
Vertieftes Verständnis der Redis-Cluster-Lösungen (Master-Slave-Modus, Sentinel-Modus, Redis-Cluster-Modus)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-03-24 19:12:073866Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis, in dem hauptsächlich die damit verbundenen Probleme des Master-Slave-Modus, des Sentinel-Modus und des Redis-Cluster-Modus vorgestellt werden. Ich hoffe, dass er für alle hilfreich ist.

Empfohlenes Lernen: Redis-Tutorial
Einführung in die Redis-Cluster-Lösung (Master-Slave-Modus, Sentinel-Modus, Redis-Cluster-Modus)
1. Master-Slave-Modus
Die Hauptexistenz der vollständigen Datenspeicherung ein einzelnes Redis Zwei Probleme:
Datensicherung und Leistungseinbußen durch große Datenmengen.
Der Master-Slave-Modus von Redis bietet eine bessere Lösung für diese beiden Probleme. Der Master-Slave-Modus bezieht sich auf die Verwendung einer Redis-Instanz als Host und der übrigen Instanzen als Backup-Maschinen.
Die Daten von Host und Slave sind vollständig konsistent. Der Host unterstützt verschiedene Vorgänge wie das Schreiben und Lesen von Daten, während der Slave nur die Synchronisierung und das Lesen von Daten mit dem Host unterstützt. Mit anderen Worten: Der Client kann Daten auf den Host schreiben , und der Host synchronisiert den Datenschreibvorgang automatisch mit dem Slave.
Der Master-Slave-Modus löst das Datensicherungsproblem gut, und da die Master-Slave-Dienstdaten nahezu konsistent sind, können Befehle zum Schreiben von Daten zur Ausführung an den Host gesendet werden, während Befehle zum Lesen von Daten an verschiedene Slaves gesendet werden können Ausführung, wodurch der Zweck der Trennung von Lesen und Schreiben erreicht wird.
So funktioniert die Master-Slave-Replikation:
Nachdem der Slave-Slave-Knotendienst gestartet und eine Verbindung zum Master hergestellt wurde, sendet er aktiv einen SYNC-Befehl. Nach Erhalt des Synchronisierungsbefehls startet der Master-Dienst-Masterknoten den Hintergrundspeichervorgang und sammelt alle empfangenen Befehle zum Ändern des Datensatzes. Nach Abschluss des Hintergrundvorgangs überträgt der Master die gesamte Datenbankdatei an den Slave, um einen vollständigen Vorgang abzuschließen Synchronisation. Der Slave-Slave-Knotendienst speichert und lädt die Datenbankdateidaten nach dem Empfang in den Speicher. Danach überträgt der Master-Knoten weiterhin alle gesammelten Änderungsbefehle und neuen Änderungsbefehle nacheinander an die Slaves. Die Slaves führen diese Datenänderungsbefehle dieses Mal aus, um eine endgültige Datensynchronisierung zu erreichen.
Wenn die Verbindung zwischen Master und Slave getrennt wird, kann sich der Slave automatisch wieder mit dem Master verbinden. Nach erfolgreicher Verbindung wird automatisch eine vollständige Synchronisierung durchgeführt. 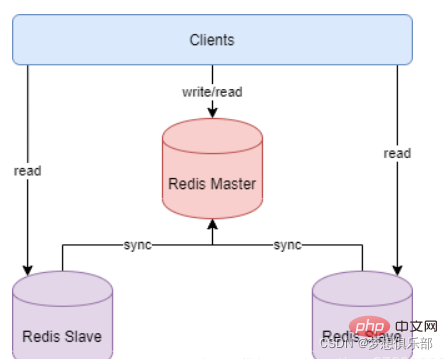
Bereitstellung:
Redis-Version:6.0.9
1. Kopieren Sie 4 Kopien von Die Konfigurationsdateien sind einfach zu konfigurieren
Die Konfigurationsdatei des Master-Knotens erfordert im Allgemeinen keine besonderen Einstellungen. Der Standardport ist 6379. Slave1-Knoten-Port-Einstellung 6380. Konfigurieren Sie dann eine Replikatzeile von 127.0.0.1 und 6379. Slave2-Knoten-Port-Einstellung 6381 Konfigurieren Sie dann eine Replikatzeile von 127.0.0.1 6379Slave3-Knotenport. Stellen Sie 6382 ein und konfigurieren Sie eine Replikatzeile von 127.0.0.1 6379
