
Detaillierte Analyse zur Optimierung von Redis, wenn der Speicher voll ist

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-03-14 17:09:273581Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Redis. Er stellt hauptsächlich die damit verbundenen Probleme zur Optimierung von Redis vor, wenn der Speicher voll ist. Er enthält auch den Eliminierungsmechanismus, den LRU-Algorithmus und die Verarbeitung eliminierter Daten an alle. Hilfreich.

Empfohlenes Lernen: Redis-Lerntutorial
Was soll ich tun, wenn der Redis-Speicher voll ist? Wie optimiert man den Speicher?
Es gibt 20 Millionen Daten in MySQL, aber nur 200.000 Daten werden in Redis gespeichert.
Wenn die Größe des Redis-Speicherdatensatzes auf eine bestimmte Größe ansteigt, werden Daten gespeichert Eliminierungsstrategie wird umgesetzt.
Welche physischen Ressourcen verbraucht Redis hauptsächlich?
Speicher.
Was passiert, wenn Redis nicht mehr über genügend Speicher verfügt?
Wenn die festgelegte Obergrenze erreicht ist, gibt der Redis-Schreibbefehl eine Fehlermeldung zurück (der Lesebefehl kann jedoch weiterhin normal zurückgegeben werden). Oder Sie können den Speichereliminierungsmechanismus konfigurieren und den alten Speicherlöschungsmechanismus konfigurieren, wenn Redis die obere Speichergrenze erreicht Der Inhalt wird gelöscht.
Sprechen Sie über den Eliminierungsmechanismus zwischengespeicherter Daten
Was sind die Eliminierungsstrategien für den Redis-Cache?
- Die einzige Strategie, die Daten nicht eliminiert, ist Noeviction.
Es gibt 7 Eliminierungsstrategien. Wir können sie basierend auf dem Umfang der Eliminierungskandidatendatensätze weiter in zwei Kategorien einteilen:
- Elimination in Daten mit einer festgelegten Ablaufzeit, einschließlich volatile-random und volatile-ttl, volatile -lru, volatile-lfu vier Typen.
- Eliminieren Sie in allen Datenbereichen, einschließlich allkeys-lru, allkeys-random und allkeys-lfu.
| Strategie | Regeln |
|---|---|
| volatile-ttl | Beim Filtern werden Schlüssel-Wert-Paare mit festgelegter Ablaufzeit entsprechend der Reihenfolge der Ablaufzeit gelöscht früher wurde gelöscht. |
| volatile-random | Schlüssel-Wert-Paare nach dem Zufallsprinzip mit festgelegter Ablaufzeit löschen. -Volatile-lru |
| allkeys-lru | Verwenden Sie den LRU-Algorithmus, um alle Daten zu filtern |
| vallkeys -lfu | Verwenden Sie den LFU-Algorithmus, um alle Daten zu filtern |
Sprechen wir über den LRU-Algorithmus
, der Daten nach dem Prinzip der am wenigsten verwendeten Daten filtert. Die am seltensten verwendeten Daten werden herausgefiltert, während die zuletzt häufig verwendeten Daten im Cache verbleiben.
