
Detaillierte Erläuterung des Persistenzprinzips des Redis-Tiefenlernens

- 青灯夜游nach vorne
- 2022-03-10 10:54:512435Durchsuche
In diesem Artikel erfahren Sie mehr über Redis, analysieren die Persistenz im Detail, stellen das Funktionsprinzip, den Persistenzprozess usw. vor. Ich hoffe, er wird Ihnen hilfreich sein!
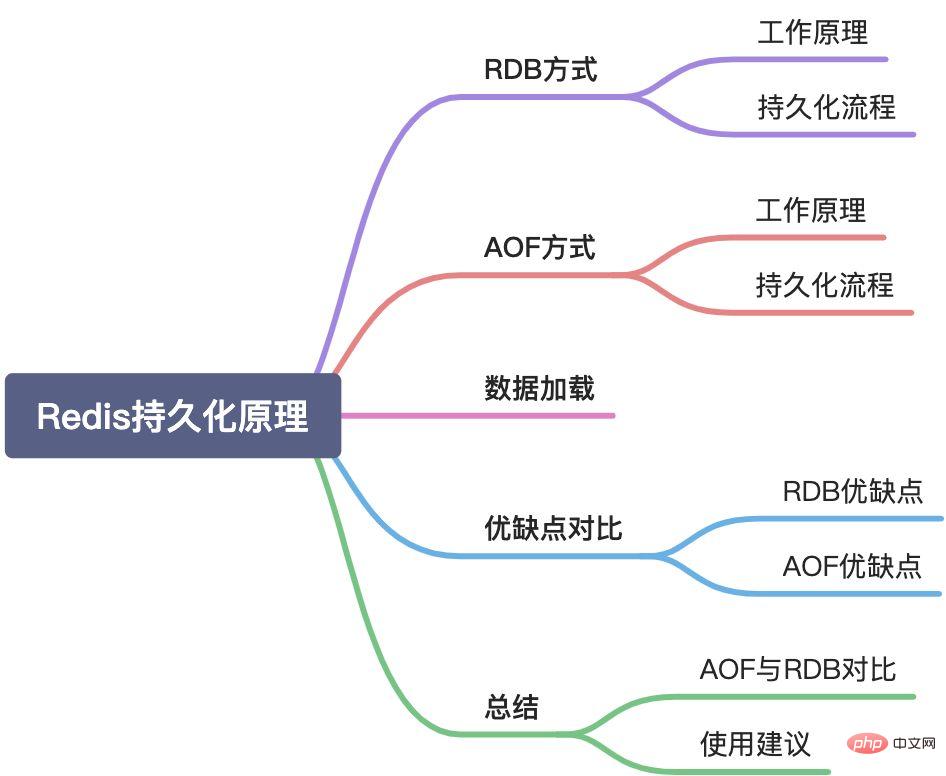
In diesem Artikel wird der Redis-Persistenzmechanismus unter folgenden Aspekten vorgestellt:
 ## Vorher geschrieben
## Vorher geschrieben
In diesem Artikel werden die beiden Persistenzmethoden von Redis im Detail als Ganzes vorgestellt, einschließlich Arbeitsprinzipien, Persistenzprozessen und Übungsstrategien und etwas theoretisches Wissen dahinter. Im vorherigen Artikel wurde nur die RDB-Persistenz eingeführt. Die Redis-Persistenz ist jedoch ein Ganzes und kann nicht separat eingeführt werden. Daher wurde sie neu organisiert. [Verwandte Empfehlungen: Redis-Video-Tutorial]
Redis ist eine In-Memory-Datenbank und alle Daten werden im Speicher gespeichert. Im Vergleich zu herkömmlichen relationalen Datenbanken wie MySQL, Oracle und SqlServer, die Daten direkt auf der Festplatte speichern Festplatte, Redis Die Lese- und Schreibeffizienz ist sehr hoch. Das Speichern im Speicher hat jedoch auch einen großen Nachteil. Sobald der Strom abgeschaltet wird oder der Computer heruntergefahren wird, gehen alle Inhalte in der Speicherdatenbank verloren. Um diesen Mangel auszugleichen, bietet Redis die Funktion, Speicherdaten in Festplattendateien zu speichern und Daten über Sicherungsdateien wiederherzustellen, den Redis-Persistenzmechanismus.
Redis unterstützt zwei Persistenzmethoden: RDB-Snapshot und AOF.
RDB-Persistenz
RDB-Snapshot In offiziellen Worten: Die RDB-Persistenzlösung ist ein Punkt-zu-Zeit-Snapshot, der in einem bestimmten Zeitintervall aus Ihrem Datensatz generiert wird. Es speichert den Speicher-Snapshot aller Datenobjekte in der Redis-Datenbank zu einem bestimmten Zeitpunkt in einer komprimierten Binärdatei, die für die Sicherung, Übertragung und Wiederherstellung von Redis-Daten verwendet werden kann. Bisher handelt es sich immer noch um die offizielle Standard-Supportlösung.
So funktioniert RDB
Da RDB eine Momentaufnahme des Datensatzes in Redis ist, wollen wir zunächst kurz verstehen, wie die Datenobjekte in Redis im Speicher gespeichert und organisiert werden.
Standardmäßig gibt es in Redis 16 Datenbanken, nummeriert von 0-15, jede Redis-Datenbank verwendet eine redisDb对象来表示,redisDbVerwenden Sie eine Hashtabelle, um K-V-Objekte zu speichern. Um das Verständnis zu erleichtern, habe ich eine der Datenbanken als Beispiel genommen, um ein schematisches Diagramm der Speicherstruktur der internen Daten von Redis zu zeichnen.