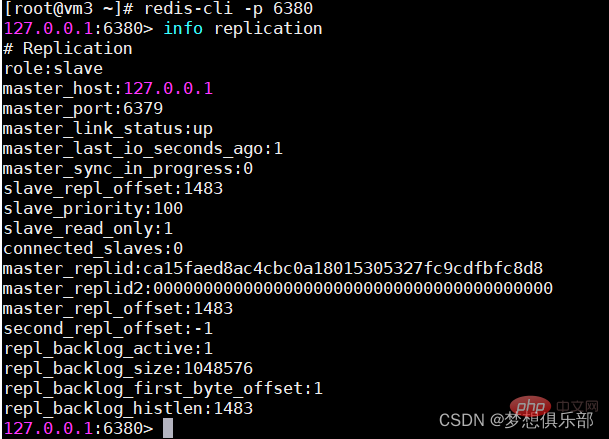
3. Öffnen Sie den Master-Knoten bzw. 3 Slave-Knoten
redis-server master.conf
redis- Server Slave1.conf
Redis-Server Slave2.conf
 1. Vorteile:
1. Vorteile: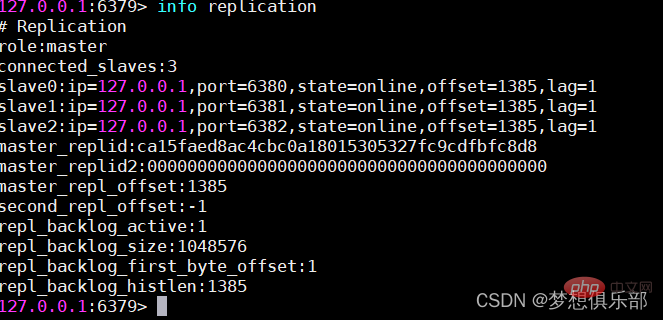 Derselbe Master kann mehrere Slaves synchronisieren.
Derselbe Master kann mehrere Slaves synchronisieren.
Die Synchronisierung zwischen Master und Slave erfolgt auf nicht blockierende Weise Der Client kann weiterhin Abfragen oder Aktualisierungsanforderungen stellen.
verfügt nicht über automatische Fehlertoleranz- und Wiederherstellungsfunktionen. Die Ausfallzeit des Masters oder Slaves kann dazu führen, dass die Clientanforderung fehlschlägt oder wechseln Sie die Client-IP manuell, um sie wiederherzustellen.
Der Master ist ausgefallen. Wenn die Daten nicht synchronisiert sind, kommt es nach dem IP-Wechsel zu Dateninkonsistenzen. Die Kapazität von Redis ist begrenzt Durch die Einzelmaschinenkonfiguration ist der Master-Slave-Modus von Redis tatsächlich sehr einfach und wird in tatsächlichen Produktionsumgebungen selten verwendet. Es wird empfohlen, den Master-Slave-Modus in tatsächlichen Produktionsumgebungen zu verwenden. Der Grund, warum es nicht empfohlen wird, liegt in seinen Mängeln. In Situationen, in denen die Datenmenge sehr groß ist oder eine hohe Verfügbarkeit des Systems erforderlich ist, ist der Master-Slave-Modus ebenfalls instabil. Obwohl dieses Modell sehr einfach ist, stellt es die Grundlage für andere Modelle dar, sodass das Verständnis dieses Modells für das Erlernen anderer Modelle sehr hilfreich sein wird.
2. Sentinel-Modus (Sentinel)
Sentinel ist, wie der Name schon sagt, dazu da, den Redis-Cluster zu bewachen. Sobald ein Problem entdeckt wird, kann es entsprechend reagieren. Zu seinen Funktionen gehören
Wenn der Master ausfällt, kann er automatisch einen Slave zum Master umwandeln (wenn der älteste Bruder stirbt, wählen Sie einen jüngeren Bruder als Nachfolger aus)
Mehrere Sentinels können dasselbe überwachen Redis und die Sentinels können auch automatisch überwachen
Nach der automatischen Erkennung des Slaves und anderer Sentinel-Knoten kann der Sentinel regelmäßig überwachen, ob diese Datenbanken und Knoten ihre Dienste gestoppt haben, indem er regelmäßig PING-Befehle sendet.
Wenn die PING-Datenbank oder der Knoten das Zeitlimit überschreitet (konfiguriert durch Sentinel Down-After-Milliseconds Master-Name Millisekunden) und nicht antwortet, geht Sentinel davon aus, dass er subjektiv offline ist (sdown, s bedeutet Subjektiv – subjektiv). Wenn der Master offline ist, sendet der Sentinel einen Befehl an andere Sentinels, um sie zu fragen, ob sie glauben, dass der Master auch subjektiv offline ist. Wenn eine bestimmte Anzahl (d. h. das Quorum in der Konfigurationsdatei) an Stimmen erreicht ist, wird der Sentinel geht davon aus, dass der Master objektiv offline war (odown, o ist objektiv – objektiv) und wählt den führenden Sentinel-Knoten aus, um die Fehlerbehebung für das Master-Slave-System einzuleiten. Wenn nicht genügend Sentinel-Prozesse vorhanden sind, um dem Offline-Status des Masters zuzustimmen, wird der objektive Offline-Status des Masters entfernt. Wenn der Master erneut eine gültige Antwort auf den an den Sentinel-Prozess gesendeten PING-Befehl zurückgibt, wird der subjektive Offline-Status des Masters entfernt .