Wie genau werden Sie dann untersucht? LRU organisiert alle Daten in einer verknüpften Liste. Der Kopf und das Ende der verknüpften Liste stellen das MRU-Ende bzw. das LRU-Ende dar und stellen die zuletzt verwendeten Daten und die zuletzt am seltensten verwendeten Daten dar. 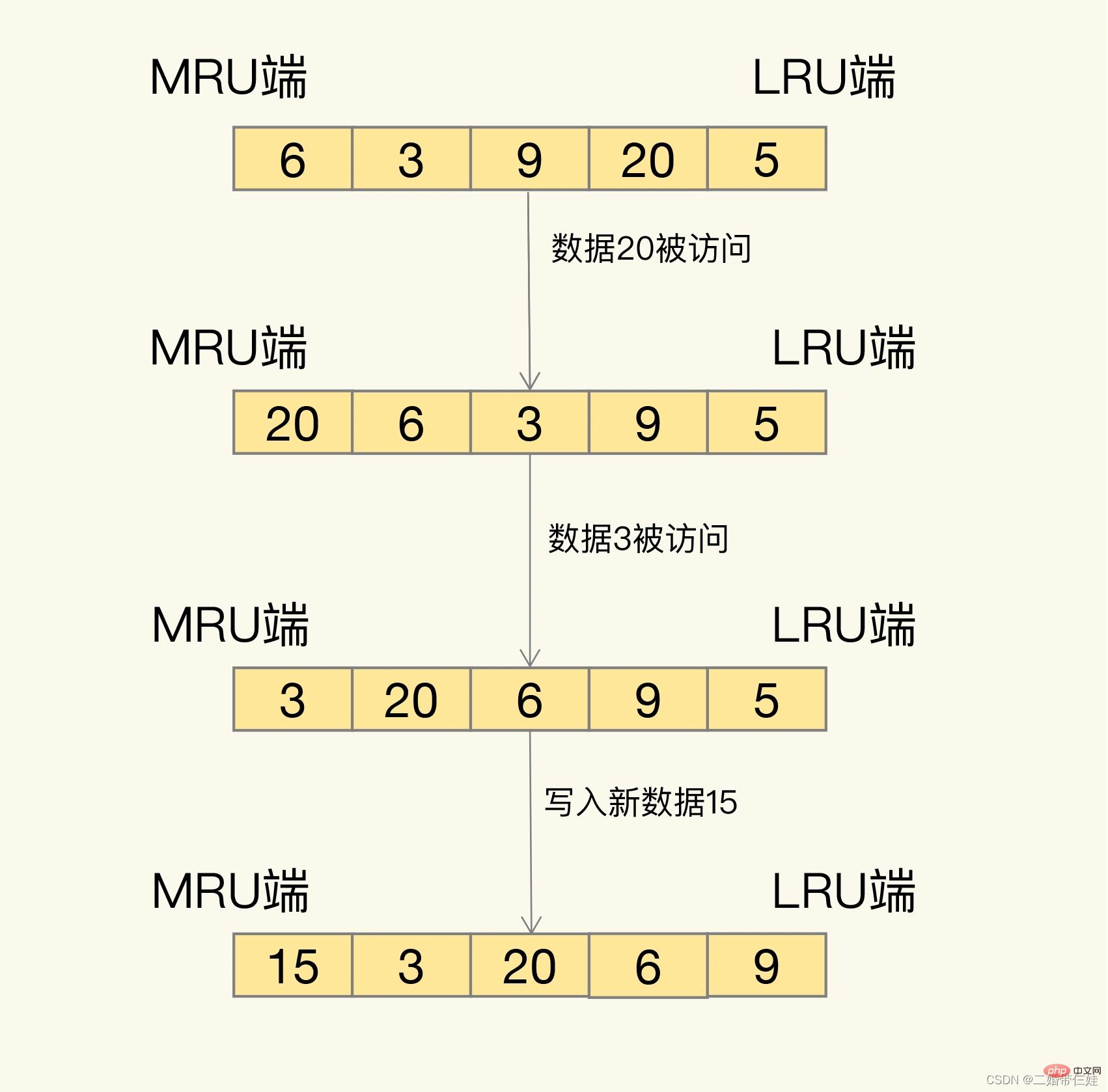
Die Idee hinter dem LRU-Algorithmus ist sehr einfach: Er geht davon aus, dass auf die Daten, auf die gerade zugegriffen wurde, definitiv erneut zugegriffen wird, und platziert sie daher auf der MRU-Seite Es kann nicht mehr darauf zugegriffen werden. Lassen Sie es also nach und nach auf die LRU-Seite zurückwandern und löschen Sie es zuerst, wenn der Cache voll ist.
Problem: Wenn der LRU-Algorithmus tatsächlich implementiert wird, muss er eine verknüpfte Liste verwenden, um alle zwischengespeicherten Daten zu verwalten, was zusätzlichen Speicherplatzaufwand mit sich bringt. Darüber hinaus müssen beim Zugriff auf Daten die Daten in die MRU in der verknüpften Liste verschoben werden. Wenn auf eine große Datenmenge zugegriffen wird, werden viele Verschiebevorgänge für verknüpfte Listen durchgeführt, was sehr zeitaufwändig ist und die Leistung des Redis-Cache verringert .