Ein Point-in-Time-Snapshot ist der Status jedes Datenobjekts in jeder Datenbank in Redis zu einem bestimmten Zeitpunkt. Angenommen, dass sich zu diesem Zeitpunkt nicht alle Datenobjekte ändern, können wir der obigen Abbildung folgen Entsprechend der Datenstrukturbeziehung werden diese Datenobjekte ausgelesen und in Dateien geschrieben, um Redis-Persistenz zu erreichen. Wenn Redis dann neu startet, wird der Inhalt dieser Datei gemäß den Regeln gelesen und dann in den Redis-Speicher geschrieben, um den Persistenzstatus wiederherzustellen.
- rdbSave: Es wird synchron ausgeführt und der Persistenzprozess wird unmittelbar nach dem Aufruf der Methode gestartet. Da es sich bei Redis um ein Single-Thread-Modell handelt, wird es während des Persistenzprozesses blockiert und kann keine externen Dienste bereitstellen.
- rdbSaveBackground: Diese Methode wird im Hintergrund ausgeführt (asynchron). Der Persistenzprozess befindet sich im untergeordneten Prozess (Aufruf von rdbSave).
Die Auslösung der RDB-Persistenz muss untrennbar mit den beiden oben genannten Methoden verbunden sein automatisch. Das manuelle Auslösen ist leicht zu verstehen. Dies bedeutet, dass wir manuell Anweisungen zur dauerhaften Sicherung an den Redis-Server initiieren und der Redis-Server dann mit der Ausführung des Persistenzprozesses beginnt. Die Anweisungen hier umfassen Speichern und BGSAVE. Automatisches Auslösen ist ein Persistenzprozess, den Redis automatisch auslöst, wenn voreingestellte Bedingungen basierend auf seinen eigenen Betriebsanforderungen erfüllt sind. Die automatisch ausgelösten Szenarien sind wie folgt (Auszug aus diesem Artikel):
-
save m nin serverCron > Konfigurationsregeln werden automatisch ausgelöst.save m n配置规则自动触发; - 从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会出发bgsave;
- 执行
debug reload命令重新加载redis时; - 默认情况下(未开启AOF)执行shutdown命令时,自动执行bgsave;
结合源码及参考文章,我整理了RDB持久化流程来帮助大家有个整体的了解,然后再从一些细节进行说明。
从上图可以知道:
- 自动触发的RDB持久化是通过rdbSaveBackground以子进程方式执行的持久化策略;
- 手动触发是以客户端命令方式触发的,包含save和bgsave两个命令,其中save命令是在Redis的命令处理线程以阻塞的方式调用
rdbSave方法完成的。
自动触发流程是一个完整的链路,涵盖了rdbSaveBackground、rdbSave等,接下来我以serverCron为例分析一下整个流程。
save规则及检查
serverCron是Redis内的一个周期性函数,每隔100毫秒执行一次,它的其中一项工作就是:根据配置文件中save规则来判断当前需要进行自动持久化流程,如果满足条件则尝试开始持久化。了解一下这部分的实现。
在redisServer中有几个与RDB持久化有关的字段,我从代码中摘出来,中英文对照着看下:
struct redisServer {
/* 省略其他字段 */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save
* 上次持久化后修改key的次数 */
struct saveparam *saveparams; /* Save points array for RDB,
* 对应配置文件多个save参数 */
int saveparamslen; /* Number of saving points,
* save参数的数量 */
time_t lastsave; /* Unix time of last successful save
* 上次持久化时间*/
/* 省略其他字段 */
}
/* 对应redis.conf中的save参数 */
struct saveparam {
time_t seconds; /* 统计时间范围 */
int changes; /* 数据修改次数 */
};
saveparams对应redis.conf下的save规则,save参数是Redis触发自动备份的触发策略,seconds为统计时间(单位:秒), changes为在统计时间内发生写入的次数。save m n的意思是:m秒内有n条写入就触发一次快照,即备份一次。save参数可以配置多组,满足在不同条件的备份要求。如果需要关闭RDB的自动备份策略,可以使用save ""。以下为几种配置的说明:
# 表示900秒(15分钟)内至少有1个key的值发生变化,则执行 save 900 1 # 表示300秒(5分钟)内至少有1个key的值发生变化,则执行 save 300 10 # 表示60秒(1分钟)内至少有10000个key的值发生变化,则执行 save 60 10000 # 该配置将会关闭RDB方式的持久化 save ""
serverCron
Durch die Kombination des Quellcodes und der Referenzartikel habe ich den RDB-Persistenzprozess organisiert Um allen ein umfassendes Verständnis zu vermitteln, gehen Sie dann von einigen Details aus. 
Wie Sie dem obigen Bild entnehmen können:
- Die automatisch ausgelöste RDB-Persistenz ist durch rdbSaveBackground. Persistenzstrategie, die im Unterprozessmodus ausgeführt wird;
- Manuelle Auslösung wird durch den Client-Befehl ausgelöst, einschließlich der Befehle save und bgsave, wobei der Befehl save im Redis-Befehlsverarbeitungsthread auf blockierende Weise aufgerufen wird
rdbSave Methode ist abgeschlossen.
Der automatische Auslöseprozess ist ein vollständiger Link, der rdbSaveBackground, rdbSave usw. abdeckt. Als Nächstes werde ich serverCron als Beispiel verwenden, um den gesamten Prozess zu analysieren.