Der Sentry glaubt, dass, nachdem der Master objektiv offline ist, der Fehlerwiederherstellungsvorgang vom gewählten Anführer-Sentinel durchgeführt werden muss.
Nachdem der Anführer ausgewählt wurde, beginnt der Anführer mit der Fehlerwiederherstellung auf dem System und wählt einen aus der Datenbank aus des ausgefallenen Masters.
Nach Auswahl des Slaves, der ersetzt werden muss, sendet der führende Wächter einen Befehl an die Datenbank, um ihn zum Master zu aktualisieren, und sendet dann Befehle an andere Slaves, um den neuen Master zu akzeptieren aktualisiert endlich die Daten. Aktualisieren Sie den gestoppten alten Master auf die Slave-Datenbank des neuen Masters, damit er nach der Wiederherstellung des Dienstes weiterhin als Slave ausgeführt werden kann. 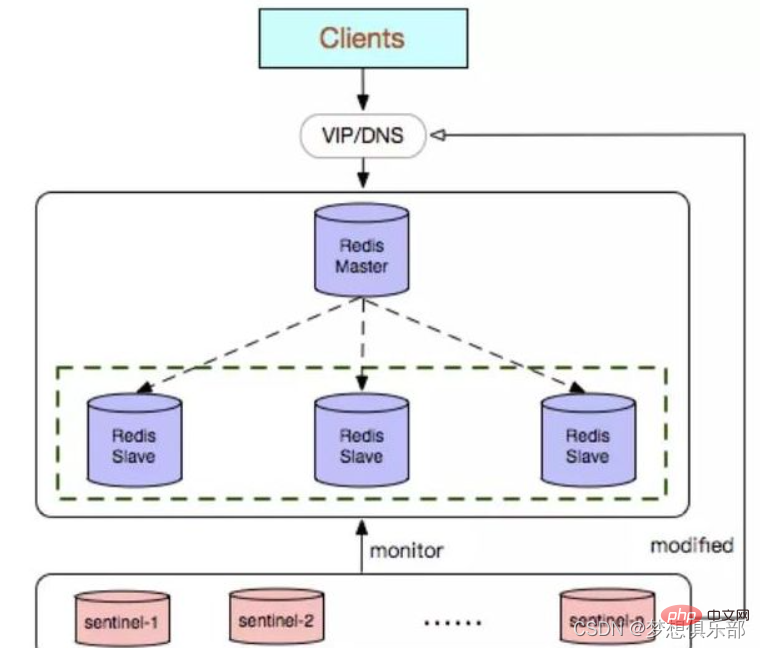
Der Sentinel-Modus basiert auf dem vorherigen Master-Slave-Replikationsmodus. Die Konfigurationsdatei von Sentinel ist sentinel.conf. Fügen Sie die folgende Konfiguration im entsprechenden Verzeichnis hinzu:
port 26379 protected-mode no daemonize yes pidfile "/var/run/redis-sentinel-26379.pid" logfile "/data/redis/logs/sentinel_26379.log" dir "/data/redis/6379" sentinel monitor mymaster 127.0.0.1 6379 2 ##指定主机IP地址和端口,并且指定当有2台哨兵认为主机挂了,则对主机进行容灾切换 #sentinel auth-pass mymaster pwdtest@2019 ##当在Redis实例中开启了requirepass,这里就需要提供密码 sentinel down-after-milliseconds mymaster 3000 ##这里设置了主机多少秒无响应,则认为挂了 sentinel failover-timeout mymaster 180000 ##故障转移的超时时间,这里设置为三分钟
Das Format ist wie folgt:
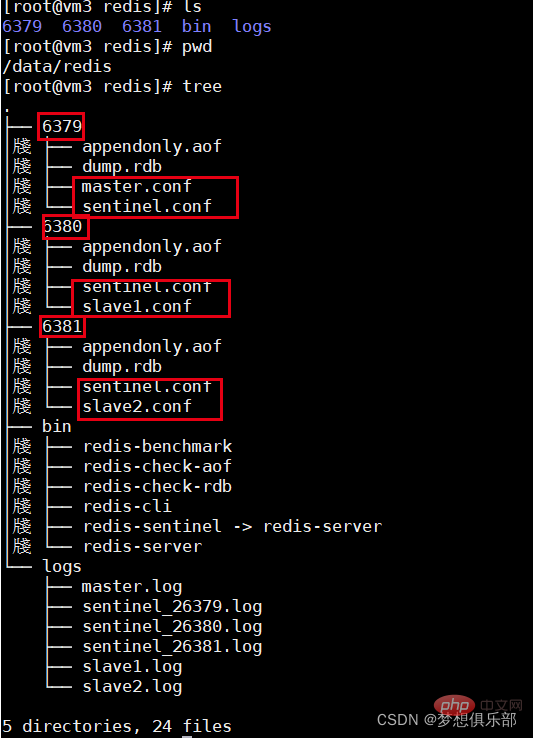
Sehen Sie sich den Sentinel-Status an: 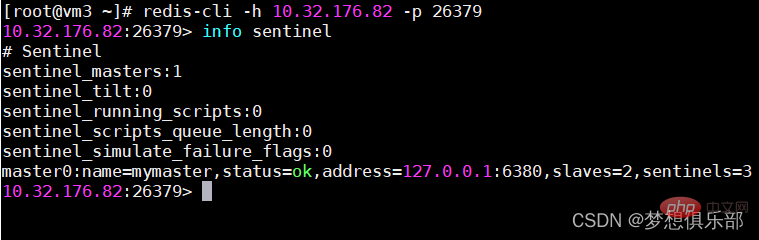
3. Redis-Cluster-Modus (Cluster)
Cluster nimmt eine zentrumslose Struktur an und seine Funktionen sind wie folgt:
Der Client ist direkt mit dem Redis-Knoten verbunden. Der Client muss keine Verbindung zu allen Knoten im Cluster herstellen , stellen Sie einfach eine Verbindung zu einem beliebigen verfügbaren Knoten im Cluster her
Der spezifische Arbeitsmechanismus des Cluster-Modus:
Auf jedem Knoten von Redis gibt es einen Steckplatz mit einem Wertebereich von 0-16383, insgesamt 16384 Steckplätze
