
Lassen Sie uns über die Verwendung von Redis zur Implementierung von verteiltem Caching sprechen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-07-14 17:01:172889Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis, das hauptsächlich Probleme im Zusammenhang mit verteiltem Caching behandelt. Verteilt bedeutet, dass es aus mehreren Anwendungen besteht, die letztendlich auf verschiedenen Servern verteilt sein können . Werfen wir einen Blick darauf. Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Redis-Video-Tutorial
Distributed-Cache-Beschreibung:
Der Schwerpunkt des verteilten Caches liegt auf der Verteilung. Ich glaube, Sie sind dort mit vielen verteilten Methoden in Berührung gekommen Es gibt viele verteilte Bereitstellungen, verteilte Sperren, Dinge, Systeme usw. Dies gibt uns ein klares Verständnis der Verteilung selbst. Die Verteilung besteht aus mehreren Anwendungen, die auf verschiedenen Servern verteilt sein können und letztendlich Dienste für die Webseite bereitstellen.
Verteiltes Caching bietet folgende Vorteile:
- Die zwischengespeicherten Daten auf allen Webservern sind gleich und die zwischengespeicherten Daten unterscheiden sich nicht aufgrund unterschiedlicher Anwendungen und unterschiedlicher Server.
- Der Cache ist unabhängig und wird vom Neustart des Webservers oder vom Löschen und Hinzufügen nicht beeinflusst, was bedeutet, dass diese Änderungen im Web keine Änderungen an den zwischengespeicherten Daten verursachen.
Da in der herkömmlichen Einzelanwendungsarchitektur die Anzahl der Benutzerbesuche nicht hoch ist, ist der größte Teil des Caches zum Speichern von Benutzerinformationen und einigen Seiten vorhanden. Die meisten Vorgänge sind direkte Lese- und Schreibinteraktionen mit der Datenbank ist einfach, auch einfache Architektur genannt.
Traditionelle OA-Projekte wie ERP, SCM, CRM und andere Systeme haben eine geringe Anzahl von Benutzern und sind auch aus geschäftlichen Gründen bei den meisten Unternehmen immer noch eine sehr verbreitete Architektur , aber einige Systeme sind es. Wenn die Anzahl der Benutzer zunimmt und das Unternehmen expandiert, treten DB-Engpässe auf.
Es gibt zwei Möglichkeiten, mit dieser Situation umzugehen, die ich unten gelernt habe
(1): Wenn die Anzahl der Benutzerbesuche nicht groß ist, aber die Menge der gelesenen und geschriebenen Daten groß ist, gehen wir im Allgemeinen damit um Mit der DB können Sie Lese- und Schreibvorgänge trennen, einen Master mit mehreren Slaves verwenden und die Hardware aktualisieren, um das DB-Engpassproblem zu lösen.
Dieser Mangel liegt auch darin:
1. Was tun, wenn die Anzahl der Benutzer groß ist? ,
2. Die Leistungssteigerung ist begrenzt,
3. Das Preis-/Leistungsverhältnis ist nicht hoch. Die Verbesserung der Leistung erfordert viel Geld (z. B. beträgt der aktuelle E/A-Durchsatz 0,9 und muss auf 1,0 erhöht werden. Dieser Preis ist in der Tat beträchtlich, wenn wir die Maschinenkonfiguration erhöhen)
(2): Wenn die Anzahl der Benutzer Da die Anzahl der Besuche ebenfalls zunimmt, müssen wir Caching einführen, um das Problem zu lösen. Ein Bild beschreibt die allgemeine Rolle des Caching.
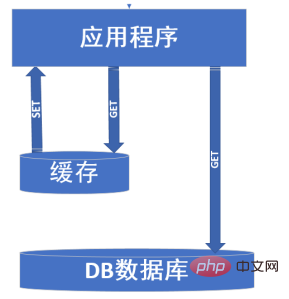
Caching zielt hauptsächlich auf Daten ab, die sich selten ändern und stark besucht werden. Die DB-Datenbank kann nur zum Festigen von Daten oder nur zum Lesen von Daten verwendet werden, die sich häufig ändern Der Vorgang des Zeichnens von SET besteht darin, die Existenz des Caches als temporäre Datenbank zu erklären. Der Vorteil besteht darin, dass der Druck übertragen werden kann der Datenbank in die Cache-Mitte.