Speicherregeln und -prüfungen
🎜serverCron ist eine periodische Funktion in Redis, die alle 100 Millisekunden ausgeführt wird. Eine ihrer Aufgaben besteht darin, den aktuellen Bedarf an automatischer Persistenz anhand der Speicherregeln in der Konfigurationsdatei zu ermitteln erfüllt sind, wird versucht, die Persistenz zu starten. Erfahren Sie mehr über die Implementierung dieses Teils. 🎜🎜Es gibt mehrere Felder im Zusammenhang mit der RDB-Persistenz inredisServer. Ich habe sie aus dem Code extrahiert und auf Chinesisch und Englisch angesehen: 🎜int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 后台无 saving/rewrite 子进程才会进行,逐个检查每个save规则*/
for (j = 0; j = sp->changes
&& server.unixtime-server.lastsave > sp->seconds
&&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* 执行bgsave过程 */
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* 省略:Trigger an AOF rewrite if needed. */
}
/* 省略其他逻辑 */
}🎜saveparams entspricht redis.conf, der Speicherparameter ist die Auslösestrategie für Redis, um eine automatische Sicherung auszulösen, Sekunden ist die statistische Zeit (Einheit: Sekunden), Änderungen Dies ist die Anzahl der Schreibvorgänge, die innerhalb der statistischen Zeit stattgefunden haben. <code>save m n bedeutet: n Schreibvorgänge innerhalb von m Sekunden lösen einen Snapshot, also ein Backup, aus. Es können mehrere Gruppen von Speicherparametern konfiguriert werden, um die Sicherungsanforderungen unter verschiedenen Bedingungen zu erfüllen. Wenn Sie die automatische Sicherungsrichtlinie von RDB deaktivieren müssen, können Sie save "" verwenden. Im Folgenden finden Sie Beschreibungen verschiedener Konfigurationen: 🎜int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
// fork子进程
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child 子进程:修改进程标题 */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
// 执行rdb持久化
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCOWInfo(CHILD_TYPE_RDB, 1, "RDB");
}
// 持久化完成后,退出子进程
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent 父进程:记录fork子进程的时间等信息*/
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
// 记录子进程开始的时间、类型等。
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}🎜serverCron Der Erkennungscode für RDB-Speicherregeln lautet wie folgt: 🎜# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof🎜Wenn keine RDB-Persistenz im Hintergrund oder kein AOF-Umschreibprozess vorhanden ist, basiert serverCron auf dem oben Die Konfiguration und der Status bestimmen, ob Persistenzvorgänge ausgeführt werden müssen. Die Grundlage für die Bestimmung ist, ob lastsave und dirty eine der Bedingungen im saveparams-Array erfüllen. Wenn eine Bedingung erfüllt ist, wird die rdbSaveBackground-Methode aufgerufen, um den asynchronen Persistenzprozess auszuführen. 🎜🎜rdbSaveBackground🎜🎜rdbSaveBackground ist eine Hilfsmethode für die RDB-Persistenz. Ihre Hauptaufgabe besteht darin, den untergeordneten Prozess zu forken. Anschließend gibt es je nach Aufrufer (übergeordneter Prozess oder untergeordneter Prozess) zwei verschiedene Ausführungslogiken. 🎜🎜🎜Wenn der Aufrufer der übergeordnete Prozess ist, geben Sie den untergeordneten Prozess aus, speichern Sie die Informationen zum untergeordneten Prozess und kehren Sie direkt zurück. 🎜🎜Wenn der Aufrufer ein untergeordneter Prozess ist, rufen Sie rdbSave auf, um die RDB-Persistenzlogik auszuführen, und verlassen Sie den untergeordneten Prozess, nachdem die Persistenz abgeschlossen ist. 🎜🎜