Wenn wir darauf zugreifen Schlüssel erhält Redis ein Ergebnis basierend auf dem CRC16-Algorithmus und berechnet dann den Rest des Ergebnisses auf 16384, sodass jeder Schlüssel einem Hash-Slot mit einer Nummer zwischen 0 und 16383 entspricht. Suchen Sie anhand dieses Werts den entsprechenden Knoten entsprechenden Steckplatz und springen dann automatisch zu diesem. Führen Sie Zugriffsvorgänge auf dem entsprechenden Knoten durch.
Um eine hohe Verfügbarkeit zu gewährleisten, führt der Cluster-Modus auch den Master-Slave-Replikationsmodus ein. Ein Master-Knoten entspricht einem oder mehreren Slave-Knoten. Wenn der Master-Knoten ausfällt, werden die Slave-Knoten aktiviert.
Wenn andere Masterknoten einen Masterknoten A anpingen und mehr als die Hälfte der Masterknoten mit A kommunizieren, tritt eine Zeitüberschreitung auf, dann gilt der Masterknoten A als ausgefallen. Wenn Master-Knoten A und seine Slave-Knoten ausfallen, kann der Cluster keine Dienste mehr bereitstellen.
Der Redis-Cluster muss sicherstellen, dass die Knoten, die den 16384-Slots entsprechen, normal funktionieren. Wenn ein Knoten ausfällt, werden auch die Slots, für die er verantwortlich ist, ungültig und der gesamte Cluster funktioniert nicht.
Um die Zugänglichkeit des Clusters zu erhöhen, besteht die offiziell empfohlene Lösung darin, den Knoten in einer Master-Slave-Struktur zu konfigurieren, dh einem Master-Knoten und n Slave-Knoten. Wenn zu diesem Zeitpunkt der Masterknoten ausfällt, wählt der Redis-Cluster basierend auf dem Wahlalgorithmus einen der Slave-Knoten aus, der zum Masterknoten befördert werden soll. Der gesamte Cluster stellt weiterhin Dienste für die Außenwelt bereit Fehlertoleranz.
Die Mindestkonfiguration von Clusterknoten im Clustermodus beträgt 6 Knoten (gemäß dem Clusterwahlmechanismus und der Implementierung der Master-Slave-Sicherung benötigt Redis insgesamt mindestens drei Master und drei Slaves, um einen Redis-Cluster zu bilden, da mindestens die Hälfte von ihnen werden benötigt, um einen Knoten zu bestimmen. Unabhängig davon, ob er ausgefallen ist und eine Master-Slave-Sicherung erfordert), stellt der Master-Knoten Lese- und Schreibvorgänge bereit, und der Slave-Knoten dient als Sicherungsknoten, stellt keine Anforderungen bereit und wird nur für Failover verwendet .
