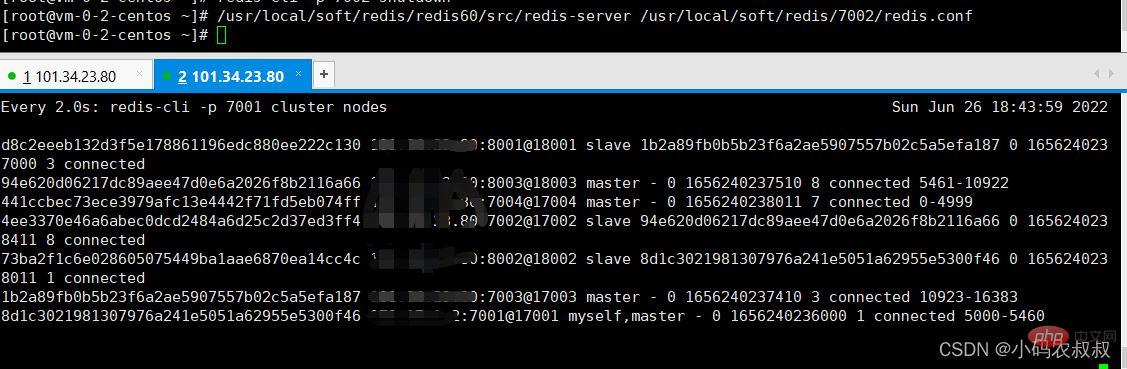
再次分析日志,可以看到这时候7002只能以slave的身份加入了集群,事实上在某些情况下,我们仍然希望这个宕机的节点恢复后依然是主节点,这该怎么办呢?这就涉及到了手动故障转移,主要操作步骤如下:
- 使用redis-cli连接7002节点;
- 执行cluster failover命令;
在上面执行之后的情况下,7002是一个slave节点
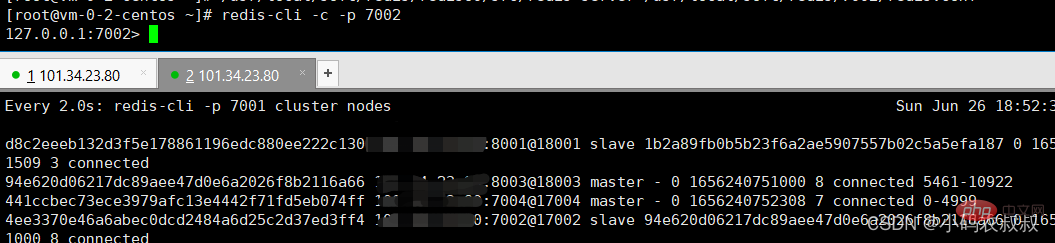
执行 CLUSTER FAILOVER 命令,观察日志动态变化,通过日志变化,可以看到,命令执行完毕后,7002很快就变成了master,而8003成了slave;
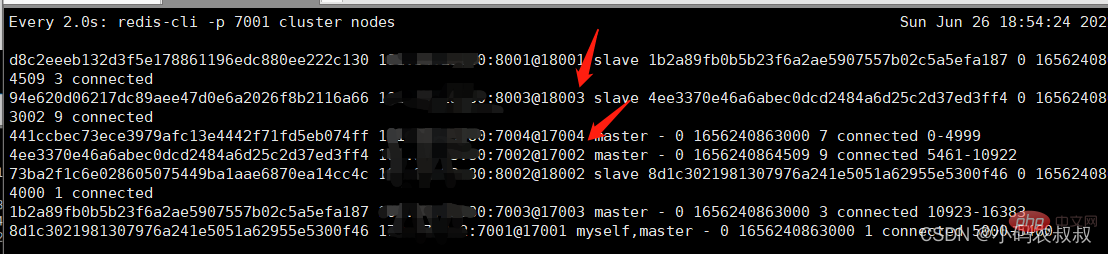
通过以上步骤就完成了redis的cluster模式下的故障转移的过程
使用redistemplate访问分片集群
1、引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2、将配置文件中的集群地址修改成下面这样即可
spring:
redis:
cluster:
nodes:
- 集群IP:7001
- 集群IP:7002
- 集群IP:7003
- 集群IP:7004
- 集群IP:8001
- 集群IP:8002
- 集群IP:8003至于具体的代码部分,可以参考下面的这个测试案例
@Autowired
private RedisTemplate<String,String> redisTemplate;
//localhost:8083/set?key=b&value=123
@GetMapping("/set")
public void set(@RequestParam String key,@RequestParam String value){
redisTemplate.opsForValue().set(key,value);
}
//localhost:8083/get?key=b
@GetMapping("/get")
public String get(@RequestParam String key){
return redisTemplate.opsForValue().get(key);
}推荐学习:Redis视频教程
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des Aufbaus und der Verwendung des Redis-Sharding-Clusters. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Redis-Studiennotizen veröffentlichen und abonnieren
- Fassen Sie die Wissenspunkte der Redis-geordneten Menge zset zusammen
- In diesem Artikel erfahren Sie, wie Sie die Redis-Nachrichtenwarteschlange mithilfe von ThinkPHP und Think-Queue implementieren.
- Redis vom Umgebungsaufbau bis zur kompetenten Nutzung (Zusammenfassungsfreigabe)
- Die von Redis geordnete Sammlung verwendet die Wissenspunktinduktion