set number 0 incr number incr number incr number incr number incr number🎜rdbSave ist eine Methode, die wirklich Persistenz bietet. Sie erfordert eine große Anzahl von E/A- und Berechnungsvorgängen während der Ausführung, was zeitaufwändig ist und viel CPU beansprucht. Der Persistenzprozess belegt weiterhin Thread-Ressourcen, was wiederum dazu führt, dass Redis keine anderen Dienste bereitstellen kann. Um dieses Problem zu lösen, verzweigt Redis den untergeordneten Prozess in rdbSaveBackground, und der untergeordnete Prozess schließt die Persistenzarbeit ab, wodurch vermieden wird, dass zu viele Ressourcen des übergeordneten Prozesses belegt werden. 🎜🎜Es ist zu beachten, dass, wenn der vom übergeordneten Prozess belegte Speicher zu groß ist, der Fork-Prozess zeitaufwändig ist und der übergeordnete Prozess keine Dienste für die Außenwelt bereitstellen kann. Darüber hinaus verringert sich die Speichernutzung des Computers Da der untergeordnete Prozess nach der Verzweigung das Doppelte der Speicherressourcen belegt, muss sichergestellt werden, dass ausreichend Speicher vorhanden ist. Überprüfen Sie die Option „latest_fork_usec“ über den Befehl „info stats“, um die für den letzten Fork-Vorgang benötigte Zeit zu erhalten. 🎜
rdbSave
Redis的rdbSave函数是真正进行RDB持久化的函数,流程、细节贼多,整体流程可以总结为:创建并打开临时文件、Redis内存数据写入临时文件、临时文件写入磁盘、临时文件重命名为正式RDB文件、更新持久化状态信息(dirty、lastsave)。其中“Redis内存数据写入临时文件”最为核心和复杂,写入过程直接体现了RDB文件的文件格式,本着一图胜千言的理念,我按照源码流程绘制了下图。
补充说明一下,上图右下角“遍历当前数据库的键值对并写入”这个环节会根据不同类型的Redis数据类型及底层数据结构采用不同的格式写入到RDB文件中,不再展开了。我觉得大家对整个过程有个直观的理解就好,这对于我们理解Redis内部的运作机制大有裨益。
AOF持久化
上一节我们知道RDB是一种时间点(point-to-time)快照,适合数据备份及灾难恢复,由于工作原理的“先天性缺陷”无法保证实时性持久化,这对于缓存丢失零容忍的系统来说是个硬伤,于是就有了AOF。
AOF工作原理
AOF是Append Only File的缩写,它是Redis的完全持久化策略,从1.1版本开始支持;这里的file存储的是引起Redis数据修改的命令集合(比如:set/hset/del等),这些集合按照Redis Server的处理顺序追加到文件中。当重启Redis时,Redis就可以从头读取AOF中的指令并重放,进而恢复关闭前的数据状态。
AOF持久化默认是关闭的,修改redis.conf以下信息并重启,即可开启AOF持久化功能。
# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof
AOF本质是为了持久化,持久化对象是Redis内每一个key的状态,持久化的目的是为了在Reids发生故障重启后能够恢复至重启前或故障前的状态。相比于RDB,AOF采取的策略是按照执行顺序持久化每一条能够引起Redis中对象状态变更的命令,命令是有序的、有选择的。把aof文件转移至任何一台Redis Server,从头到尾按序重放这些命令即可恢复如初。举个例子:
首先执行指令set number 0,然后随机调用incr number、get number 各5次,最后再执行一次get number ,我们得到的结果肯定是5。
因为在这个过程中,能够引起number状态变更的只有set/incr类型的指令,并且它们执行的先后顺序是已知的,无论执行多少次get都不会影响number的状态。所以,保留所有set/incr命令并持久化至aof文件即可。按照aof的设计原理,aof文件中的内容应该是这样的(这里是假设,实际为RESP协议):
set number 0 incr number incr number incr number incr number incr number
最本质的原理用“命令重放”四个字就可以概括。但是,考虑实际生产环境的复杂性及操作系统等方面的限制,Redis所要考虑的工作要比这个例子复杂的多:
- Redis Server启动后,aof文件一直在追加命令,文件会越来越大。文件越大,Redis重启后恢复耗时越久;文件太大,转移工作就越难;不加管理,可能撑爆硬盘。很显然,需要在合适的时机对文件进行精简。例子中的5条incr指令很明显的可以替换为为一条
set命令,存在很大的压缩空间。 - 众所周知,文件I/O是操作系统性能的短板,为了提高效率,文件系统设计了一套复杂的缓存机制,Redis操作命令的追加操作只是把数据写入了缓冲区(aof_buf),从缓冲区到写入物理文件在性能与安全之间权衡会有不同的选择。
- 文件压缩即意味着重写,重写时即可依据已有的aof文件做命令整合,也可以先根据当前Redis内数据的状态做快照,再把存储快照过程中的新增的命令做追加。
- aof备份后的文件是为了恢复数据,结合aof文件的格式、完整性等因素,Redis也要设计一套完整的方案做支持。
持久化流程
从流程上来看,AOF的工作原理可以概括为几个步骤:命令追加(append)、文件写入与同步(fsync)、文件重写(rewrite)、重启加载(load),接下来依次了解每个步骤的细节及背后的设计哲学。
Befehl anhängen
Wenn die AOF-Persistenzfunktion aktiviert ist, hängt Redis nach der Ausführung eines Schreibbefehls den ausgeführten Schreibbefehl im Protokollformat an (d. h. RESP, das Kommunikationsprotokoll für die Interaktion zwischen dem Redis-Client und dem Server). . Wird an das Ende des vom Redis-Server verwalteten AOF-Puffers angehängt. Es gibt nur einen Single-Thread-Anhängevorgang für AOF-Dateien und es gibt keine komplexen Vorgänge wie Suchen. Es besteht kein Risiko einer Dateibeschädigung, selbst wenn der Strom ausgeschaltet oder ausgefallen ist. Darüber hinaus bietet die Verwendung von Textprotokollen viele Vorteile:
- Textprotokolle sind gut kompatibel; lesbar und bequem zum Anzeigen, Ändern und anderen Bearbeiten.
- Der AOF-Puffertyp ist eine von Redis unabhängig entworfene Datenstruktur
sds, die je nach Befehlstyp (catAppendOnlyGenericCommand,catAppendOnlyExpireAtCommand etc.) verarbeiten den Befehlsinhalt und schreiben ihn schließlich in den Puffer. <li>Es ist zu beachten, dass, wenn das AOF-Umschreiben beim Anhängen von Befehlen läuft, diese Befehle auch an den Umschreibepuffer (<code>aof_rewrite_buffer) angehängt werden.