Cluster-Cluster-Bereitstellung
Gemäß dem Cluster-Wahlmechanismus und der Implementierung der Master-Slave-Sicherung benötigt Redis insgesamt mindestens drei Master und drei Slaves, um einen Redis-Cluster zu bilden. Die Testumgebung kann 6 Redis-Knoten auf einer physischen Maschine starten , aber in der Produktion Die Umgebung muss mindestens 2 bis 3 physische Maschinen vorbereiten. (Hier werden drei virtuelle Maschinen verwendet)
Der Cluster-Modus basiert auf dem Sentinel-Modus. Wenn die Daten so groß sind, dass sie dynamisch erweitert werden müssen, funktionieren die ersten beiden nicht. Die Daten müssen nach bestimmten Regeln fragmentiert werden. Verteilen Sie Redis-Daten an mehrere Maschinen. 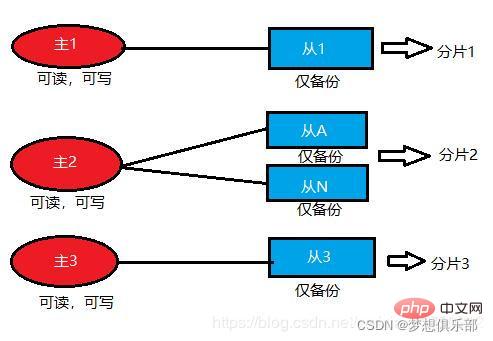
该模式就支持动态扩容,可以在线增加或删除节点,而且客户端可以连接任何一个主节点进行读写,不过此时的从节点仅仅只是备份的作用。至于为何能做到动态扩容,主要是因为Redis集群没有使用一致性hash,而是使用的哈希槽。Redis集群会有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,而集群的每个节点负责一部分hash槽。
那么这样就很容易添加或者删除节点, 比如如果我想新添加个新节点, 我只需要从已有的节点中的部分槽到过来;如果我想移除某个节点,就只需要将该节点的槽移到其它节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
需要注意的是,该模式下不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为。
搭建集群
这里就直接搭建较为复杂的Cluster模式集群,也是企业级开发过程中使用最多的。
1.建redis各节点目录
最终目录结构如下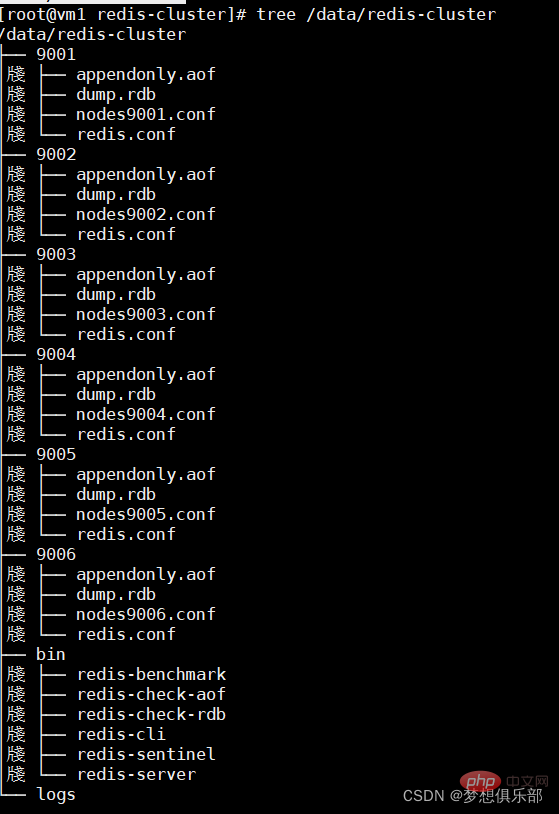
2.逐个修改redis配置
以 9001 的为例子,其余五个类似。
编辑 /data/redis-cluster/9001/redis.conf
redis.conf修改如下:
port 9001(每个节点的端口号) daemonize yes appendonly yes //开启aof bind 0.0.0.0(绑定当前机器 IP) dir "/data/redis-cluster/9001"(数据文件存放位置,,自己加到最后一行 快捷键 shift+g) pidfile /var/run/redis_9001.pid(pid 9001和port要对应) logfile "/data/redis-cluster/logs/9001.log" cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000