Lösung:
In Redis wurde der LRU-Algorithmus vereinfacht, um die Auswirkungen der Datenbeseitigung auf die Cache-Leistung zu reduzieren. Insbesondere zeichnet Redis standardmäßig den aktuellsten Zugriffszeitstempel aller Daten auf (aufgezeichnet durch das LRU-Feld in der Schlüssel-Wert-Paar-Datenstruktur RedisObject). Wenn Redis dann die zu eliminierenden Daten bestimmt, wählt es zum ersten Mal zufällig N Daten aus und verwendet sie als Kandidatensatz. Als nächstes vergleicht Redis die LRU-Felder dieser N Daten und entfernt die Daten mit dem kleinsten LRU-Feldwert aus dem Cache.
Wenn Daten erneut eliminiert werden müssen, muss Redis die Daten in den Kandidatensatz aufnehmen, der bei der ersten Eliminierung erstellt wurde. Das Auswahlkriterium lautet hier: Der LRU-Feldwert der Daten, die in den Kandidatensatz eingegeben werden können, muss kleiner sein als der kleinste LRU-Wert im Kandidatensatz. Wenn neue Daten in den Kandidatendatensatz eingegeben werden und die Anzahl der Daten im Kandidatendatensatz maxmemory-samples erreicht, entfernt Redis die Daten mit dem kleinsten LRU-Feldwert im Kandidatendatensatz.
Verwendungsvorschläge:
- Verwenden Sie zuerst die Allkeys-LRU-Strategie. Auf diese Weise können Sie die Vorteile von LRU, einem klassischen Caching-Algorithmus, voll ausnutzen, um die zuletzt aufgerufenen Daten im Cache zu halten und die Anwendungszugriffsleistung zu verbessern. Wenn in Ihren Geschäftsdaten ein offensichtlicher Unterschied zwischen heißen und kalten Daten besteht, empfehle ich Ihnen die Verwendung der allkeys-lru-Strategie.
- Wenn sich die Datenzugriffshäufigkeit in Geschäftsanwendungen nicht wesentlich unterscheidet und es keinen offensichtlichen Unterschied zwischen heißen und kalten Daten gibt, empfiehlt es sich, die Allkeys-Random-Strategie zu verwenden und die eliminierten Daten zufällig auszuwählen.
- Wenn in Ihrem Unternehmen ein Bedarf an angehefteten Daten besteht, wie etwa angeheftete Nachrichten und angeheftete Videos, dann können Sie die volatile-lru-Strategie nutzen und keine Ablaufzeit für diese angehefteten Daten festlegen. Auf diese Weise werden die Daten, die angeheftet werden müssen, niemals gelöscht und andere Daten werden nach Ablauf gemäß den LRU-Regeln gefiltert.
Wie gehe ich mit gelöschten Daten um?
Sobald die gelöschten Daten ausgewählt sind und es sich um saubere Daten handelt, werden wir sie direkt löschen. Wenn es sich bei den Daten um schmutzige Daten handelt, müssen wir sie zurück in die Datenbank schreiben.
Wie kann man also beurteilen, ob ein Datenelement sauber oder schmutzig ist?
- Der Unterschied zwischen sauberen und schmutzigen Daten besteht darin, ob sie im Vergleich zu dem Wert beim ursprünglichen Lesen aus der Back-End-Datenbank geändert wurden. Saubere Daten wurden nicht geändert, sodass die Daten in der Back-End-Datenbank ebenfalls die neuesten Werte sind. Beim Ersetzen kann es direkt gelöscht werden.
- Verschmutzte Daten sind Daten, die geändert wurden und nicht mehr mit den in der Back-End-Datenbank gespeicherten Daten übereinstimmen. Wenn die schmutzigen Daten zu diesem Zeitpunkt nicht in die Datenbank zurückgeschrieben werden, geht der neueste Wert dieser Daten verloren, was sich auf die normale Verwendung der Anwendung auswirkt.
Auch wenn es sich bei den gelöschten Daten um schmutzige Daten handelt, schreibt Redis sie nicht zurück in die Datenbank. Wenn wir also den Redis-Cache verwenden und die Daten geändert werden, müssen sie bei der Änderung der Daten in die Datenbank zurückgeschrieben werden. Andernfalls werden die verschmutzten Daten bei der Beseitigung von Redis gelöscht und die Datenbank enthält keine aktuellen Daten mehr.
Wie optimiert Redis den Speicher?