Schreiben und Synchronisieren von Dateiensds,Redis会根据命令的类型采用不同的方法(catAppendOnlyGenericCommand、catAppendOnlyExpireAtCommand等)对命令内容进行处理,最后写入缓冲区。
需要注意的是:如果命令追加时正在进行AOF重写,这些命令还会追加到重写缓冲区(aof_rewrite_buffer)。
文件写入与同步
AOF文件的写入与同步离不开操作系统的支持,开始介绍之前,我们需要补充一下Linux I/O缓冲区相关知识。硬盘I/O性能较差,文件读写速度远远比不上CPU的处理速度,如果每次文件写入都等待数据写入硬盘,会整体拉低操作系统的性能。为了解决这个问题,操作系统提供了延迟写(delayed write)机制来提高硬盘的I/O性能。
传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行。 当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时, 再将该缓冲排入到输出队列,然后待其到达队首时,才进行实际的I/O操作。这种输出方式就被称为延迟写。
延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,使得欲写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能造成文件更新内容的丢失。为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个函数为强制写入硬盘提供支持。
Redis每次事件轮训结束前(beforeSleep)都会调用函数flushAppendOnlyFile,flushAppendOnlyFile会把AOF缓冲区(aof_buf)中的数据写入内核缓冲区,并且根据appendfsync配置来决定采用何种策略把内核缓冲区中的数据写入磁盘,即调用fsync()。该配置有三个可选项always、no、everysec,具体说明如下:
- always:每次都调用
fsync(),是安全性最高、性能最差的一种策略。 - no:不会调用
fsync()。性能最好,安全性最差。 - everysec:仅在满足同步条件时调用
fsync()。这是官方建议的同步策略,也是默认配置,做到兼顾性能和数据安全性,理论上只有在系统突然宕机的情况下丢失1秒的数据。
注意:上面介绍的策略受配置项no-appendfsync-on-rewrite的影响,它的作用是告知Redis:AOF文件重写期间是否禁止调用fsync(),默认是no。
如果appendfsync设置为always或everysec,后台正在进行的BGSAVE或者BGREWRITEAOF消耗过多的磁盘I/O,在某些Linux系统配置下,Redis对fsync()的调用可能阻塞很长时间。然而这个问题还没有修复,因为即使是在不同的线程中执行fsync(),同步写入操作也会被阻塞。
为了缓解此问题,可以使用该选项,以防止在进行BGSAVE或BGREWRITEAOF
 🎜
🎜Die traditionelle UNIX-Implementierung verfügt über einen Puffer-Cache oder Seiten-Cache im Kernel. Die meisten Festplatten-I/ O wird durch Pufferung durchgeführt. Beim Schreiben von Daten in eine Datei kopiert der Kernel die Daten normalerweise zuerst in einen der Puffer. Wenn der Puffer noch nicht voll ist, stellt er sie nicht in die Ausgabewarteschlange, sondern wartet darauf, dass sie voll sind oder wenn der Kernel sie benötigt Wenn der Puffer zum Speichern anderer Plattenblockdaten wiederverwendet wird, wird der Puffer in die Ausgabewarteschlange eingereiht, und der eigentliche E/A-Vorgang wird erst ausgeführt, wenn er den Kopf der Warteschlange erreicht. Diese Ausgabemethode wird als verzögertes Schreiben bezeichnet.🎜Verzögertes Schreiben reduziert die Anzahl der Lese- und Schreibvorgänge auf der Festplatte, verringert aber auch die Aktualisierungsgeschwindigkeit des Dateiinhalts, sodass die in die Datei zu schreibenden Daten für einen bestimmten Zeitraum nicht auf die Festplatte geschrieben werden. Wenn ein Systemfehler auftritt, kann diese Verzögerung dazu führen, dass Dateiaktualisierungen verloren gehen. Um die Konsistenz zwischen dem tatsächlichen Dateisystem auf der Festplatte und dem Inhalt im Puffercache sicherzustellen, bietet das UNIX-System drei Funktionen: sync, fsync und fdatasync, um das erzwungene Schreiben auf die Festplatte zu unterstützen. 🎜🎜Redis ruft die Funktion
flushAppendOnlyFile auf, bevor jede Ereignisrotation endet (beforeSleep), und flushAppendOnlyFile ruft den AOF-Puffer auf (aof_buf ) wird in den Kernel-Puffer geschrieben, und die zum Schreiben der Daten im Kernel-Puffer auf die Festplatte verwendete Strategie wird basierend auf der appendfsync-Konfiguration bestimmt, d. h. durch Aufrufen von fsync( ). Diese Konfiguration hat drei Optionen: <code>always, no und everysec. Die Details sind wie folgt: 🎜🎜🎜always: Rufen Sie fsync auf every time () ist die Strategie mit der höchsten Sicherheit und der schlechtesten Leistung. 🎜🎜nein: fsync() wird nicht aufgerufen. Beste Leistung, schlechteste Sicherheit. 🎜🎜everysec: Rufen Sie fsync() nur auf, wenn die Synchronisierungsbedingungen erfüllt sind. Dies ist die offiziell empfohlene Synchronisierungsstrategie und ist auch die Standardkonfiguration. Sie berücksichtigt sowohl die Leistung als auch die Datensicherheit. Theoretisch geht bei einem plötzlichen Systemausfall nur 1 Sekunde Daten verloren. 🎜🎜🎜Hinweis: Die oben vorgestellte Strategie wird durch das Konfigurationselement no-appendfsync-on-rewrite beeinflusst. Seine Funktion besteht darin, Redis darüber zu informieren, ob der Aufruf von fsync() während des Umschreibens der AOF-Datei verboten werden soll . , der Standardwert ist nein. 🎜🎜Wenn appendfsync auf always oder everysec eingestellt ist, wird BGSAVE oder ausgeführt Im Hintergrund verarbeitet >BGREWRITEAOF verbraucht zu viel Festplatten-E/A. Unter bestimmten Linux-Systemkonfigurationen kann der Aufruf von Redis an fsync() für längere Zeit blockieren. Dieses Problem wurde jedoch noch nicht behoben, da der synchrone Schreibvorgang auch dann blockiert wird, wenn fsync() in einem anderen Thread ausgeführt wird. 🎜🎜Um dieses Problem zu mildern, kann diese Option verwendet werden, um zu verhindern, dass fsync() im Hauptprozess aufgerufen wird, wenn BGSAVE oder BGREWRITEAOF ausgeführt wird. 🎜- 设置为
yes意味着,如果子进程正在进行BGSAVE或BGREWRITEAOF,AOF的持久化能力就与appendfsync设置为no有着相同的效果。最糟糕的情况下,这可能会导致30秒的缓存数据丢失。 - 如果你的系统有上面描述的延迟问题,就把这个选项设置为
yes,否则保持为no。
文件重写
如前面提到的,Redis长时间运行,命令不断写入AOF,文件会越来越大,不加控制可能影响宿主机的安全。
为了解决AOF文件体积问题,Redis引入了AOF文件重写功能,它会根据Redis内数据对象的最新状态生成新的AOF文件,新旧文件对应的数据状态一致,但是新文件会具有较小的体积。重写既减少了AOF文件对磁盘空间的占用,又可以提高Redis重启时数据恢复的速度。还是下面这个例子,旧文件中的6条命令等同于新文件中的1条命令,压缩效果显而易见。
我们说,AOF文件太大时会触发AOF文件重写,那到底是多大呢?有哪些情况会触发重写操作呢?