3.逐个启动redis节点
/data/redis-cluster/bin/redis-server /data/redis-cluster/9001/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9002/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9003/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9004/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9005/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9006/redis.conf
现在检查一下是否成功开启,如下图所示,都开启成功。
ps -el | grep redis
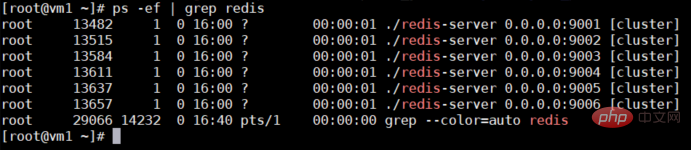
4.集群配置
此时的节点虽然都启动成功了,但他们还不在一个集群里面,不能互相发现,测试会报错:(error) CLUSTERDOWN Hash slot not served。
如下图所示

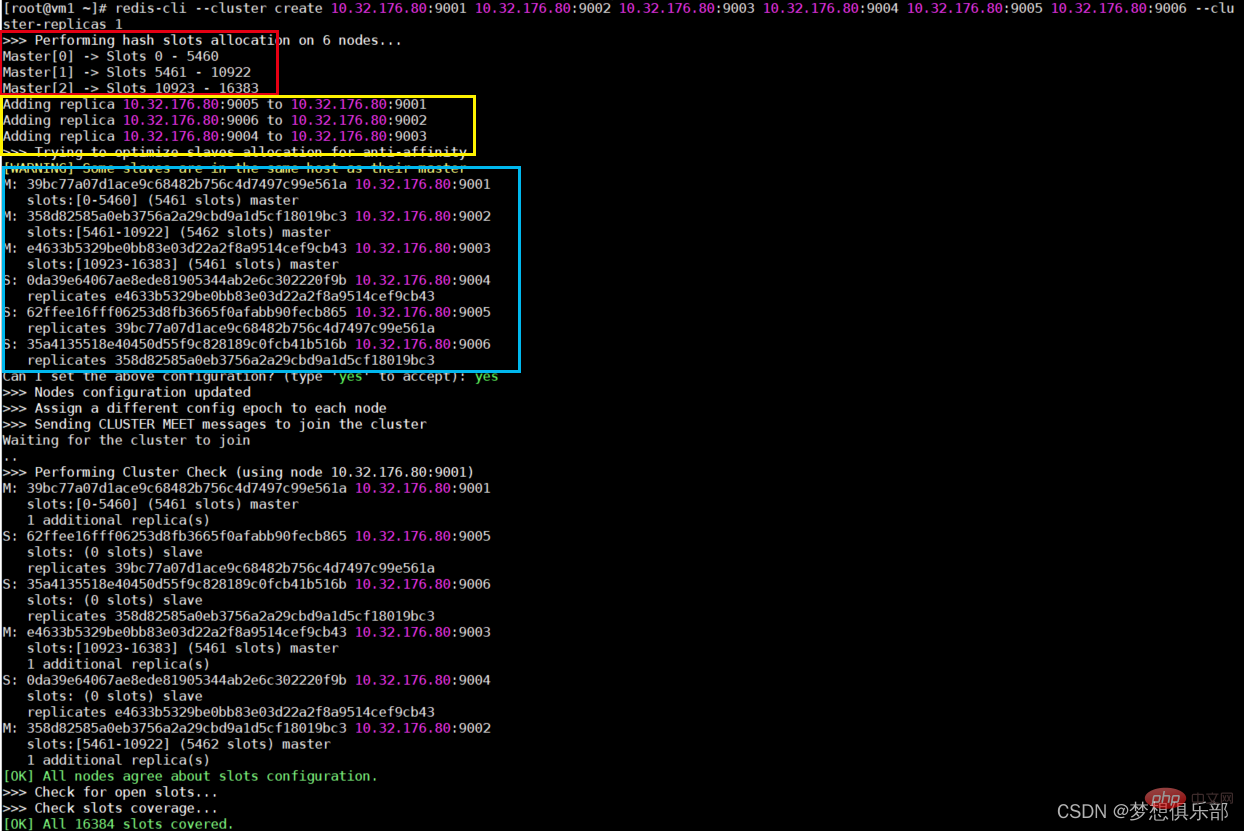
redis-cli --cluster create 10.32.176.80:9001 10.32.176.80:9002 10.32.176.80:9003 10.32.176.80:9004 10.32.176.80:9005 10.32.176.80:9006 --cluster-replicas 1
–cluster-replicas 1 这个指的是从机的数量,表示我们希望为集群中的每个主节点创建一个从节点。
红色选框是给三个主节点分配的共16384个槽点。
黄色选框是主从节点的分配情况。
蓝色选框是各个节点的详情。
5.测试
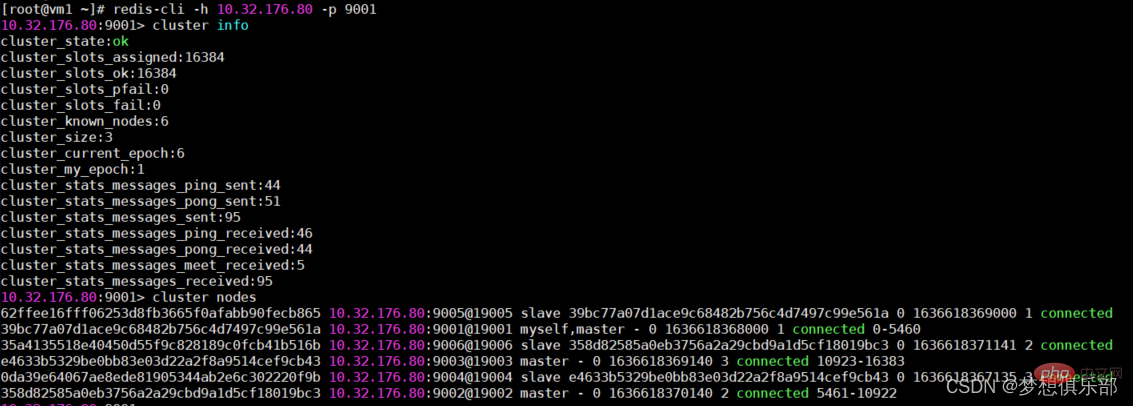
现在通过客户端命令连接上,通过集群命令看一下状态和节点信息等
/data/redis-cluster/bin/redis-cli -c -h 10.32.176.80 -p 9001 cluster info cluster nodes
效果图如下,集群搭建成功。
现在往9001这个主节点写入一条信息,我们可以在9002这个主节点取到信息,集群间各个节点可以通信。
6.故障转移
故障转移机制详解
集群中的节点会向其它节点发送PING消息(该PING消息会带着当前集群和节点的信息),如果在规定时间内,没有收到对应的PONG消息,就把此节点标记为疑似下线。当被分配了slot槽位的主节点中有超过一半的节点都认为此节点疑似下线(就是其它节点以更高的频次,更频繁的与该节点PING-PONG),那么该节点就真的下线。其它节点收到某节点已经下线的广播后,把自己内部的集群维护信息也修改为该节点已事实下线。
节点资格审查:然后对从节点进行资格审查,每个从节点检查最后与主节点的断线时间,如果该值超过配置文件的设置,那么取消该从节点的资格。准备选举时间:这里使用了延迟触发机制,主要是给那些延迟低的更高的优先级,延迟低的让它提前参与被选举,延迟高的让它靠后参与被选举。(延迟的高低是依据之前与主节点的最后断线时间确定的)