1. Kontrollieren Sie die Anzahl der Schlüssel: Wenn Sie Redis zum Speichern großer Datenmengen verwenden, gibt es normalerweise eine große Anzahl von Schlüsseln, und zu viele Schlüssel verbrauchen auch viel Speicher. Redis ist im Wesentlichen ein Datenstrukturserver, der uns eine Vielzahl von Datenstrukturen wie Hash, Liste, Set, Zset und andere Strukturen bereitstellt. Vermeiden Sie Missverständnisse bei der Verwendung von Redis, verwenden Sie APIs wie get/set ausgiebig und verwenden Sie Redis als Memcached. Um denselben Dateninhalt zu speichern, kann die Verwendung der Redis-Datenstruktur zur Reduzierung der Anzahl äußerer Schlüssel auch viel Speicher sparen.
2. Schlüsselwertobjekte reduzieren Der direkteste Weg, die Redis-Speichernutzung zu reduzieren, besteht darin, die Länge von Schlüsseln und Werten zu reduzieren.
- Schlüssellänge: Beim Entwerfen von Schlüsseln gilt bei vollständiger Beschreibung des Geschäfts: Je kürzer der Schlüsselwert, desto besser.
- Wertlänge: Die Reduzierung von Wertobjekten ist komplizierter. Eine häufige Anforderung besteht darin, Geschäftsobjekte in binäre Arrays zu serialisieren und in Redis abzulegen. Zunächst sollten Geschäftsobjekte optimiert und unnötige Attribute entfernt werden, um die Speicherung ungültiger Daten zu vermeiden. Zweitens sollte im Hinblick auf die Auswahl des Serialisierungstools ein effizienteres Serialisierungstool ausgewählt werden, um die Größe des Byte-Arrays zu reduzieren.
3. Codierungsoptimierung. Redis stellt externe Typen wie String, Liste, Hash, Set, Zet usw. bereit, aber Redis verfügt intern über das Konzept der Codierung für verschiedene Typen. Die sogenannte Codierung bezieht sich auf die spezifische zugrunde liegende Datenstruktur, die für die Implementierung verwendet wird. Unterschiedliche Kodierungen wirken sich direkt auf die Speichernutzung sowie die Lese- und Schreibeffizienz der Daten aus.
- 1. redisObject-Objekt
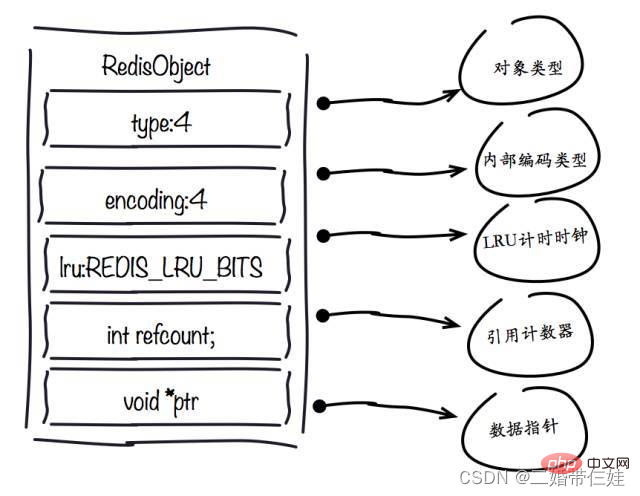
Typfeld:
Verwenden Sie Sammlungstypdaten, da normalerweise viele kleine Schlüsselwerte kompakter zusammen gespeichert werden können. Verwenden Sie so viele Hashes wie möglich (d. h. die in einer Hash-Tabelle gespeicherte Anzahl ist gering) und beanspruchen sehr wenig Speicher. Daher sollten Sie Ihr Datenmodell so weit wie möglich in eine Hash-Tabelle abstrahieren. Wenn in Ihrem Websystem beispielsweise ein Benutzerobjekt vorhanden ist, legen Sie keinen separaten Schlüssel für den Namen, den Nachnamen, die E-Mail-Adresse und das Passwort des Benutzers fest. Speichern Sie stattdessen alle Informationen des Benutzers in einer Hash-Tabelle.
Encoding-Feld:
Es gibt offensichtliche Unterschiede in der Speichernutzung bei Verwendung unterschiedlicher Codierungen
LRU-Feld:
Entwicklungstipp: Sie können den Befehl scan + object emptytime verwenden, um stapelweise abzufragen, auf welche Schlüssel nicht zugegriffen wurde Suchen Sie nach Schlüsseln, auf die längere Zeit nicht zugegriffen wurde, um die Speichernutzung zu reduzieren.