**
与RDB方式一样,AOF文件重写既可以手动触发,也会自动触发。手动触发直接调用bgrewriteaof命令,如果当时无子进程执行会立刻执行,否则安排在子进程结束后执行。自动触发由Redis的周期性方法serverCron检查在满足一定条件时触发。先了解两个配置项:
- auto-aof-rewrite-percentage:代表当前AOF文件大小(aof_current_size)和上一次重写后AOF文件大小(aof_base_size)相比,增长的比例。
- auto-aof-rewrite-min-size:表示运行
BGREWRITEAOF时AOF文件占用空间最小值,默认为64MB;
Redis启动时把aof_base_size初始化为当时aof文件的大小,Redis运行过程中,当AOF文件重写操作完成时,会对其进行更新;aof_current_size为serverCron执行时AOF文件的实时大小。当满足以下两个条件时,AOF文件重写就会触发:
增长比例:(aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage 文件大小:aof_current_size > auto-aof-rewrite-min-size
手动触发与自动触发的代码如下,同样在周期性方法serverCron中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 省略rdb持久化条件检查 */
/* AOF重写条件检查:aof开启、无子进程运行、增长百分比已设置、当前文件大小超过阈值 */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
/* 计算增长百分比 */
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/**/
}
AOF文件重写的流程是什么?听说Redis支持混合持久化,对AOF文件重写有什么影响?
从4.0版本开始,Redis在AOF模式中引入了混合持久化方案,即:纯AOF方式、RDB+AOF方式,这一策略由配置参数aof-use-rdb-preamble(使用RDB作为AOF文件的前半段)控制,默认关闭(no),设置为yes可开启。所以,在AOF重写过程中文件的写入会有两种不同的方式。当aof-use-rdb-preamble的值是:
- no:按照AOF格式写入命令,与4.0前版本无差别;
- yes:先按照RDB格式写入数据状态,然后把重写期间AOF缓冲区的内容以AOF格式写入,文件前半部分为RDB格式,后半部分为AOF格式。
结合源码(6.0版本,源码太多这里不贴出,可参考aof.c)及参考资料,绘制AOF重写(BGREWRITEAOF)流程图:
结合上图,总结一下AOF文件重写的流程:
- rewriteAppendOnlyFileBackground开始执行,检查是否有正在进行的AOF重写或RDB持久化子进程:如果有,则退出该流程;如果没有,则继续创建接下来父子进程间数据传输的通信管道。执行fork()操作,成功后父子进程分别执行不同的流程。
-
父进程:
- 记录子进程信息(pid)、时间戳等;
- 继续响应其他客户端请求;
- 收集AOF重写期间的命令,追加至aof_rewrite_buffer;
- 等待并向子进程同步aof_rewrite_buffer的内容;
-
子进程:
- Ändern Sie den aktuellen Prozessnamen, erstellen Sie die zum Umschreiben erforderliche temporäre Datei und rufen Sie die Funktion rewriteAppendOnlyFile auf.