Wahlabstimmung: Wenn der Slave-Knoten die Wahlqualifikation erhält, initiiert er eine Wahlanfrage an andere Master-Knoten mit Slots, und diese stimmen ab. Je höher der Slave-Knoten, desto wahrscheinlicher ist es, dass er zum Master-Knoten wird der Slave-Knoten Wenn die Anzahl der erhaltenen Stimmen einen bestimmten Wert erreicht (wenn beispielsweise N Master-Knoten im Cluster vorhanden sind, gilt ein Slave-Knoten als Gewinner, solange er N/2+1 Stimmen erhält). wird als Masterknoten abgelöst.
Ersetzen Sie den Master-Knoten: Der ausgewählte Slave-Knoten führt „slaveof no one“ aus, um seinen Status von „Slave“ zu „Master“ zu ändern, führt dann die Operation „clusterDelSlot“ aus, um die für den ausgefallenen Master-Knoten verantwortlichen Slots zu löschen, und führt „clusterAddSlot“ aus, um diese Slots sich selbst zuzuweisen Anschließend wird eine eigene Pong-Nachricht an den Cluster gesendet, um alle Knoten im Cluster darüber zu informieren, dass der aktuelle Slave-Knoten zum Master-Knoten geworden ist.
Übernahme verwandter Vorgänge: Der neue Masterknoten übernimmt die Slot-Informationen des zuvor ausgefallenen Masterknotens, empfängt und verarbeitet Befehlsanfragen im Zusammenhang mit seinem eigenen Slot.
Failover-Test
Dies ist die Situation bestimmter Knoten im vorherigen Cluster. Ich habe sie wie folgt vereinfacht. Sie können sich die Clusterinformationen im Bild ansehen.
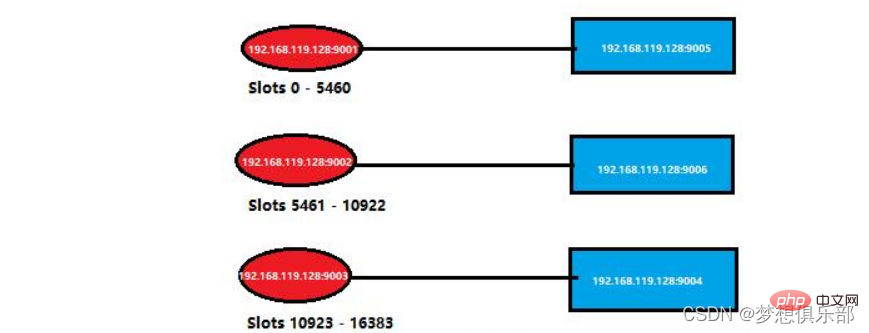
Schließen Sie hier den Prozess von Port 9001, der simulieren soll, dass der Masterknoten auflegt.