Das Aufkommen des Caches löst das Problem des Datenbankdrucks, aber wenn die folgenden Situationen auftreten, spielt der Cache keine Rolle mehr: Cache-Penetration, Cache-Zusammenbruch und Cache-Lawine sind drei Situationen.
Cache-Penetration: Wenn wir den Cache in unseren Programmen verwenden, gehen wir normalerweise zuerst zum Cache, um die gewünschten Cache-Daten abzufragen. Wenn die gewünschten Daten nicht im Cache vorhanden sind, verliert der Cache seine Rolle. (Cache-Fehler) Wir müssen uns nur an die DB-Bibliothek wenden, um Daten anzufordern. Wenn es zu diesem Zeitpunkt zu viele solcher Aktionen gibt, stürzt die Datenbank ab. Diese Situation muss von uns verhindert werden. Beispiel: Wir beziehen Benutzerinformationen aus dem Cache, geben jedoch absichtlich Benutzerinformationen ein, die nicht im Cache vorhanden sind, um den Cache zu umgehen und den Druck wieder auf die Daten zu verlagern. Um dieses Problem zu lösen, können wir die Daten, auf die zum ersten Mal zugegriffen wird, zwischenspeichern, da der Cache die Benutzerinformationen nicht finden kann und die Datenbank die Benutzerinformationen nicht abfragen kann. Um einen wiederholten Zugriff zu vermeiden, speichern wir die Anforderung zu diesem Zeitpunkt zwischen Zurück zum Cache: Einige Leute haben möglicherweise Fragen, was zu tun ist, wenn auf Zehntausende Parameter zugegriffen wird, die eindeutig sind und den Cache vermeiden können.
Cache-Aufschlüsselung: Bei einigen Cache-SCHLÜSSELn mit festgelegter Ablaufzeit erfolgt der Zugriff auf das Programm mit hohem gleichzeitigem Zugriff (Cache-Ungültigmachung). Zu diesem Zeitpunkt wird eine Mutex-Sperre verwendet Lösen Sie das Problem.
Mutex-Sperrprinzip: Die beliebte Beschreibung lautet, dass 10.000 Benutzer darauf zugegriffen haben, aber nur ein Benutzer die Berechtigung zum Zugriff auf die Datenbank erhalten kann, wird der Cache neu erstellt. Zu diesem Zeitpunkt ist der Rest Da der Besucher keine Berechtigung hat, wartet er auf den Zugriff auf den Cache.
Läuft nie ab: Manche Leute denken vielleicht: Kann es nicht ausreichen, wenn ich die Ablaufzeit nicht festlege? Ja, aber das hat auch Nachteile. Zu diesem Zeitpunkt sind die Daten im Cache relativ verzögert.
Cache-Lawine: bedeutet, dass mehrere Caches gleichzeitig ablaufen. Zu diesem Zeitpunkt kommt es zu einer großen Anzahl von Datenzugriffen (Cache-Invalidierung) und der Druck auf die Datenbank DB steigt erneut. Die Lösung besteht darin, beim Festlegen der Ablaufzeit eine Zufallszahl zur Ablaufzeit hinzuzufügen, um sicherzustellen, dass der Cache in großen Bereichen nicht ausfällt.