- Schreiben Sie gemäß der
aof-use-rdb-preamble-Konfiguration die erste Hälfte in RDB oder AOF-Modus und Synchronisierung mit der Festplatte;aof-use-rdb-preamble配置,以RDB或AOF方式写入前半部分,并同步至硬盘; - 从父进程接收增量AOF命令,以AOF方式写入后半部分,并同步至硬盘;
- 重命名AOF文件,子进程退出。
数据加载
Redis启动后通过loadDataFromDisk函数执行数据加载工作。这里需要注意,虽然持久化方式可以选择AOF、RDB或者两者兼用,但是数据加载时必须做出选择,两种方式各自加载一遍就乱套了。
理论上,AOF持久化比RDB具有更好的实时性,当开启了AOF持久化方式,Redis在数据加载时优先考虑AOF方式。而且,Redis 4.0版本后AOF支持了混合持久化,加载AOF文件需要考虑版本兼容性。Redis数据加载流程如下图所示:
在AOF方式下,开启混合持久化机制生成的文件是“RDB头+AOF尾”,未开启时生成的文件全部为AOF格式。考虑两种文件格式的兼容性,如果Redis发现AOF文件为RDB头,会使用RDB数据加载的方法读取并恢复前半部分;然后再使用AOF方式读取并恢复后半部分。由于AOF格式存储的数据为RESP协议命令,Redis采用伪客户端执行命令的方式来恢复数据。
如果在AOF命令追加过程中发生宕机,由于延迟写的技术特点,AOF的RESP命令可能不完整(被截断)。遇到这种情况时,Redis会按照配置项aof-load-truncated
- Laden von Daten
Nachdem Redis gestartet wurde, wird der Datenladevorgang über die Funktion loadDataFromDisk ausgeführt. Hierbei ist zu beachten, dass die Persistenzmethode zwar AOF, RDB oder beides sein kann, beim Laden der Daten jedoch eine Auswahl getroffen werden muss, was zu Chaos führt.
Theoretisch bietet die AOF-Persistenz eine bessere Echtzeitleistung als RDB. Wenn die AOF-Persistenz aktiviert ist, gibt Redis AOF beim Laden von Daten Priorität. Darüber hinaus unterstützt AOF nach Redis 4.0 die Hybridpersistenz, und beim Laden von AOF-Dateien muss die Versionskompatibilität berücksichtigt werden. Der Redis-Datenladevorgang ist in der folgenden Abbildung dargestellt:
Aktivieren Sie im AOF-Modus den Hybrid Persistenzmechanismus Die generierte Datei ist „RDB-Header + AOF-Tail“. Wenn er nicht aktiviert ist, liegen alle generierten Dateien im AOF-Format vor. Wenn Redis unter Berücksichtigung der Kompatibilität der beiden Dateiformate feststellt, dass es sich bei der AOF-Datei um einen RDB-Header handelt, verwendet es die RDB-Datenlademethode zum Lesen und Wiederherstellen der ersten Hälfte und verwendet dann die AOF-Methode zum Lesen und Wiederherstellen der zweiten Hälfte . Da es sich bei den im AOF-Format gespeicherten Daten um RESP-Protokollbefehle handelt, verwendet Redis einen Pseudo-Client, um Befehle zur Wiederherstellung der Daten auszuführen.
Wenn während des Anhängevorgangs des AOF-Befehls eine Ausfallzeit auftritt, ist der RESP-Befehl des AOF aufgrund der technischen Merkmale des verzögerten Schreibens möglicherweise unvollständig (abgeschnitten). Wenn diese Situation auftritt, führt Redis je nach Konfigurationselement aof-load-truncated unterschiedliche Verarbeitungsstrategien aus. Diese Konfiguration weist Redis an, beim Start die AOF-Datei zu lesen und zu tun, wenn festgestellt wird, dass die Datei abgeschnitten (unvollständig) ist:
RDB vs. AOF
RDB Vorteile
- RDB ist eine kompakte und komprimierte Binärdatei, die eine Momentaufnahme der Redis-Daten zu einem bestimmten Zeitpunkt darstellt. Sie eignet sich sehr gut für Backup, vollständige Replikation und andere Szenarien.
- RDB eignet sich sehr gut für die Notfallwiederherstellung und die Datenmigration kann an jeden beliebigen Ort verschoben und neu geladen werden.
- RDB ist ein Speicher-Snapshot von Redis-Daten mit schnellerer Datenwiederherstellung und höherer Leistung als die AOF-Befehlswiedergabe.
RDB-Nachteile
- Die RDB-Methode kann keine Echtzeit- oder Second-Level-Persistenz erreichen. Da der Persistenzprozess nach der Verzweigung des untergeordneten Prozesses vom untergeordneten Prozess abgeschlossen wird, ist der Speicher des untergeordneten Prozesses nur eine Momentaufnahme der Daten des übergeordneten Prozesses zum Zeitpunkt der Verzweigungsoperation. Nach der Verzweigungsoperation wird der übergeordnete Prozess fortgesetzt Um die Außenwelt zu bedienen, ändern sich die internen Daten ständig. Die Daten werden nicht mehr aktualisiert und es gibt immer Unterschiede zwischen den beiden, sodass keine Echtzeitleistung erreicht werden kann.
- Der Fork-Vorgang während des RDB-Persistenzprozesses verdoppelt die Speichernutzung. Je mehr Daten der übergeordnete Prozess hat, desto länger dauert der Fork-Prozess.
- Eine hohe Parallelität von Redis-Anfragen kann häufig zu Speicherregeln führen, was dazu führt, dass die Häufigkeit von Fork-Vorgängen und dauerhaften Sicherungen unkontrollierbar ist.
- Für RDB-Dateien gelten Dateiformatanforderungen, bei einigen älteren Versionen ist dies der Fall inkompatibel. Problem mit neuer Version.
AOF-Vorteile
- AOF-Persistenz hat eine bessere Echtzeitleistung, wir können drei verschiedene Methoden wählen (appendfsync): nein, jede Sekunde, immer, jede Sekunde, da die Standardstrategie die beste Leistung hat, extrem. In diesem Fall Es kann zu einem Datenverlust von einer Sekunde kommen.