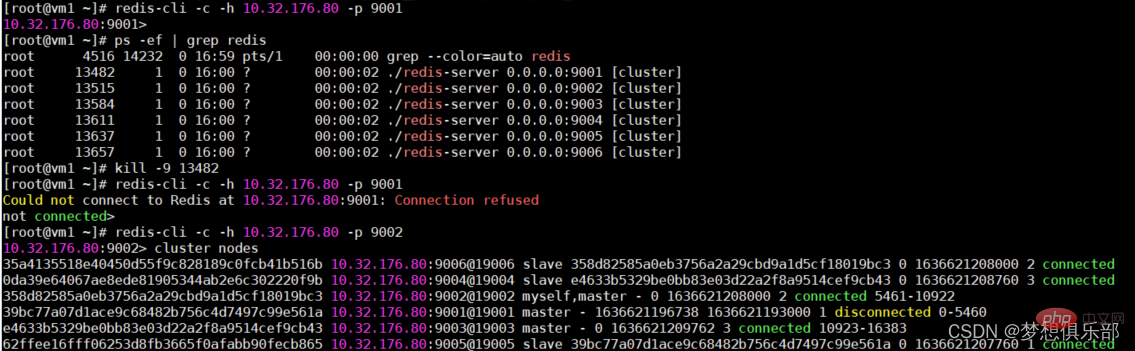
Wenn Sie sich beim toten Redis-Knoten anmelden, wird Ihnen der Zugriff über einen Masterknoten verweigert, der noch normal läuft, und dann die Informationen im Cluster erneut überprüfen
Kurz gesagt, die vorherigen Clusterinformationen wird Wie unten gezeigt
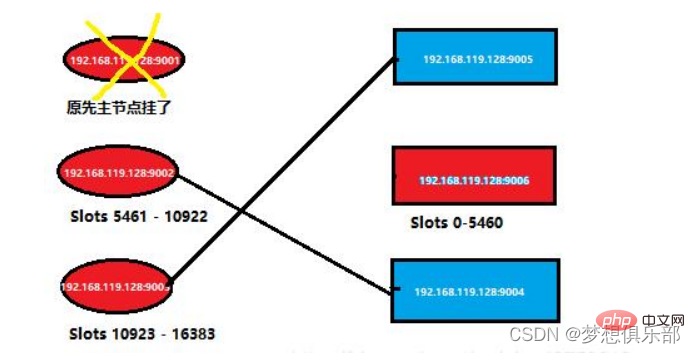

Jetzt starte ich den Masterknoten neu, der gerade aufgelegt hat, und überprüfe die Knotensituation im Cluster erneut. Die spezifische Situation ist wie in der Abbildung unten dargestellt

Kurz gesagt, jetzt im Cluster Die Knotensituation ist wie folgt
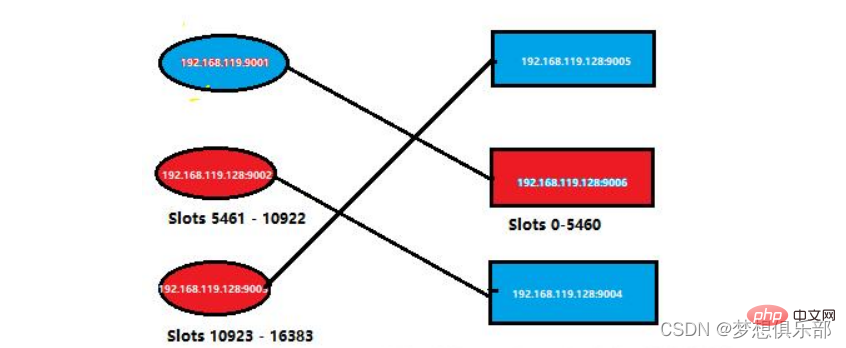
Empfohlenes Lernen:Redis-Tutorial
Das obige ist der detaillierte Inhalt vonVertieftes Verständnis der Redis-Cluster-Lösungen (Master-Slave-Modus, Sentinel-Modus, Redis-Cluster-Modus). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Analyse zur Optimierung von Redis, wenn der Speicher voll ist
- Was soll ich tun, wenn die Double-Write-Caches von Redis und MySQL inkonsistent sind? Lösungsaustausch
- Lassen Sie uns gemeinsam den Redis-Sentry-Modus analysieren
- So stellen Sie die Konsistenz zwischen Redis-Cache und Datenbank sicher
- Fassen Sie die sechs zugrunde liegenden Datenstrukturen von Redis zusammen und organisieren Sie sie