Refcount-Feld:
Wenn das Objekt eine Ganzzahl ist und der Bereich [0-9999] beträgt, kann Redis gemeinsam genutzte Objekte verwenden, um Speicher zu sparen.
ptr-Feld :
Entwicklungstipp: In Szenarien mit hohem gleichzeitigem Schreiben wird empfohlen, die Zeichenfolgenlänge auf 39 Byte zu beschränken, sofern die Bedingungen dies zulassen, um die Anzahl der Speicherzuweisungen zum Erstellen von redisObject zu reduzieren und die Leistung zu verbessern.
- 2. Schlüsselwertobjekte reduzieren
Der direkteste Weg, die Redis-Speichernutzung zu reduzieren, besteht darin, die Länge von Schlüsseln und Werten zu reduzieren.
Sie können einen allgemeinen Komprimierungsalgorithmus verwenden, um JSON und XML zu komprimieren, bevor Sie sie in Redis speichern, wodurch die Speichernutzung reduziert wird.
- 3 Der gemeinsam genutzte Objektpool bezieht sich auf den ganzzahligen Objektpool [0-9999 ] intern von Redis verwaltet. Das Erstellen einer großen Anzahl von RedisObjects vom Typ Integer ist mit einem Speicheraufwand verbunden. Die interne Struktur jedes RedisObjects belegt mindestens 16 Bytes, was sogar den Speicherplatzverbrauch der Ganzzahl selbst übersteigt. Daher verwaltet der Redis-Speicher einen ganzzahligen Objektpool [0-9999], um Speicher zu sparen. Zusätzlich zu ganzzahligen Wertobjekten können auch andere Typen wie interne Listen-, Hash-, Set- und Zset-Elemente ganzzahlige Objektpools verwenden.
Versuchen Sie daher in der Entwicklung unter der Voraussetzung, die Anforderungen zu erfüllen, ganzzahlige Objekte zu verwenden, um Speicher zu sparen. Wenn maxmemory festgelegt ist und LRU-bezogene Eliminierungsstrategien aktiviert sind, wie zum Beispiel: volatile-lru, allkeys-lru, verbietet Redis die Verwendung gemeinsamer Objektpools.
Warum ist der Objektpool ungültig, nachdem Maxmemory und die LRU-Eliminierungsstrategie aktiviert wurden? Der LRU-Algorithmus muss die letzte Zugriffszeit des Objekts ermitteln, um die längste nicht besuchte Daten jedes Objekts zu entfernen wird im lru-Feld des redisObject-Objekts gespeichert. Objektfreigabe bedeutet, dass mehrere Referenzen dasselbe redisObject gemeinsam nutzen. Zu diesem Zeitpunkt wird auch das LRU-Feld gemeinsam genutzt, sodass es unmöglich ist, die letzte Zugriffszeit jedes Objekts zu ermitteln. Wenn maxmemory nicht festgelegt ist, löst Redis das Speicherrecycling erst aus, wenn der Speicher erschöpft ist, sodass der gemeinsam genutzte Objektpool normal funktionieren kann.
Zusammenfassend lässt sich sagen, dass der Shared Object Pool mit der Maxmemory + LRU-Strategie in Konflikt steht, sodass Sie bei der Verwendung vorsichtig sein müssen.
Warum nur Integer-Objektpool? Erstens hat der Integer-Objektpool die höchste Wiederverwendungswahrscheinlichkeit. Zweitens besteht eine Schlüsseloperation der Objektfreigabe darin, die Gleichheit zu beurteilen. Der Grund, warum Redis nur einen Integer-Objektpool hat, liegt in der zeitlichen Komplexität des Integer-Vergleichsalgorithmus O(1) und nur 10.000 werden ganzzahlig beibehalten, um Objektpoolverschwendung zu vermeiden. Wenn die Gleichheit der Zeichenfolgen beurteilt wird, wird die Zeitkomplexität zu O(n), insbesondere lange Zeichenfolgen verbrauchen mehr Leistung (Gleitkommazahlen werden intern in Redis mithilfe von Zeichenfolgen gespeichert). Für komplexere Datenstrukturen wie Hash, Liste usw. erfordert die Gleichheitsbeurteilung O(n2). Für Single-Threaded-Redis ist ein solcher Overhead offensichtlich unangemessen, sodass Redis nur einen ganzzahligen gemeinsam genutzten Objektpool behält.