Projektvorbereitung
1. Installieren Sie zuerst Redis, Sie können hier nachlesen
2. Dann herunterladen und installieren: Client-Tool: RedisDesktopManager (bequeme Verwaltung)
3. Referenzieren Sie Microsoft.Extensions.Caching.Redis in unserem Projekt Nuget
Zu diesem Zweck erstellen wir ein neues ASP.NET Core MVC-Projekt und registrieren zunächst den Redis-Dienst in der Methode „ConfigureServices“ der Startup-Klasse des Projekts:
public void ConfigureServices(IServiceCollection services)
{
//将Redis分布式缓存服务添加到服务中
services.AddDistributedRedisCache(options =>
{
//用于连接Redis的配置 Configuration.GetConnectionString("RedisConnectionString")读取配置信息的串
options.Configuration = "localhost";// Configuration.GetConnectionString("RedisConnectionString");
//Redis实例名DemoInstance
options.InstanceName = "DemoInstance";
});
services.AddMvc();
}
Sie können auch die IP-Adresse, die Portnummer und die IP-Adresse angeben des Redis-Servers bei der Registrierung des Redis-Dienstes oben Redis-Server in der Services.AddDistributedRedisCache-Methode Wenn Sie die später eingeführte IDistributedCache aufrufen, löst die Methode in der Schnittstelle RedisConnectionException und RedisTimeoutException aus, wenn der Vorgang auf dem Redis-Server abläuft. Wenn wir also den Redis-Dienst unten registrieren, geben wir drei Zeitüberschreitungen an:
public void ConfigureServices(IServiceCollection services)
{
//将Redis分布式缓存服务添加到服务中
services.AddDistributedRedisCache(options =>
{
//用于连接Redis的配置 Configuration.GetConnectionString("RedisConnectionString")读取配置信息的串
options.Configuration = "192.168.1.105:6380,password=1qaz@WSX3edc$RFV";//指定Redis服务器的IP地址、端口号和登录密码
//Redis实例名DemoInstance
options.InstanceName = "DemoInstance";
});
services.AddMvc();
}
Unter anderem dient ConnectTimeout dazu, eine Verbindung zum Redis-Server herzustellen. Der Timeout-Zeitraum und SyncTimeout und ResponseTimeout sind die Timeout-Zeiträume für Datenvorgänge auf dem Redis-Server. Beachten Sie, dass wir oben das Attribut „options.ConfigurationOptions“ verwendet haben, um die IP-Adresse, die Portnummer und das Anmeldekennwort des Redis-Servers festzulegen. IDistributedCache-Schnittstelle
IDistributedCache-Schnittstelle Enthält synchrone und asynchrone Methoden. Die Schnittstelle ermöglicht das Hinzufügen, Abrufen und Löschen von Elementen in einer verteilten Cache-Implementierung. Die IDistributedCache-Schnittstelle enthält die folgenden Methoden: Get, GetAsync, die einen Zeichenfolgenschlüssel entgegennimmt und das Cache-Element als Byte[] abruft, wenn es im Cache gefunden wird.Set, SetAsync
Fügen Sie mithilfe von Zeichenfolgenschlüsseln Elemente (Byte[]-Form) zum Cache hinzu oder ändern Sie sie. Refresh, RefreshAsync
Aktualisieren Sie ein Element im Cache basierend auf einem Schlüssel und setzen Sie seinen einstellbaren Ablaufzeitwert zurück (falls vorhanden). Remove, RemoveAsync
Cache-Elemente basierend auf dem Schlüssel entfernen. Wenn der an die Remove-Methode übergebene Schlüssel in Redis nicht vorhanden ist, meldet die Remove-Methode keinen Fehler, es passiert jedoch nichts. Wenn der an die Remove-Methode übergebene Parameter jedoch null ist, wird eine Ausnahme ausgelöst. Da die Set- und Get-Methoden der IDistributedCache-Schnittstelle wie oben erwähnt über Byte-Arrays von Redis auf Daten zugreifen, ist dies in gewisser Weise nicht sehr praktisch. Im Folgenden kapsele ich eine RedisCache-Klasse. Auf jede Art von Daten kann zugegriffen werden von Redis.