- Für AOF-Dateien gibt es nur Anhängevorgänge, keine komplizierten Such- und anderen Dateivorgänge und kein Risiko einer Beschädigung. Selbst wenn die zuletzt geschriebenen Daten abgeschnitten sind, können sie mit dem
redis-check-aof-Tool problemlos repariert werden. - Wenn die AOF-Datei größer wird, kann Redis sie automatisch im Hintergrund neu schreiben. Während des Umschreibvorgangs wird die alte Datei weiterhin geschrieben. Nach Abschluss des Umschreibvorgangs wird die neue Datei kleiner und der inkrementelle Befehl während des Umschreibvorgangs wird auch an die neue Datei angehängt.
- Die AOF-Datei enthält alle Betriebsbefehle für Daten in Redis auf eine leicht verständliche und zu analysierende Weise. Selbst wenn alle Daten versehentlich gelöscht werden, können wir alle Daten abrufen, indem wir den letzten Befehl entfernen, solange die AOF-Datei nicht neu geschrieben wird.
- AOF unterstützt bereits Hybridpersistenz, die Dateigröße kann effektiv gesteuert werden und die Effizienz des Datenladens wird verbessert.
Nachteile von AOF
- Bei derselben Datenerfassung sind AOF-Dateien normalerweise größer als RDB-Dateien.
- Unter einer bestimmten Fsync-Strategie ist AOF etwas langsamer als RDB. Im Allgemeinen ist die Leistung von fsync_every_second immer noch sehr hoch und die Leistung von fsync_no mit der von RDB vergleichbar. Unter enormem Schreibdruck kann RDB jedoch die größte Garantie für niedrige Latenzzeiten bieten.
- Auf AOF ist Redis einmal auf einige seltene Fehler gestoßen, die auf RDB kaum zu finden sind. Einige spezielle Anweisungen (z. B. BRPOPLPUSH) führen dazu, dass die neu geladenen Daten nicht mit denen vor der Persistenz übereinstimmen, die Redis-Beamte einmal unter denselben Bedingungen getestet haben, das Problem konnte jedoch nicht reproduziert werden.
Verwendungsvorschläge
Nachdem wir die Arbeitsprinzipien, Ausführungsprozesse, Vor- und Nachteile der beiden Persistenzmethoden von RDB und AOF verstanden haben, wollen wir darüber nachdenken, wie wir die Vor- und Nachteile in tatsächlichen Szenarien abwägen und die beiden Persistenzmethoden sinnvoll einsetzen können. Wenn Sie Redis nur als Caching-Tool verwenden, können alle Daten basierend auf der persistenten Datenbank rekonstruiert werden. Sie können die Persistenzfunktion deaktivieren und Schutzarbeiten wie Vorheizen, Cache-Penetration, Ausfall und Lawine durchführen.
Unter normalen Umständen übernimmt Redis mehr Arbeit, wie z. B. verteilte Sperren, Rankings, Registrierungszentren usw. Die Persistenzfunktion wird bei der Notfallwiederherstellung und Datenmigration eine größere Rolle spielen. Es wird empfohlen, mehrere Grundsätze zu befolgen:
- Verwenden Sie Redis nicht als Datenbank. Alle Daten können vom Anwendungsdienst so weit wie möglich automatisch rekonstruiert werden.
- Verwenden Sie Redis Version 4.0 oder höher und verwenden Sie die AOF+RDB-Hybrid-Persistenzfunktion.
- Planen Sie den von Redis maximal belegten Speicher richtig, um zu verhindern, dass beim AOF-Neuschreiben oder Speichern nicht genügend Ressourcen zur Verfügung stehen.
- Vermeiden Sie die Bereitstellung mehrerer Instanzen auf einer einzigen Maschine.
- Die meisten Produktionsumgebungen werden in Clustern bereitgestellt. Die Persistenzfunktion kann auf dem Slave aktiviert werden, sodass der Master externe Schreibdienste besser bereitstellen kann.
- Sicherungsdateien sollten automatisch in externe Computerräume oder Cloud-Speicher hochgeladen werden, um eine Notfallsicherung vorzubereiten.
Über fork()
Durch die obige Analyse wissen wir alle, dass RDB-Snapshots und AOF-Umschreiben einen Fork erfordern. Dies ist ein schwerer Vorgang und führt zu einer Blockierung von Redis. Um die Reaktion des Redis-Hauptprozesses nicht zu beeinträchtigen, müssen wir daher die Blockierung so weit wie möglich reduzieren.
- Reduzieren Sie die Häufigkeit von Forks. Sie können beispielsweise RDB manuell auslösen, um Snapshots und AOF-Rewrites zu generieren.
- Kontrollieren Sie die maximale Speichernutzung von Redis, um zu verhindern, dass Forks zu lange dauern Eine ordnungsgemäß konfigurierte Speicherzuweisungsstrategie von Linux vermeidet Fork-Fehler aufgrund unzureichenden physischen Speichers.
- Weitere Kenntnisse zum Thema Programmierung finden Sie unter: Einführung in die Programmierung
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des Persistenzprinzips des Redis-Tiefenlernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Worauf sollten wir bei der Implementierung verteilter Sperren in Redis achten? [Zusammenfassung der Vorsichtsmaßnahmen]
- Führen Sie Sie Schritt für Schritt durch, um den Hochverfügbarkeitscluster von Redis zu verstehen
- Fassen Sie 10 Tipps zur Verbesserung der Redis-Leistung zusammen
- Vermitteln Sie ein umfassendes Verständnis der verteilten Sperren in Redis
- Lassen Sie uns über Redis-Dateiereignisse und Zeitereignisse sprechen
- Lassen Sie uns über die 5 Datentypen in Redis sprechen und sehen, wie sie angewendet werden können!