- 4. String-Optimierung
- Redis verwendet nicht den String-Typ der nativen C-Sprache, sondern implementiert eine eigene String-Struktur mit einem internen einfachen dynamischen String, der als SDS bezeichnet wird.
String-Struktur:
- Eigenschaften:
- Erfassung der O(1)-Zeitkomplexität: Stringlänge, verwendete Länge, unbenutzte Länge.
Kann zum Speichern von Byte-Arrays verwendet werden und unterstützt die sichere Binärdatenspeicherung.
Implementiert intern einen Speicherplatz-Vorzuweisungsmechanismus, um die Anzahl der Speicherneuzuweisungen zu reduzieren.
Lazy-Deletion-Mechanismus, der Speicherplatz nach der String-Reduzierung wird nicht freigegeben und als vorab zugewiesener Speicherplatz reserviert.
Vorabzuteilungsmechanismus:
- Entwicklungstipps: Versuchen Sie, häufige String-Änderungsvorgänge wie „Append“ und „Setrange“ zu reduzieren. Verwenden Sie stattdessen „Set“, um Strings zu ändern, um Speicherverschwendung und Speicherfragmentierung durch Vorabzuweisung zu reduzieren.
String-Rekonstruktion: Eine sekundäre Codierungsmethode basierend auf dem Hash-Typ.
- Wie verwende ich die sekundäre Kodierung?
Die in der sekundären Kodierungsmethode verwendete ID-Länge ist besonders.
Es besteht ein Problem: Wenn die zugrunde liegende Struktur des Hash-Typs kleiner als der festgelegte Wert ist, wird eine komprimierte Liste verwendet, und wenn sie größer als der festgelegte Wert ist, wird eine Hash-Tabelle verwendet.
Nach der Konvertierung von einer komprimierten Liste in eine Hash-Tabelle wird der Hash-Typ immer in der Hash-Tabelle gespeichert und nicht zurück in die komprimierte Liste konvertiert.
Im Hinblick auf die Einsparung von Speicherplatz sind Hash-Tabellen nicht so effizient wie komprimierte Listen. Um das kompakte Speicherlayout der komprimierten Liste vollständig nutzen zu können, ist es im Allgemeinen erforderlich, die Anzahl der im Hash gespeicherten Elemente zu steuern.
- 5. Codierungsoptimierung
Der von ziplist codierte Hash-Typ spart immer noch viel Speicher als der von hashtable codierte Satz.
- 6. Kontrollieren Sie die Anzahl der Schlüssel
Entwicklungstipp: Nachdem Sie Ziplist + Hash zur Schlüsseloptimierung verwendet haben und die Timeout-Löschfunktion verwenden möchten, können Entwickler die Zeit speichern, zu der jedes Objekt geschrieben wird, und dann Verwenden Sie hscan für geplante Aufgaben. Verwenden Sie den Befehl, um die Daten zu scannen, die Timeout-Datenelemente im Hash herauszufinden und sie zu löschen.
Wenn Redis nicht mehr über genügend Speicher verfügt, besteht die erste Überlegung darin, keine Maschinen für die horizontale Erweiterung hinzuzufügen. Versuchen Sie zunächst, den Speicher zu optimieren. Wenn Sie auf einen Engpass stoßen, denken Sie über eine horizontale Erweiterung nach. Auch bei Clustering-Lösungen ist die Optimierung auf vertikaler Ebene gleichermaßen wichtig, um unnötige Ressourcenverschwendung und Verwaltungskosten nach dem Clustering zu vermeiden.
Empfohlenes Lernen: Redis-Tutorial
Das obige ist der detaillierte Inhalt vonDetaillierte Analyse zur Optimierung von Redis, wenn der Speicher voll ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Lassen Sie uns über die 5 Datentypen in Redis sprechen und sehen, wie sie angewendet werden können!
- Verstehen Sie kurz die Implementierung des LRU-Cache-Eliminierungsalgorithmus von Redis
- Detaillierte Erläuterung des Persistenzprinzips des Redis-Tiefenlernens
- Detaillierte Erklärung der klassischen Redis-Techniken: Makefile
- Detaillierte Erläuterung der Persistenzprinzipien der klassischen Redis-Techniken