Das Json.NET Nuget-Paket wird zum Serialisieren und Deserialisieren des Json-Formats verwendet: public void ConfigureServices(IServiceCollection services)
{
//将Redis分布式缓存服务添加到服务中
services.AddDistributedRedisCache(options =>
{
options.ConfigurationOptions = new StackExchange.Redis.ConfigurationOptions()
{
Password = "1qaz@WSX3edc$RFV",
ConnectTimeout = 5000,//设置建立连接到Redis服务器的超时时间为5000毫秒
SyncTimeout = 5000,//设置对Redis服务器进行同步操作的超时时间为5000毫秒
ResponseTimeout = 5000//设置对Redis服务器进行操作的响应超时时间为5000毫秒
};
options.ConfigurationOptions.EndPoints.Add("192.168.1.105:6380");
options.InstanceName = "DemoInstance";
});
services.AddMvc();
}
Nutzungstest
Dann erstellen wir einen neuen CacheController im ASP.NET Core MVC-Projekt und fügen ihm dann die Indexmethode hinzu, um den zu testen Verwandte Methoden der RedisCache-Klasse:
using Microsoft.Extensions.Caching.Distributed;
using Newtonsoft.Json;
using System.Text;
namespace AspNetCoreRedis.Assembly
{
/// <summary>
/// RedisCache缓存操作类
/// </summary>
public class RedisCache
{
protected IDistributedCache cache;
/// <summary>
/// 通过IDistributedCache来构造RedisCache缓存操作类
/// </summary>
/// <param name="cache">IDistributedCache对象</param>
public RedisCache(IDistributedCache cache)
{
this.cache = cache;
}
/// <summary>
/// 添加或更改Redis的键值,并设置缓存的过期策略
/// </summary>
/// <param name="key">缓存键</param>
/// <param name="value">缓存值</param>
/// <param name="distributedCacheEntryOptions">设置Redis缓存的过期策略,可以用其设置缓存的绝对过期时间(AbsoluteExpiration或AbsoluteExpirationRelativeToNow),也可以设置缓存的滑动过期时间(SlidingExpiration)</param>
public void Set(string key, object value, DistributedCacheEntryOptions distributedCacheEntryOptions)
{
//通过Json.NET序列化缓存对象为Json字符串
//调用JsonConvert.SerializeObject方法时,设置ReferenceLoopHandling属性为ReferenceLoopHandling.Ignore,来避免Json.NET序列化对象时,因为对象的循环引用而抛出异常
//设置TypeNameHandling属性为TypeNameHandling.All,这样Json.NET序列化对象后的Json字符串中,会包含序列化的类型,这样可以保证Json.NET在反序列化对象时,去读取Json字符串中的序列化类型,从而得到和序列化时相同的对象类型
var stringObject = JsonConvert.SerializeObject(value, new JsonSerializerSettings()
{
ReferenceLoopHandling = ReferenceLoopHandling.Ignore,
TypeNameHandling = TypeNameHandling.All
});
var bytesObject = Encoding.UTF8.GetBytes(stringObject);//将Json字符串通过UTF-8编码,序列化为字节数组
cache.Set(key, bytesObject, distributedCacheEntryOptions);//将字节数组存入Redis
Refresh(key);//刷新Redis
}
/// <summary>
/// 查询键值是否在Redis中存在
/// </summary>
/// <param name="key">缓存键</param>
/// <returns>true:存在,false:不存在</returns>
public bool Exist(string key)
{
var bytesObject = cache.Get(key);//从Redis中获取键值key的字节数组,如果没获取到,那么会返回null
if (bytesObject == null)
{
return false;
}
return true;
}
/// <summary>
/// 从Redis中获取键值
/// </summary>
/// <typeparam name="T">缓存的类型</typeparam>
/// <param name="key">缓存键</param>
/// <param name="isExisted">是否获取到键值,true:获取到了,false:键值不存在</param>
/// <returns>缓存的对象</returns>
public T Get<T>(string key, out bool isExisted)
{
var bytesObject = cache.Get(key);//从Redis中获取键值key的字节数组,如果没获取到,那么会返回null
if (bytesObject == null)
{
isExisted = false;
return default(T);
}
var stringObject = Encoding.UTF8.GetString(bytesObject);//通过UTF-8编码,将字节数组反序列化为Json字符串
isExisted = true;
//通过Json.NET反序列化Json字符串为对象
//调用JsonConvert.DeserializeObject方法时,也设置TypeNameHandling属性为TypeNameHandling.All,这样可以保证Json.NET在反序列化对象时,去读取Json字符串中的序列化类型,从而得到和序列化时相同的对象类型
return JsonConvert.DeserializeObject<T>(stringObject, new JsonSerializerSettings()
{
TypeNameHandling = TypeNameHandling.All
});
}
/// <summary>
/// 从Redis中删除键值,如果键值在Redis中不存在,该方法不会报错,只是什么都不会发生
/// </summary>
/// <param name="key">缓存键</param>
public void Remove(string key)
{
cache.Remove(key);//如果键值在Redis中不存在,IDistributedCache.Remove方法不会报错,但是如果传入的参数key为null,则会抛出异常
}
/// <summary>
/// 从Redis中刷新键值
/// </summary>
/// <param name="key">缓存键</param>
public void Refresh(string key)
{
cache.Refresh(key);
}
}
} Zuvor haben wir in der Methode „ConfigureServices“ der Startup-Klasse des Projekts beim Aufrufen von „services.AddDistributedRedisCache“ zum Registrieren des Redis-Dienstes „options.InstanceName = „DemoInstance““ festgelegt. Was genau bewirkt dies? Instanzname haben? Wofür ist es? Nachdem wir den folgenden Code der Index-Methode im obigen CacheController aufgerufen haben:
public class CacheController : Controller
{
protected RedisCache redisCache;
//由于我们前面在Startup类的ConfigureServices方法中调用了services.AddDistributedRedisCache来注册Redis服务,所以ASP.NET Core MVC会自动依赖注入下面的IDistributedCache cache参数
public CacheController(IDistributedCache cache)
{
redisCache = new RedisCache(cache);
}
public IActionResult Index()
{
bool isExisted;
isExisted = redisCache.Exist("abc");//查询键值"abc"是否存在
redisCache.Remove("abc");//删除不存在的键值"abc",不会报错
string key = "Key01";//定义缓存键"Key01"
string value = "This is a demo key !";//定义缓存值
redisCache.Set(key, value, new DistributedCacheEntryOptions()
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(10)
});//设置键值"Key01"到Redis,使用绝对过期时间,AbsoluteExpirationRelativeToNow设置为当前系统时间10分钟后过期
//也可以通过AbsoluteExpiration属性来设置绝对过期时间为一个具体的DateTimeOffset时间点
//redisCache.Set(key, value, new DistributedCacheEntryOptions()
//{
// AbsoluteExpiration = DateTimeOffset.Now.AddMinutes(10)
//});//设置键值"Key01"到Redis,使用绝对过期时间,AbsoluteExpiration设置为当前系统时间10分钟后过期
var getVaue = redisCache.Get<string>(key, out isExisted);//从Redis获取键值"Key01",可以看到getVaue的值为"This is a demo key !"
value = "This is a demo key again !";//更改缓存值
redisCache.Set(key, value, new DistributedCacheEntryOptions()
{
SlidingExpiration = TimeSpan.FromMinutes(10)
});//将更改后的键值"Key01"再次缓存到Redis,这次使用滑动过期时间,SlidingExpiration设置为10分钟
getVaue = redisCache.Get<string>(key, out isExisted);//再次从Redis获取键值"Key01",可以看到getVaue的值为"This is a demo key again !"
redisCache.Remove(key);//从Redis中删除键值"Key01"
return View();
}
}Wir melden uns mit redis-cli beim Redis-Server an und verwenden den Befehl Keys *, um alle im aktuellen Redis-Dienst gespeicherten Schlüssel anzuzeigen Sie können die Ergebnisse wie folgt sehen:
Sie können sehen, dass der in Redis in unserem Code gespeicherte Schlüssel zwar „Key01“ ist, der tatsächlich im Redis-Dienst gespeicherte Schlüssel jedoch „DemoInstanceKey01“ ist, also der tatsächlich in Redis gespeicherte Schlüssel Redis-Dienst Der Schlüssel ist eine Tastenkombination aus „InstanceName+Key“, sodass wir in Redis Daten für verschiedene Anwendungen isolieren können, indem wir unterschiedliche InstanceNames festlegen. Dies ist die Rolle von InstanceName
Empfohlenes Lernen:
Redis-Video-TutorialDas obige ist der detaillierte Inhalt vonLassen Sie uns über die Verwendung von Redis zur Implementierung von verteiltem Caching sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Beherrschen Sie die Redis-Persistenz vollständig: RDB und AOF
- Redis-Studiennotizen veröffentlichen und abonnieren
- Detaillierte Erläuterung der Beispiele für Redis-Cluster-Operationen
- Fassen Sie die Wissenspunkte der Redis-geordneten Menge zset zusammen
- In diesem Artikel erfahren Sie, wie Sie die Redis-Nachrichtenwarteschlange mithilfe von ThinkPHP und Think-Queue implementieren.